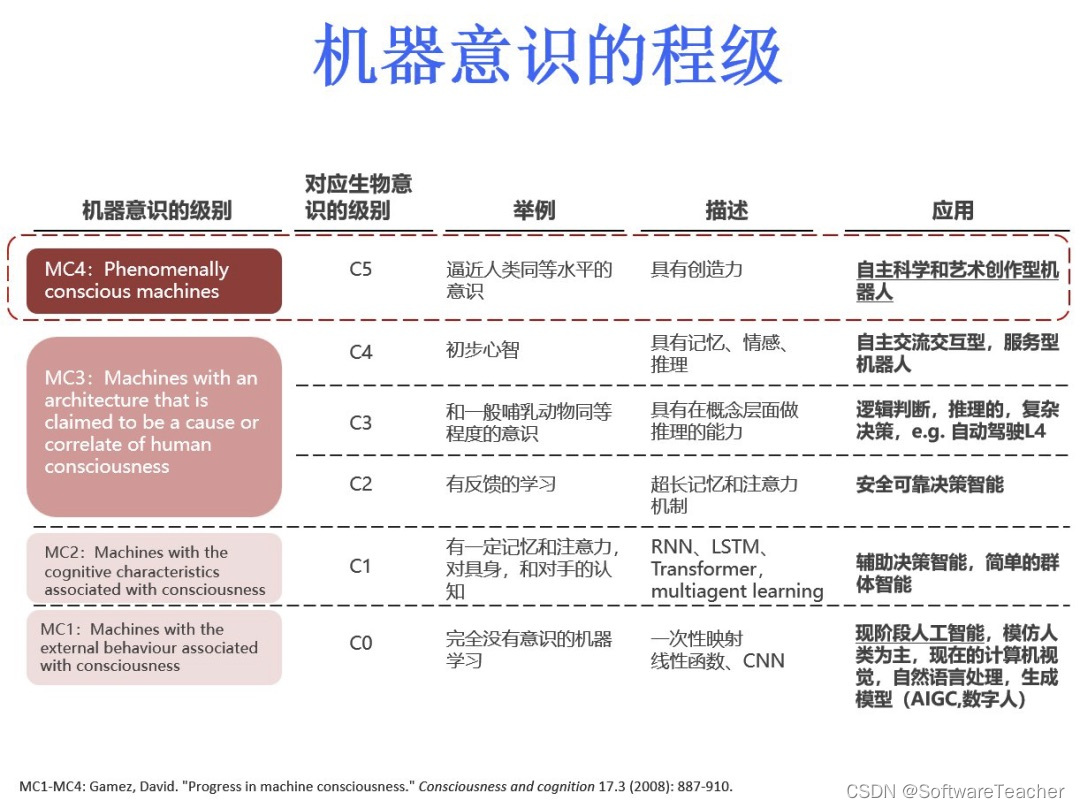
引言
GPT(Generative Pre-Trained Transformer)系列是OpenAI开发的一系列以Transformer[2]为基础的生成式预训练模型,这个系列目前包括文本预训练模型GPT-1[3],GPT-2[4],GPT-3[5],InstructGPT[7]、ChatGPT[8](这两个工作可以看作GPT-3.5的延伸),图像预训练iGPT[6],GPT-4[1]。
生成式任务主流的五种算法

图1 不同生成模型概览
生成任务的核心思想就是保证生成的样本的分布要与训练数据的分布接近,这样生成出来的数据和原有的数据就会十分相似,可以以假乱真的地步。当今深度学习领域最主流的模型包括自回归模型Autoregressive Model (AR)、生成对抗网络Generative Adversarial Network (GAN)、标准化流模型Normalizing Flow (Flow)、自编码器Auto-Encoder (AE)与变分自编码器Variational Auto-Encoder (VAE)、去噪扩散模型Denoising Diffusion Probablistic Model (Diffusion)等等。如图1所示 ,展示了不同模型的处理流程。为了避免出现大量的数学公式,这里只是形式化得说明不同生成框架的基本处理流程,如果大家对算法细节感兴趣,还是建议去阅读原始论文。
Generative Adversarial Network(GAN)
GAN由两部分组成,一个是生成器,一个是判别器。训练的时候,从一个先验分布中采样一个 ,输入到生成器中,得到一个样本。然后再从真实的数据集中采样出一些真实的样本,跟生成器生成的样本一起输入到判别器,由判别器来判断生成样本的真实度,以此来指导生成器的训练。理想状态下,生成器和判别器会达到一个均衡状态,此时,采样一个 ,输入到生成器里就可以得到一个比较好的样本。GAN从2014年发明以来,此类方法已经成为计算机视觉领域生成任务的主力,支配了图像生成、图像编辑、视频生成、视频编辑乃至超分降噪增强等领域,近几年Stylegan系列方法把GAN的效果推到了一个顶峰。不过GAN类的方法在NLP领域一直没有大火,这有可能跟GAN不太擅长处理离散空间有关,也有可能跟判断文本是真实的还是生成的这个任务更难有关(最近也有相关的工作去判断一段文本是不是由ChatGPT生成的,效果也比较一般)。
Auto-Encoder(AE)
Auto-Encoder是由两部分组成,一个是编码器,一个是解码器。Auto-Encoder也是利用自监督的方式,编码器负责将输入编码成一个latent code,然后解码器负责将latent code恢复成输入的原始状态。如果是在输入添加一个mask,在NLP领域就是大名鼎鼎的Bert,在CV领域就是MAE系列方法。2014年,Auto-Encoder的变体Variational Auto-Encoder被提出,其结构上很像Autoencoder,但是思想上更像是变分贝叶斯和图模型,不像是AE是把输入映射到一个固定维度的向量上,VAE则是映射到一个分布上。VAE方法至今仍活跃在CV领域,如VQ-VAE等。
Normalizing Flow(Flow)
在机器学习的问题中,想直接去做概率密度估计是非常难的 。考虑到深度学习的训练过程中,需要做反向传播,那么某些概率分布,比如后验概率就需要变得非常简单,这样才能高效、容易得计算导数。这就是为什么即使真实世界是非常复杂的,高斯分布还能广泛得应用在含有隐变量的生成模型中。Normalizing Flow是一种更好的更强大的概率分布近似方法,其通过应用一系列可逆的变换,将一个简单的分布映射成一个复杂的分布(其实思想上跟diffusion model有点类似)。其中比较有代表性的是openai的Glow ,和超分领域的SRFlow 。
Autoregressive Model(AR)
