- 数学基础
- 线性代数
- 从行的角度
- 从列的角度
- 行列式的几何解释
- 向量范数和矩阵范数
- 向量范数
- 矩阵范数的更强的性质的意义
- 几种向量范数诱导的矩阵范数
- 1 范数诱导的矩阵范数
- 无穷范数诱导的矩阵范数
- 2 范数诱导的矩阵范数
- 各种范数之间的等价性
- 向量与矩阵序列的收敛性
- 函数的可微性与展开
- 一维优化问题
- 牛顿莱布尼茨公式对多维的拓展
- Lipschitz 连续
- 中值定理
- 凸优化问题
- 凸函数的判断
- f 在 D 一阶可微
- 正定矩阵
- f 在 D 二阶可微
- 凸函数的判断
- 无约束问题的最优性条件
- 一阶必要条件
- 二阶必要条件
- 二阶充分条件
- 充要条件
- 一般算法框架
- 线搜索
- 精确线搜索
- 单峰区间
- 黄金分割方法
- 无法执行黄金分割的情况
- 牛顿法
- 原理
- 算法
- 收敛速度
- 割线法
- 抛物线方法
- 原理
- 算法
- 与黄金分割的对比
- 判断插点位置的注意事项
- 非精确线搜索
- Armijo-Goldstein 准则
- Wolfe-Powell 准则
- Armijo 准则的实现
- 线搜索方法框架
- 线搜索方法的收敛性
- 精确线搜索
- 梯度法和牛顿法
- 最速下降法(梯度法)
- 牛顿法
- 阻尼牛顿法
- 修正牛顿法
- 共轭方向法和共轭梯度法
- 收敛速度的证明
- 另一种讲法
- 怎么求第 k 步的搜索方向
- 对于非线性问题
- 二次终止性
- 从内积角度看傅里叶变换
- 拟牛顿法
- 对称秩一校正
- 对称秩二
- DFP, BFGS
- 对称正定
- 拟牛顿法的收敛性
- 有约束的最优化问题
- 约束最优化问题的最优性条件
- 等式约束的最优性条件
- 拉格朗日乘子法
- 证明一阶必要条件
- 二阶充分条件
- 不等式约束问题的最优性条件
- 无效约束和有效约束
- Farkas 引理
- Gordan 引理
- 不等式约束问题的几何最优性条件
- 不等式约束问题的 KT 条件
- 一般约束问题的最优性条件
- 不等式约束和等式约束统一为等式约束
- 一阶必要条件
- 二阶充分条件
- 等式约束的最优性条件
- 约束优化问题的可行方向法
- Zoutendijk 可行方向法
- 可行方向
- 非线性约束下的非线性优化
- 问题转化
- 迭代时满足约束
- 下降可行方向的条件
- 线性约束的可行方向法
- 非线性约束的可行方向法
- 梯度投影法
- 怎么把一个向量投影到边界上
- 投影到 a 向量
- 投影到 A 矩阵
- 投影矩阵的性质
- 投影到 Mx = 0 表示的空间
- 投影到 Mx = b 表示的空间
- A = (A1, A2)
- 算法流程
- 怎么把一个向量投影到边界上
- Zoutendijk 可行方向法
- 罚函数
- 外罚函数
- 证明收敛
- 聚点
- 算法框架
- 优缺点
- 内点法
- 算法框架
- 证明收敛
- 优缺点
- 乘子法(PH 算法)
- PH 算法流程
- 外罚函数
- 划重点
- 绪论
- 无约束问题的最优性条件
- 什么是凸集,凸函数
- 多元函数
- 线搜索的框架
- 常用方法的收敛速度
- 判断迭代是否终止的判据
- 线搜索
- 梯度法
- 共轭方向法
- 二次终止性
- 拟牛顿法
- 有约束的优化问题
- 约束问题的可行方向法
- 约束问题的罚函数方法
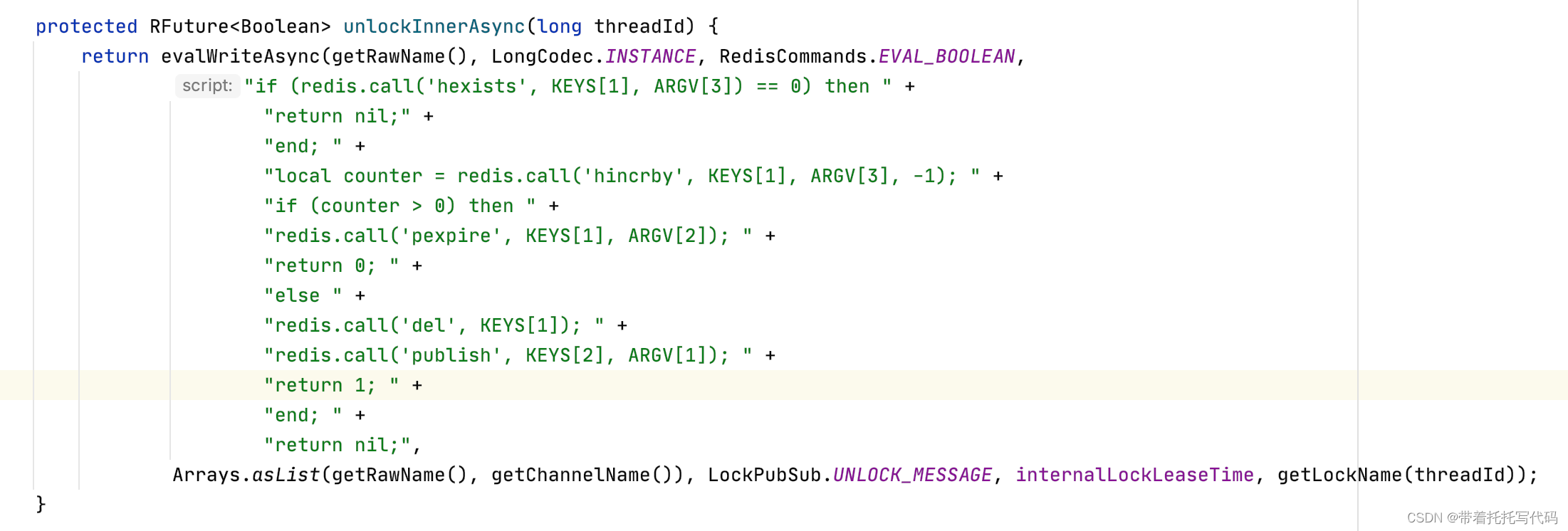
拟牛顿法
考:提出的思想是什么
希望用一个对称正定矩阵 B 去近似 Hesse 矩阵 G
或者是用一个对称正定矩阵 H 去近似 Hesse 矩阵 G 的逆
并且要求这个方法比较简单,不然还不如直接求 G
考:方程是什么(条件是什么)
因为 G 满足
G k + 1 ( x k + 1 − x k ) ≈ g k + 1 − g k G_{k+1}(x_{k+1}-x_{k}) \approx g_{k+1} - g_{k} Gk+1(xk+1−xk)≈gk+1−gk
如果记 s k = x k + 1 − x k , y k = g k + 1 − g k s_k = x_{k+1}-x_{k}, y_k = g_{k+1} - g_{k} sk=xk+1−xk,yk=gk+1−gk
那么上式转化为
G k + 1 s k ≈ y k G_{k+1}s_k \approx y_k Gk+1sk≈yk
那么我们的问题就转化为找一个 B 满足
B k + 1 s k ≈ y k B_{k+1}s_k \approx y_k Bk+1sk≈yk
或者是找一个
实际迭代用一个修正公式
B k + 1 = B k + E k B_{k+1} = B_k + E_k Bk+1=Bk+Ek
对称秩一校正
考:对称秩一校正公式是怎么得到的
E k = a u k u k T E_k = a u_k u_k^T Ek=aukukT 一个自由度
因为 u k u k T u_k u_k^T ukukT 这个矩阵的每一列都是 u k T u_k^T ukT 这个列向量的 u i u_i ui 倍
所以这个矩阵线性无关的列只有一个,那就是 u k T u_k^T ukT 所以秩为 1
α ( u k T s k ) u k = y k − B k s k \alpha(u_k^T s_k)u_k = y_k-B_ks_k α(ukTsk)uk=yk−Bksk
