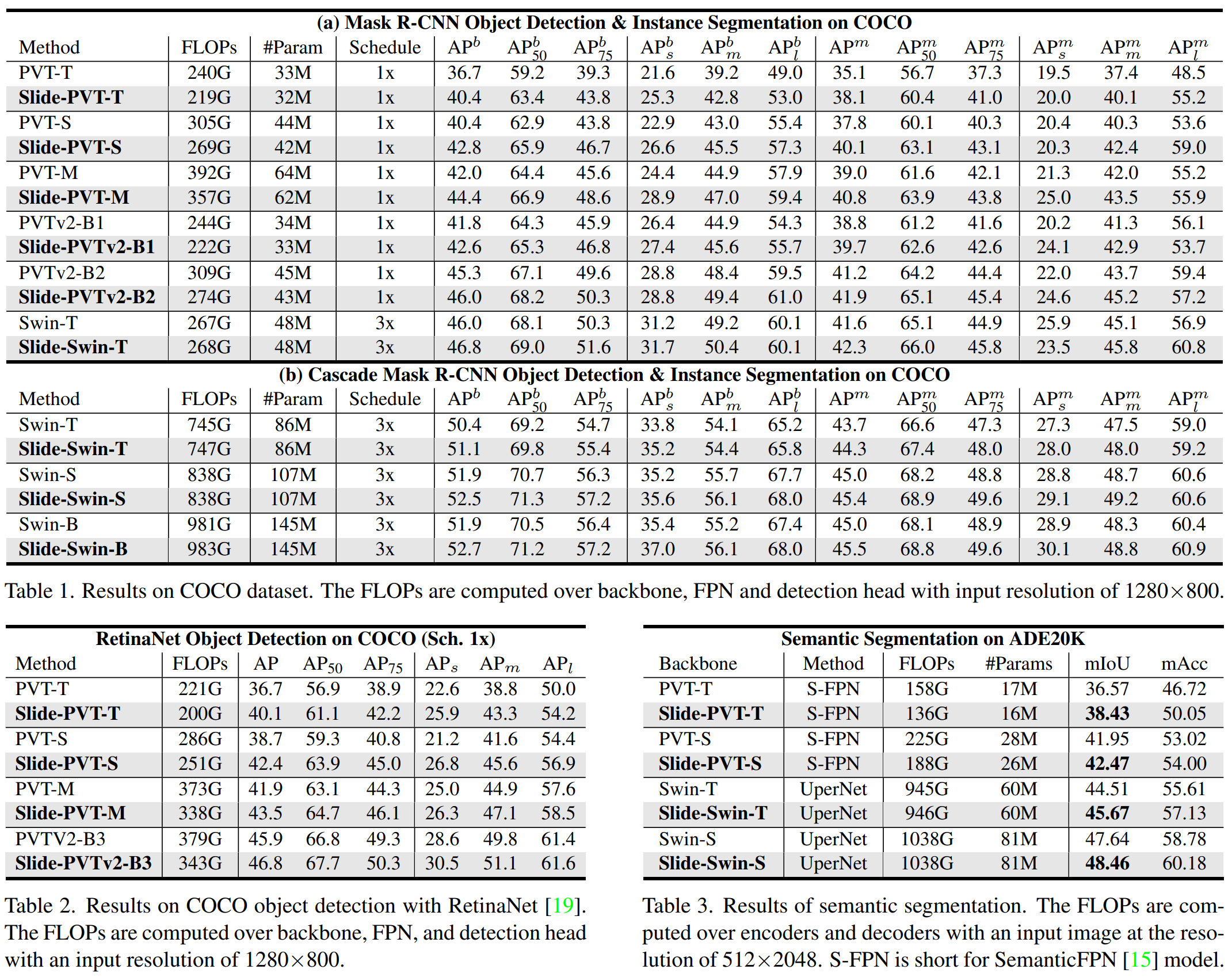
以下是Andrej Karpathy一小时讲解chatgpt的笔记。
Andrej Karpathy做自动驾驶的人应该比较熟悉,他是李飞飞的学生。在openAI做了一年半的科学家之后,去了特斯拉。在Tesla AI day讲解tesla自动驾驶方案的就是他。

这里我的主要收获是两个
- 大模型是一个有损压缩文件
- 大模型可以看成新型操作系统
下面我把比较有关键的PPT笔记总结一下,比较有趣的将其看成操作系统的我会在第二部分介绍。
一 有损压缩
- 大模型运行起来只需要两个文件,140GB的参数文件和500行的C代码,参见llama.cpp.