Autoregressive model,中文称为自回归模型,一般来说是单向的,比如放在NLP里,就是从左到右依次预测单词(当然也可以从右往左),比较有代表性的就是GPT系列,放在CV里就是按照像素的遍历顺序,依次预测像素值,比较有代表性的就是PixelRNN、PixelCNN等。如果与Auto-Encoder的方法作对比,Auto-encoder的方法基本上可以看到完整的上下文,即使是基于masked的方式,如bert,也是能看到整个语言序列或者整张图像的全局信息,而往往Autoregressive Model只能看到单向的信息,当然可能这种方式更符合人类说话的习惯。从现在的发展情况看,可能基于Auto-encoder的方法如bert、MAE这种,更适合做理解,做预训练模型,然后迁移到下游的任务,而基于Autoregressive的方法如GPT系列可能更适合做生成。
Diffusion Model
Diffusion Model的概念启发于non-equilibrium thermodynamics领域。包括两个过程,第一个过程从一张图像逐渐添加高斯噪声,最终完全变成一个noise图像,然后还有一个相反的过程,是从一张noise的图像中恢复出原始的图像。Diffusion Model里也有latent的概念,只不过是高维的,当然后续也有通过降低latent的维度来优化计算过程的,比如大名鼎鼎的stable diffusion。
从一个图像分布中采样一张图片,forward的过程是逐步向这张图片上加高斯噪声,每一步是由varaince beta控制的。因为使用了重参数化技巧,所以可以在任意的时间T,采样出这个表达的形式。这个过程可以类比朗之万动力学,朗之万随机梯度下降就是在sgd里添加随机的高斯噪声,避免走入local minimal。Reverse的过程则是从一个随机的高斯noise重建一张图片,经过一大波计算和简化,最终的目标变成了预测第T步的noise。此外,为了加速推理的过程,可以跳几步采样,比如DDIM。值得注意的是denoise用的模型是基于时间t的unet+cross attention机制,来灵活得处理不同的条件信息,比如class、语义图等。
Diffusion Model在最近两年已经成为CV生成领域最热门的方法。尤其是在多模态生成领域,如text-image生成上,基本上是获得了统治性的地位,诸如stable diffusion、dalle2等方法都大量使用了diffusion model。在单一的图像生成领域,Diffusion Model在生成的效果和多样性上也已经击败早年的一些GAN类方法。当然如果在封闭的数据集上,最新的一些GAN 方法也还是能匹配diffusion model的效果。当前的Diffusion Model依然面临在推理时需要消耗海量计算资源的问题,这也限制了其落地的场景。
总结
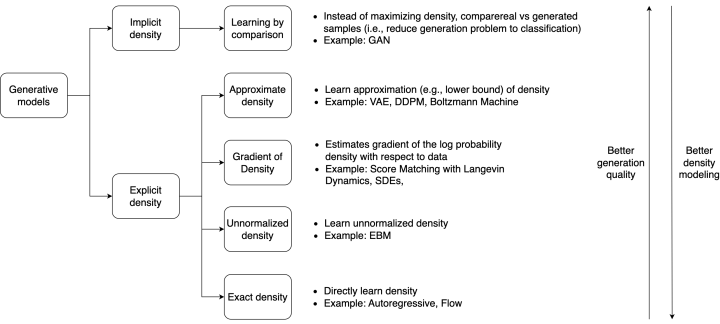
图2 生成任务算法分类
如图2所示,不同的生成任务的算法,可以按照其不同的特性分为这几类。注意,图中所说的更好的生成质量和更好的概率密度建模是考虑整体方法的平均能力,并不能代表特定任务的特定方法,比如现在有一些Diffusion Model就比一些GAN类方法的生成效果更好。此外,这些生成任务的算法并不是孤立的,互相排斥的,他们之前也完全可以相互结合,如VAE和Flow结合 ,Autoregressive和Flow结合 等等。
GPT发展史
GPT-1
长久以来,NLP领域的发展一直不如CV领域,主要原因是因为CV领域有百万级别且标注质量还不错的分类数据集ImageNet。CV领域以往都是在ImageNet上预训练一个分类模型,然后把backbone finetune到下游的数据上。相比而言,NLP领域一直都没有质量高的大型的有监督数据。此外,就算是同样一个样本,一张图片上的信息量是要远大于一句话,综合这些因素造成NLP领域发展相对缓慢。事实上,是从GPT-1开始,NLP领域才开始应用大规模的无监督数据做预训练,并迁移到下游的。当然本身这种做法在机器学习领域并不罕见,同样的做法至少可以追溯到2012年word2vec时期,只不过当时模型的参数量和数据的规模都没有现在这么大。
