数据网格(Data Mesh)
一种新型的数据架构模式,旨在解决传统数据架构中存在的一些问题,例如数据孤岛、数据冗余、数据安全等。数据网格将数据作为一种服务,通过在分布式环境中提供数据服务,实现数据的共享和利用。
以下是数据网格的详细介绍:
-
基本概念
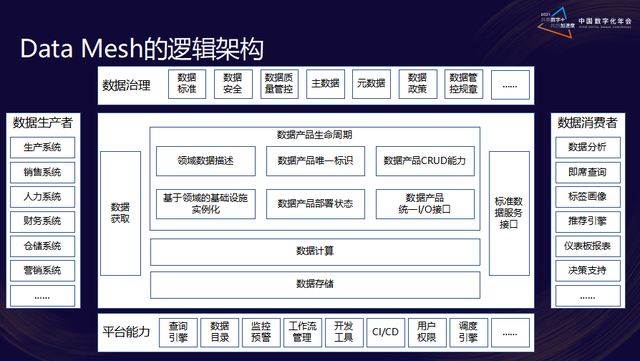
数据网格的基本构成单元是数据产品,数据产品是由数据仓库、数据集市、数据源等组成的。数据网格还包括数据消费者、数据生产者、数据管理员等角色,他们共同协作,实现数据的共享和利用。 -
架构设计
数据网格的架构设计包括数据生产者、数据仓库、数据集市、数据消费者等组件,其中数据生产者是数据源,负责提供数据;数据仓库是数据的存储中心,负责数据的存储、管理和计算;数据集市是数据的展示中心,负责数据的展示和分析;数据消费者是数据的使用者,负责使用数据,并进行数据的反馈和更新。
- 数据治理
数据网格强调数据治理的重要性,包括数据质量、数据安全、数据合规等方面。数据管理员负责数据的治理和管理,包括数据的清洗、整合、标准化等操作。
- 数据服务
数据网格的核心是数据服务,数据生产者提供数据接口,数据消费者使用数据接口,数据仓库和数据集市提供数据计算和分析服务。数据服务的目的是让数据变得可用,提高数据的价值。
- 优点
数据网格的优点包括提高数据的可用性、可靠性和安全性;提高数据的灵活性和可扩展性;提高数据的处理效率和质量;降低数据管理成本和风险。
- 应用场景
数据网格适用于大型企业和组织,可以应用于数据中台、大数据平台、数据仓库等场景,帮助企业实现数据的共享和利用,提高数据的价值和作用。数据网格是一种新型的数据架构模式,它将数据作为一种服务,通过在分布式环境中提供数据服务,实现数据的共享和利用,是数据管理和利用的重要趋势。
数据运维(Data Ops)
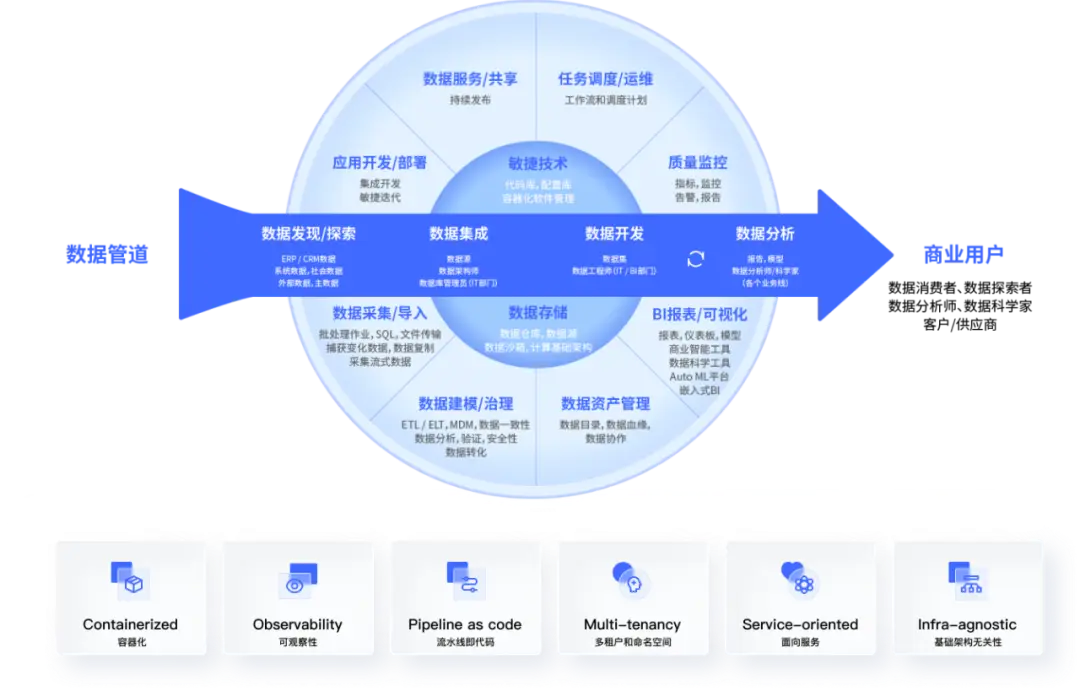
是一种基于运维理念的数据管理方法,它结合了 DevOps、数据仓库和数据科学等领域的思想和技术,旨在提高数据的质量、可靠性和可用性,从而支持企业的业务发展和创新。
数据运维的核心理念是将数据作为一种服务,通过持续集成、持续交付和持续运营的方式,实现数据的快速、可靠和安全的生产、传输和消费。数据运维的主要目标是提高数据的生产率、降低数据的成本、提高数据的质量和可靠性,以及实现数据的合规性和安全性。
目标
DataOps 的目标是提高数据处理的效率和质量,以更快地生成高质量的数据产品。它通过自动化数据处理流程、优化数据管道、提高数据质量和一致性来实现这一目标。
