文章目录
- 题目
- 标题和出处
- 难度
- 题目描述
- 要求
- 示例
- 数据范围
- 解法
- 思路和算法
- 代码
- 复杂度分析
题目
标题和出处
标题:删点成林
出处:1110. 删点成林
难度
6 级
题目描述
要求
给定二叉树的根结点 root \texttt{root} root,树中每个结点的值各不相同。
在删除所有结点值在 to_delete \texttt{to\_delete} to_delete 中出现的结点之后,得到一个森林(一些不相交的树构成的集合)。
返回森林中的每个树的根结点。可以按任意顺序返回答案。
示例
示例 1:
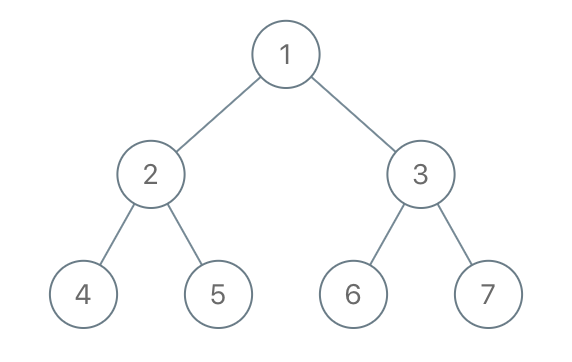
输入: root = [1,2,3,4,5,6,7], to_delete = [3,5] \texttt{root = [1,2,3,4,5,6,7], to\_delete = [3,5]} root = [1,2,3,4,5,6,7], to_delete = [3,5]
输出: [[1,2,null,4],[6],[7]] \texttt{[[1,2,null,4],[6],[7]]} [[1,2,null,4],[6],[7]]
示例 2:
输入: root = [1,2,4,null,3], to_delete = [3] \texttt{root = [1,2,4,null,3], to\_delete = [3]} root = [1,2,4,null,3], to_delete = [3]
输出: [[1,2,4]] \texttt{[[1,2,4]]} [[1,2,4]]
数据范围
- 树中结点数目最大为 1000 \texttt{1000} 1000
- 每个结点都有一个介于 1 \texttt{1} 1 和 1000 \texttt{1000} 1000 之间的各不相同的值
- to_delete.length ≤ 1000 \texttt{to\_delete.length} \le \texttt{1000} to_delete.length≤1000
- to_delete \texttt{to\_delete} to_delete 包含介于 1 \texttt{1} 1 和 1000 \texttt{1000} 1000 之间的各不相同的值
解法
思路和算法
对于二叉树中的每个结点,如果结点值在给定的数组中,则该结点需要删除。为了快速判断结点值是否在给定的数组中,应使用哈希集合存储给定的数组中的每个值。
删除结点之后得到的森林中的每个树的根结点可能有如下两种情况。
-
如果根结点没有被删除,则根结点是森林中的一个树的根结点;如果根结点被删除,则根结点不在森林中。
-
对于被删除的结点,其每个非空结点都是森林中的一个树的根结点。
可以使用深度优先搜索实现。从根结点开始搜索,搜索过程中需要记录当前结点的父结点是否被删除,如果父结点被删除则当前结点在不被删除的情况下需要加入森林,如果父结点不被删除则当前结点不加入森林。
由于根结点没有父结点,因此根结点的父结点记为被删除。对于每个结点,深度优先搜索执行如下操作。
-
如果当前结点的父结点被删除且当前结点不被删除,则将当前结点加入森林。
-
对于当前结点的每个非空子结点继续深度优先搜索,并更新当前结点的子结点的状态,其中子结点的父结点是否被删除的信息即为当前结点是否被删除的信息。
-
如果当前结点被删除则返回空结点,如果当前结点不被删除则返回当前结点。
上述操作中,如果一个结点的父结点被删除,则该结点作为一个新树的根结点加入森林中。对于每个结点,其在深度优先搜索中的返回值取决于该结点是否被删除。因此上述操作可以得到正确的结果。
代码
class Solution {Set<Integer> toDeleteSet = new HashSet<Integer>();List<TreeNode> forest = new ArrayList<TreeNode>();public List<TreeNode> delNodes(TreeNode root, int[] to_delete) {for (int val : to_delete) {toDeleteSet.add(val);}dfs(root, true);return forest;}public TreeNode dfs(TreeNode node, boolean parentDelete) {boolean currDelete = toDeleteSet.contains(node.val);if (parentDelete && !currDelete) {forest.add(node);}TreeNode left = node.left, right = node.right;if (left != null) {node.left = dfs(left, currDelete);}if (right != null) {node.right = dfs(right, currDelete);}return currDelete ? null : node;}
}
复杂度分析
-
时间复杂度: O ( n ) O(n) O(n),其中 n n n 是二叉树的结点数。每个结点都被访问一次。
-
空间复杂度: O ( n ) O(n) O(n),其中 n n n 是二叉树的结点数。空间复杂度主要是递归调用的栈空间,取决于二叉树的高度,最坏情况下是 O ( n ) O(n) O(n)。