论文标题:TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones
论文作者:Zhengqing Yuan, Zhaoxu Li, Lichao Sun
作者单位:Anhui Polytechnic University, Nanyang Technological University, Lehigh University
论文原文:https://arxiv.org/abs/2312.16862
论文出处:–
论文被引:–(12/31/2023)
论文代码:https://github.com/DLYuanGod/TinyGPT-V,115 star
Abstract
在先进的多模型学习时代,GPT-4V 等多模态大型语言模型(MLLM)在连接语言和视觉元素方面取得了显著进展。然而,代码闭源和相当大的计算需求为普及使用和修改带来了明显的挑战。这正是 LLaVA 和 MiniGPT-4 等开源 MLLM 的用武之地,它们在各种任务中取得了突破性的成就。尽管取得了这些成就,计算效率仍是一个悬而未决的问题,因为这些模型(如 LLaVA-v1.5-13B)需要大量资源。为了解决这些问题,我们推出了 TinyGPT-V,这是一个将惊人性能与普通计算能力相结合的新潮模型。它只需要 24G GPU 进行训练,8G GPU 或 CPU 进行推理,因此脱颖而出。TinyGPT-V 以 Phi-2 为基础,将有效的语言骨干与 BLIP-2 或 CLIP 的预训练视觉模块相结合。TinyGPT-V 的 2.8B 参数可以经过独特的量化处理,适合在 8G 各种设备上进行本地部署和推理任务。我们的工作促进了设计高性价比,高效和高性能 MLLM 的进一步发展,扩大了它们在广泛现实世界场景中的适用性。此外,本文还提出了通过小型骨干网建立多模态大型语言模型的新范式。
1 Introduction
最近,随着扩展性多模态大语言模型(MLLM)GPT-4V 的问世,我们在视觉语言理解和生成方面看到了一些令人印象深刻的能力[45]。尽管如此,必须承认的是,GPT-4V 并未开源,因此限制了普遍使用和独立修改。从好的方面看,最近开源 MLLMs(如 LLaVA 和 MiniGPT-4)的数量激增,它们在某些任务中表现出了突破性的能力,在图像描述(IC,Image Captioning),视觉问答(VQA)和指代表达理解(Referring Expression Comprehension,REC)等领域超过了 GPT-4V [8, 26, 27, 50]。例如,在各种视觉基础和问题解答任务的测试中,MiniGPT-v2 [6] 与其他传统视觉语言模型相比,表现出了卓越的实力。
尽管一些开源 MLLM 具备强大的视觉语言能力,但它们在训练和推理阶段仍然消耗了过多的计算资源。例如,LLaVA-v1.5-13B [26] 在 25.5 小时的训练过程中使用了 8 个 80GB 显存的 A100 GPU。由于大型语言模型的性能直接影响到 MLLM 的能力,因此在使用这些模型时,如 LLaVA-v1.5-13B 使用 Vicuna-13b-v1.5 [49],MiniGPT-v2 使用 LLaMA2-7B-Chat [41],需要大量的大型语言模型参数来提高 IC,VQA 等复杂任务的性能 [50]。因此,我们需要一个能与 LLaMA2 和 Vicuna-v1.5 等模型性能相媲美的大型语言模型,而不需要过多的 GPU 计算资源。
因此,我们提出了一种名为 TinyGPT-V 的新模型,它只需要 24G GPU 进行训练,推理只需要 8G GPU 或 CPU。
- LLM:采用大型语言模型 Phi-2 [19],该模型是在 Phi [24]的基础上构建的,其效果超过了 13B 语言模型的最佳效果,而且与规模大 25 倍的模型相比,其效果相似或更好。
- 视觉感知:使用了与 BLIP-2 [23] 或 CLIP [35] 相同的预训练视觉模块,其中包含一个作为视觉编码器的 ViT [10] 以及一个映射模块。按照 MiniGPT 的训练方法,TinyGPT-V 在整个训练过程中只微调视觉编码器和语言模型之间的映射模块,而冻结所有其他参数。
- TinyGPT-V 在不同的训练阶段使用与 MiniGPT-v2 相同的数据集,如 LAION [37],Conceptual Captions [4, 39],SBU [33] 等 [25, 38, 18, 21] 。[25, 38, 18, 21, 29, 13, 31, 20, 46]。
在我们的研究中,我们观察到 TinyGPT-V 显示出许多与 GPT-4 相同的特质,从 Phi-2 模型的应用中受益匪浅。TinyGPT-V 仅有 2.8B 个参数,其独特的量化过程使其适用于 8G 移动设备上的本地部署和推理任务。TinyGPT-V 标志着在实现无与伦比的性能和保持 MLLM 效率之间的平衡方面取得了重大进展。通过我们的贡献,我们努力使社区能够设计出更具成本效益,更高效,更高性能的 MLLM,以满足广泛的实际应用场景。
2 Related Work
Advanced language model.