s k s_k sk 是列向量, u k T u_k^T ukT 是行向量, ( u k T s k ) (u_k^T s_k) (ukTsk) 是一个数,所以 u k u_k uk 与 y k − B k s k y_k-B_ks_k yk−Bksk 平行
所以把 u k u_k uk 写成 y k − B k s k y_k-B_ks_k yk−Bksk 的倍数
初始 B 0 = I B_0 = I B0=I 显然是对称正定
之后要确定方向的时候,还是要求解 G d = − g Gd = -g Gd=−g 也就是求解这个 B d = − g Bd = -g Bd=−g 中的 d
也就是要求一个 B B B 的逆,一般是可以接受的
但是如果你是用 H H H 取近似 G G G 的逆
那么直接就能 d k = − H k g k d_k = -H_k g_k dk=−Hkgk 了
目标函数的计算耗时
一阶导用差分来算的话,至少算两次目标函数,那么更耗时
二阶导同理,至少算四次目标函数,更耗时,所以才要避免计算 G
对称秩二
加两个修正的话,有两个参数,能够修正的范围就更多
现在在推导的时候没有那个关键条件 左边的列向量和右边的列向量是平行的
现在的问题是,右端的向量 y k − B k s k y_k-B_ks_k yk−Bksk 位于左边的 u k , v k u_k,v_k uk,vk 张成的平面上
那么其实两个基向量的系数可以任取
那么我们就取一中最简单的情况,就是 y k − B k s k y_k-B_ks_k yk−Bksk 中的 y k y_k yk 与 u k u_k uk 平行, B k s k B_ks_k Bksk 与 v k v_k vk 平行
DFP, BFGS
BFGS, DFP 怎么推导得到的








对称正定
考:BFGS, DFP 每一步校正的时候,怎么保证 Bk 对称正定?
还要证明迭代得到的 B k B_k Bk 也是对称正定,那么就是要求这个条件
书上结论错了,不是说有一个对称正定矩阵 B,就能把这个对称正定矩阵分解为对称正定矩阵 B 1 2 B 1 2 B^{\frac{1}{2}}B^{\frac{1}{2}} B21B21
这里实际上应该是对称正定矩阵的 Cholesky 分解(Cholesky 分解是 LU 分解对对称正定矩阵的特殊情况)
Cauchy-Schwarz 不等式 ( a ⋅ b ) 2 ⩽ ( a ⋅ a ) ( b ⋅ b ) (a \cdot b)^2 \leqslant (a \cdot a)(b \cdot b) (a⋅b)2⩽(a⋅a)(b⋅b)
同样的是 ∫ ( a ⋅ b ) 2 d x ⩽ ∫ ( a ⋅ a ) ( b ⋅ b ) d x \int(a \cdot b)^2 \mathrm{d}x \leqslant \int(a \cdot a)(b \cdot b) \mathrm{d}x ∫(a⋅b)2dx⩽∫(a⋅a)(b⋅b)dx
一个向量像另外一个向量投影再投影回他自身,得到的向量的长度,小于它自身的长度
因为 B 是对称正定,所以 B d = − g Bd = -g Bd=−g 有唯一解 d
同时还有 0 < d T B d = − d T g 0<d^TBd = -d^Tg 0<dTBd=−dTg,所以解得的 d 与下降方向 -g 成锐角,所以能够保证下降
所以之前这一段在证啥来着
所以问题怎么就转化成了 保证 y k T s k > 0 y_k^Ts_k > 0 ykTsk>0?
那么问题转变成,你怎么保证 y k T s k > 0 y_k^Ts_k > 0 ykTsk>0
对于精确线搜索,有 g k + 1 T d k = 0 g^T_{k+1} d_k = 0 gk+1Tdk=0,故 y k T s k = α k ( g k + 1 − g k ) T d k = − α k g k T d k > 0 y_k^Ts_k = \alpha_k(g_{k+1}-g_k)^T d_k = -\alpha_k g^T_k d_k > 0 ykTsk=αk(gk+1−gk)Tdk=−αkgkTdk>0
对于 Armijo 准则,有一个条件 α < 1 \alpha<1 α<1 保证了
对于 Wolfe 准则,利用该准则的第二个不等式,即 ∇ f ( x k − α k d k ) T d k ⩾ σ g k T d k \nabla f(x_k - \alpha_k d_k)^T d_k \geqslant \sigma g_k^T d_k ∇f(xk−αkdk)Tdk⩾σgkTdk
有 y k T s k = α k ( g k + 1 − g k ) T d k ⩾ α k ( σ − 1 ) g k T d k > 0 y_k^T s_k = \alpha_k(g_{k+1}-g_{k})^Td_k \geqslant \alpha_k(\sigma-1)g_k^T d_k > 0 ykTsk=αk(gk+1−gk)Tdk⩾αk(σ−1)gkTdk>0
那么就证明了对于精确线搜索和非精确线搜索,都有 y k T s k > 0 y_k^Ts_k > 0 ykTsk>0
总之我感觉就是,首先你要知道要证 y k T s k > 0 y_k^Ts_k > 0 ykTsk>0,然后你要知道对于精确线搜索和非精确线搜索,都有 y k T s k > 0 y_k^Ts_k > 0 ykTsk>0
拟牛顿法的收敛性
考:拟牛顿法的收敛速度?有没有二次终止性?
