【Pytorch】学习记录分享7——PyTorch自然语言处理基础-词向量模型Word2Vec
- 1. 词向量模型Word2Vec)
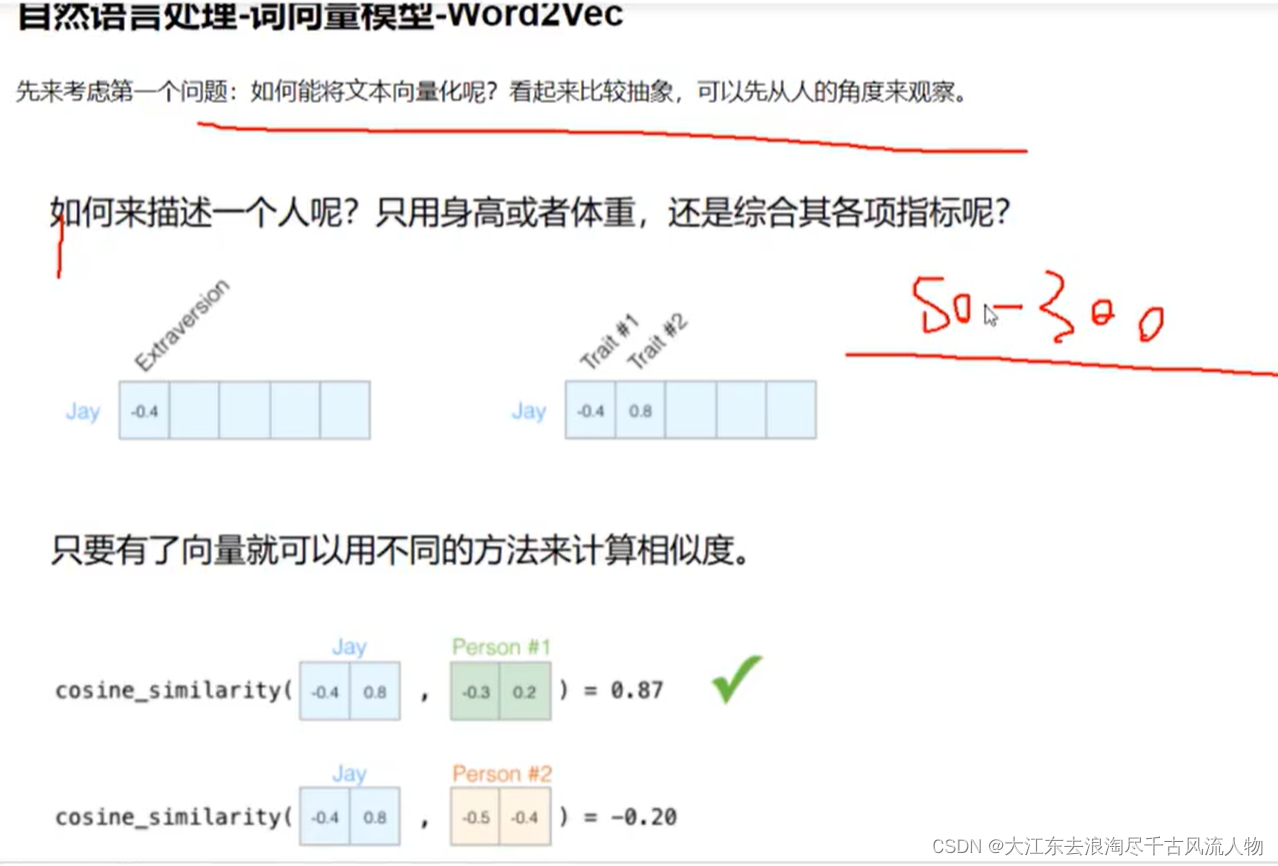
- 1. 如何度量这个单词的?
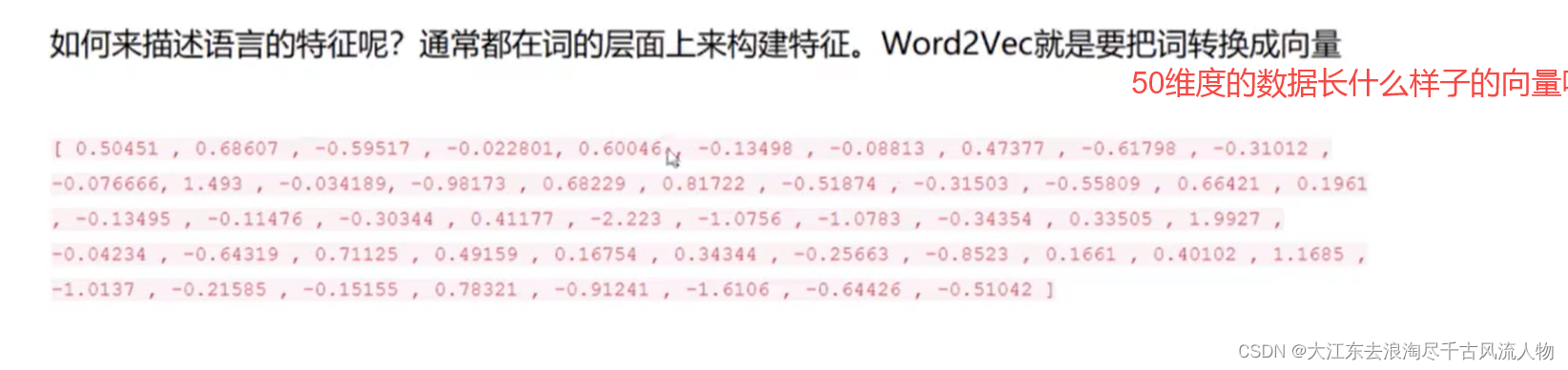
- 2.词向量是什么样子?