从自然语言处理(NLP)领域的 GPT2 [36] 和 BERT [9] 等早期成功案例开始,语言模型的发展经历了许多重要的里程碑。这些基础模型为随后开发规模更大,包含数千亿个参数的语言模型奠定了基础。规模的急剧扩大导致了先进功能的出现,如 GPT-3 [2],Chinchilla [16],OPT [48] 和 BLOOM [44] 等模型。例如,ChatGPT [32] 和 InstructGPT [34] 利用这些强大的模型来回答各种问题和执行复杂的任务,如coding。LLaMA [41] 等开源 LLM 的引入进一步推动了这一领域的研究,激发了 Alpaca [40],Vicuna [7] 等后续开发。这些模型利用额外的高质量指令数据集对 LLaMA 模型进行了微调,展示了 LLM 框架的多功能性和适应性。最近最显著的进步是 Phi [24] 及其后续产品 Phi-2 [19]。这些模型表现出了卓越的性能,可与规模大 25 倍的模型相媲美,甚至超过它们。这表明语言建模的格局发生了重大变化,它强调效率和效果,而不一定依赖于纯粹的规模。这种发展标志着 NLP 领域进入了一个新时代,更小,更高效的模型可以取得与更大的模型相媲美的结果,为应用和研究开辟了新的可能性。
Multimodal language model.
近年来,将视觉输入与用于视觉语言任务的大型语言模型相匹配的趋势得到了广泛关注[5, 42, 1 , 23 , 28, 26 , 50, 6]。
- VisualGPT [5] 和 Frozen [42] 等开创性工作利用预先训练好的语言模型进行 IC 和 VQA。
- Flamingo [1] 等模型进一步推动了这一方法的发展,这些模型采用了门控交叉注意机制,将预先训练好的视觉编码器和语言模型统一起来,在大量图像-文本对上进行训练。
- BLIP-2 [23] 引入了高效的 Q-Former 来对齐视觉和语言模式。
- 这些开创性的研究为该领域的进一步创新铺平了道路,促成了 LLaVA [28] 和 MiniGPT4 [50] 等模型的开发,以及它们随后的迭代:LLaVA-v1.5 [26],MiniGPT-v2 [6],ArtGPT-4 [47],instruction GPT-4 [43] 和 Instruction Mining [3]。
这些模型通过指令调优展示了先进的多模态能力,展现了非凡的泛化能力。尽管这些多模态语言模型具有强大的视觉语言任务能力,但通常需要大量的计算资源。相比之下,TinyGPT-V 代表了一种范式的转变,它利用成本效益高,功能强大的小型语言模型,实现了一种适用于各种真实世界视觉语言应用的稳健,易于部署的模型。这种方法强调了向更高效但同样胜任的多模态语言建模迈进的趋势。
3 Method
我们首先提出了我们的视觉语言模型TinyGGPT-V,然后讨论了模型的结构和任务的组织,最后介绍了每个阶段的训练过程。
3.1 Model Architecture
在本小节中,我们介绍了TinyGPT-V的结构,它由视觉编码器线性投影层和大型语言模型组成。
Visual encoder backbone.