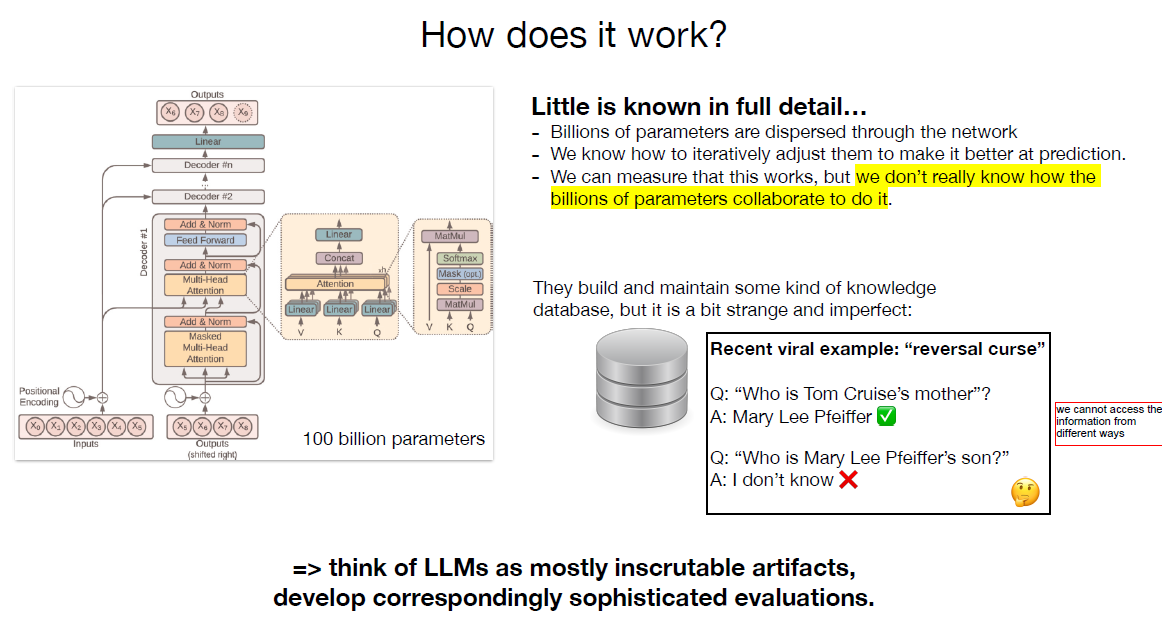
2. 大模型可以理解为对互联网上文本所有内容的有损压缩。

3. 大模型存储了海量的信息,但是并不一定支持从不同的角度问相同的问题。这张幻灯片里,提问汤姆克鲁斯的妈妈是谁,大模型回答了Mary Lee Pfeifeer。但是我们再问大模型,Mary Lee Pfeifeer的儿子是谁,大模型就不知道了。
4. 大模型分为pre-training和fine tuning两个阶段。
- Pre-training 预训练主要是获取知识
- Fine-tuning 主要是alignment,拉通对齐。
5. 两者的计算量和工作流程相差很多
- Pre-training 训练时间以年为单位
- Finetuning调优时间以星期为单位,此外fine-tuning也会有大量人工的工作。

