简介
Dinky 是一个
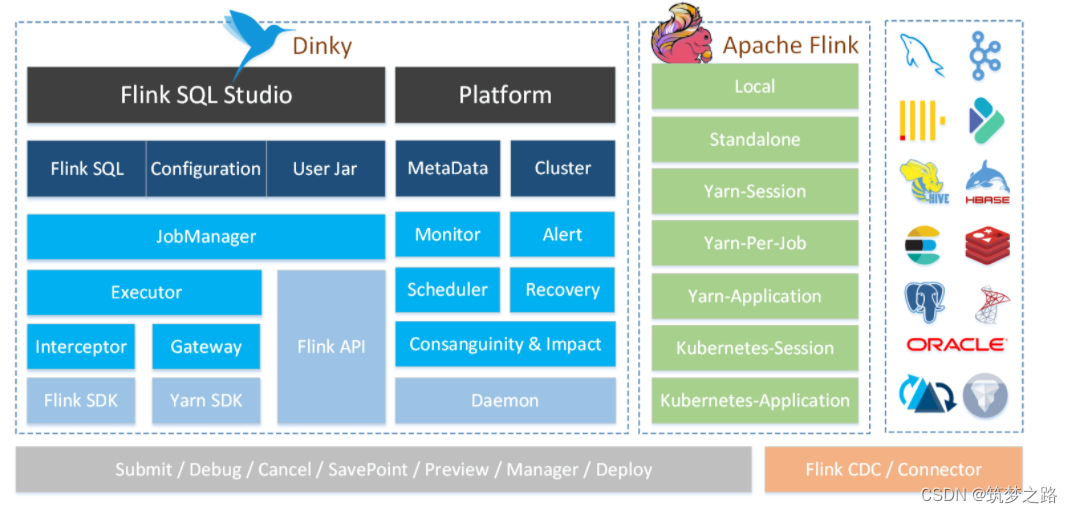
开箱即用、易扩展,以Apache Flink为基础,连接OLAP和数据湖等众多框架的一站式实时计算平台,致力于流批一体和湖仓一体的探索与实践。
主要功能
其主要功能如下:
- 沉浸式 FlinkSQL 数据开发:自动提示补全、语法高亮、语句美化、在线调试、语法校验、执行计划、MetaStore、血缘分析、版本对比等
- 支持 FlinkSQL 多版本开发及多种执行模式:Local、Standalone、Yarn/Kubernetes Session、Yarn Per-Job、Yarn/Kubernetes Application
- 支持 Apache Flink 生态:Connector、FlinkCDC、Table Store 等
- 支持 FlinkSQL 语法增强:整库同步、执行环境、全局变量、语句合并、表值聚合函数、加载依赖、行级权限等
- 支持 FlinkCDC 整库实时入仓入湖、多库输出、自动建表
- 支持 SQL 作业开发:ClickHouse、Doris、Hive、Mysql、Oracle、Phoenix、PostgreSql、Presto、SqlServer、StarRocks 等
- 支持实时在线调试预览 Table、ChangeLog、Charts 和 UDF
- 支持 Flink Catalog、数据源元数据在线查询及管理
- 支持实时任务运维:上线下线、作业信息、集群信息、作业快照、异常信息、数据地图、数据探查、历史版本、报警记录等
- 支持作为多版本 FlinkSQL Server 以及 OpenApi 的能力
- 支持实时作业报警及报警组:钉钉、微信企业号、飞书、邮箱等
- 支持自动托管的 SavePoint/CheckPoint 恢复及触发机制:最近一次、最早一次、指定一次等
- 支持多种资源管理:集群实例、集群配置、Jar、数据源、报警组、报警实例、文档、全局变量、系统配置等
- 支持企业级管理:多租户、用户、角色、项目空间
Dinky 不依赖任何外部的 Hadoop 或者 Flink 环境,可以单独部署在 flink、 hadoop 和 K8S 集群之外,完全解耦,支持同时连接多个不同的集群实例进行运维。
优化Flink体验
1、沉浸式的 FlinkSQL IDE
- Apache Flink 提供了 sql-client,但 sql-client 仅作为一个 beta 的功能,难以被应用到生产中
- Dinky 提供了沉浸式的 FlinkSQL IDE 开发能力,提供了自动提示与补全、语法高亮、语句美化、语法校验和逻辑检查、调试预览结果、字段级血缘分析等专业的功能,使 FlinkSQL 的开发如同 SQL 开发一样舒适与简单
2、极易用的任务构建方式
-
Flink 在构建 FlinkSQL Jar 任务时通常需要考虑依赖及版本的维护、代码的编写、繁琐的编译打包过程等。
-
Dinky 将 FlinkSQL 任务的构建进行了极简,开发人员只需要专注 FlinkSQL 的口径书写,并且可以实时进行检查与调试,在任务提交的过程则是快速的自动化托管,以实现一个 FlinkSQL 语句可以在所有的执行模式与外部集群上随意切换。
-
对于 Dinky 来说,主要划分两类用户。一类是平台运维人员,该人员需要根据官网文档及自身的 Flink 知识储备来手动搭建稳定的 Dinky 运作环境,门槛较高;另一类是数据开发人员,该类人员只需熟悉 FlinkSQL 的语法与常见的应用场景,即可快速高效地进行 FlinkSQL 的开发与运维,达到易用的任务构建方式。这也是最符合企业生产团队的分工策略,平台和开发分离。
3、无侵入的部署模式
-
一些开源项目或自建平台通常需要绑死 Flink 集群或者侵入 Flink 的源码,容易 Flink 功能受限或在搭建和后续扩展时出现问题。
-
Dinky 则是完全无侵入,可部署与各个集群之外,同时连接和监控多个集群。轻易地对接各个版本的 Flink 集群与公司内仓库分支优化过的 Flink 集群,完全兼容 Flink 自身的 connector、udf、cdc 等。