与 MiniGPT-v2 一样,ViT 的 EVA [11] 在 TinyGPT-V 适应过程中充当视觉基础模型。在整个模型训练过程中,视觉基础模型始终处于冻结状态。我们的模型训练在第一,第二和第三阶段以 224x224 的图片分辨率运行,在第四阶段以 448x448 的图片分辨率运行。
Linear projection layers.
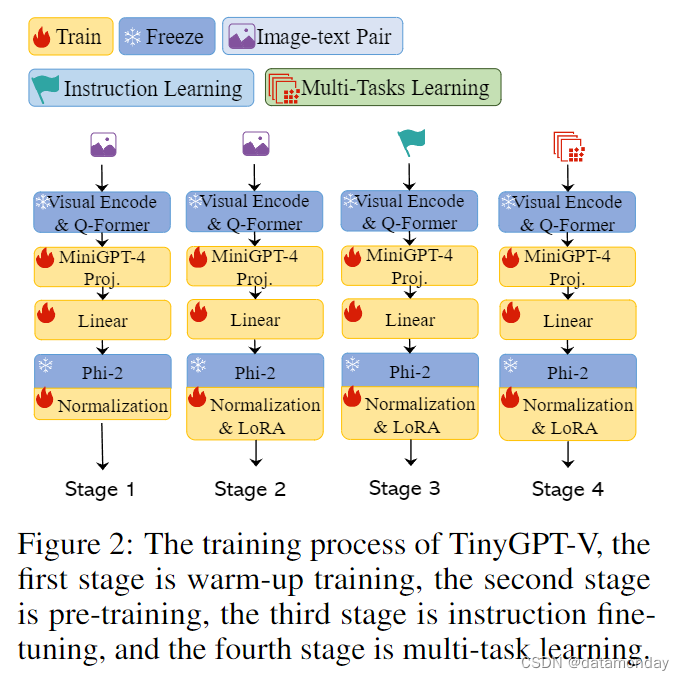
线性投影层的功能是将视觉编码器提取的视觉特征嵌入语言模型。同时,还努力使广泛的语言模型能够理解基于图像的信息。我们之所以采用源自 BLIP-2 [23] 架构的 Q-Former 层作为初始线性投影层,是因为我们希望在视觉语言模型中部署预训练 BLIP 系统时,能够从中提取最大的功能。这种方法大大减少了需要训练阶段的参数量。我们利用高斯分布初始化的线性投影层作为第二层。这样做的目的是弥合 Q-Former 输出与语言模型嵌入层之间的维度差距,从而更好地将视觉标记与语言模型的相关隐藏空间对齐。如图 2 所示,为了加快 TinyGPT-V 的训练过程,我们首先使用 MiniGPT-4 (Vicuna 7B)中预先训练好的线性投影作为基础层。随后,我们整合了一个额外的线性层投影,以有效衔接 Phi-2 模型的相应隐藏空间。
Large lanuguage model backbone.