6. Pre-training训练的结果,如果你问pre-training 之后模型一个问题,因为这个模型只是对互联问文本的压缩,你问它一个问题,它可能继续问你其他的问题,因为互联网上有海量的垃圾文本。
Finetuning阶段会让人类针对问题的标准答案,输入给模型,进行fine-tuning,此外也会训练reward-model,建立评判模型,对模型输出结果打分,结合强化学习训练模型。

7. 大模型的效果是可以预测的,由参数数量和文本数量决定。

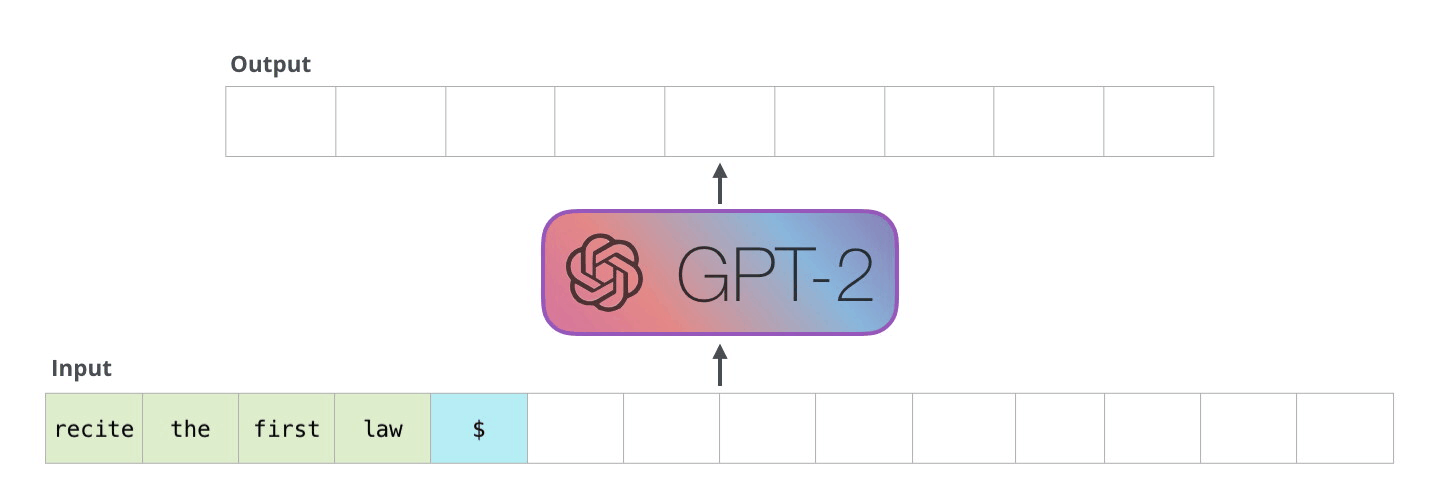
8. 人脑的思维方式有两种,快速响应和需要思考的两种问题。但是目前LLM只会第一种。也就是现在的LLM只能像刚才所说的,拿到有损压缩文件后,计算下一个token的概率,并没有理解。
(译者注:就像那个经典笑话:
A: 我会速算。
B:1234*4321等于多少?
A:788156。
B: 这对吗?
