🌈🌈🌈🌈🌈🌈🌈🌈
欢迎关注公众号(通过文章导读关注),发送【资料】可领取 深入理解 Redis 系列文章结合电商场景讲解 Redis 使用场景、中间件系列笔记和编程高频电子书!
【11来了】文章导读地址:点击查看文章导读!
🍁🍁🍁🍁🍁🍁🍁🍁
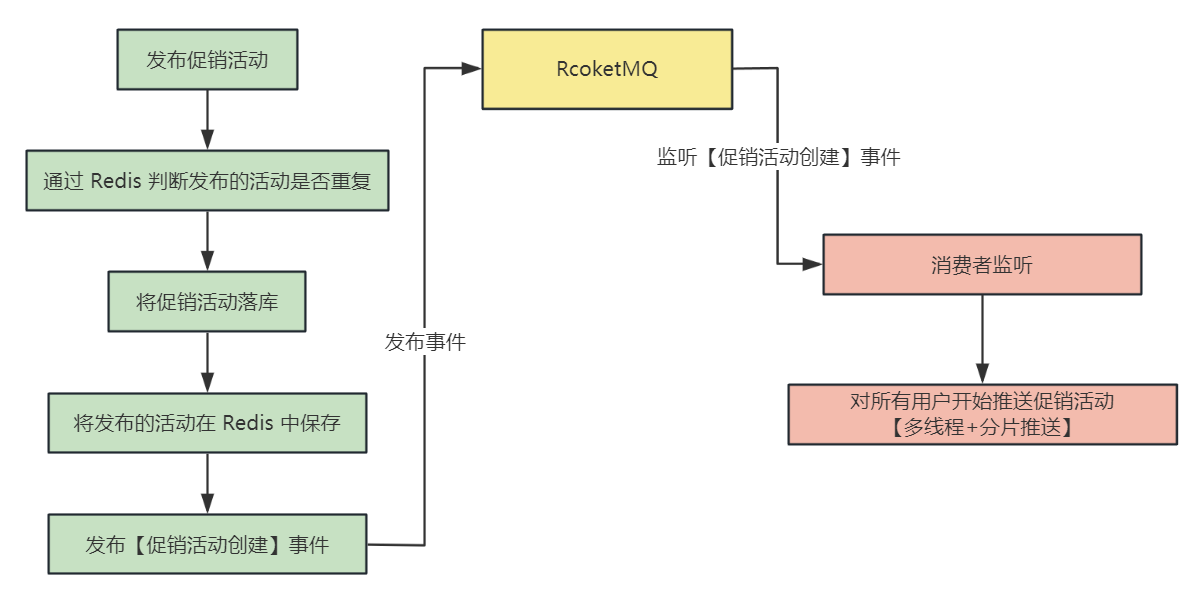
首先介绍一下发布促销活动的整体业务流程:
-
运维人员操作页面发布促销活动
-
判断促销活动是否和以往活动发布重复
-
先将促销活动落库
-
发布【促销活动创建】事件
-
消费者监听到【促销活动创建】事件,开始对所有用户推送促销活动
由于用户量很大,这里使用
多线程 + 分片推送来大幅提升推送速度
整个流程中的主要技术难点就在于:多线程 + 分片推送
整体的流程图如下:
接下来,开始根据流程图中的各个功能来介绍代码如何实现:
通过 Redis 判断发布的活动是否重复
通过将已经发布的促销活动先保存在 Redis 中,避免短时间内将同一促销活动重复发布
Redis 中存储的 key 的设计:promotion_Concurrency + [促销活动名称] + [促销活动创建人] + [促销活动开始事件] + [促销活动结束时间]
如果一个促销活动已经发布,那么就将这个促销活动按照这个 key 存储进入 Redis 中,value 的话,设置为 UUID 即可
过期时间 的设置:这里将过期时间设置为 30 分钟
通过 MQ 发送【促销活动创建】事件
这里发布促销活动创建事件的时候,消息中存放的数据使用了一个事件类进行存储,这个事件类中只有一个属性,就是促销活动的实体类:
/*** 促销活动创建事件,用于 MQ 传输*/
@Data
public class SalesPromotionCreatedEvent {// 促销活动实体类private SalesPromotionDO salesPromotion;
}
那么通过消费者监听到【促销活动创建】事件之后,就会进行 用户推送 的动作
如何实现用户分片 + 多线程推送
首先来了解一下为什么要对用户进行分片:在电商场景中用户的数量是相当庞大的,中小型电商系统的用户数量都可以达到千万级,那么如果给每一个用户都生成一条消息进行 MQ 推送,这个推送的时间相当漫长,必须优化消息推送的速度,因此将多个用户 合并成一个分片 来进行推送,这样消耗的时间可能还有些久,就再将多个分片 合并成一条消息,之后再将合并后的消息通过 多线程 推送到 MQ 中,整个优化流程如下:
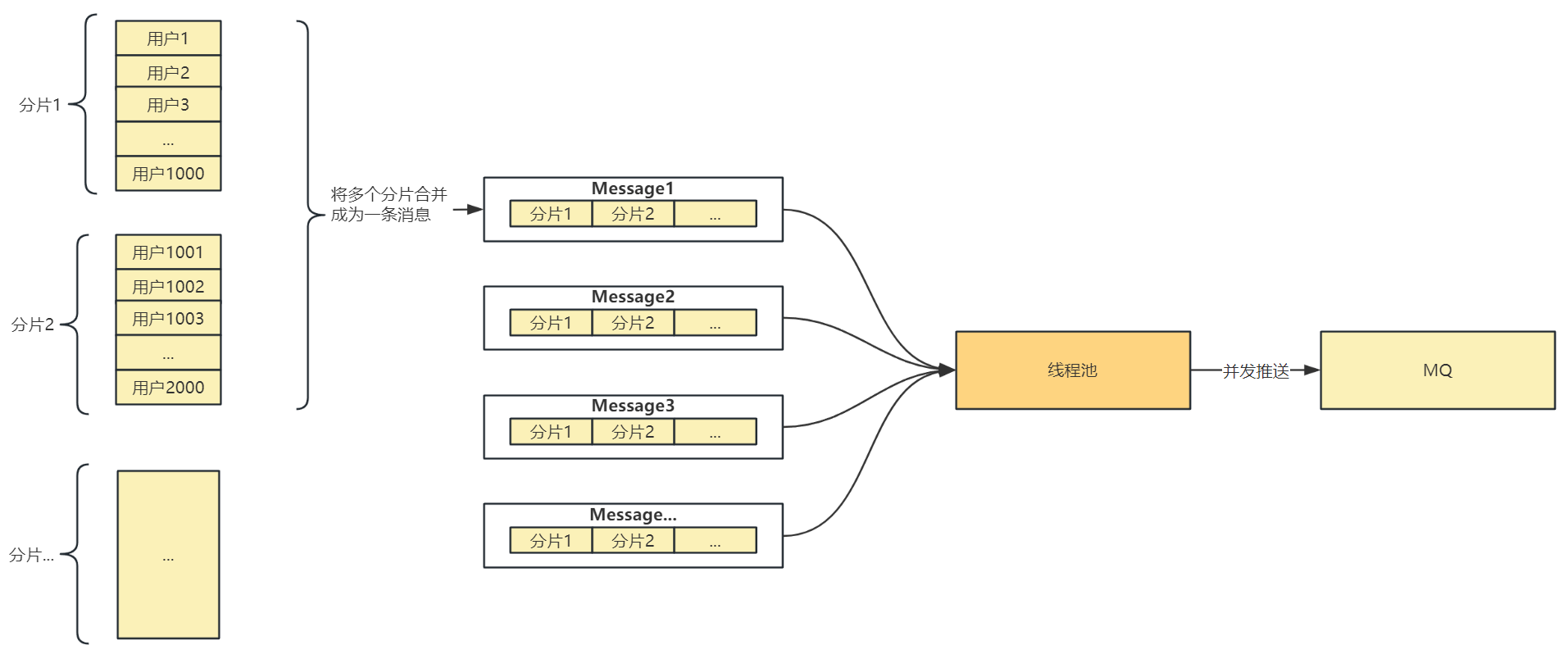
接下来说一下分片中具体的实现:
首先对用户分片的话,需要知道用户的总数,并且设置好每个分片的大小,才可以将用户分成一个个的分片
获取用户总数的话,假设用户表中 id 是自增的,那么直接从用户表中拿到最大的 用户 id 作为用户总数即可,用户总数不需要非常准确,某个分片多几个少几个影响不大,将每个分片大小设置为 1000,也就是一个分片存放 1000 个用户 id
那么分片操作就是创建一个 Map<Long, Long> userBuckets = LinkedHashMap<Long, Long>(),将每一个分片的用户起使 id 和结束 id 放入即可
之后再将多个用户分片给合并为一条消息,这里合并的时候保证一条消息不超过 1MB(RocketMQ 官方推荐),首先将需要推送的一个个分片给生成一个 JSON 串,表示一个个的推送任务,将所有推送任务放入到 List 集合中,接下来去遍历 List 集合进行多个分片的合并操作,List 集合中存储的是一个个分片任务的 String 串,只需要拿到 String 串的长度,比如说长度为 200,那么这个 String 串占用的空间为 200B,累加不超过 1MB,就将不超过 1MB 的分片合并为一条消息,代码如下:
@Slf4j
@Component