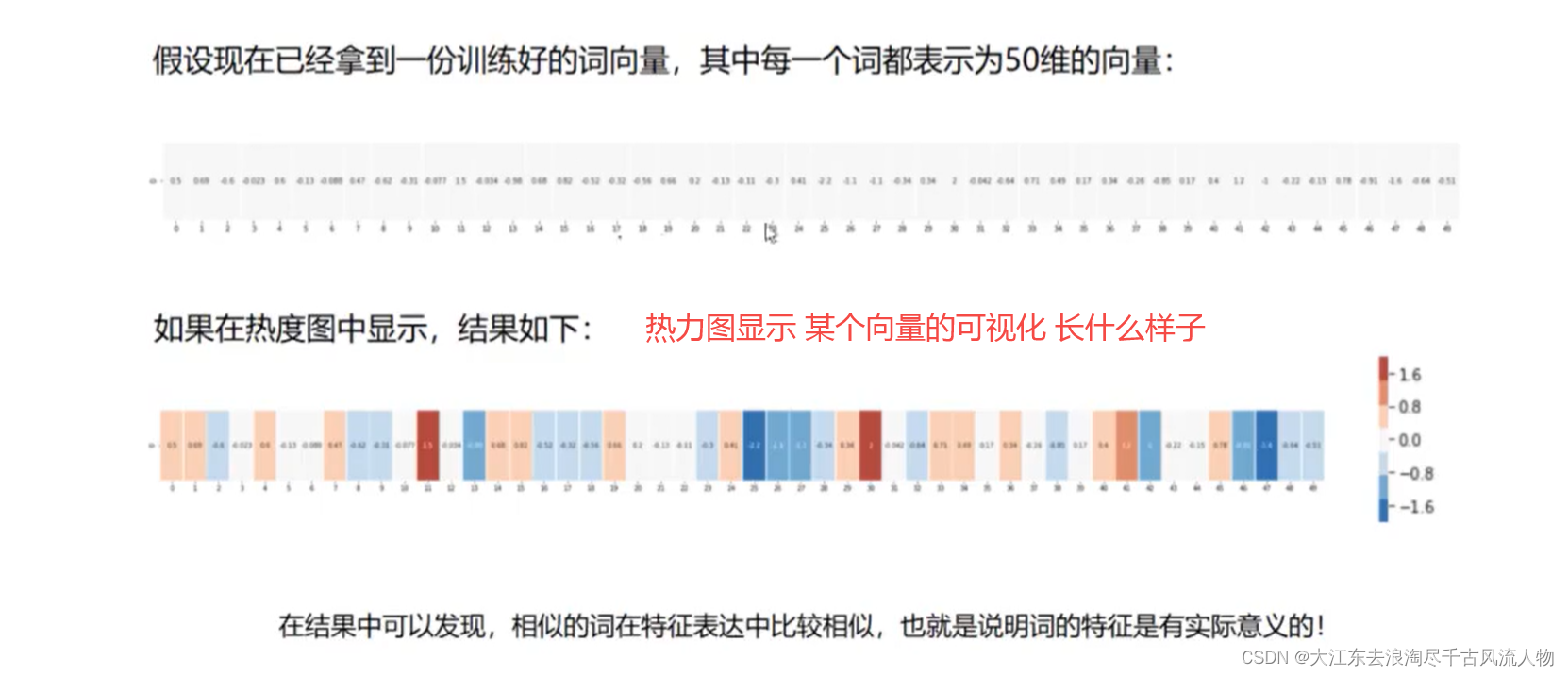
- 3.词向量对应的热力图:
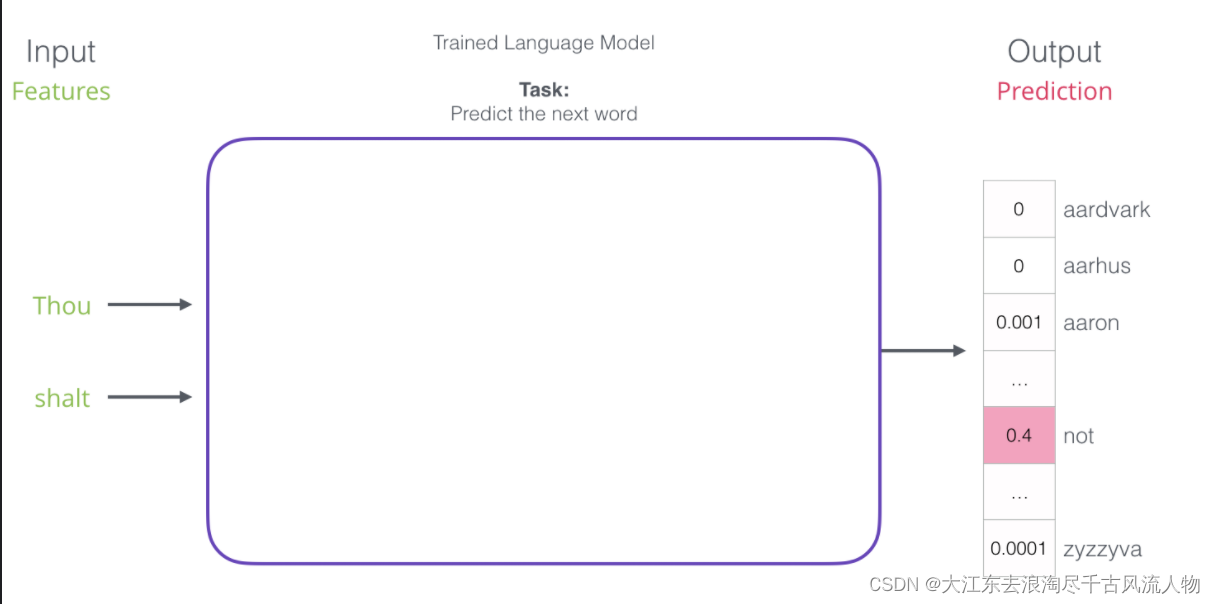
- 4.词向量模型的输入与输出
- 2.如何构建训练数据
- 2.1 构建训练数据
- 2.2 不同模型对比(传入中间词预测上下文,传入上下文,预测中间词汇)
- 3.如何训练
- 3.1 如何设计驯联网络
- 3.2 改进方案:加入一些负样本(负采样模型)
- 3.3 词向量训练过程
1. 词向量模型Word2Vec)
1. 如何度量这个单词的?
