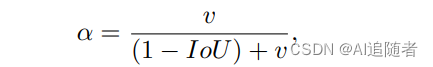SG-Former: Self-guided Transformer with Evolving Token Reallocation
1. Introduction
方法的核心是利用显著性图,根据每个区域的显著性重新分配tokens。显著性图是通过混合规模的自我关注来估计的,并在训练过程中自我进化。直观地说,我们将更多的tokens分配给显著区域,以实现细粒度的关注,而将更少的tokens分配到次要区域,以换取效率和全局感受场。

2. Method
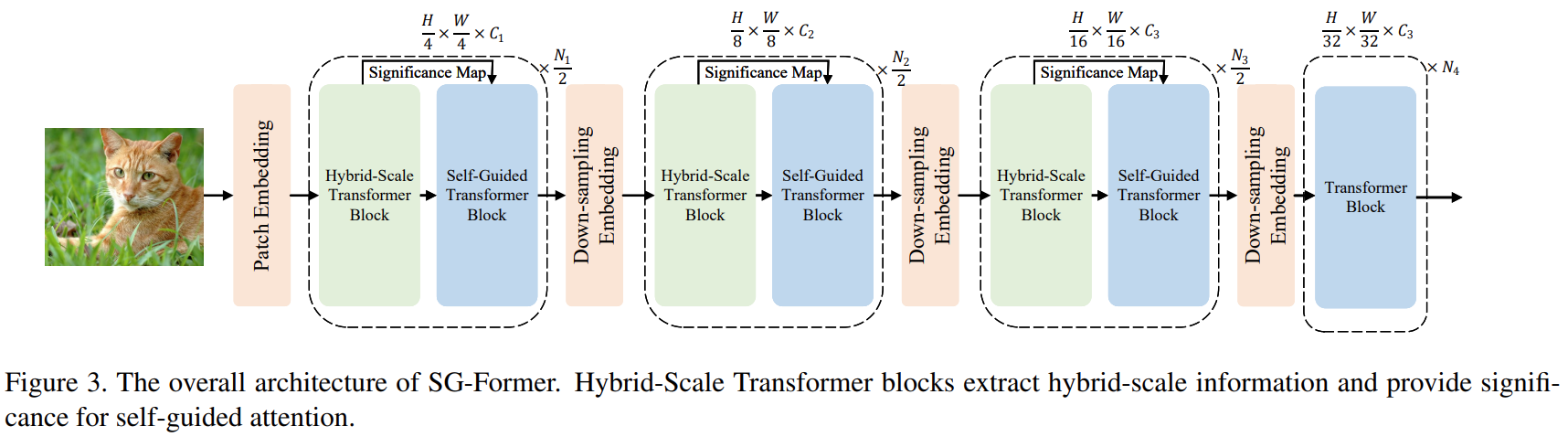
hybrid-scale Transformer block提取混合尺度对象和多粒度信息,指导区域重要性;self-guided Transformer block根据混合尺度Transformer块的显著性信息,在保持显著区域细粒度的同时,对全局信息进行建模。
