Slide-Transformer: Hierarchical Vision Transformer with Local Self-Attention
一、分析
1、改进transformer的几个思路:
(1)将全局感受野控制在较小区域,如:PVT,DAT,使用稀疏全局注意力来从特征图选择稀疏的键对值,并且在所有查询中共享它们。
(2)就是Swin Transformer这条窗口注意力范式,输入被分为特殊设计的窗口,特征在窗口中提取并融合。非常有效,但是有一些局限性,一方面,稀疏全局注意力在捕捉局部特征方面往往较差,并且容易受到关键和值位置的影响,在这些位置,其他区域中的信息特征可能会被丢弃。另一方面,窗口注意可能会阻碍跨窗口通信,这又引入了额外的设计,如窗口偏移,从而对模型结构设置限制。
一个自然有效的替代方案不是缩小全局感受野,而是通过将每个查询的感受野约束在其自己的相邻像素中来采用局部注意力。与前面提到的注意力模式相比,局部注意力具有与平移等变和局部归纳偏差卷积的优点,同时也享有自注意机制的灵活性和数据依赖性。许多工作已经研究了将局部注意力应用于现代卷积或Transformer模型。然而,他们要么使用低效的Im2Col函数,这会导致推理时间的大幅增加,要么依赖于精心编写的CUDA内核,这限制了在没有CUDA支持的设备上的适用性。因此,开发一个既高效又可推广的局部注意力模块仍然具有挑战性。
