介绍:
Hierarchical Clustering 是一种常用的聚类方法,它通过构建一个层次化的聚类树(或者称为聚类图),将数据点逐步合并组成不同的聚类簇。
Hierarchical Clustering 的主要思想是将相似的数据点归为一类,然后逐步合并这些类别,最终形成一个层次化的聚类结果。这个过程可以通过两种方式实现:自底向上的聚合(Agglomerative Clustering)和自顶向下的分解(Divisive Clustering)。
自底向上的聚合是一种自底向上逐步合并数据点的方法。首先,将每个数据点视为一个初始的聚类簇。然后,根据某种相似性度量(例如欧氏距离、曼哈顿距离等),计算两个聚类簇之间的相似度。接着,将相似度最高的两个聚类簇合并成一个新的聚类簇,并更新相似度矩阵。重复这个过程,直到所有数据点都合并成一个聚类簇,或者达到预设的聚类数量。
自顶向下的分解则是一种自顶向下逐步划分数据点的方法。首先,将所有数据点视为一个初始的聚类簇。然后,根据某种相似度度量,选择一个聚类簇进行划分,将其分成两个较小的子簇。重复这个过程,直到达到预设的聚类数量或者满足某种停止准则。
无论是自底向上的聚合还是自顶向下的分解,最终都会得到一个层次化的聚类结果,可以通过聚类树或者聚类图来可视化。聚类树的每个节点代表一个聚类簇,而每个分支代表两个聚类簇的合并或划分关系。
Hierarchical Clustering 的优点包括不需要预先指定聚类数量、可以处理非凸形状的聚类簇、适用于不同类型的数据。但它也有一些缺点,例如计算复杂度较高、结果容易受到初始化和相似度度量方式的影响。因此,在使用 Hierarchical Clustering 时,需要根据具体情况选择合适的相似度度量和聚类算法。
数据 :
import pandas as pd#Hierarchical Clusting
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inlinedata = pd.read_csv("customers.csv") 
data.describe()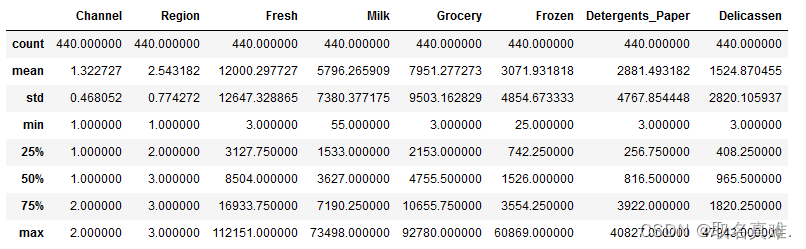
StandardScaler和normalize都是用来对数据进行归一化处理的机器学习预处理方法,但是它们有一些区别:
标准化方法不依赖于数据的分布,而归一化方法则依赖于数据的分布。标准化方法通过对数据进行减去平均值然后除以标准差的操作,将数据转换成均值为0,方差为1的分布。而归一化方法是将数据限定在一个特定的范围内,例如[0, 1]或[-1, 1]。
标准化方法对异常值的处理更加稳健,而归一化方法对异常值更加敏感。标准化方法在计算平均值和标准差时会将所有数据点都考虑在内,因此异常值的影响相对较小。而归一化方法的结果受到最大值和最小值的影响,如果存在异常值,那么最大值和最小值会被拉大或缩小,导致其他数据的变化幅度也增大或减小。
标准化方法保留了数据的原始信息,而归一化方法则改变了数据的原始信息。标准化方法只是对数据进行了线性映射,不改变数据的分布形状和相对大小关系。而归一化方法将数据映射到一个特定的范围内,改变了数据的分布形状和相对大小关系。
综上所述,选择标准化方法还是归一化方法取决于具体的应用场景和数据特点。如果希望保留数据的原始信息并且对异常值有较强的鲁棒性,可以选择标准化方法;如果希望将数据映射到一个特定的范围内并且不关心数据的分布形状和相对大小关系,可以选择归一化方法。
from sklearn.preprocessing import StandardScaler#列
sc=StandardScaler()
scaled_data=sc.fit_transform(data)from sklearn.preprocessing import normalize#行
norm_data=normalize(data)df=pd.DataFrame(scaled_data,columns=data.columns)
df1=pd.DataFrame(norm_data,columns=data.columns)
Dendrogram图:
import scipy.cluster.hierarchy as shc
plt.figure(figsize=[10,7])
plt.title('Dendrogram')
dend=shc.dendrogram(shc.linkage(df,method='ward'))#method表示测距离不同的方法 
import scipy.cluster.hierarchy as shc
plt.figure(figsize=[10,7])