2.词向量是什么样子?
3.词向量对应的热力图:
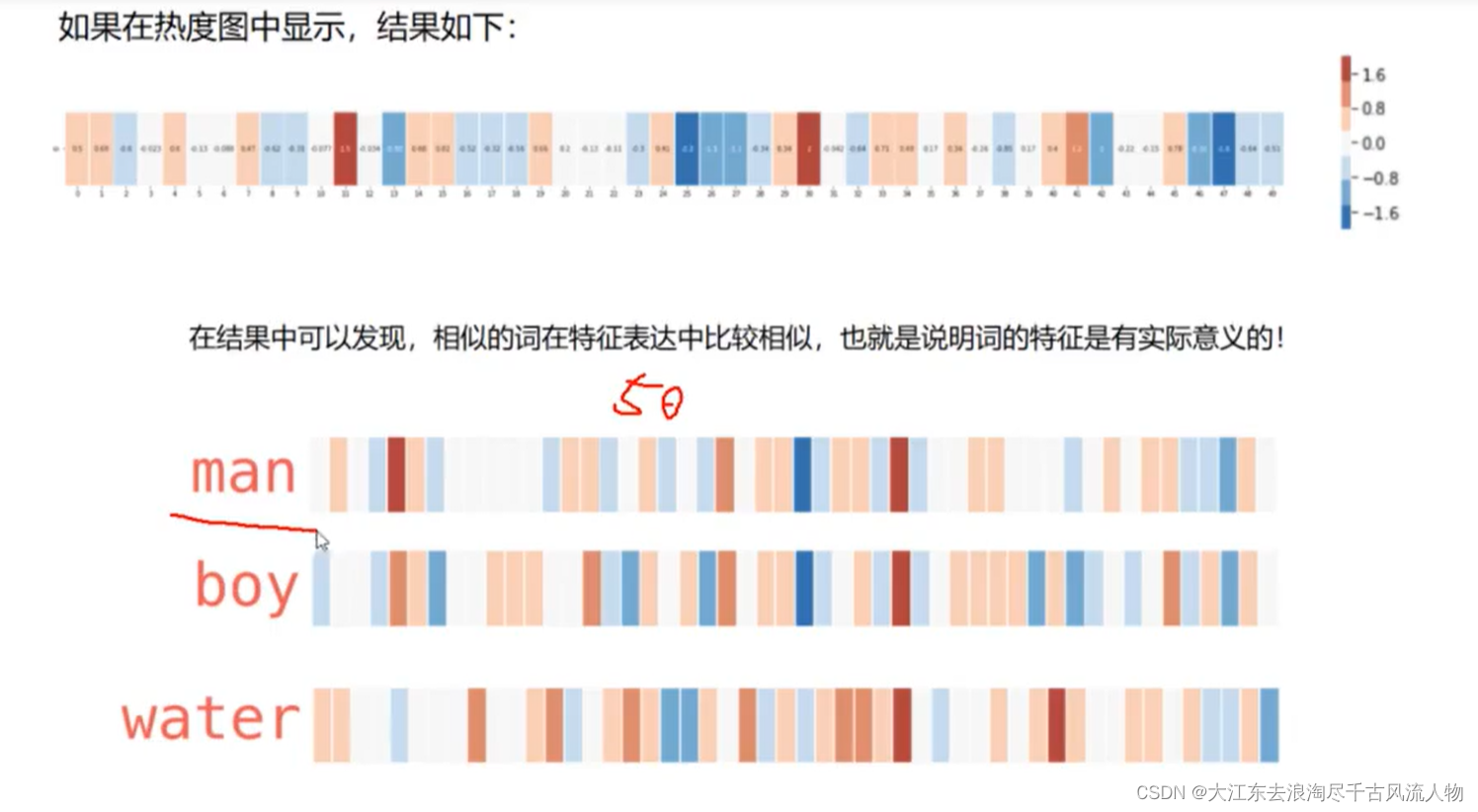
4.词向量模型的输入与输出
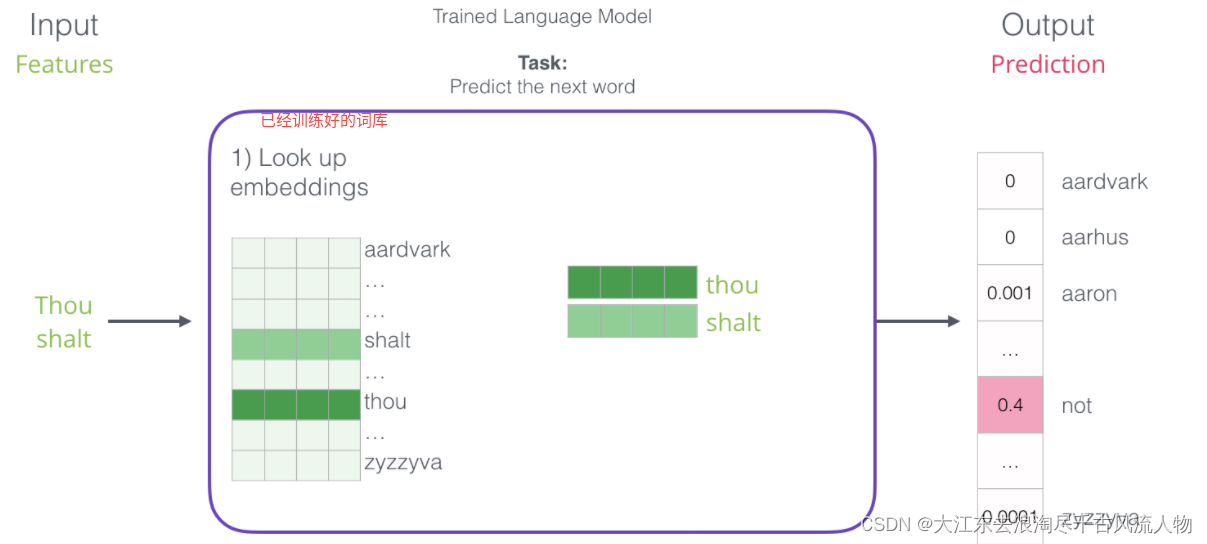
2.如何构建训练数据