我们利用 Phi-2 [19] 模型作为 TinyGPT-V 大型语言模型的骨干。Phi-2 是一个拥有 27 亿参数的语言模型,具有出色的推理能力和语言理解能力,在参数少于 130 亿的基础语言模型中表现出最先进的性能。在复杂的基准测试中,Phi-2 的性能可媲美或超越 25 倍以上的大多数模型。我们完全依靠 Phi-2 语言标记(token)来执行多项视觉语言操作。对于需要创建空间位置的视觉锚定任务,我们明确要求语言模型生成文本描述的边界框,以表示其地理坐标。
Normalization and LoRA for TinyGPT-V
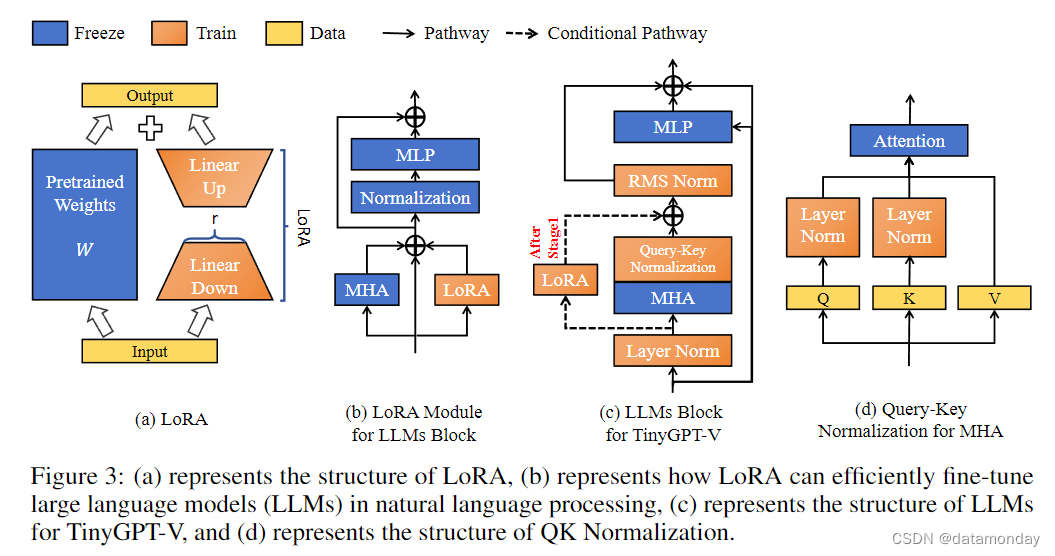
在第 4.3 节中,我们推断,训练较小规模的大型语言模型进行迁移学习,尤其是跨不同模态(如从文本到图像)的迁移学习,会带来巨大的挑战。我们的研究发现,较小的模型在多模态数据计算过程中特别容易出现 NaN 或 INF 值。这通常会导致计算损失值为 NaN,从而导致初始批量前向传播失败。此外,在这些较小的模型中,可训练参数的数量有限,这也会导致在整个训练过程中梯度消失。为了解决这些问题,如图 3 © 所示,我们整合了 LLaMA-2 的后规范化(post-norm)和输入规范化(input norm)机制,在每个多头注意力层 (MHA) 之后实施 RMS Norm,以规范后续层的数据。我们还更新了 Phi-2 模型中所有层的规范,以提高训练的稳定性,如下式所示。

此外,Henry et.al [15] 强调了 Query-Key Normalization 在低资源学习场景中的重要作用。因此,如图 3 (d) 所示,我们在 Phi-2 模型中加入了 “Query-Key Normalization”,详见下式。
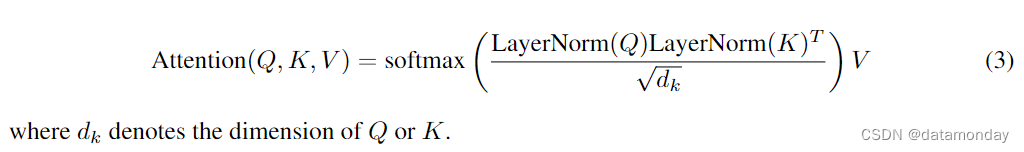
LoRA 机制[17]的结构如图 3(a)所示,它是一种与图 3(c)所示的冻结预训练权重并行的高效微调方法,不会增加大型语言模型的推理耗时,也更容易优化。
3.2 Multi-task Instruction Template
在训练统一的多模态模型以处理视觉问答(VQA),图像描述(IC),指代表达理解(REC),生成以及物体解析和定位(object parsing and grounding)等不同任务时,为了减少潜在的模糊性,我们在多任务指令模板中使用了 MiniGPT-v2 特定任务标记。它源于 LLaMA-2 对话模板[41],包括由图像特征,任务标识符和指令输入组成的通用输入格式。它有六个不同的任务标识符,每个都与特定任务相关。对于需要模型识别所指对象空间位置的任务,它采用文本格式的边界框,坐标归一化范围为 0 到 100。总之,MiniGPT-v2 提供的独特任务特定标记有助于任务之间的歧义区分,从而使任务执行更加精确和准确。
3.3 Training Stages
在本小节中,将描述 TinyGT-V 的三阶段训练过程。
Warm-up training for the first training stage.