拟牛顿法具有二次终止性
只要证明每一步的搜索方向与目标函数的负梯度方向的夹角小于 90 度
根据 B 是正定的,得到 sTBs 是大于 0 的
但是趋于极限的时候,可能 cos θ k → 0 \cos{\theta_k} \rightarrow 0 cosθk→0,这也是不满足的
引入一个函数,函数中包含一个 cos θ k \cos{\theta_k} cosθk
G 乘 sk 表示二阶导 G 沿着 sk 的分量
gk+1 - gk
= ∫ G(xk + tsk)sk dt
G 的范数有一个上限,记为 W
有约束的最优化问题
等式约束
不等式约束
一般约束
一个二维等式约束的情况
画 f ( x ) f(x) f(x) 的等值线图,从只有一个点开始画,直到出现一圈等值线刚好与等式约束 h ( x ) h(x) h(x) 代表的曲线相切
也就是意味着 f ( x ) f(x) f(x) 和 h ( x ) h(x) h(x) 在那个切点的方向上的各自的梯度方向是共线的
两个三维等式约束的情况
两个三维等式约束代表了两个曲面,这两个曲面的交集一般是一个曲线,这个曲线的切线上的点,的切线方向,与这两个曲面在这点的法向(梯度方向)都垂直
而 f ( x ) f(x) f(x) 的等值面第一次碰到这个曲线的时候,与这个曲线相切,那么切点处 f ( x ) f(x) f(x) 的梯度与切点处的切向量垂直
那么这三个梯度方向是共面的,也就是线性相关的
约束最优化问题的最优性条件
分为等式约束问题的最优性条件和不等式约束问题的最优性条件
最后等式约束问题的最优性条件和不等式约束问题的最优性条件合并到一起,得到一个一般约束问题额最优性条件
考:几个最优性条件的表示
考:最优性条件的几何含义
考:给你一个目标函数的等值线的图,给一个约束函数的区域,判断哪些点是满足必要条件,哪些点是满足充要条件
等式约束的最优性条件
一阶必要条件: ∇ f ( x ∗ ) − ∑ i = 1 l λ i ∗ ∇ h i ( x ∗ ) = 0 \nabla f(x^*) - \sum_{i=1}^l \lambda_i^* \nabla h_i(x^*) = 0 ∇f(x∗)−∑i=1lλi∗∇hi(x∗)=0
二阶充分条件: ∇ h i ( x ∗ ) d = 0 \nabla h_i(x^*)d = 0 ∇hi(x∗)d=0, d T ∇ x x 2 L ( x ∗ , λ ∗ ) d > 0 d^T \nabla^2_{xx}L(x^*,\lambda^*)d>0 dT∇xx2L(x∗,λ∗)d>0
一阶必要条件: f ( x ) f(x) f(x) 的梯度可以写为各个约束条件的梯度的线性组合
二阶充分条件: d T G d > 0 d^TGd > 0 dTGd>0 沿着两个方向的 d 走,函数值都要增大
拉格朗日乘子法
得到的公式
就是我们之前讲的, f ( x ) f(x) f(x) 的梯度可以写为各个约束条件的梯度的线性组合
需要各个约束是向量无关的,为什么?
假设两个约束曲线唯一确定一个点,然后再假设确定的这个点是这两个曲线相切的切点,那么这两个约束曲线在这一点的梯度是共线的,但是这一点不一定是 f ( x ) f(x) f(x) 与约束曲线相切的地方,所以 f ( x ) f(x) f(x) 在一点的梯度不与约束在这一点的梯度不一定共线,这样的话, f ( x ) f(x) f(x) 在解的梯度不能表示为约束的梯度的线性组合
所以才需要这个约束
证明一阶必要条件
H H H 是拉格朗日函数 h ( x ) h(x) h(x) 的梯度
不失一般性,可以设 H H H 的前 l l l 行构成的 l l l 阶子矩阵 H 1 H_1 H1 是非奇异的
因为,我们有 l l l 个线性无关的约束,所以肯定有 l l l 个线性无关的行
我们可以把这 l l l 个线性无关的行提到矩阵的前面
为什么我们可以提呢?
其实调换矩阵的行的过程本质上就是调换了坐标系的轴
不管轴怎么变,图形仍然是那个图形,所以不妨碍证明
所以把 H H H 分为两个部分 H 1 , H 2 H_1, H_2 H1,H2
其实就是相当于把 x x x 分为两个部分, x = ( y , z ) x=(y,z) x=(y,z) 我们要把 y 消去,留下 z
在解 x ∗ = ( y ∗ , z ∗ ) x^*=(y^*,z^*) x∗=(y∗,z∗) 的地方,满足 h ( x ∗ ) = h ( y ∗ , z ∗ ) = 0 h(x^*) = h(y^*,z^*) = 0 h(x∗)=h(y∗,z∗)=0
h 对 y 的导,这个雅可比矩阵,就是 H 的前 l l l 阶子矩阵的转置
根据隐函数定理可知在 z ∗ z^* z∗ 附近存在 y = u ( z ) y=u(z) y=u(z) 且使得 h ( u ( z ) , z ) = 0 h(u(z),z)=0 h(u(z),z)=0
故有 h ( u ( z ) , z ) h(u(z),z) h(u(z),z) 在 z ∗ z^* z∗ 的梯度为 0
∂ f / ∂ z 1 = 0 \partial{f}/\partial{z_1} = 0 ∂f/∂z1=0
其中
∂ f / ∂ z 1 = ∂ f / ∂ y 1 ⋅ ∂ y 1 / ∂ z 1 + ∂ f / ∂ y 2 ⋅ ∂ y 2 / ∂ z 1 + . . . \partial{f}/\partial{z_1} = \partial{f}/\partial{y_1} \cdot \partial{y_1}/\partial{z_1}+\partial{f}/\partial{y_2} \cdot \partial{y_2}/\partial{z_1} + ... ∂f/∂z1=∂f/∂y1⋅∂y1/∂z1+∂f/∂y2⋅∂y2/∂z1+...
可以写成 f 的梯度 · y 对 zi 的导数
二阶充分条件
对称正定 d T G d > 0 d^TGd > 0 dTGd>0 的意思是,沿着两个方向的 d 走,函数值是要增大的
类比一维情况下的抛物线。
一阶必要条件是点在约束上的法向与在可行域内的法向共线
h 的梯度在 h = 0 的下半部分,说明 h = 0 的下半部分是 h > 0,上半部分是 h < 0
沿着两个 d,对于 L = f − λ h L = f - \lambda h L=f−λh,都是 f 增加,h 增加
λ \lambda λ 是 f 的梯度 = λ \lambda λ 倍的 h 的梯度,但是 f 的梯度是向右上的,与 h 的梯度相反,所以 λ < 0 \lambda<0 λ<0
所以两个方向上都是 L 增加
对于有界的向量,每次都把区间二等分,肯定有一半区间是存在无穷个向量的,那么划分无穷次,最终那个区间就会收敛到某个值
考:带约束情况下,一阶必要条件和二阶充分条件有什么区别
不等式约束问题的最优性条件
无效约束和有效约束
考虑不等式约束 g ( x ) ⩾ 0 g(x) \geqslant 0 g(x)⩾0
如果全局极小值点在约束的范围内,说明这个约束没有起作用,称这个约束为无效约束
问题就转化为无约束的优化问题
如果约束起作用的话,那么极小值一定在约束的边界上,那么不等式约束就转化为了等式约束
其实就是当前迭代点代进去不等式,如果等号成立(当前迭代点一定在约束的边界上),就是就是有效约束
不成立(当前迭代点在约束的范围内),就是无效约束
相当于,我们通过对约束是否有效的分析,能够将不等式约束和等式约束统一为等式约束
Farkas 引理
书上在 Farkas 引理中的描述,在 a = sum alphai bi 之后似乎还有一句话是错的
相容的意思就是一个东西可以推出另一个东西
alphai 非负,也就是说 a 在 bi 组成的扇形区域内