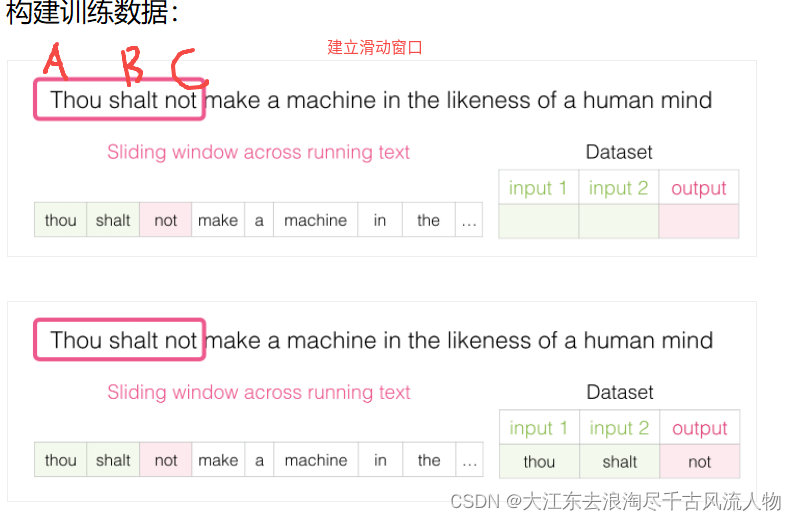
2.1 构建训练数据
类似wiki与合乎说话逻辑的文本均可以作为训练数据
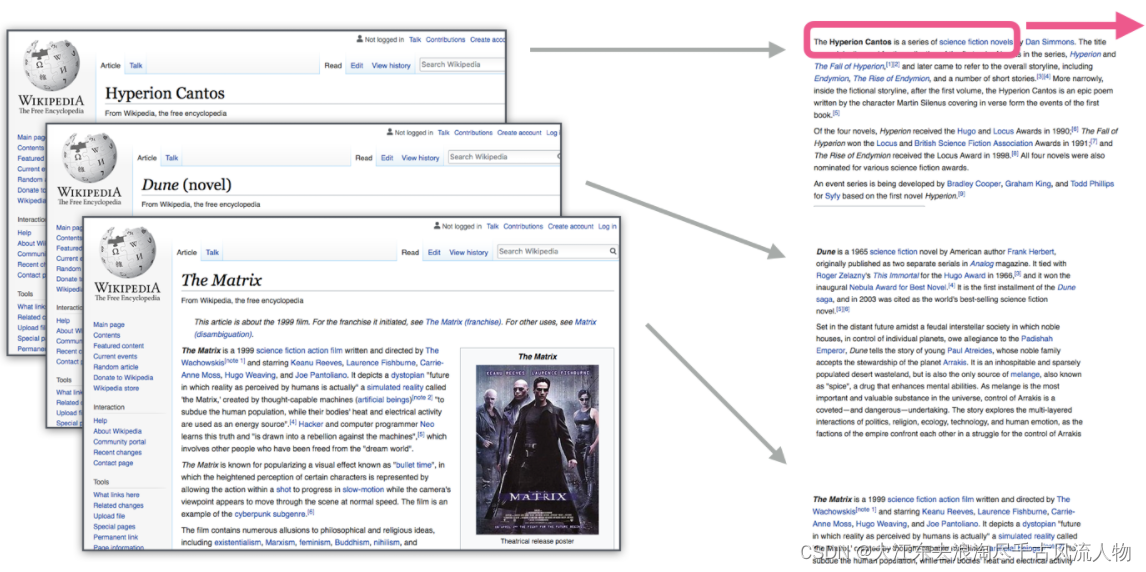
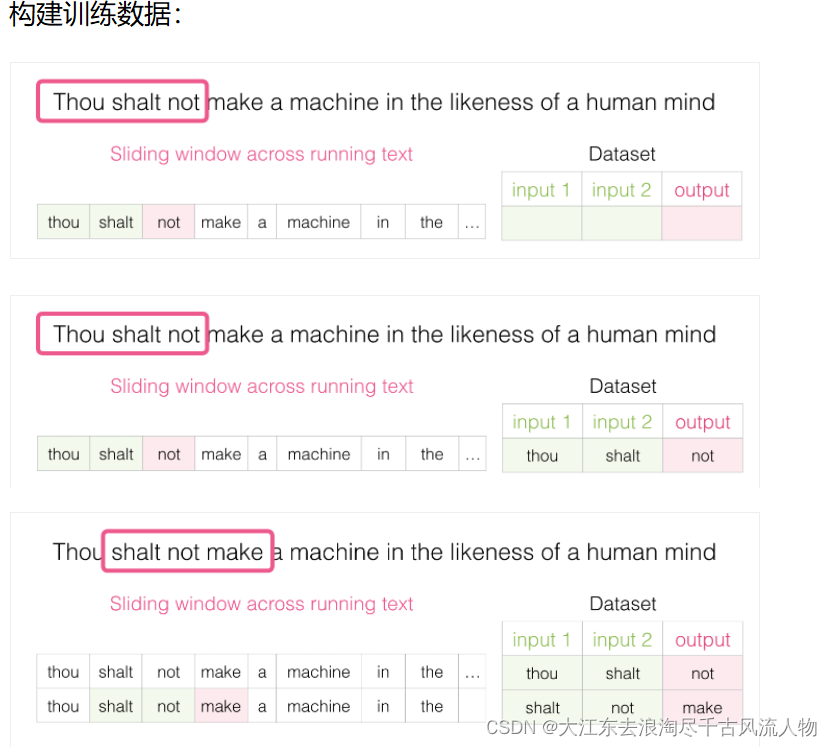