A:你就说快不快吧。

9. 现在研究人员也在尝试如何让大模型“think”。
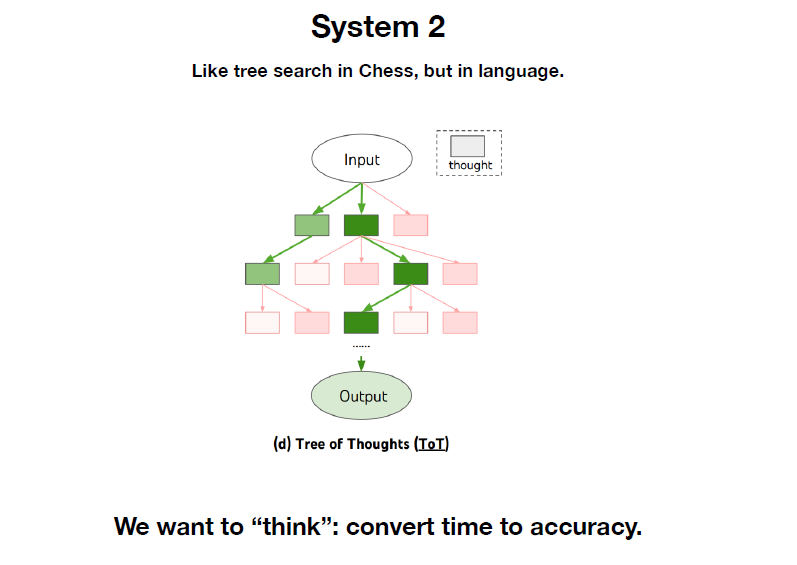
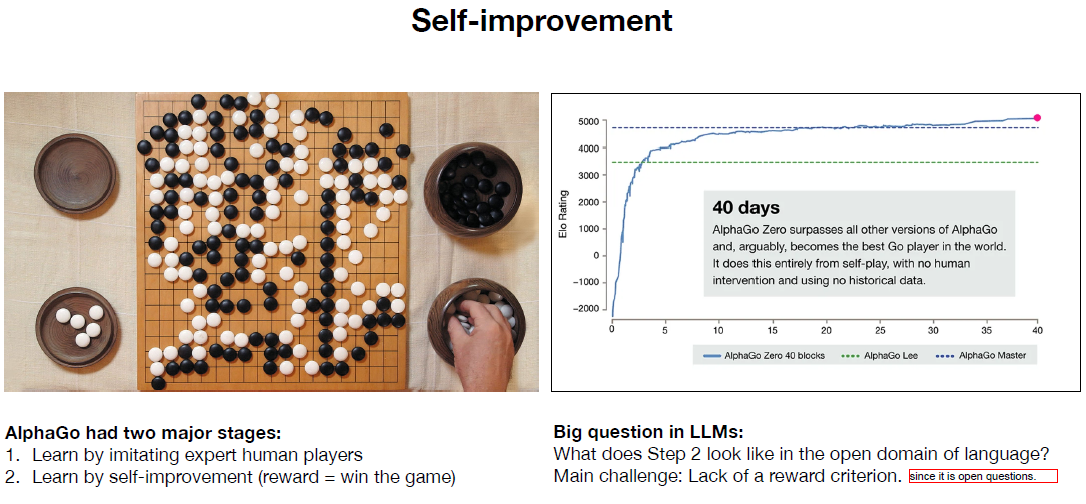
10. 完全让模型自我提升是比较困难的,不同于围棋比赛alpha go,有明确的输赢机制。大模型输出的结果进行打分,是比较困难的。毕竟是生成文本类的开放答案。
二 新型操作系统
LLM 可以看成是一种新型的操作系统,它会文件,浏览网页,也可以说话和生成视频,也可以自我提升。
在你向大模型提问,要求它计算或者画图时,他可以调用对应的python或者计算接口。
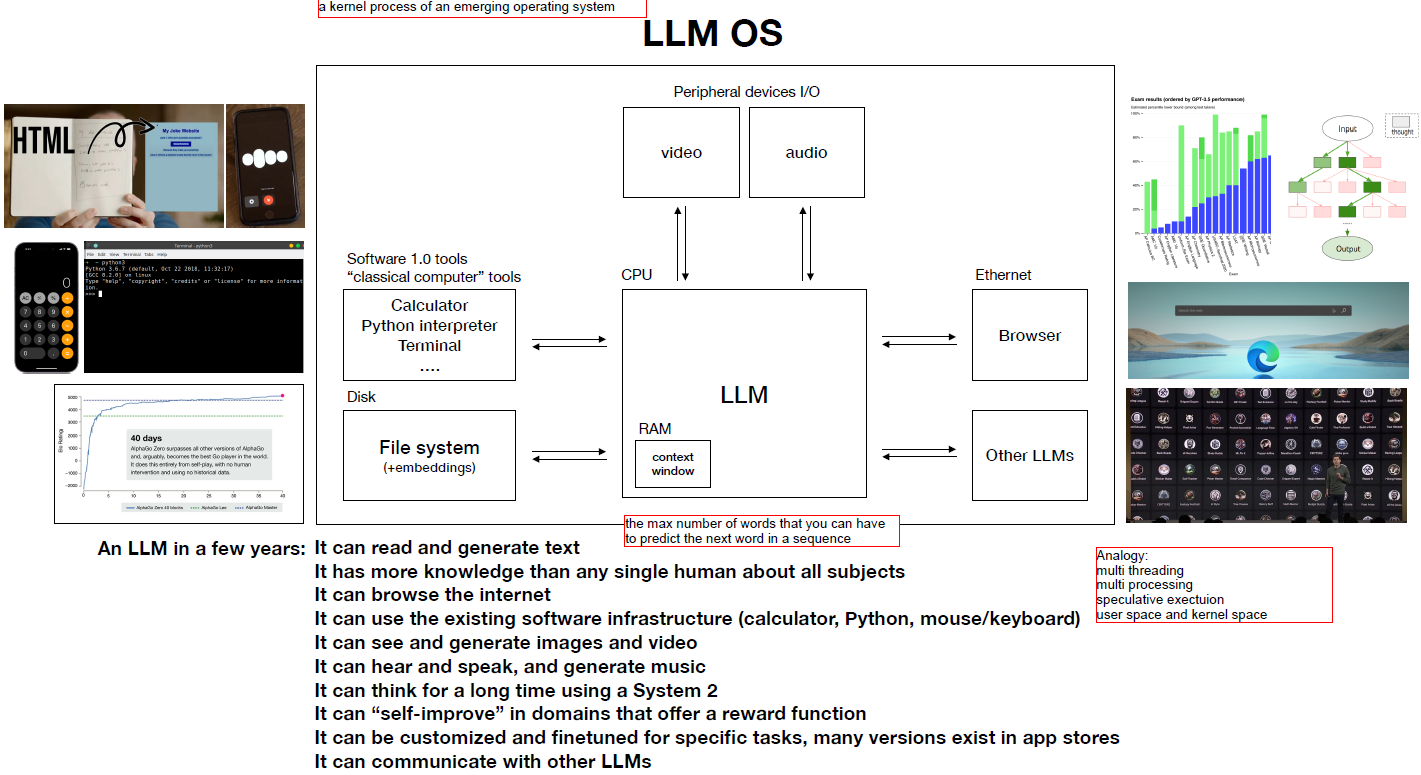
此外,类似于RAM的概念,大模型有上下文context window的概念。此外类似的概念,还有多线程,多进程和推测执行(但是这里他没有展开讲,我搜索了一下,要是不对,欢迎私信)。
- 多线程:正常情况下每次只能产生一个token,如果多个decoder同时工作,那么可以产生多个token。