bi d > 0 表示所有的 bi 都与 d 成锐角
两个命题等价,也就是
“a 在 bi 构成的扇形区域内” 等价于 “d 位于 bi 与 d 成锐角的区域 可以推出 d 位于 a 与 d 成锐角的区域”

Gordan 引理
然后通过 Farkas 引理去证明 Gordan 引理
b1 与 d 成锐角的半圆和 b2 与 d 成锐角的半圆刚好组成一个完整的圆,那就是无解
这种情况下就是 alpha1 b1 + alpha2 b2 = 0,alphai 都是非负了
如果是三个 b 的情况,假设 b1 和 b2 成锐角,那么没有 alpha1 b1 + alpha2 b2 = 0
但是如果有第三个 b3,b3 所在的半圆和 “b1 与 b2 两个半圆的公共扇形”没有交集的话
那么仍然有 alpha1 b1 + alpha2 b2 + alpha3 b3 = 0 alphai 都是非负

不等式约束问题的几何最优性条件
如果是局部极小值,说明可行方向里面没有方向再下降了,能在下降就不是局部极小值了,所以也就是可行方向集与下降方向集交集为空集
也就是不等式组
f 梯度 · d < 0
-gi 梯度 · d < 0
这就跟之前 Gordan 引理里面的 biTd < 0 中的 bi 是一样的
不等式约束问题的 KT 条件
不等式约束问题的 KT 条件(不等式约束问题的一阶必要条件)

一般约束问题的最优性条件
不等式约束和等式约束统一为等式约束
之前我们等式约束那里, λ \lambda λ 没有限定正负
但是在这里,不等式约束有额外的要求是, λ > 0 \lambda > 0 λ>0
因为我们需要确定,g 的梯度的方向是指向 g > 0 的区域
对于不等式约束 g ( x ) ⩽ 0 g(x) \leqslant 0 g(x)⩽0 那么它的要求就是 λ < 0 \lambda < 0 λ<0
原本的,无效约束的情况是
g(x) > 0
f 梯度 = 0
有效约束的情况是
g(x) = 0
f 梯度 = λ \lambda λ g 梯度
现在我们可以把无效约束的条件和有效约束的条件统一起来,
因为无效约束的话,相当于 λ = 0 \lambda=0 λ=0
所以无效约束的条件写为
g(x) > 0
f 梯度 = λ \lambda λ g 梯度 = 0
也是可以的
那么再进一步,无效约束和有效约束的条件还可以写成同一组式子
g(x) >= 0
f 梯度 = λ \lambda λ g 梯度
λ \lambda λ >= 0
λ \lambda λ g(x) = 0
一阶必要条件
以前的书叫 KT,现在叫 KKT
这称为 KKT 条件

二阶充分条件
跟等式约束一样,也是 d T G d > 0 d^TGd>0 dTGd>0
所以现在的情况是,等式约束有一阶必要条件和二阶充分条件,不等式约束只有一阶必要条件,现在合并起来,一般约束有一阶必要条件和二阶充分条件
约束优化问题的可行方向法
考:处理约束的两大类方法
Zoutendijk 可行方向法
梯度投影法
简约梯度法
Zoutendijk 可行方向法
可行方向
考:可行方向,下降可行方向
可行方向:从 x k x_k xk 沿 d d d 做微小移动得到的新的点 x k + 1 x_{k+1} xk+1 也满足约束
下降可行方向:可行方向上,函数值是下降的
所以无约束问题中我们是每一步找下降方向
有约束问题中我们是每一步找下降可行方向
非线性约束下的非线性优化
非线性约束一般是一条曲线
先考虑线性约束的话, E x = e Ex = e Ex=e 写成 E 1 T ( x − x 1 ) = 0 E_1^T (x - x_1) = 0 E1T(x−x1)=0,其中 E 1 T x 1 = e 1 E_1^Tx_1 = e_1 E1Tx1=e1
E 1 T ( x − x 1 ) = 0 E_1^T (x - x_1) = 0 E1T(x−x1)=0 表示一个超平面,E 有 l l l 个的话,解就在 n − l n-l n−l 维的子空间
假设 A x = b Ax = b Ax=b A = [ A 1 A 2 ] , b = [ b 1 b 2 ] A = [A1 A2], b = [b1 b2] A=[A1A2],b=[b1b2]
如果 A 1 x = b 1 , A 2 x > b 2 A_1 x = b_1, A_2 x > b_2 A1x=b1,A2x>b2(如果不是,就把等号的部分提到前面来)
那么就是 A 1 A_1 A1 这部分约束起作用了, A 2 A_2 A2 没有
d 是 x 处的下降可行方向的充要条件
A 1 d > = 0 A_1 d >= 0 A1d>=0
E d = 0 E d = 0 Ed=0
∇ f ( x ) T d < 0 \nabla f(x)T d < 0 ∇f(x)Td<0
前两个表示可行
第三个表示下降
证明:
走之前 E 1 x k = e 1 E_1 x_k = e_1 E1xk=e1 走之后 E 1 x k + 1 = e 1 E_1 x_{k+1} = e_1 E1xk+1=e1 两式相减就是 E1 d = 0
走之前 A1 xk = 0 走之后 A1 xk+1 >= 0 两式相减就是 A1 d >= 0
这里也看出,这和无效约束 A2 无关
问题转化
问题从 min f ( x ) \min f(x) minf(x) 转化为 min ∇ f ( x ) T d \min \nabla f(x)^T d min∇f(x)Td
区别在于 原来的 f 是一个非线性的,现在的 ∇ f ( x ) T \nabla f(x)^T ∇f(x)T 是线性的
现在就是线性规划问题,他的解一定在边界上
如果 ∇ f \nabla f ∇f 与 d d d 成一个钝角,那么如果 d d d 不断变大,那么 ∇ f ( x ) T d < 0 \nabla f(x)^T d < 0 ∇f(x)Td<0 会不断变小,这样违背了我们 min n a b l a f ( x ) T d \min nabla f(x)^T d minnablaf(x)Td 的初衷
所以我们要约束 d 的大小
但是我们是用 -1 <= d <= 1 来约束的,为什么不用 || d || = 1 之类的来约束?
因为二范数相当于 sqrt(d1^2 + d2^2 + …) = 1 是一个非线性的约束
我们本来就转化为了线性的约束,不希望再求非线性的约束
迭代时满足约束
现在我们是迭代 x + alpha d
这个 alpha 肯定有限制,不能让下一步超出可行域了
想象一个线性约束,可行域是一个多边形,不能超出这个多边形
一维线搜索问题是 min f(x + alpha d)
alpha 应该大于 0 小于某个数
alpha = max{alpha | x + alpha d in F}
对于有效约束 A1 xk + alpha A1 dk >= b1
无效约束 A2 xk + alpha A12k >= b2
因为 A1 xk = b1, alpha > 0, A1 dk > 0,所以有效约束这里自然满足
因为 A2 xk > b2 是已经满足的,所以 b2 - A2 xk > 0
现在要证 alpha >= (b2 - A2 xk)/(A2 dk)
A2 dk > 0 时
比如,你已经在右边了,你继续往右走,位置还是在无效约束的右边
等号满足的时候就是你这个点刚好在无效约束上面
A2 dk < 0 时
现在要证 alpha <= (b2 - A2 xk)/(A2 dk)
取最小的正数,就相当于取到了 alpha 的上限
也就是 d 与各个约束的交点可能在约束的前面或者后面
如果交在后面,就是 A2 dk > 0 时,自动满足
