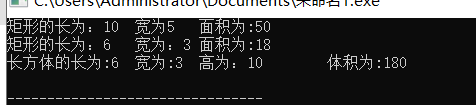
人类大脑有数百亿个相互连接的神经元(如下图(a)所示),这些神经元通过树突从其他神经元接收信息,在细胞体内综合、并变换信息,通过轴突上的突触向其他神经元传递信息。我们在博文《最优化方法Python计算:无约束优化应用——逻辑回归模型》中讨论的逻辑回归模型(如下图(b)所示)与神经元十分相似,由输入端接收数据 x = ( x 1 x 2 ⋮ x n ) \boldsymbol{x}=\begin{pmatrix} x_1\\x_2\\\vdots\\x_n \end{pmatrix} x= x1x2⋮xn ,作加权和 ∑ i = 1 n w i x i \sum\limits_{i=1}^nw_ix_i i=1∑nwixi加上偏移量 b b b,即 ∑ i = 1 n w i x i + b \sum\limits_{i=1}^nw_ix_i+b i=1∑nwixi+b,用逻辑函数将其映射到区间 ( 0 , 1 ) (0,1) (0,1)内,然后将如此变换所得的信息 y y y输出。

这启发人们将诸多逻辑回归模型分层连接起来,构成人工神经网络,创建出多层感应模型。下图展示了一个包括输入层、输出层和两个隐藏层(图中阴影部分)的人工神经网络。图中,黑点表示数据节点,圆圈表示人工神经元的处理节点。