2.2 不同模型对比(传入中间词预测上下文,传入上下文,预测中间词汇)
CBOW:
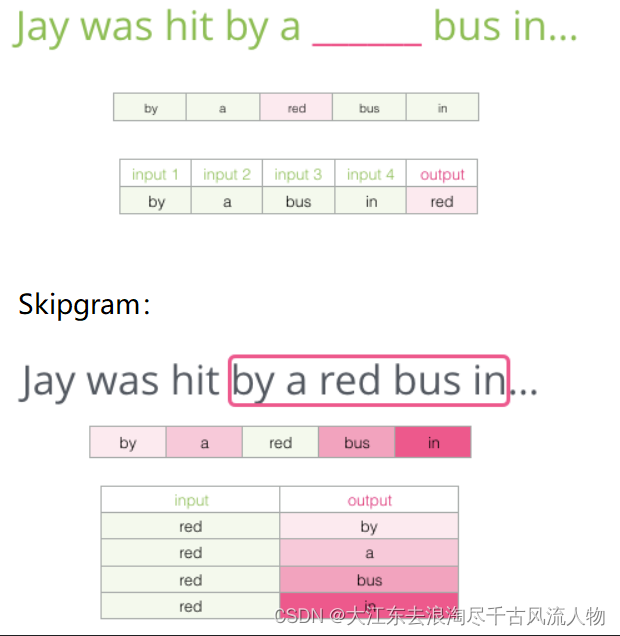
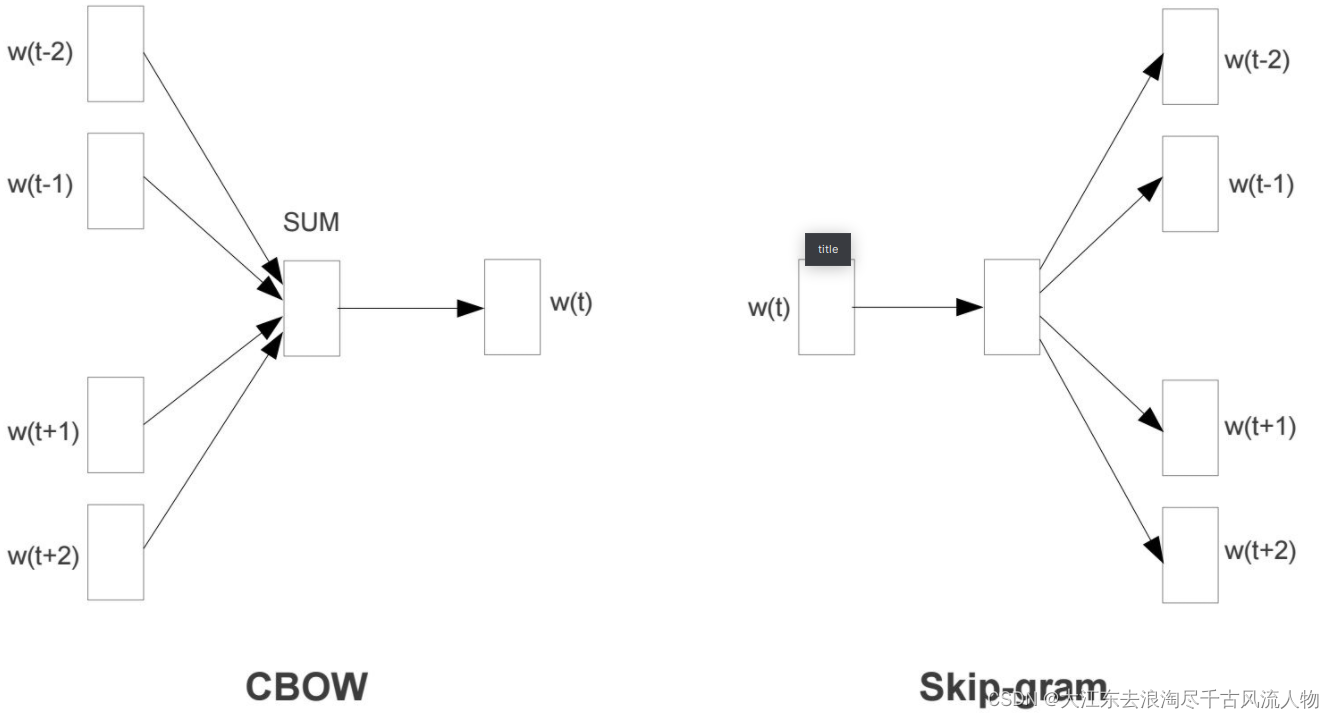
Skip-gram模型所需训练数据集 :