如果交在前面,就是 A2 dk < 0 时,这个时候我们要选一个距离本点最近的交点
下降可行方向的条件
∇ g i ( x ) d > 0 \nabla g_i(x) d > 0 ∇gi(x)d>0
i 需要是有效约束
(A1 d)i = 0 表示 A1 d 的某一行是 0 也就是 A1 的某一行就是法向
也就是 d 与 ∇ g i ( x ) \nabla g_i(x) ∇gi(x) 成锐角
问题确定之后 ∇ f \nabla f ∇f 和 ∇ g \nabla g ∇g 都是确定的
线性约束的可行方向法
考: 可行方向法的基本框架
线性约束,可以想象成边界都是直线
-
给定初始点,给定终止误差
-
在第 k 个迭代点 x k x_k xk 处,将不等式约束分为有效约束和非有效约束:
A 1 x k = b 1 , A 2 x k > b 2 A_1 x_k = b_1, A_2 x_k > b_2 A1xk=b1,A2xk>b2
其中, A = [ A 1 A 2 ] , b = [ b 1 b 2 ] A = \left[\begin{array}{ccc} A_1 \\ A_2 \end{array}\right], b = \left[\begin{array}{ccc} b_1 \\ b_2 \end{array}\right] A=[A1A2],b=[b1b2]
-
若 x k x_k xk 是可行域的一个内点(此时没有等式约束,即 E = 0 , A 1 = 0 E = 0, A_1 = 0 E=0,A1=0):
那么,若 ∣ ∣ ∇ f ( x k ) ∣ ∣ < ε \vert \vert \nabla f(x_k) \vert \vert < \varepsilon ∣∣∇f(xk)∣∣<ε,停算,得到近似极小点 x k x_k xk,否则,取搜索方向为 d k = − ∇ f ( x k ) d_k = -\nabla f(x_k) dk=−∇f(xk),转步 6
-
若不为内点,那么,求解线性规划问题
{ min z = ∇ f ( x k ) T d , s . t . A 1 d ⩾ 0 , E d = 0 − 1 ⩽ d i ⩽ 1 , i = 1 , ⋯ , n , \begin{cases} \min z & = \nabla f(x_k)^T d, \\ \mathrm{s.t.} & A_1 d \geqslant 0, \\ & Ed = 0 \\ & -1 \leqslant d_i \leqslant 1, i = 1, \cdots, n, \end{cases} ⎩ ⎨ ⎧minzs.t.=∇f(xk)Td,A1d⩾0,Ed=0−1⩽di⩽1,i=1,⋯,n,
求得最优解为 d k d_k dk 和最优值为 z k z_k zk
-
若 ∣ z ∣ < ε \vert z \vert < \varepsilon ∣z∣<ε,停算,输出 x k x_k xk 作为近似极小点,否则,以 d k d_k dk 作为搜索方向,转步 6
-
首先计算步长的最大值(防止超出可行域),然后进行无约束问题的一维线搜索,获得最优解 α k \alpha_k αk
步长的最大值的确定:
b ˉ = b 2 − A 2 x k , d ˉ = A 2 d k \bar{b} = b_2 - A_2 x_k, \bar{d} = A_2 d_k bˉ=b2−A2xk,dˉ=A2dk
α ˉ = min { b i ˉ d i ˉ ∣ d i < 0 } \bar{\alpha} = \min\{\dfrac{\bar{bi}}{\bar{di}} \vert di < 0\} αˉ=min{diˉbiˉ∣di<0},如果 di 不全大于 0
这里 ∣ d i < 0 \vert di < 0 ∣di<0 表示只在 d i < 0 di < 0 di<0 时才考虑对应的 b i ˉ d i ˉ \dfrac{\bar{bi}}{\bar{di}} diˉbiˉ,是集合里面那个 ∣ \vert ∣
如果 di 全大于 0,那么可以一定找到一个很大的 α \alpha α 使得 α d > b \alpha d > b αd>b 成立,所以此时 α ˉ = ∞ \bar{\alpha} = \infty αˉ=∞,也就是 α \alpha α 没有限制
会不会有存在一个 d b 使得 α 无论取什么值, α d > b \alpha d > b αd>b 都不成立?不过应该是不会,毕竟是从约束推出来的
{ min f ( x k + α d k ) , s . t . 0 ⩽ α ⩽ α ˉ , \begin{cases} \min f(x_k + \alpha d_k), \\ \mathrm{s.t.} & 0 \leqslant \alpha \leqslant \bar{\alpha}, \end{cases} {minf(xk+αdk),s.t.0⩽α⩽αˉ,
-
置 x k + 1 : = x k + α k d k , k : = k + 1 x_{k+1} := x_k + \alpha_k d_k, k := k + 1 xk+1:=xk+αkdk,k:=k+1,转步 2
非线性约束的可行方向法
梯度投影法
考:可行方向法的梯度投影法的基本思想
x 在边界上的时候,就在边界上找最小点
也就是取负梯度向边界面交集的投影作为搜索方向
x 不在边界上的时候,就直接取负梯度作为搜索方向(或者是拟牛顿,或者是共轭梯度)
剩下的问题就是,怎么把一个向量投影到边界上
怎么把一个向量投影到边界上
投影到 a 向量
设 P a P_a Pa 为将某向量 b 投影到 a 上的投影矩阵
P a b = p a P_a b = pa Pab=pa
投影到 A 矩阵
P A P_A PA 的含义就是把 b 投影到 A 的列向量组成的线性空间的投影矩阵
P A b = A x P_A b = Ax PAb=Ax
x 是 b 投影之后在 A 的列空间中的系数
怎么求这个系数呢?利用投影的性质
原向量与投影向量之间的差,垂直于 A 的列空间
A T ( b − A x ) = 0 A^T(b - Ax) = 0 AT(b−Ax)=0
得 A T b − A T A x = 0 A^T b - A^T A x = 0 ATb−ATAx=0
x = ( A T A ) − 1 A T b x = (A^T A)^{-1} A^T b x=(ATA)−1ATb
那么 P A b = A x P_A b = Ax PAb=Ax 变为
P A b = A ( A T A ) − 1 A T b P_A b = A (A^T A)^{-1} A^T b PAb=A(ATA)−1ATb
那么 P A = A ( A T A ) − 1 A T P_A = A (A^T A)^{-1} A^T PA=A(ATA)−1AT
投影矩阵的性质
1.对称性
两个向量的点积,两个向量交换顺序也不改变它的值
(P b)^T b = b^T (P b)
=> b^T P^T b = b^T P b
那么 P^T = P
2.幂等性
再投影一次,还是它本身
P P b = P b
也就是 P^2 = P
也就是 P^n = P
3.半正定
投影之后的向量和投影之前的向量的夹角小于 90 度
(P b)^T b >= 0
b^T P^T b >= 0
b^T P b >= 0
4.垂直的另一个
(I - P) b = e
e 是垂直的那个向量
那么 I - P 是把 b 投影到与 a 垂直的那个空间
思路应该是从 投影到 a 向量,到投影到 A 矩阵,到投影到 Mx=0 表示的空间,到投影到 Mx=b 表示的空间
所以为什么中间会插进来一个投影的性质来着?