public class SalesPromotionCreatedEventListener implements MessageListenerConcurrently {@DubboReference(version = "1.0.0")private AccountApi accountApi;@Resourceprivate DefaultProducer defaultProducer;@Autowired@Qualifier("sharedSendMsgThreadPool")private SafeThreadPool sharedSendMsgThreadPool;@Overridepublic ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> list, ConsumeConcurrentlyContext consumeConcurrentlyContext) {try {for(MessageExt messageExt : list) {// 这个代码就可以拿到一个刚刚创建成功的促销活动String message = new String(messageExt.getBody());SalesPromotionCreatedEvent salesPromotionCreatedEvent =JSON.parseObject(message, SalesPromotionCreatedEvent.class);// 将消息中的数据解析成促销活动实体类SalesPromotionDO salesPromotion = salesPromotionCreatedEvent.getSalesPromotion();// 为了这个促销活动,针对全体用户发起push// bucket,就是一个用户分片,这里定义用户分片大小final int userBucketSize = 1000;// 拿到全体用户数量,两种做法,第一种是去找会员服务进行 count,第二种是获取 max(userid),自增主键JsonResult<Long> queryMaxUserIdResult = accountApi.queryMaxUserId();if (!queryMaxUserIdResult.getSuccess()) {throw new BaseBizException(queryMaxUserIdResult.getErrorCode(), queryMaxUserIdResult.getErrorMessage());}Long maxUserId = queryMaxUserIdResult.getData();// 上万条 key-value 对,每个 key-value 对就是一个 startUserId->endUserId,推送任务分片Map<Long, Long> userBuckets = new LinkedHashMap<>(); // // 数据库自增主键是从1开始的long startUserId = 1L; // 这里对所有用户进行分片,将每个分片的 <startUserId, endUserId> 都放入到 userBuckets 中Boolean doSharding = true;while (doSharding) {if (startUserId > maxUserId) {doSharding = false;break;}userBuckets.put(startUserId, startUserId + userBucketSize);startUserId += userBucketSize;}// 提前创建一个推送的消息实例,在循环中直接设置 startUserId 和 endUserId,避免每次循环都去创建一个新对象PlatformPromotionUserBucketMessage promotionPushTask = PlatformPromotionUserBucketMessage.builder().promotionId(salesPromotion.getId()).promotionType(salesPromotion.getType()).mainMessage(salesPromotion.getName()).message("您已获得活动资格,打开APP进入活动页面").informType(salesPromotion.getInformType()).build();// 将需要推送的消息全部放到这个 List 集合中List<String> promotionPushTasks = new ArrayList<>();for (Map.Entry<Long, Long> userBucket : userBuckets.entrySet()) {promotionPushTask.setStartUserId(userBucket.getKey());promotionPushTask.setEndUserId(userBucket.getValue());String promotionPushTaskJSON = JsonUtil.object2Json(promotionPushTask);promotionPushTasks.add(promotionPushTaskJSON);}log.info("本次推送消息用户桶数量, {}",promotionPushTasks.size());// 将上边 List 集合中的推送消息进行合并,这里 ListSplitter 的代码会在下边贴出来ListSplitter splitter = new ListSplitter(promotionPushTasks, MESSAGE_BATCH_SIZE);while(splitter.hasNext()){List<String> sendBatch = splitter.next();log.info("本次批次消息数量,{}",sendBatch.size());// 将多个分片合并为一条消息,提交到线程池中进行消息的推送sharedSendMsgThreadPool.execute(() -> {defaultProducer.sendMessages(RocketMqConstant.PLATFORM_PROMOTION_SEND_USER_BUCKET_TOPIC, sendBatch, "平台优惠活动用户桶消息");});}}} catch(Exception e) {log.error("consume error, 促销活动创建事件处理异常", e);return ConsumeConcurrentlyStatus.RECONSUME_LATER;}return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}
}
其中实现将分片合并的代码 ListSplitter 如下:
public class ListSplitter implements Iterator<List<String>> {// 设置每一个batch最多不超过800k,因为rocketmq官方推荐,不建议长度超过1MB,// 而封装一个rocketmq的message,包括了messagebody,topic,addr等数据,所以我们这边儿设置的小一点儿private int sizeLimit = 800 * 1024;private final List<String> messages;private int currIndex;private int batchSize = 100;public ListSplitter(List<String> messages, Integer batchSize) {this.messages = messages;this.batchSize = batchSize;}public ListSplitter(List<String> messages) {this.messages = messages;}@Overridepublic boolean hasNext() {return currIndex < messages.size();}// 每次从list中取一部分@Overridepublic List<String> next() {int nextIndex = currIndex;int totalSize = 0;for (; nextIndex < messages.size(); nextIndex++) {String message = messages.get(nextIndex);// 获取每条消息的长度int tmpSize = message.length();// 如果当前这个分片就已经超过一条消息的大小了,就将这个分片单独作为一条消息发送if (tmpSize > sizeLimit) {if (nextIndex - currIndex == 0) {nextIndex++;}break;}if (tmpSize + totalSize > sizeLimit || (nextIndex - currIndex) == batchSize ) {break;} else {totalSize += tmpSize;}}List<String> subList = messages.subList(currIndex, nextIndex);currIndex = nextIndex;return subList;}@Overridepublic void remove() {throw new UnsupportedOperationException("Not allowed to remove");}
}
线程池中的参数如何设置?
上边使用了线程池进行并发推送消息,那么线程池的参数如何设置了呢?
这里主要说一下对于核心线程数量的设置,直接设置为 0,因为这个线程池主要是对促销活动的消息进行推送,这个推送任务并不是一直都有的,有间断性的特点,因此不需要线程常驻在线程池中,空闲的时候,将所有线程都回收即可
在这个线程池中,通过信号量来控制最多向线程池中提交的任务,如果超过最大提交数量的限制,会在信号量处阻塞,不会再提交到线程池中:
public class SafeThreadPool {private final Semaphore semaphore;private final ThreadPoolExecutor threadPoolExecutor;// 创建线程池的时候,指定最大提交到线程池中任务的数量public SafeThreadPool(String name, int permits) {// 如果超过了 100 个任务同时要运行,会通过 semaphore 信号量阻塞semaphore = new Semaphore(permits);/*** 为什么要这么做,corePoolSize 是 0 ?* 消息推送这块,并不是一直要推送的,促销活动、发优惠券,正常情况下是不会推送* 发送消息的线程池,corePoolSize是0,空闲把线程都回收掉就挺好的*/threadPoolExecutor = new ThreadPoolExecutor(0,permits * 2,60,TimeUnit.SECONDS,new SynchronousQueue<>(),NamedDaemonThreadFactory.getInstance(name));}public void execute(Runnable task) {/*** 超过了 100 个 batch 要并发推送,就会在这里阻塞住* 在比如说 100 个线程都在繁忙的时候,就不可能说有再超过 100 个 batch 要同时提交过来* 极端情况下,最多也就是 100 个 batch 可以拿到信号量*/semaphore.acquireUninterruptibly();threadPoolExecutor.submit(() -> {try {task.run();} finally {semaphore.release();}});}
}// 自定义的线程工厂,创建的线程都作为守护线程存在
public class NamedDaemonThreadFactory implements ThreadFactory {private final String name;private final AtomicInteger counter = new AtomicInteger(0);private NamedDaemonThreadFactory(String name) {this.name = name;}public static NamedDaemonThreadFactory getInstance(String name) {Objects.requireNonNull(name, "必须要传一个线程名字的前缀");return new NamedDaemonThreadFactory(name);}@Overridepublic Thread newThread(Runnable r) {Thread thread = new Thread(r, name + "-" + counter.incrementAndGet());thread.setDaemon(true);return thread;}