- 多进程:一个问题,多个model同时响应,对各个model的结果进行择优。
- 推测执行:transformer处理下一个token,需要等待上一个token一直计算完毕最后一个layer,强依赖。在上一个token还在计算过程中,就推测它的结果,推测计算下一个token。
三 transformer
在这个讲解大模型的视频以外,他也有一个一小时讲解transformer的视频。

3.1 Tranformer
介绍一下transformer视频的收获
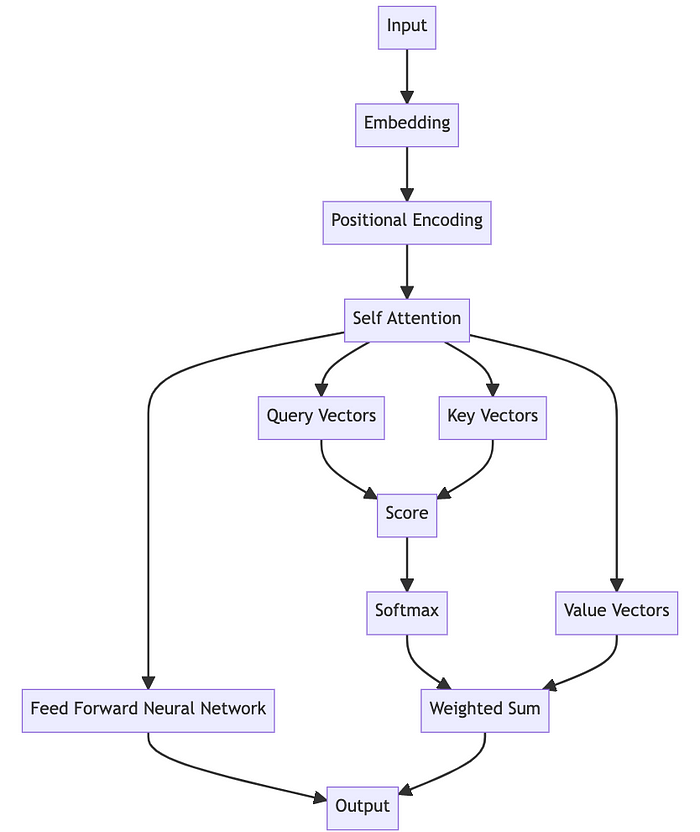
- Transformer根据之前的单词token,产生新的token,最简单的就是将前面所有的token取均值,但是显然过于简单。因此transformer通过对之前的单词赋以不同的权重,各自的weight*各自的value得到下一个单词的预测
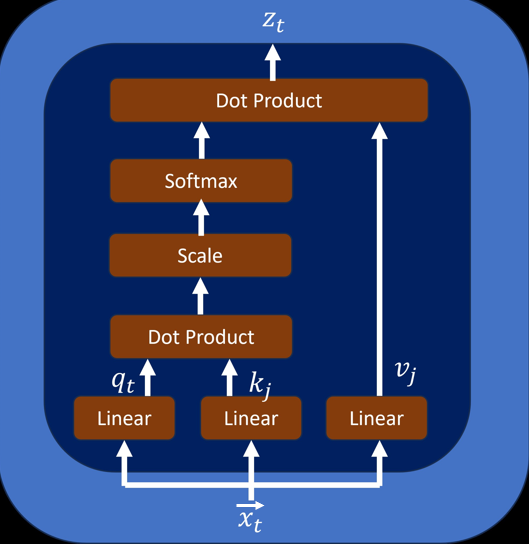

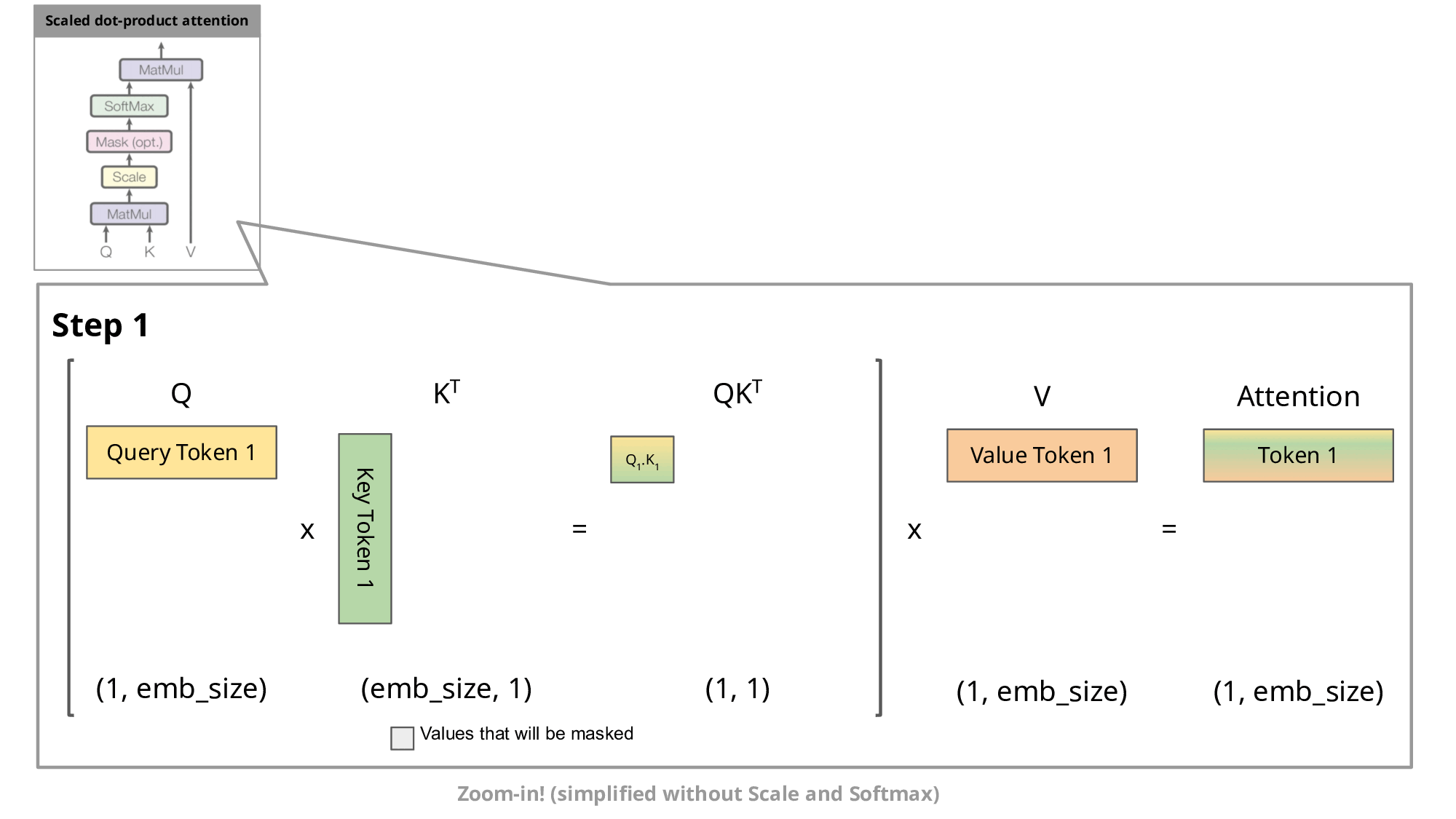