PVT将特征图中的稀疏位置采样视为键值对。DAT采取了进一步的步骤,并以数据相关的方式将固定位置向不同的方向移动。MViT在输入上使用池化函数,以获得键和值对,这可以被视为特征图的较低分辨率。Swin Transformer使用窗口+位移,CSwin Transformer在此基础上使用十字形窗口,进一步提高模型能力。local attention限制每个查询的感受野在周围的像素。
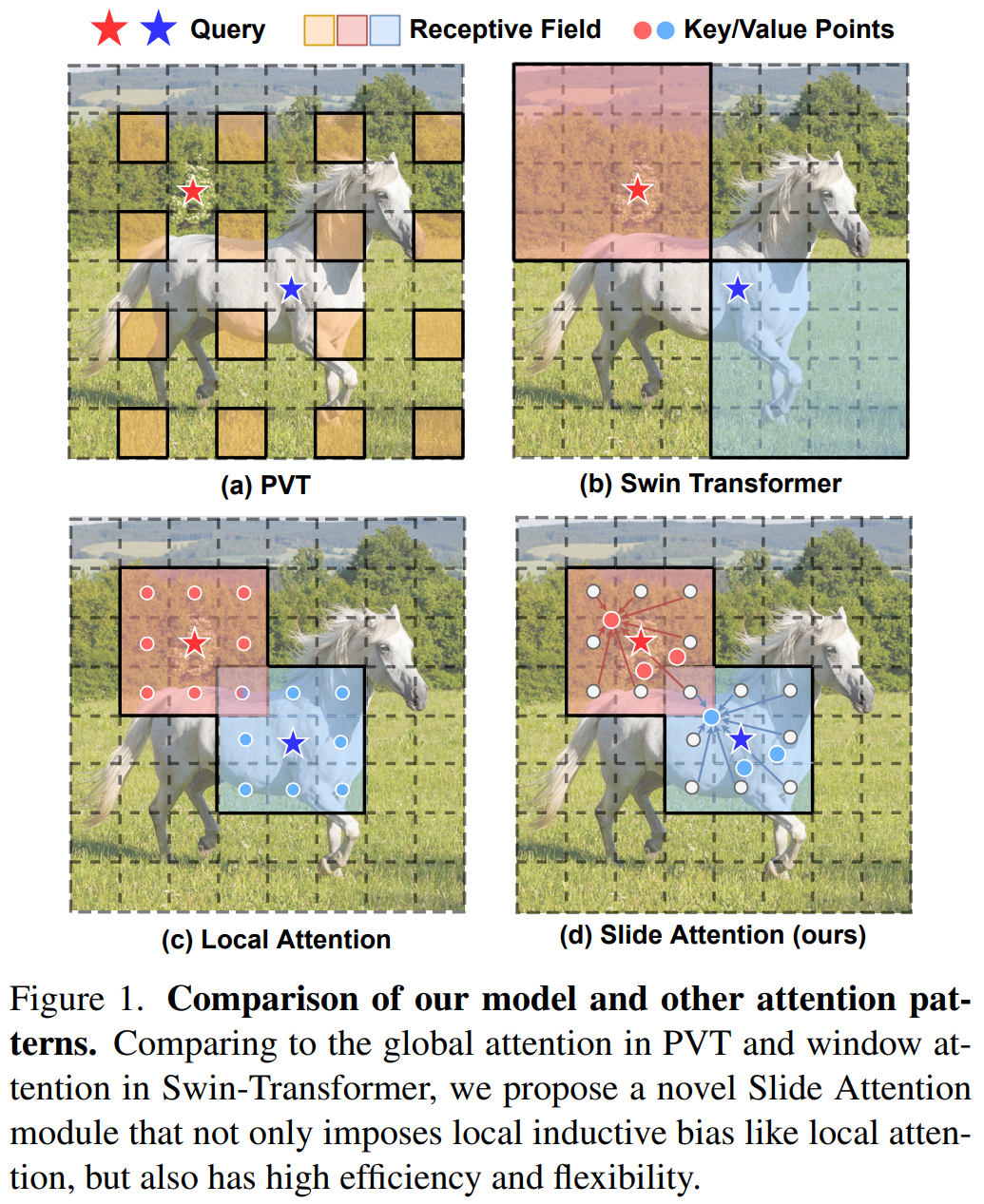
2、Attention Patterns(即总结一下)
(1) 稀疏全局注意力考虑选择一组稀疏的键值对,而不是密集的特征图。然而,这也限制了将特征提取到有限的输入子集中的潜力。此外,键和值对对于所有查询都是相同的。这种查询不可知的选择策略可能导致整个特征图中的特征同质化。
(2) 窗口注意力是另一种将输入小心地完全划分为特定窗口的选项,在特定窗口中提取特征。尽管部分解决了查询不可知的键值对的限制,但所设计的模式可能会导致不自然的情况,即不同窗口边缘的特征尽管在特征图中很近,但却被完全隔离。此外,窗口模式需要在连续的块之间转换,以促进跨窗口的连接,这涉及到模型结构中的额外设计。
(3) 局部注意力将每个查询的感受野约束在其自己的相邻像素中,与卷积共享相似的模式。与以前的模式相比,局部注意力同时具有卷积和自我注意力的优点:1)以查询为中心的注意力模式产生的局部归纳偏差;2) 像传统卷积一样的平移等方差,显示出对输入偏移方差的鲁棒性;3) 涉及很少的人工设计,对模型架构设计的限制最小。
3、 Local Attention Implementation
不同方法的效率:

二、方法
1. New Perspective on Im2Col