plt.title('Dendrogram')
dend=shc.dendrogram(shc.linkage(df1,method='ward'))#method表示测距离不同的方法 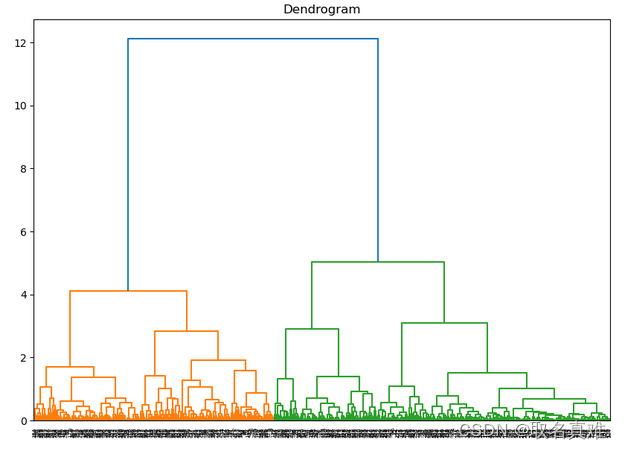
plt.figure(figsize=(10, 7))
plt.title("Dendrograms")
dend = shc.dendrogram(shc.linkage(df1, method='ward'))
plt.axhline(y=6, color='r', linestyle='--') 
建模:
from sklearn.cluster import AgglomerativeClustering
cluster=AgglomerativeClustering(n_clusters=2,affinity='euclidean',linkage='ward')#分成两类,用欧几里得
cluster.fit_predict(df1)'''结果:
array([1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0,0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 1,1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1,1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0,0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1,0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0,0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1,0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1,0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1,0, 0, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 1, 0,0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0,0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1,1, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0,0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0,0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0,0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0, 1,1, 1, 0, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0,0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0,1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 1, 1, 1,1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1],dtype=int64)
'''df1['cluster']=cluster.fit_predict(df1)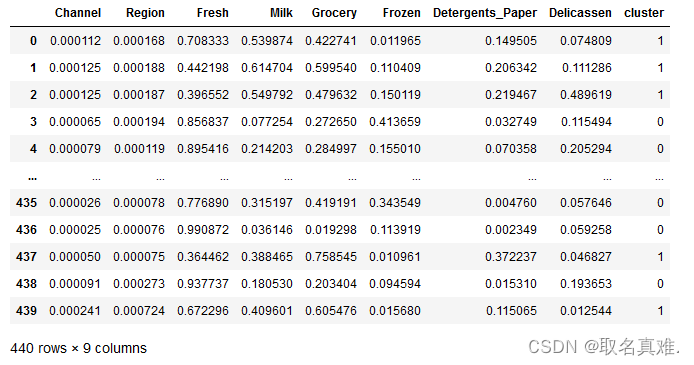
plt.figure(figsize=[10,7])
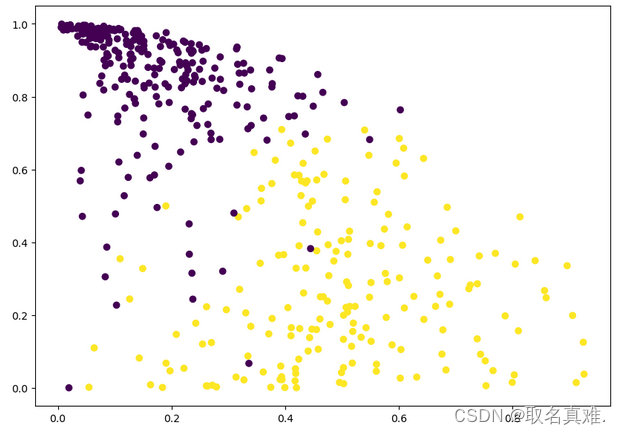
plt.scatter(df1.Milk,df1.Grocery,c=cluster.labels_)#基于Milk和Grocery,可以看出买Milk越多的越少关注Grocery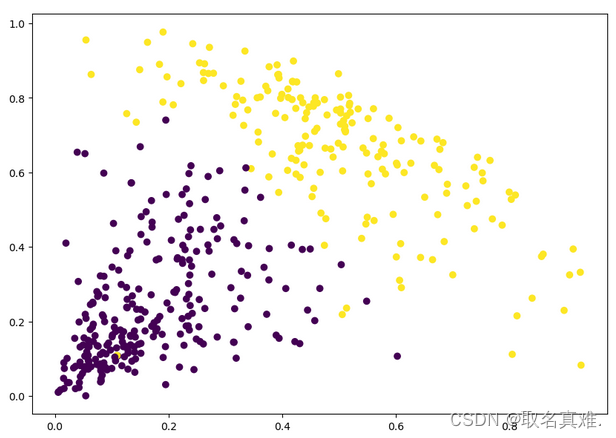
plt.figure(figsize=(10, 7))
plt.scatter(df1['Milk'], df1['Fresh'], c=cluster.labels_) #可以看出越是对新鲜产品关注的,对牛奶更不关注