2. Weight是通过当前单词的query和当前单词之前的所有token的各个key的相似度求dot product之后进行softmax得到的。
3. Self-attention层的意义主要在于将当前token和其他token进行交流communication,在feedforward层的意义则进行计算computation。在self-attention层的操作更多的是线性的,在feedforward层引入了非线性。
4. 如果只是线性的矩阵乘法计算,那么当前token对其他token的位置是无感的,因此增加positional encoding,用来将各个token的位置信息也进行编码。

3.2 KV Cache
译者另注:
此外我们可以看到每次新的token计算时,新的token的query都需要和之前的token的key做dot product,然后结果取softmax之后和之前的token的value进行权重相乘。
之前token的key和value都是不变的,因此我们可以将其缓存起来,也就是KV Cache的作用。
加上这个cache之后,更像操作系统了。

引自:
[1][2] Andrej Karpathy 视频讲解
[3] Transformers KV Caching Explained https://medium.com/@joaolages/kv-caching-explained-276520203249
[4] Decoding the Magic of Self-Attention: A Deep Dive into its Intuition and Mechanisms https://medium.com/@farzad.karami/decoding-the-magic-of-self-attention-a-deep-dive-into-its-intuition-and-mechanisms-394aa98f34c5
[5] Self-Attention: A step-by-step guide to calculating the context vector https://medium.com/@lovelyndavid/self-attention-a-step-by-step-guide-to-calculating-the-context-vector-3d4622600aac