GPT-1跟更早的工作ELMo 在idea上基本是一致的,相当是一个数据量和计算量更大的ELMo,主要的区别一个是GPT-1的网络结构是多层transformer decoder如图3所示,而ELMo是双向LSTM,所以在网络结构上是完全没有创新的,第二个区别在于GPT-1在finetune迁移到下游任务的时候,不需要专门为了特定任务设计网络结果,而是直接在原有的base模型后接一个简单的线性层即可。

图3 GPT-1的transformer decoder
前面提到,GPT-1的训练过程分为两段,第一段是一个无监督训练,给定一个序列 , 是序列里第 个词汇,给定一个滑动窗口 ,第个词则是由前个词预测而来,符合前文介绍的Autoregressive模式。GPT-1使用标准语言建模来最大化该序列的概率:
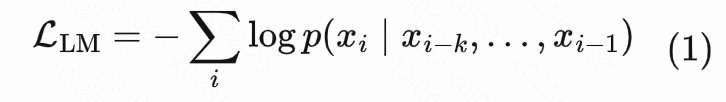
在第二个阶段,GPT-1利用半监督训练去迁移到下游任务。也就是在第一阶段的无监督训练的目标上,叠加下游的目标,比如如果是文本分类,就是在GPT-1的base model后面再接一个线性层,然后叠加的是一个普通的分类loss。那至于为什么在finetune阶段还需要把无监督的loss加上,论文给的解释是有两个好处,一个是能加快训练收敛的速度,一个是能提高监督模型的泛化能力。
顺便再八卦一句,GPT-1的一作就是第一次把GAN方法在图像生成上做出make sense结果的大名鼎鼎的DCGAN的作者,我现在依稀还记得,就是在2015年底,DCGAN横空出世,大家都被论文披露的效果惊艳到了,然后彻底引爆了学术界对GAN的兴趣,才有了从2016年开始乃至现在整个GAN领域的蓬勃发展。这个大佬同样是里程碑式的text-image多模态模型CLIP的一作,甚至连openai提出的强化学习算法PPO里,都有这个大佬的参与。这个大佬的工作横跨CV、NLP、强化学习,而且出品的都是顶级的工作,实在是令人惊叹。希望能在未来的GPT-4(据说会是一个多模态模型)中,看到这个大佬在这三个领域的顶级表现。
GPT-2
在GPT-1和GPT-2这两个工作之间,谷歌发布了Bert,更大的参数量、更大的数据量把GPT-1击败了。两者主要的区别在于Bert用的是Transformer的编码器,GPT-1用的是Transformer的解码器,预训练的过程中,Bert利用的是MAE,GPT-1是Autoregressive。然而,在这个情况下,GPT-2并没有变更技术路线,还是继续用解码器,用Autoregressive这种方式,然后把参数量提升到15亿(Bert最大也就3.4亿参数量),是前作GPT-1的10倍多,数据量也上升至百万量级。其实可以看到,从Bert、GPT-2开始,基本宣告了大公司NLP领域军备竞赛,后面NLP领域就开始涌现出一个又一个大力出奇迹的模型。
不过GPT-2这篇文章贡献点不只是在更大的参数量和更大的数据规模上,还关注了zero-shot learning。先前在NLP领域里,大家处理下游的任务,都是需要在新的任务上finetune的,而GPT-2是想不通过finetune,预训练的模型直接应用在下游任务上。解决这个问题的办法,是给下游的任务设计一个提示的方法 ,这个其实也算是prompt learning早期的应用之一。比如说,对一个下游的语言翻译任务来说,可以把输入的序列做成这样的形式 (translate to french, english text, french text),这个三元组分别就代表了任务、输入和输出。如果要做阅读理解,输入序列可以长成这样:(answer the question, document, question, answer)。然后通过模型自身强大的学习能力,去理解要去作这个下游任务。
GPT-3