在最初的预训练阶段,TinyGPT-V 使用一个大型的对齐图像-文本对库学习视觉-语言理解。该模型将引入的投影层输出识别为软提示,引导其创建相关文本,并允许大型语言模型接受来自图像模态的输入。预训练过程使用了 Conceptual Caption,SBU 和 LAION 的组合数据集,训练 20000 步,约 500 万个图像-文本对。
Pre-training for the second training stage.
在初始训练阶段之后,大语言模型便具备了处理图像模态输入的能力。为了保证模型在过渡到后续训练阶段时性能更加稳定,我们重新使用了第一阶段的数据集,专门用于训练 LoRA 模块。
Human-like learning for the third training stage.
我们从 MiniGPT4 或 LLaVA 中选择了一些图像-文本对(image-text pairings),对 TinyGPT-V 模型进行了微调,其中包括以下指令:
"###Human: <Img><ImageHere></Img> Take a look at this image and describe what you notice.###Assistant:."
我们使用了一个统一的模板(Template),包括随机选择的提示(Prompt),这提高了模型生成一致且更自然的响应的能力。
Multi-task learning in the fourth training stage.
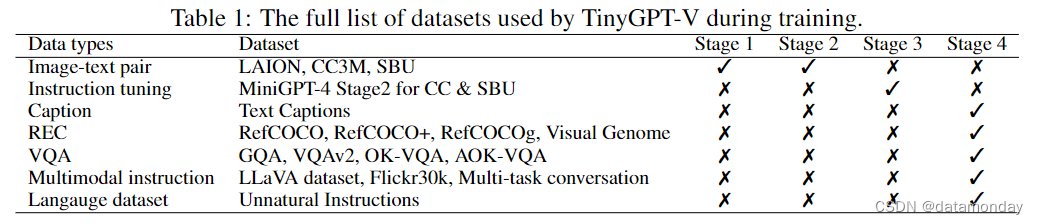
TinyGPT-V 的第四个训练阶段与 MiniGPT-v2 相同,主要是通过使用更多的多模态指令数据集来微调模型,从而增强其作为聊天机器人的对话能力。如表 1 所示,这些数据集包括 LLaVA,混合多任务数据集 Flickr30k 和非自然指令。
- LLaVA 数据集用于多模态指令调优,其中包含详细描述和复杂推理示例。
- Flickr30k 数据集用于改进基础图像标题生成以及对象解析和基础能力。
- 此外,还创建了一个混合多任务数据集,以提高模型在多轮对话中处理多个任务的能力。
- 最后,为了恢复语言生成能力,在 TinyGPT-V 的第三阶段训练中加入了非自然指令数据集。
4 Experiments
在本节中,我们将详细介绍训练和评估方法。
4.1 Training
Experimental setting.
硬件环境:NVIDIA 24GB 显存的 RTX 3090 GPU,AMD EPYC 7552 48 core CPU,80GB RAM。
软件环境:PyTorch 2.0.0 ,CUDA 11.8,便于在 GPU 上进行优化的张量操作。
Training process.