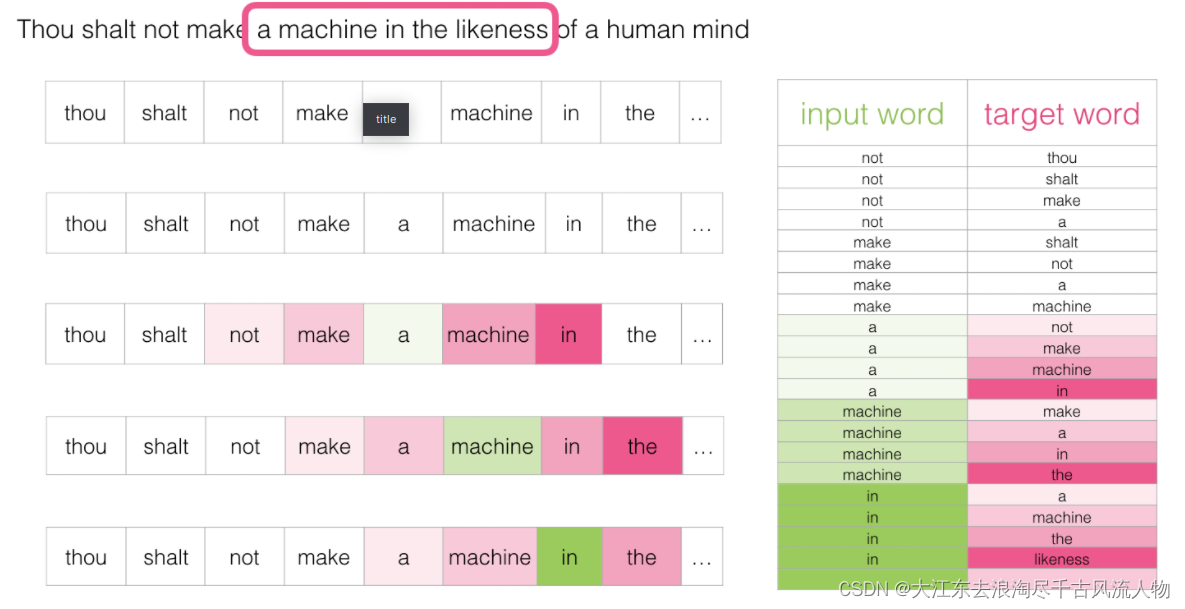
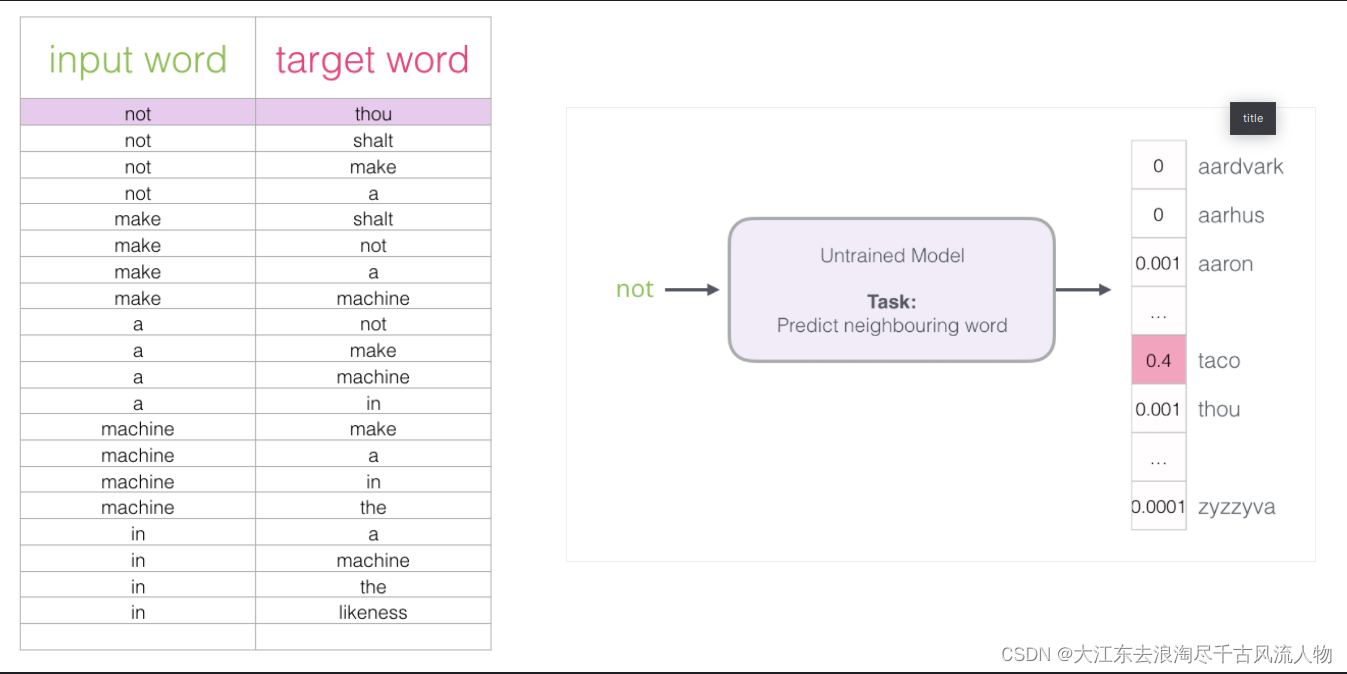
3.如何训练
3.1 如何设计驯联网络
如果一个语料库稍微大一些,可能的结果简直太多了,最后一层相当于softmax,计算起来十分耗时,有什么办法来解决嘛?