2.1 Self-Guided Attention

通过将几个tokens合并为一个token聚合来减少序列长度这种减少注意力计算的聚合方法面临两个问题:(i)信息可能在显著区域丢失或与不相关的信息混合,(ii)在次要区域或背景区域,许多标记(序列的较高比例)对于简单语义是冗余的,同时需要大量计算。
输入特征图:![]() ,映射为Q、K、V
,映射为Q、K、V
然后H个相互独立的自注意力头平行的计算自注意力,为了计算注意力后保持特征图大小不变的同时降低计算成本,使用重要性引导聚合模块(IAM)固定Q的长度,但聚合K和V的tokens。
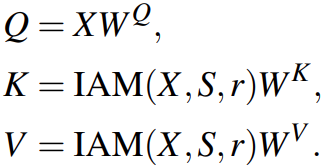
其中![]() 是significance map。将S的值生序排列,分为n个子区域
是significance map。将S的值生序排列,分为n个子区域![]() 。s1是最不重要的,Sn是最重要的。r是聚合率,每r个tokens聚合在一起。在不同重要性的区域设置了不同的聚合率r1,··,rn,使得每个子区域都有一个聚合率,并且子区域越重要,聚合率越小。
。s1是最不重要的,Sn是最重要的。r是聚合率,每r个tokens聚合在一起。在不同重要性的区域设置了不同的聚合率r1,··,rn,使得每个子区域都有一个聚合率,并且子区域越重要,聚合率越小。
IAM的目标是在显著区域将更少的令牌聚合为一(即,保留更多),在背景区域将更多的令牌聚合成一(即保留更少)。
然后:
![]()
F是聚合函数。

2.2 Hybrid-scale Attention
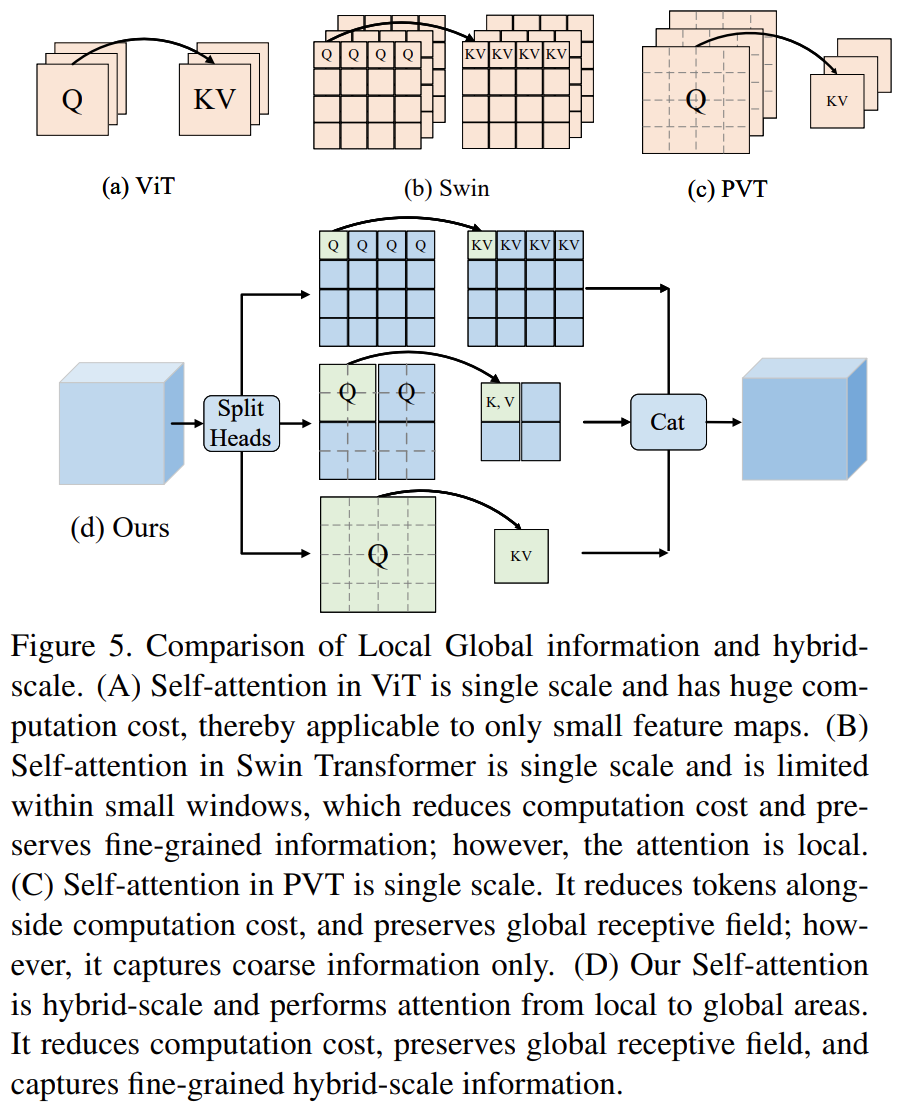
H个heads分成h组,每组H/h个heads。