GPT-2发布之后,就在社交媒体上引发了不小的热议,一方面,GPT-2确实能生成一些似是而非的文章、假新闻,让人分不清是不是这些内容是不是由AI撰写的,另一方面,在大部分的使用场景下,GPT-2还是会经常胡说八道(这个特点一直延续到了ChatGPT)。抛开zero-shot的任务,GPT-2在常规的NLP任务上相比于先前的方法并没有优势。可能zero-shot本身还是有点太极端了,所以GPT-3采用few-shot(每个任务10-100个有标签的样本)的方式,想在常规任务上达到一个好的效果。由于GPT-3将模型的参数量提升到了1750亿,batch size来到了320万(有钱真好啊),所以GPT-3的作者们在迁移到下游任务的时候依然不想去finetune整个网络,不想重新训练。

图4 GPT-3的fewshot learning的方法
如图4所示,GPT-3在作zero-shot任务的时候,是先告知一个具体的任务,然后再给一个prompt,在作one-shot任务的时候,其实就是把已知的带标签的样本,放在输入序列里,一起输入模型,所以fewshot任务其实也就是把有限的这几个有标签的数据全部放在输入序列中。这样一来,GPT-3可以不经过任何的finetune训练就可以吸收这些fewshot样本的知识,并且在推理的时候运用到。
GPT-3的效果相比于GPT-2来说提升太多了,所以其一经发布就在社交媒体上引起轩然大波。又因为GPT-3不需要重新训练就可以迁移到下游任务上,所以才可以让这么多用户凭借自己的创意玩起来,写新闻、搞翻译、写代码都不在话下,GPT-3官网上已知的应用都已经有好几百了。然而还是以前的老问题,GPT-3因为训练数据的问题,在性别、种族、宗教上都存在一些偏见,而且也沿袭了GPT系列的老传统,总是喜欢胡说八道,只不过相比于前几代,分辨GPT-3是不是在胡说八道的成本要大的多。
InstructGPT/ChatGPT
InstructGPT和ChatGPT是GPT-3和GPT-4之间的过渡模型,据Openai的披露,这两个工作的不同一个是在采集数据的方式上,ChatGPT因为任务不同,所以需要收集多轮的对话数据。另一个区别是InstructGPT是在GPT3上微调,ChatGPT是在GPT3.5上微调,除此之外技术原理基本上是一致的。由于ChatGPT并没有公开的论文,所以要搞懂ChatGPT,我们必须要先读懂InstructGPT。
我们回顾一下GPT系列的训练目标,是给定前面的一些单词系列,预测下一个单词。而用户在实际的使用过程中,是想要通过人类的指示,得到安全、可信、有帮助的答案。从这个地方可以看到,GPT-系列的训练目标,跟用户的意图是不匹配的。所以InstructGPT就是为了解决训练目标和用户意图之间的alignment的问题。InstructGPT解决这个alignment的技术就是RLHF(reinforcement learning from human feadback)。
如图5所示,InstructGPT的训练过程分为以下三个阶段:
第一阶段:训练监督模型
让人类标注人员写一些问题,比如“向一个小孩子解释什么是月亮”,这种问题有些是标注人员自己想的,有些是从已有的数据集里抽取的,也有一些是来自以往GPT3收到的问题请求。这些问题就构成了prompt。然后再由人类标注人员,给这些问题写答案,这就构建了一个有监督的数据集。GPT-3使用这些有监督的数据去finetune,获得SFT模型, Supervised Fine-Tuning。此时的SFT模型在遵循指令/对话方面已经优于 GPT-3,但不一定符合人类偏好。

居中图5 InstructGPT的训练流程
第二阶段:训练奖励模型(Reward Mode,RM)
reinforcement learning from human feadback,顾名思义,是用人类的反馈指导强化学习训练。然而,在强化学习里,非常重要的概念叫reward,强化学习的目标就是为了达成最大的reward。这个reward本身是非常难定义的,把人类引入进来,在模型作生成的时候,人类对模型的输出 做一个评价,可以当作reward指导强化学习训练。但是事实上,不可能在模型训练的时候找一个人,专门盯着模型,模型输出一个 就作一个评价,这种方式时间上效率实在是太低了。所以首先需要从人类的反馈中,先学习一个reward网络。