4、增强式的功能体验
-
一些开源项目及自建平台一般只专注于 Flink 任务的提交与运维。
-
Dinky 则不同,为更舒适地使用 Flink 的相关功能进行的功能增强,如表值聚合函数、全局变量、CDC多源合并、执行环境、语句合并、共享会话等,并且还在不断地扩展新的功能增强,以使 Flink 更贴近企业的需求。
5、实时的监控报警
- Dinky 提供实时的监控报警能力,实时守护已上线的流或批任务,在任务触发异常停止和成功完成时都会实时报警通知,并且记录了外部集群实时的任务信息,摆脱 History Server 的限制,弥补 deploy 的集群作业失败后信息难查询的不足,用户随时随地都可追溯历史作业的执行信息与异常。
6、一站式的开发运维
- Dinky 提供了一站式的开发运维能力,从 FlinkSQL 开发调试到作业上线下线的运维监控,再到数据源的 OLAP 及普通查询能力等,使得数仓建设或数据治理过程中所有的工作均可以在 Dinky 上完成。
7、易扩展的代码实现
-
Dinky 非常注重代码的扩展能力,在源码中大量使用了 SPI 机制来支持用户低成本地自定义扩展新功能,比如数据源、报警方式、自定义语法等扩展。
-
Dinky 的功能体验也十分注重扩展能力,在功能设计上尽可能地开放了最大的配置能力,如自定义提示与补全语法、自定义数据源的Flink 配置与生成规则、自定义全局变量、自定义Flink执行环境、自定义集群配置的各种配置项等等。
-
Dinky 的外部对接也很注重扩展能力,基于 SpringBoot 的代码的高内聚和低耦合以及提供多种规范的 OpenAPI 使其可以很方便地扩展第三方生态、微服务或者平台。
8、小而美的产品形态
-
常规的大数据平台或者开源项目一般是十分庞大的,维护成本较高。
-
正如 Dinky 本名所释,小巧而精美,一直是开源项目建设的首要目标。小巧具体指易搭建、不绑定任何外部中间件或文件系统、代码简洁易维护;精美则指沉浸式的页面、经过打磨的各种功能等。
Next
1、多租户及命名空间
- Dinky 目前需要一个多租户的能力来分离业务数据及资源队列,需要命名空间来增强和规范代码业务逻辑的实现与扩展。
2、全局血缘与影响分析
- Dinky 目前需要将所有的字段级血缘进行存储,以构建全局的血缘和影响分析,方便用户更容易地追溯数据问题。
3、统一元数据管理
- Dinky 目前需要统一的元数据中心来管理外部数据源元数据,使其可以自动同步数据库物理模型与平台逻辑模型之间的结构,增强平台一站式的开发能力。
4、Flink 元数据持久化
- Dinky 目前需要持久化 Flink Catalog,使作业开发时不再需要编写 CREATE TABLE 等语句,转变为可视化的元数据管理功能。
5、多版本 Flink-Client Server
- Dinky 目前的 Flink 多版本支持需要启动多个不同版本的实例来支持。未来需要实现客户端与服务端分离,单独实现多版本的 Server。
6、整库同步
- 数据库的整库同步是一个常见的场景,Dinky 未来将提供一个简短的 FlinkSQL 实现整库同步任务构建的能力。
docker一键启动
1. 准备mysql
使用mysql5.7或者mysql8.0及以上的版本
创建一个库名dinky,然后将dinky.sql导入
2. 创建容器
docker run -d --restart=always -p 8888:8888 -p 8081:8081 -e MYSQL_ADDR=192.168.100.30:3306 -e MYSQL_DATABASE=dinky -e MYSQL_USERNAME=dinky -e MYSQL_PASSWORD=NSpRXYeHBsBy6yH5 --name dinky registry.cn-hangzhou.aliyuncs.com/dinky/dinky-standalone-server:0.7.0-flink143.访问测试
访问http://ip:8888端口,用户名密码为admin