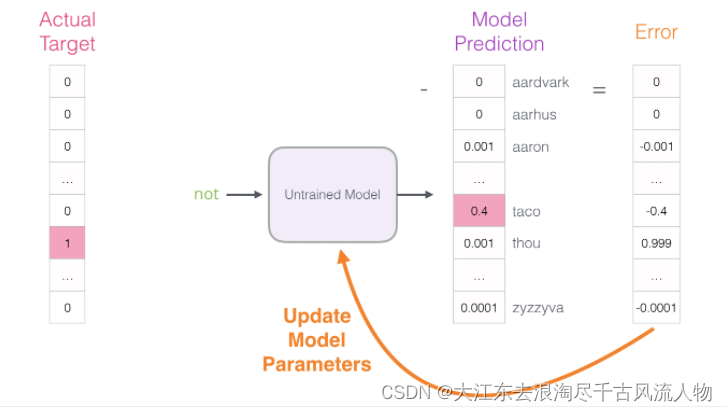
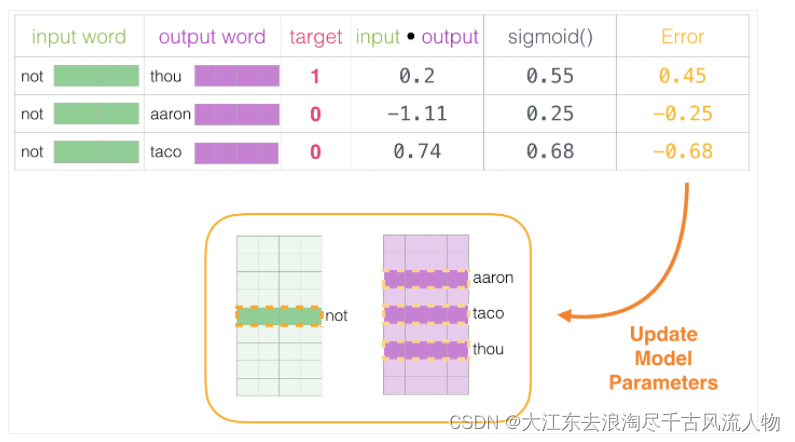
初始方案:输入两个单词,看他们是不是前后对应的输入和输出,也就相当于一个二分类任务,但是这样做之后

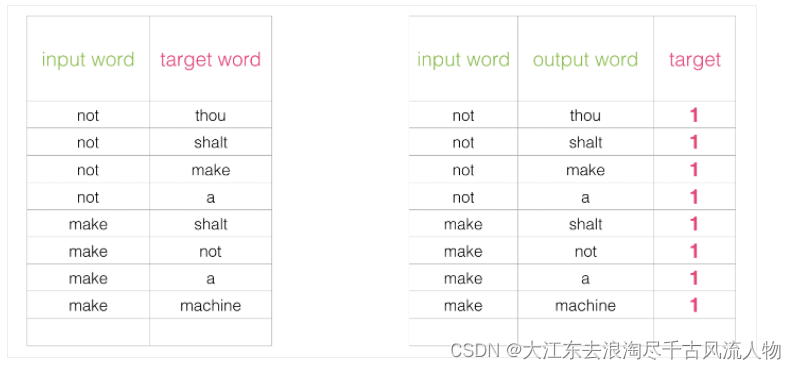
出发点非常好,但是此时训练集构建出来的标签全为1,无法进行较好的训练