具体的做法是在数据集中随机抽取问题,然后对每一个问题都生成 个答案,在原文里 ,然后由人类对这9个答案进行排序。在得到9个答案的排序名次之后,抽取里面任意两个答案用pair-wise ranking loss进行训练,这里的做法跟metric learning、检索、计算美学里的完全一样,基本的思路就是让同一个问题下,排序靠前的回答得分更高,排序较低的回答得分更低。

值得注意的是,这个过程中只是用了3.3万个人工标注的数据,这个成本是相当低的,所以这个思路完全可以借鉴到大家自己的任务中去。
第三阶段:采用PPO(Proximal Policy Optimization)结合无监督的目标进行优化
如公式(3)所示,第一行是PPO的目标,第二行是通用的语言模型目标(根据前 个的词预测当前的词)。PPO的目标也由两部组成,左边那部分就是第二阶段提到的reward model,目的是让网络输出的回答的评分越高越好,右边那部分是度量KL散度,让优化后的模型的输出跟优化前模型的数据尽可能接近,避免结果跑偏。
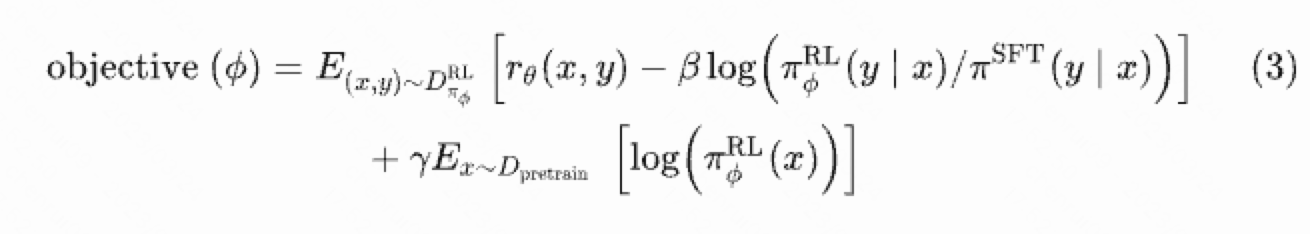
至此,已经梳理完毕InstructGPT的核心技术,但是跟InstructGPT不同的是,ChatGPT有很强大的上下文语义的理解能力,可以进行质量很高的多轮对话,这项能力背后的技术没有在Openai的官方信息中得到体现,有人猜测这个技术可能跟谷歌的Chain of Thought有关。
参考文献
[1] https://www.searchenginejournal.com/openai-gpt-4/476759/.
[2] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[3] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018.
[4] Radford A, Wu J, Child R, et al. Language models are unsupervised multitask learners[J]. OpenAI blog, 2019, 1(8): 9.
[5] Brown T, Mann B, Ryder N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901.
[6] Chen M, Radford A, Child R, et al. Generative pretraining from pixels[C]//International conference on machine learning. PMLR, 2020: 1691-1703.
[7] Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. arXiv preprint arXiv:2203.02155, 2022.
[8] https://openai.com/blog/chatgpt/.
[9] Wei J, Bosma M, Zhao V Y, et al. Finetuned language models are zero-shot learners[J]. arXiv preprint arXiv:2109.01652, 2021.
[10] Christiano P F, Leike J, Brown T, et al. Deep reinforcement learning from human preferences[J]. Advances in neural information processing systems, 2017, 30.