记逻辑函数 sigmoid ( x ) = 1 1 + e − x = φ ( x ) \text{sigmoid}(x)=\frac{1}{1+e^{-x}}=\varphi(x) sigmoid(x)=1+e−x1=φ(x)。设多层感应模型的输入数据为 n n n维向量 x = ( x 1 x 2 ⋮ x n ) \boldsymbol{x}=\begin{pmatrix} x_1\\x_2\\\vdots\\x_n \end{pmatrix} x= x1x2⋮xn 。不算输入层,模型连同输出层及隐藏层共有 l l l层。记 m 0 = n m_0=n m0=n,第 i i i层( 0 < i ≤ l 0<i\leq l 0<i≤l)含有 m i m_i mi个神经元。于是,相邻的两层,第 i − 1 i-1 i−1和第 i i i之间共有 ( m i − 1 + 1 ) m i (m_{i-1}+1)m_{i} (mi−1+1)mi个待定参数。因此,模型具有
p = ∑ i = 1 l ( m i − 1 + 1 ) m i p=\sum_{i=1}^l(m_{i-1}+1)m_i p=i=1∑l(mi−1+1)mi
个待定参数,组织成 p p p维向量 w = ( w 1 w 2 ⋮ w p ) \boldsymbol{w}=\begin{pmatrix} w_1\\w_2\\\vdots\\w_p \end{pmatrix} w= w1w2⋮wp 。设 k 0 = 0 k_0=0 k0=0,对 1 < i ≤ l 1<i\leq l 1<i≤l, k i = ∑ t = 0 i − 1 ( m t + 1 ) m t + 1 k_i=\sum\limits_{t=0}^{i-1}(m_{t}+1)m_{t+1} ki=t=0∑i−1(mt+1)mt+1,记 ( m i − 1 − 1 ) × m i (m_{i-1}-1)\times m_i (mi−1−1)×mi矩阵
w i = ( w k i + 1 ⋯ w k i + ( m i − 1 + 1 ) ( m i − 1 ) + 1 ⋮ ⋱ ⋮ w k i + ( m i − 1 + 1 ) ⋯ w k i + ( m i − 1 + 1 ) m i ) , i = 1 , 2 ⋯ , l \boldsymbol{w}_i=\begin{pmatrix} w_{k_i+1}&\cdots&w_{k_i+(m_{i-1}+1)(m_i-1)+1}\\ \vdots&\ddots&\vdots\\ w_{k_i+(m_{i-1}+1)}&\cdots&w_{k_i+(m_{i-1}+1)m_i} \end{pmatrix}, i=1,2\cdots,l wi= wki+1⋮wki+(mi−1+1)⋯⋱⋯wki+(mi−1+1)(mi−1)+1⋮wki+(mi−1+1)mi ,i=1,2⋯,l
定义函数
F ( w ; x ) = φ ( ( ⋯ φ ⏟ l ( ( x ⊤ , 1 ) w 1 ) , 1 ) , ⋯ ) , 1 ) w l ) . F(\boldsymbol{w};\boldsymbol{x})=\underbrace{\varphi((\cdots\varphi}_l((\boldsymbol{x}^\top,1)\boldsymbol{w}_1),1),\cdots),1)\boldsymbol{w}_l). F(w;x)=l φ((⋯φ((x⊤,1)w1),1),⋯),1)wl).
该函数反映了数据从输入层到输出层的传输方向,称为前向传播函数,作为多层感应模型的拟合函数。按此定义,我们构建如下的多层感应模型类
import numpy as np #导入numpy
class MLPModel(LogicModel): #多层感应模型def construct(self, X, hidden_layer_sizes): #确定网络结构if len(X.shape)==1: #计算输入端节点数k = 1else:k = X.shape[1]self.layer_sizes = (k,)+hidden_layer_sizes+(1,) def patternlen(self): #模式长度p = 0l = len(self.layer_sizes) #总层数for i in range(l-1): #逐层累加m = self.layer_sizes[i]n = self.layer_sizes[i+1]p += (m+1)*nreturn pdef F(self, w, x): #拟合函数l = len(self.layer_sizes) #总层数m, n = self.layer_sizes[0],self.layer_sizes[1]k = (m+1)*n #第0层参数个数W = w[0:k].reshape(m+1,n) #0层参数折叠为矩阵z = LogicModel.F(self, W, x) #第1层的输入for i in range(1, l-1): #逐层计算m = self.layer_sizes[i] #千层节点数n = self.layer_sizes[i+1] #后层节点数W = w[k:k+(m+1)*n].reshape(m+1,n) #本层参数矩阵z = np.hstack((z, np.ones(z.shape[0]). #本层输入矩阵reshape(z.shape[0], 1)))z = LogicModel.F(self, W, z) #下一层输入k += (m+1)*n #下一层参数下标起点y = z.flatten() #展平输出return ydef fit(self, X, Y, w = None, hidden_layer_sizes = (100,)): #重载训练函数self.construct(X, hidden_layer_sizes)LogicModel.fit(self, X, Y, w)
class MLPRegressor(Regression, MLPModel):'''神经网络回归模型'''
MLPModel继承了LogicModel类(详见博文《最优化方法Python计算:无约束优化应用——逻辑回归模型》)在MLPModel中除了重载模式长度计算函数patternlen、拟合函数F和训练函数fit外,增加了一个LogicModel类所没有的对象函数construct,用来确定神经网络的结构:有少层,各层有多少个神经元。
具体而言,第3~8行的construct函数,利用传递给它的输入矩阵X和隐藏层结构hidden_layer_sizes,这是一个元组,计算神经网络的各层结构。第4~7行的if-else分支按输入数据X的形状确定输入层的节点数k。第8行将元组(k,1)和(1,)分别添加在hidden_layer_sizes的首尾两端,即确定了网络结构layer_sizes。
第9~16行重载了模式长度计算函数patternlen。第11行根据模型的结构元组layer_sizes的长度确定层数l。第12~15行的for循环组成计算各层的参数个数:m为前层节点数(第13行),n为后层节点数(第14行),则第15行中(m+1)*n就是本层的参数个数,这是因为后层的每个节点的输入必须添加一个偏移量。第16行将算得的本层参数个数累加到总数p(第10行初始化为0)。
第17~32行重载拟合函数F,参数中w表示模式 w ∈ R p \boldsymbol{w}\in\text{R}^p w∈Rp,x表示自变量 ( x ⊤ , 1 ) (\boldsymbol{x}^\top,1) (x⊤,1)。第18行读取网络层数l。第19~22行计算第1隐藏层的输入:第19行读取第0层节点数m第1隐藏层节点数n。第20行计算第0层参数个数k(也是第1层参数下标起点)。第22行构造第0层的参数矩阵W。第22行计算 φ ( ( x ⊤ , 1 ) w 1 ) \varphi((\boldsymbol{x}^\top,1)\boldsymbol{w}_1) φ((x⊤,1)w1),作为第1隐藏层的输入z。第23~20行的for循环依次逐层构造本层参数矩阵 w i \boldsymbol{w}_i wi(第26行)和输入 ( z i ⊤ , 1 ) (\boldsymbol{z}_i^\top,1) (zi⊤,1)(第27~28行),第30行计算下一层的输入 φ ( ( z i ⊤ , 1 ) w i ) \varphi((\boldsymbol{z}_i^\top,1)\boldsymbol{w}_i) φ((zi⊤,1)wi)为z,第30行更新下一层参数下标起点k。完成循环,所得y因为是矩阵运算的结果,第31层将其扁平化为一维数组。第33~35行重载训练函数fit。与其祖先LogicModel的(也是LineModel)fit函数相比,多了一个表示网络结构的参数hidden_layer_sizes。如前所述,这是一个元组,缺省值为(100,),意味着只有1个隐藏层,隐藏层含100个神经元。函数体内第34行调用自身的construct函数,构造网络结构layer_sizes,供调用拟合函数F时使用。第35行调用祖先LogicModel的fit函数完成训练。
第36~37用Regression类和MLPModel类联合构成用于预测的多层感应模型类MLPRegressor。
理论上,只要给定足够多的隐藏层和层内所含神经元,多层感应模型能拟合任意函数。
例1 用MLPRegressor对象拟合函数 y = x 2 y=x^2 y=x2。
解:先构造训练数据:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import uniform
np.random.seed(2023)
x = uniform.rvs(-1, 2, 50)
y = (x**2)
plt.scatter(x, y)
plt.show()
第5行产生50个服从均匀分布 U ( 0 , 1 ) U(0,1) U(0,1)的随机数值,赋予x。第6行计算x的平方赋予y。第7行绘制 ( x , y ) (x,y) (x,y)散点图。