特点
DataOps 具有以下特点:
- 自动化:DataOps 将自动化作为其核心原则之一。它使用自动化工具和流程来简化数据处理流程,从而提高效率和减少错误。
- 可重复:DataOps 强调可重复性,以确保数据处理流程的一致性和准确性。这意味着每次数据处理都应该是可重复的,并且可以在任何时候进行验证。
- 可扩展:DataOps 支持可扩展的数据处理流程,以满足不断变化的业务需求。这意味着数据处理流程可以轻松地扩展,以适应不同的数据规模和复杂性。
- 协作:DataOps 强调团队协作,以确保数据处理流程的顺利进行。这意味着数据团队需要密切合作,以确保数据处理流程的高效性和准确性。
工具
DataOps 使用一系列工具来支持数据处理流程,包括:
数据仓库和平台:例如 Apache Hadoop、Apache Hive、Amazon S3 等。
数据集成工具:例如 Talend、Apache NiFi 等。
数据质量工具:例如 Trifacta、DataCleanBot 等。
持续集成/持续交付(CI/CD)工具:例如 Jenkins、GitLab 等。
数据运维的关键技术包括:
-
数据集成:数据集成是将多个数据源中的数据合并到一个统一的数据仓库或数据集中,以便进行数据分析和决策。数据集成的技术包括 ETL、ETL、数据虚拟化等。
-
数据仓库:数据仓库是一个结构化的数据存储系统,用于支持数据分析和决策。数据仓库的技术包括 SQL、NoSQL 数据库、分布式存储等。
-
数据治理:数据治理是对数据进行管理、监督和控制的过程,以确保数据的准确性、一致性和安全性。数据治理的技术包括数据质量管理、数据安全、数据隐私等。
-
数据分析:数据分析是使用统计学和数据科学技术对大量数据进行处理和分析,以提取有用的信息和洞察。数据分析的技术包括机器学习、深度学习、数据挖掘等。
-
数据可视化:数据可视化是将数据以图形或图像的形式呈现出来,以便更好地理解和分析数据。数据可视化的技术包括报表、仪表盘、数据可视化等。
应用
DataOps 可以应用于各种数据处理场景,包括:
数据科学:DataOps 可以用于数据科学家和数据工程师之间的协作,以快速生成高质量的数据产品。
商业智能:DataOps 可以用于快速生成报告和洞察,以帮助企业做出更好的业务决策。
机器学习:DataOps 可以用于快速迭代机器学习模型,以提高模型的准确性和效率。
总的来说,数据运维是一种基于运维理念的数据管理方法,它结合了 DevOps、数据仓库和数据科学等领域的思想和技术,旨在提高数据的质量、可靠性和可用性,从而支持企业的业务发展和创新。