将![]() 聚合成一个,Q不聚合,这样A和KV的数量不一样了,然后将QKV分窗口,窗口大小M,Q和KV数量不一样,所以Q的窗口大小是
聚合成一个,Q不聚合,这样A和KV的数量不一样了,然后将QKV分窗口,窗口大小M,Q和KV数量不一样,所以Q的窗口大小是![]() :
:
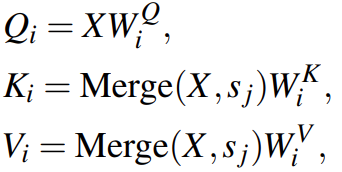
计算注意力:
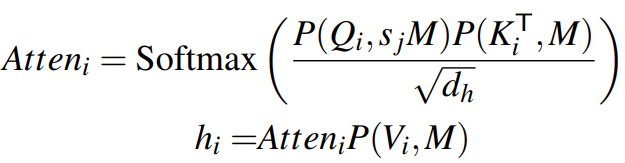
计算significance map:
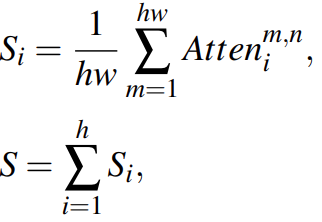
3 实验结果
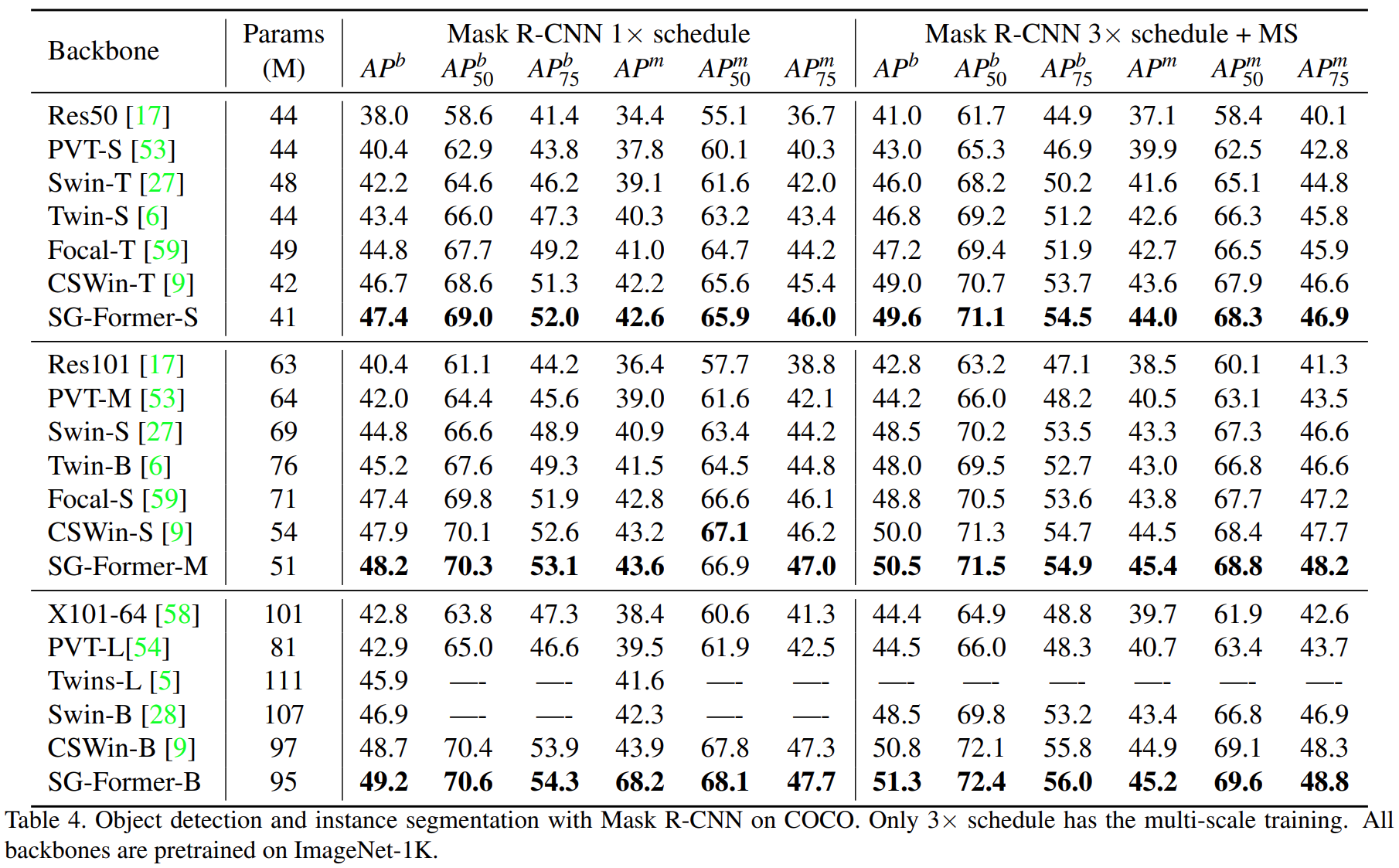

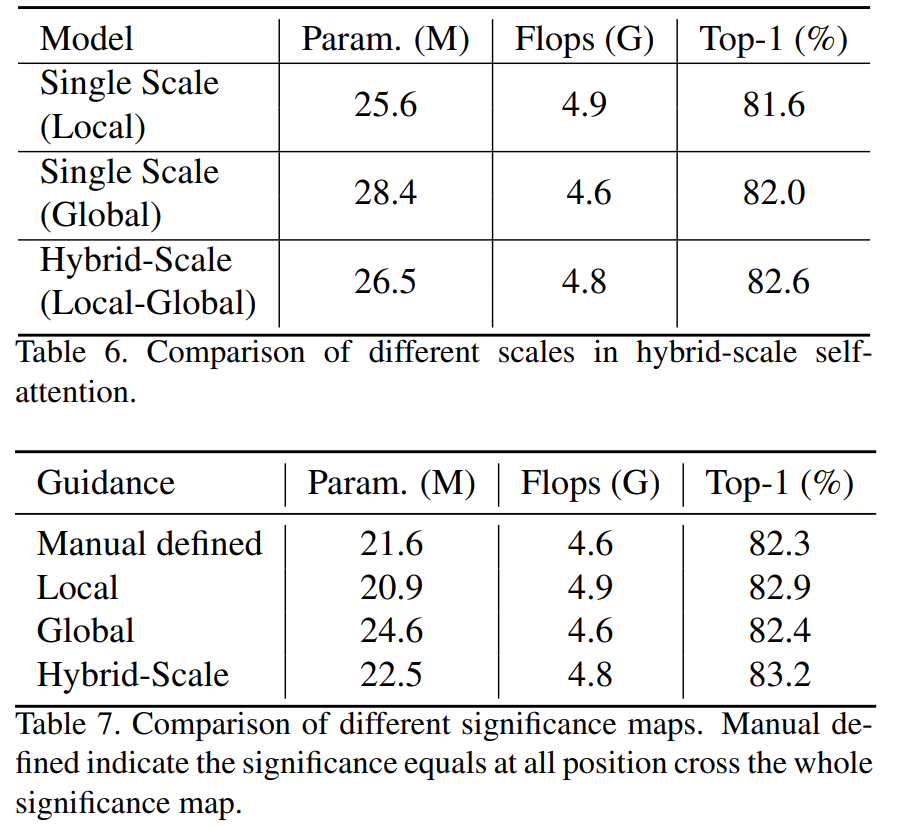
反正现在试的,这个模型比VIT快很多,计算量也少很多,但是不知道效果,实验结果还没出来。