图(1)是原本的Im2Col的基于列的试图。图2是基于行的试图,是作者发现的。以k=3为例,如果我们首先将原始特征图向9个不同的方向移动(图3(2.b)),然后将这些特征展平成行,最后将它们连接成列(图3的2.c)),则所获得的键/值矩阵被证明等效于HW局部窗口,该窗口可以恢复与原始Im2Col函数完全相同的输出(图3中的1.c))。
2. Shift as Depthwise Convolution
采用一个精心设计卷积核的深度卷积来代替低效的特征偏移。如上图(3.(3))
3. Deformed Shifting Module

引入了一种并行卷积路径,其中核参数在训练过程中被随机初始化并可学习。与将特征向不同方向转移的固定内核相比,可学习内核可以被解释为所有局部特征的线性组合。
(1) 局部注意力中的关键和价值对由一个更灵活的模块来处理,该模块大大提高了模型容量,并可以捕捉各种特征。(2) 可学习卷积核与DCN中的可变形技术表现出相似性。类似于DCN中四个相邻像素的双线性插值,我们的变形移位模块可以被视为局部窗口内特征的线性组合。这最终有助于增强输入的空间采样位置和模型几何变换。(3) 我们使用重新参数化技术[8]将两条平行路径转换为单个卷积。这样,我们可以在保持推理效率的同时提高模型容量。
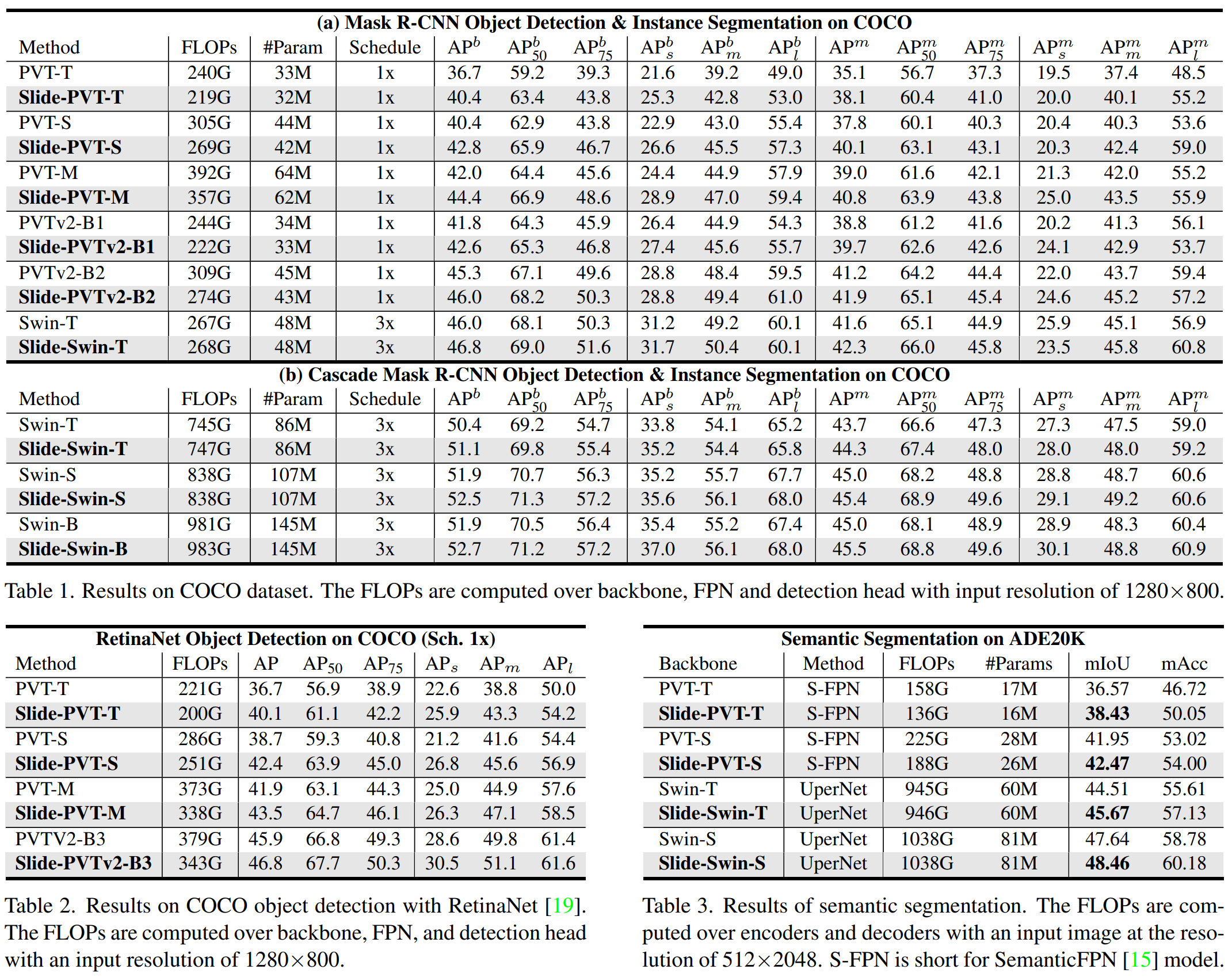
结果:





![[笔记] 使用 qemu 创建虚拟磁盘并安装 grub](https://img-blog.csdnimg.cn/direct/978f71634b194e74a799da86001193e2.png)