用仅含一个隐藏层,隐藏层中包含3个神经元的多层感应器拟合 y = x 2 y=x^2 y=x2
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import uniform
.random.seed(2023)
x = uniform.rvs(-1, 2, 50)
y = (x**2)
nnw = MLPRegressor()
nnw.fit(x,y,hidden_layer_sizes = (3,))
yp, acc = nnw.test(x, y)
plt.scatter(x, yp)
plt.show()
print('1隐藏层含3个神经元网络拟合均方根误差%.4f'%acc)
前5行与前同。第6行创建MLPRegressor类对象nnw。第7行用x,y训练nnw为含1个隐藏层,隐藏层含3个神经元的神经网络。第8行调用nnw的test函数,用返回的yp绘制 ( x , y p ) (x,y_p) (x,yp)散点图。

训练中...,稍候
726次迭代后完成训练。
1隐藏层含3个神经元网络拟合均方根误差0.0238
用含两个隐藏层,分别包含7个、3个神经元的多层感应器拟合 y = x 2 y=x^2 y=x2
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import uniform
.random.seed(2023)
x = uniform.rvs(-1, 2, 50)
y = (x**2)
nnw = MLPRegressor()
nnw.fit(x, y, hidden_layer_sizes = (7, 3))
yp, acc = nnw.test(x,y)
plt.scatter(x, yp)
plt.show()
print('2隐藏层含各7,3个神经元网络拟合方根误差%.4f'%acc)
与上一段代码比较,仅第8行训练nnw的网络换成两个隐藏层,分别包含7个、3个神经元的多层感应器。运行程序,输出

训练中...,稍候
1967次迭代后完成训练。
2隐藏层含各7,3个神经元网络拟合方根误差0.0053
比前一个显然拟合得更好,但也付出了计算时间的代价。
Say good bye, 2023.