投影到 Mx = 0 表示的空间
记 P M P_M PM 为把某向量投影到 M x = 0 M x = 0 Mx=0 所表示的空间中的投影矩阵
M 1 M_1 M1 是 M M M 的第一行
M 1 x = 0 M_1 x = 0 M1x=0 表示超平面的法向量就是 M 1 M_1 M1
那么 M x = 0 M x = 0 Mx=0 表示每一行表示的超平面的交集
先找 b 向着与 M x = 0 Mx = 0 Mx=0 垂直的空间做投影
我们只需要把 b 向着 M 1 , M 2 , . . . M_1, M_2,... M1,M2,... 张成的空间做投影
那么只需要把之前的 P = A ( A T A ) − 1 A T P = A (A^T A)^{-1} A^T P=A(ATA)−1AT 改一下
之前的那个 A A A 是列向量组成的,现在我们的 M i M_i Mi 是行向量
于是用 M T M^T MT 去替换 A A A
得 M T ( M M T ) − 1 M M^T (M M^T)^{-1} M MT(MMT)−1M
那么 v ⊥ = M T ( M M T ) − 1 M v v⊥ = M^T (M M^T)^{-1} M v v⊥=MT(MMT)−1Mv
那么 v ∥ = v − v ⊥ = ( I − M T ( M M T ) − 1 M ) v v∥ = v - v⊥ = (I - M^T (M M^T)^{-1} M) v v∥=v−v⊥=(I−MT(MMT)−1M)v
也就是 P M = I − M T ( M M T ) − 1 M P_M = I - M^T (M M^T)^{-1} M PM=I−MT(MMT)−1M
投影到 Mx = b 表示的空间
记 P M b P_M^b PMb 是为把某向量投影到 M x = b M x = b Mx=b 所表示的空间中的投影矩阵
这就是一开始我们想要的,投影到可行域的边界
x k + 1 = x k + α d x_{k+1} = x_{k} + \alpha d xk+1=xk+αd
实际上我们是要投影 d
可以想成我们在 x_{k} 的位置建立了一个局部坐标系
将 x k + 1 = x k + α d x_{k+1} = x_{k} + \alpha d xk+1=xk+αd 向 M x = b Mx = b Mx=b 做投影
等价于
将 d = x k + 1 − x k d = x_{k+1} - x_{k} d=xk+1−xk 向 M x = 0 Mx = 0 Mx=0 做投影
因为两个 b b b 相减了
那么 P M b P_M^b PMb 就化归为 P M P_M PM 的问题
P M b ( x k + 1 ) = P M ( x k + 1 − x k ) = P M ( d ) P_M^b(x_{k+1}) = P_M(x_{k+1}-x_{k}) = P_M(d) PMb(xk+1)=PM(xk+1−xk)=PM(d)
考:给你一个方向,计算他的梯度投影方向
就是用 P M = I − M T ( M M T ) − 1 M P_M = I - M^T (M M^T)^{-1} M PM=I−MT(MMT)−1M
P M b ( x k + 1 ) = P M ( x k + 1 − x k ) = P M ( d ) P_M^b(x_{k+1}) = P_M(x_{k+1}-x_{k}) = P_M(d) PMb(xk+1)=PM(xk+1−xk)=PM(d)
A = (A1, A2)
A1 是有效约束 A2 是无效约束
要证 P(-nabla f(xk)) 是一个下降方向
(nabla f(xk))^T P(-nabla f(xk))
= -(nabla f(xk))^T P (nabla f(xk))
因为 P 正定
所以 (nabla f(xk))^T P (nabla f(xk)) > 0
所以 P(-nabla f(xk)) < 0
因为这个情况 P nabla f(xk) 要求 ≠ \ne = 0
所以 不会有 d 垂直于 nabla f(xk)
然后证明是可行方向
如果是 P nabla f(xk) = 0 的情况
也就是搜索方向垂直于边界
但是朝着边界的法向量投影,系数 lambda
如果 lambda > 0 也就是这就是最小值点了
如果 lambda < 0 那就是还没到最小值点
算法流程
先搜边界上的极小值点,搜完之后再往内部走

其中有提到一个 dk 可能等于 0,什么情况会这样呢
M M M 是有效约束 A 1 A_1 A1 和等式约束 E E E 的组合
有一个情况是,如果 M 是可逆矩阵的话,比如说 M 首先是一个方阵,然后你就可以注意一下 M 是不是可逆的。如果确定了 M 是可逆,那么有
P = I − M T ( M M T ) − 1 M = I − M T M T − 1 M − 1 M = I − I = 0 P = I - M^T (M M^T)^{-1} M = I - M^T {M^T}^{-1} M^{-1} M = I - I = 0 P=I−MT(MMT)−1M=I−MTMT−1M−1M=I−I=0
所以 P 乘任何一个向量都是 0,所以可以算出来 dk 是 0
罚函数
考:罚函数的基本思想
根据约束条件的特点将其转化为某种惩罚函数加到目标函数中去, 从而将约束优化问题转化为一系列的无约束优化问题来求解
外罚函数
min f(x)
s.t. hi(x) > 0, i = 1,2, …, l
gi(x) >= 0, i = 1, 2 , …, m
罚函数 P_bar 在可行域里面是 0,在外面是正,距离可行域越远,值越大
P(x) = f(x) + sigma P_bar(x)
随着 sigma 的增大,P 的极小值越来越大
罚函数取为 P(x) = sum hi^2(x) + sum (min(0, gi))^2
在可行域里面 gi >= 0 min(0, gi) = 0
在可行域外面 gi < 0 min(0, gi) = gi
目标函数替换为 P(x, sigma) = f(x) + sigma P(x)
x 在可行域里面 P = 0
x 在可行域外面 P > 0 距离可行域越远,值越大
sigma 越大,sigma * P_bar(x) 也越大
如果要 sigma * P_bar 极小,就是要 P_bar 极小
就是要 x 靠近可行域
min P(x, sigma)
在可行域外惩罚,所以是外罚
∂ P / ∂ x 1 = ∂ P / ∂ x 2 = 0 \partial{P}/\partial{x_1} = \partial{P}/\partial{x_2} = 0 ∂P/∂x1=∂P/∂x2=0
得到的方程组解出 x1 x2 关于 sigma 的表达式
令 sigma 趋于无穷,得到 x1 x2 的值
写成算法也比较简单,就是不断增加 sigma,xk 的变化较小时停止
证明收敛
随着 xk 迭代,P 在增加或不变,P_bar 在减小或不变,f 在增大或不变
证:
(1)
因为 sigma_{k+1} > sigma_{k}
所以 P(x_{k+1}, sigma_{k+1}) > P(x_{k+1}, sigma_{k})
因为 x_{k} 是 P(x, sigma_{k}) 的极小值
对于固定的 sigma,P(x, sigma) 只有一个极小值,所以其他的 x 在 P(x, sigma_{k}) 都大于 P(x_{k}, sigma_{k})
所以 P(x_{k+1}, sigma_{k}) > P(x_{k}, sigma_{k})
即 随着 xk 迭代,P 在增加或不变
(2)
f(x_{k+1}) + sigma_{k} P(x_{k+1}) >= f(x_{k}) + sigma_k P(x_k)
f(x_k) + sigma_{k+1} P(x_{k}) >= f(x_{k+1}) + sigma_{k+1} P(x_{k+1})
两式相加
(sigma_{k+1} - sigma_{k}) (P(x_k) - P_{k+1}) >= 0