3.2 改进方案:加入一些负样本(负采样模型)
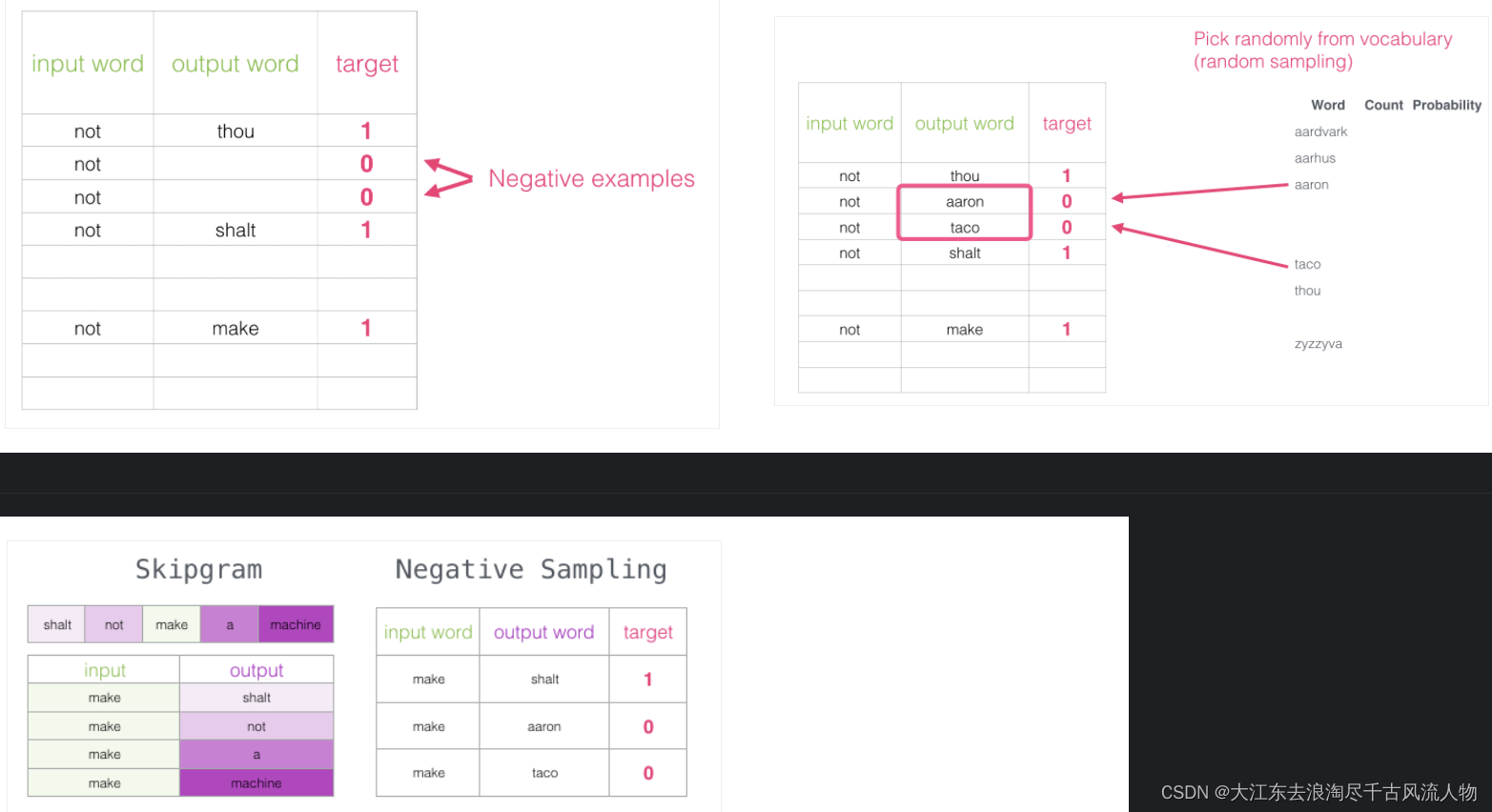
3.3 词向量训练过程
1.初始化词向量矩阵
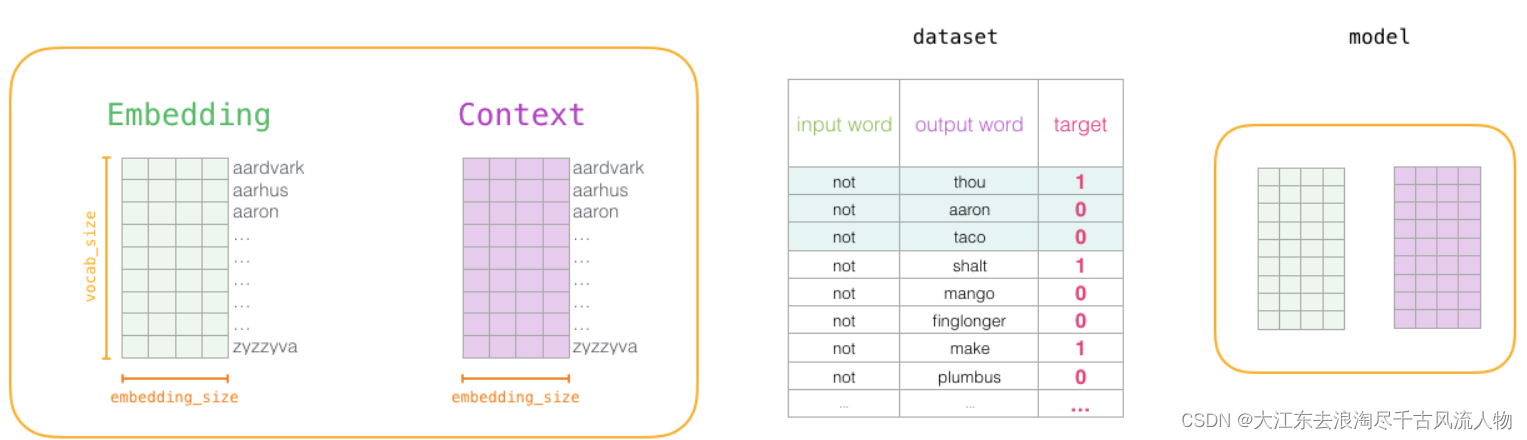
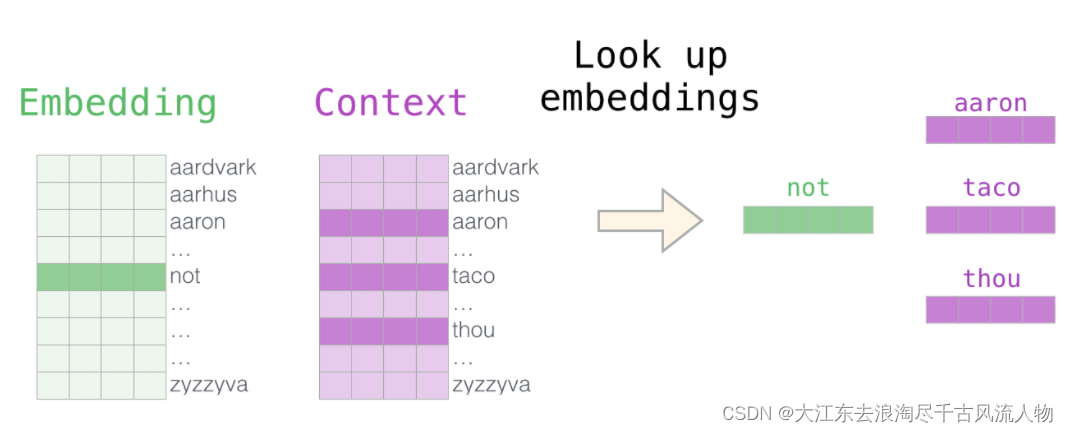
2.通过神经网络返向传播来计算更新,此时不光更新权重参数矩阵W,也会更新输入数据