因为 (sigma_{k+1} - sigma_{k}) >= 0
所以 (P(x_k) - P_{k+1}) >= 0
也证明了第二个
(3)
再根据 f(x_{k+1}) + sigma_{k} P(x_{k+1}) >= f(x_{k}) + sigma_k P(x_k) 证明了第三个
聚点
在 x_bar 的邻域里面,序列 {x_k} 中有无限个点落在这个领域里面
所以就称这个 x_bar 是序列
继续证
假设 x* 是原问题的可行点
可行点有 P = 0
P(xk, sigma_k) < P(x, sigma_k)
根据之前的引理,所以 P(xk ,sigma_k) 单调递增有上界
f(xk) <= P(xk, sigma_k) < P(x*, sigma_k) = f(x*)
所以 f(xk) 也收敛
lim (sigma P) = lim (P - f) = P_infty - f_infty
sigma -> infty 所以 P -> 0 也就是 x 趋于可行域
再证 x_infty 是全局极小点,即 f(x_infty) = f(x*)
\dots
算法框架
考:怎么构造增广目标函数
考:算法框架
对于
{ min f ( x ) , s . t . h i ( x ) = 0 , g i ( x ) ⩾ 0 , \begin{cases} \min & f(x) , \\ \mathrm{s.t.} & h_i(x) = 0, \\ & g_i(x) \geqslant 0, \end{cases} ⎩ ⎨ ⎧mins.t.f(x),hi(x)=0,gi(x)⩾0,
取罚函数为
P ˉ ( x ) = ∑ h i 2 ( x ) + ∑ [ min { 0 , g i ( x ) } ] 2 \bar{P}(x) = \sum h_i^2(x) + \sum [\min\{0, g_i(x)\}]^2 Pˉ(x)=∑hi2(x)+∑[min{0,gi(x)}]2
-
给定初始点,终止误差
-
以 x k − 1 x_{k-1} xk−1 为初始点求解子问题:
min x ∈ R n P ( x , σ k ) = f ( x ) + σ k P ˉ ( x ) \min_{x \in \mathcal{R}^n} P(x, \sigma_k) = f(x) + \sigma_k \bar{P}(x) minx∈RnP(x,σk)=f(x)+σkPˉ(x)
令其极小点为 x k x_k xk
-
若 σ k P ˉ ( x k ) ⩽ ε \sigma_k \bar{P}(x_k) \leqslant \varepsilon σkPˉ(xk)⩽ε,停算,输出 x k x_k xk
-
令 σ k + 1 = γ σ k , k = k + 1 \sigma_{k+1} = \gamma \sigma_k, k = k + 1 σk+1=γσk,k=k+1,转步 2
外罚函数可以用在等式约束和不等式约束的时候
没有等式约束的时候就删掉 ∑ h i 2 ( x ) \sum h_i^2(x) ∑hi2(x) 这一项
没有不等式约束的时候就删掉 ∑ [ min { 0 , g i ( x ) } ] 2 \sum [\min\{0, g_i(x)\}]^2 ∑[min{0,gi(x)}]2 这一项
优缺点
xk 可能刚好停在可行域边缘外面一点,对于某些严格要求结果落在可行域的问题是不可接受的
罚函数 sigma 的取值困难,如果取得小,起不到惩罚的作用,如果取得大,可能造成 P 的 Hesse 矩阵很大,条件数很大,导致误差很大,或者是溢出
找到后面的时候 P_bar 会比较小
P_bar 一般是不可微的,导致没有办法使用基于导数的优化方法
这一点指的是在可行域外和可行域内之间的那个相接处可能不连续
但是可以用差分来近似
内点法
在可行域边界上施加了一个很陡的坡,导致迭代点不会走出可行域
罚函数只定义在可行域里面,第一个 x 也落在可行域里面
H_bar 形式 1/g(x) 或者 -ln(g(x))
f(x) + tau H_bar(x)
tau 趋于 0 时,求得的 x 极小点趋于原问题的极小点
算法框架
考:怎么构造增广目标函数
考:算法框架
对于
{ min f ( x ) , g i ( x ) ⩾ 0 , \begin{cases} \min & f(x) , \\ & g_i(x) \geqslant 0, \end{cases} {minf(x),gi(x)⩾0,
取罚函数为
H ˉ ( x ) = ∑ 1 g i ( x ) \bar{H}(x) = \sum \dfrac{1}{g_i(x)} Hˉ(x)=∑gi(x)1
或
H ˉ ( x ) = − ∑ ln [ g i ( x ) ] \bar{H}(x) = - \sum \ln[g_i(x)] Hˉ(x)=−∑ln[gi(x)]
-
给定初始点,终止误差
-
以 x k − 1 x_{k-1} xk−1 为初始点求解子问题:
min x ∈ R n H ( x , σ k ) = f ( x ) + τ k H ˉ ( x ) \min_{x \in \mathcal{R}^n} H(x, \sigma_k) = f(x) + \tau_k \bar{H}(x) minx∈RnH(x,σk)=f(x)+τkHˉ(x)
令其极小点为 x k x_k xk
-
若 τ k H ˉ ( x k ) ⩽ ε \tau_k \bar{H}(x_k) \leqslant \varepsilon τkHˉ(xk)⩽ε,停算,输出 x k x_k xk
-
令 τ k + 1 = ρ τ k , k = k + 1 \tau_{k+1} = \rho \tau_k, k = k + 1 τk+1=ρτk,k=k+1,转步 2
内点法只能用在不等式约束里面
你看他那个罚函数,只有 g
证明收敛
引理
H(x_{k+1}, tau_{k+1}) = f(x_{k+1}) + tau H_bar(x_{k+1})
=
\dots
H 单调下降
定理
任意一聚点都是全局极小点
H = f + tau_k H
优缺点
初始值要求在可行域里面
找到的值一定在可行域里面
不能适用于等式约束
随着迭代的推进,解趋于边界,罚参数越来越小,矩阵的病态程度越来越大
乘子法(PH 算法)
乘子法就是为了解决外罚函数和内罚函数的这些缺陷
假设现在 h(x) >= 0,右边界区域不起作用
f ( x ) − λ ∗ h ( x ) f(x) - \lambda^* h(x) f(x)−λ∗h(x)
在 P’(x) 的基础上不断减 P’_bar(x) 不会影响迭代点,因为不会影响 P’ 的分布
但是在 P’(x) 的基础上减去水平线 h’(x),相当于整体向下拉,向下拉到一定程度,刚好为 0 的解就刚好靠在
设 x* lambda* 是 KT 点,那么如果 x* 在可行域里面,那么
L(x*, lambda*) = f(x*) - lambda* h(x*) = 0
根据最优性条件,h(x*) = 0
对于其他 x,就会有
L(x*, lambda*) = f(x*) < = f(x) = f(x) - lambda* h(x) = L(x, lambda*)
也就是原来的等式约束问题转化为 min L(x, lambda*)
此问题可以再用外罚函数的方法来求解,其增广目标函数为
Phi(x, lambda*, sigma) = L(x, lambda*) + sigma / 2 * || h(x) ||^2
可以证明,sigma > 0 适当大的时候,x* 是 Phi(x, lambda*, sigma) 的极小点
问题在于,乘子向量 lambda* 并不一致,故而增广函数中乘子向量应当视为未知
按照以下步骤迭代求解
先取一个 lambda = lambda0,求 Phi(x, lambda0, sigma) 的极值点 x0
然后改变 lambda 的值,再求新的 x1
直到 lambda 趋向 lambda* 及 x 趋向 x*
如何改变 lambda 的值?
假设第 k 次我们求解得到 Phi(x, lambdak, sigma) 的极值点 xk
那么由该步极值条件可知 nabla Phi(x, lambdak, sigma) = 0
展开 Phi,得
展:
Phi = L(x, lambda*) + sigma / 2 * || h(x) ||^2
= f(x*) - lambda* h(x*) + sigma / 2 * || h(x) ||^2
那么展开得
nabla f(x*) - nabla lambda* h(x*) + sigma (nabla h(x)) h(x) = 0
即
nabla f(x*) - (nabla h(x))(\lambda - sigma h(x)) = 0
又因为 KT 点满足
nabla f(x*) - (nabla h(x*)) lambda* = 0, h(x*) = 0
两式对比,所以希望 \lambda - sigma h(x) 逼近 lambda*
所以取 lambda_{k+1} = lambda_k - sigma h(x_k) = 0
可见向量序列 x_k 收敛的充要条件为 h(x_k) -> 0
也要证明 h(x_k) -> 0 也是 (x_K, lambda_k) 为 KT 点的充要条件
PH 算法流程
考:怎么构造增广目标函数
考:算法框架
对于
{ min f ( x ) , h i ( x ) = 0 , \begin{cases} \min & f(x) , \\ & h_i(x) = 0, \end{cases} {minf(x),hi(x)=0,
先设拉格朗日函数,然后再使用外罚
最后的增广函数为
f ( x ) − λ T h ( x ) + σ 2 ∣ ∣ h ( x ) ∣ ∣ 2 f(x) - \lambda^T h(x) + \dfrac{\sigma}{2}\vert \vert h(x)\vert \vert^2 f(x)−λTh(x)+2σ∣∣h(x)∣∣2
或
H ˉ ( x ) = − ∑ ln [ g i ( x ) ] \bar{H}(x) = - \sum \ln[g_i(x)] Hˉ(x)=−∑ln[gi(x)]
-
给定初始点,终止误差
-
以 x k − 1 x_{k-1} xk−1 为初始点求解子问题:
min x ∈ R n Φ ( x , λ k , σ k ) = f ( x ) − λ k T h ( x ) + σ k 2 ∣ ∣ h ( x ) ∣ ∣ 2 \min_{x \in \mathcal{R}^n} \Phi(x, \lambda_k, \sigma_k) = f(x) - \lambda_k^T h(x) + \dfrac{\sigma_k}{2}\vert \vert h(x)\vert \vert^2 minx∈RnΦ(x,λk,σk)=f(x)−λkTh(x)+2σk∣∣h(x)∣∣2
令其极小点为 x k x_k xk
-
若 ∣ ∣ h ( x k ) ∣ ∣ ⩽ ε \vert \vert h(x_k)\vert \vert \leqslant \varepsilon ∣∣h(xk)∣∣⩽ε,停算,输出 x k x_k xk
-
更新罚参数
若 ∣ ∣ h ( x k ) ∣ ∣ ⩾ θ ∣ ∣ h ( x k − 1 ) ∣ ∣ \vert \vert h(x_k)\vert \vert \geqslant \theta \vert \vert h(x_{k-1})\vert \vert ∣∣h(xk)∣∣⩾θ∣∣h(xk−1)∣∣,令 σ k + 1 = η σ k \sigma_{k+1} = \eta \sigma_k σk+1=ησk,否则 σ k + 1 = σ k \sigma_{k+1} = \sigma_k σk+1=σk
-
更新乘子向量
令 λ k + 1 = λ k − σ k h ( x k ) \lambda_{k+1} = \lambda_k - \sigma_k h(x_k) λk+1=λk−σkh(xk)
-
k = k + 1 转步 2
划重点
绪论
考线代的常识
线性代数方程的解,存在性
无约束问题的最优性条件
必要条件,充分条件
一阶必要条件 梯度为 0
二阶必要条件 Hessian 矩阵半正定
二阶充分条件 Hessian 矩阵正定
什么是凸集,凸函数
多元函数
二次函数什么时候有最小值
Hessian 矩阵正定表示什么含义
表示抛物面的开口朝上,所以必然有最小值
线搜索的框架
循环的每一步先找搜索方向,然后在这个方向上找极小值
常用方法的收敛速度
最速下降 一次收敛
牛顿 二次收敛
判断迭代是否终止的判据
进退法:找到高低高三个点
黄金分割法、抛物线法:新找到的点与旧的低点之间的距离小于 ε \varepsilon ε
Armijo 准则: f ( x k + β m d k ) ⩽ f ( x k ) + σ β m g k T d k f(x_k +\beta^m d_k) \leqslant f(x_k) + \sigma \beta^m g_k^T d_k f(xk+βmdk)⩽f(xk)+σβmgkTdk
最速下降法、各个牛顿法、共轭方向法、共轭梯度法、BFGS, DFP: ∣ ∣ g k ∣ ∣ ⩽ ε \vert \vert g_k \vert \vert \leqslant \varepsilon ∣∣gk∣∣⩽ε
线搜索
已知搜索方向,给出一维方向上的表达式
单峰区间的原理和步骤
高低高三个点
找完单峰区间之后,黄金分割
黄金分割的原理,具体步骤
比如给出黄金分割三个点
精确线搜索的牛顿法的具体公式
给你一个函数,一个 xk,算一下 x_{k+1}
精确线搜索的抛物线方法
给三个点,算出第四个点,然后之后要用哪三个点做下一步的迭代?
Armijo 准则知道怎么算
为了保证收敛,每一步的搜索方向有什么要求
搜索方向与负梯度方向夹成一个锐角
梯度法
最速下降法
多维情况下的牛顿法
给定多维函数,给 xk 算 x_{k+1}
牛顿法的优缺点
梯度法的优缺点
共轭梯度法,拟牛顿方法为了要提出这些方法,为了解决什么问题
梯度方法的缺点,收敛速度慢
拟牛顿方法收敛速度快
收敛速度的本质原因是,用于拟合的函数的精度是几阶
共轭方向法
共轭方向法 求极小值,等价于求梯度为 0 的点,等价于求线性代数方程组
要么用直接法,要么用迭代法
在正交的坐标系里面找,那么每一个未知数的值就可以独立求解
找完了之后就可以不用管了
共轭方向的概念,给你几个方向,怎么转化成共轭方向
知道每一步的共轭方向怎么来的
分两个,一个是线性问题的共轭方向,一个是非线性问题的
对于线性问题的,
β k − 1 = g k T G d k − 1 d k − 1 T G d k − 1 = g k T ( g k − g k − 1 ) d k − 1 T ( g k − g k − 1 ) = g k T g k d k − 1 T g k − 1 = g k T g k g k − 1 T g k − 1 \beta_{k-1} = \dfrac{g^{T}_{k}Gd_{k-1}}{d^T_{k-1}Gd_{k-1}} = \dfrac{g^{T}_{k}(g_k -g_{k-1})}{d^T_{k-1}(g_k -g_{k-1})} = \dfrac{g^{T}_{k}g_k}{d^{T}_{k-1}g_{k-1}} = \dfrac{g^{T}_{k}g_k}{g^{T}_{k-1}g_{k-1}} βk−1=dk−1TGdk−1gkTGdk−1=dk−1T(gk−gk−1)gkT(gk−gk−1)=dk−1Tgk−1gkTgk=gk−1Tgk−1gkTgk
对于非线性问题,上面的式子就不是等价的了
所以会有多个等式,用其中任意一种就是一个算法
二次终止性
当使用精确线搜索方法时,对于正定二次目标函数极小值问题,共轭方向法在有限步内可以求得极小值,这称为二次终止性
一般的方法没有这个性质
拟牛顿法
每一步保证正定性,所以每一步保证有解
提出的思想是什么
方程是什么
条件是什么
矩阵 B 拟合的是什么矩阵
对称秩一校正公式是怎么得到的
BFGS, DFP 怎么推导得到的
BFGS, DFP 每一步校正的时候,怎么保证 Bk 对称正定
拟牛顿法的收敛速度?有没有二次终止性?
有
有约束的优化问题
几个最优性条件的表示
最优性条件的几何含义
给你一个目标函数的等值线的图,给一个约束函数的区域,判断哪些点是满足必要条件,哪些点是满足充要条件
约束问题的可行方向法
处理约束的两大类方法
可行方向,下降可行方向
目标函数和约束函数的图,判断哪些是可行点
可行方向法的基本框架
循环的每一步,先找下降可行方向,然后沿着这个方向搜索,但是搜索有一个范围
可行方向法的梯度投影法的基本思想
给你一个方向,计算他的梯度投影方向
Wolfe 简约梯度法没讲
约束问题的罚函数方法
罚函数的基本思想
算法框架,基本过程
给你一个简单的目标函数和约束,写出它的增广目标函数,手动算一下它的极值点
外罚函数和内罚函数都是要掌握这些
写出乘子法的增广目标函数,算极值点