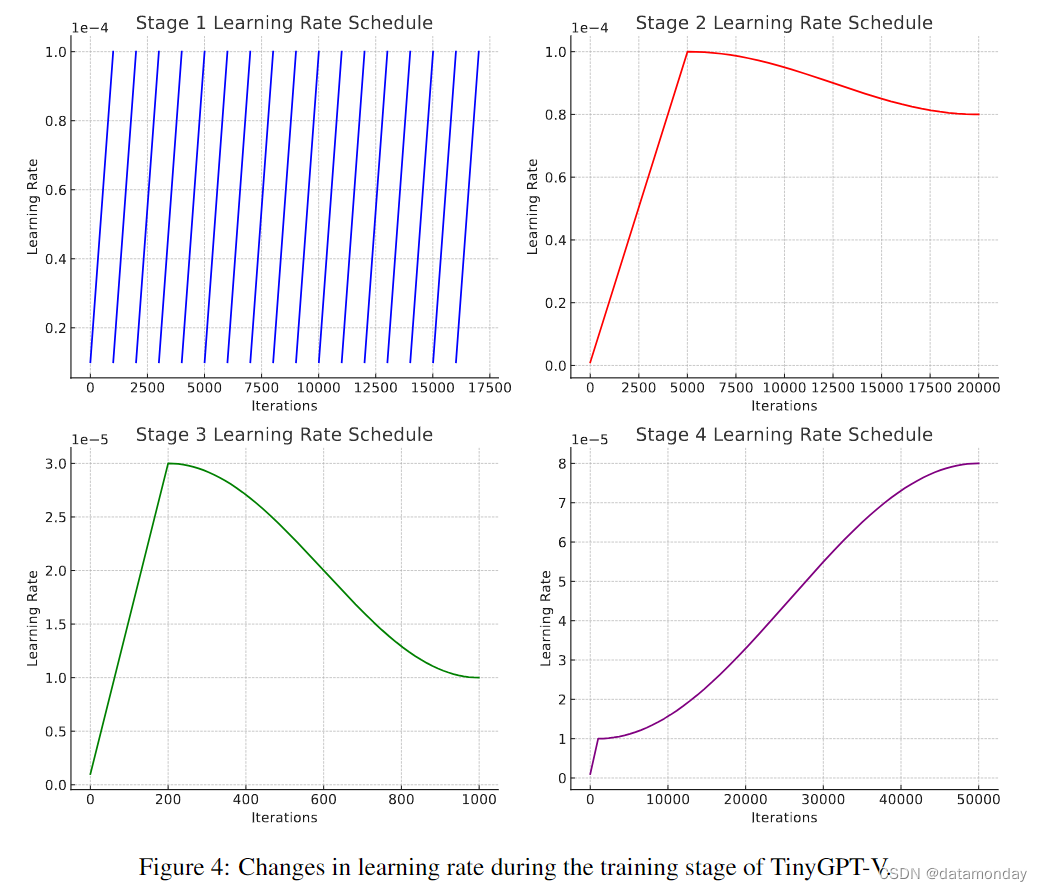
如图 4 和图 5 所示,在实验过程中,我们通过四个不同的阶段精心安排了模型的训练,每个阶段都有特定的学习率策略和损失曲线。
第 1 阶段:采用动态学习率方法,17 个epoch,每个 epoch 包含 1000 次迭代。每个epoch 开始时的学习率为1e-5,到epoch结束时逐渐升至1e-4。所有epoch中均遵从这种模式。训练损失呈现出稳步下降的趋势,从 7.152 开始,逐渐下降到 2.620,反映出模型从数据中学习的能力在不断提高。这一阶段的目的是让 TinyGPT-V 中的 Phi-2 模型对图像模态的输入做出某种反应。完成文本和图像在语义空间中的对齐。
第 2 阶段:4 个epoch,每个 epoch 迭代 5000 次,采用 linear_warmup_cosine_lr[14, 12] 学习率计划。warmup 阶段 5000 步,学习率从 1e-6(warmup_lr)线性上升到 1e-4(init_lr),然后余弦衰减到最低学习率 8e-5。在这一阶段,损失持续减少,从 2.726 开始,最终达到 2.343。这一阶段的目的是让 LoRA 模块在多模态数据中发挥作用,进一步降低模型在图像-文本对上的损失,提高模型从数据中学习的能力。
第 3 阶段:5 个epoch,每个 epoch 迭代 200 次。采用 linear_warmup_cosine_lr 计划,热身阶段为 200 步。学习率从 1e-6,上升到 3e-5(init_lr),然后下降到 1e-5(min_lr)。损失值从 1.992 开始下降到 1.125,反映了明显的改进。这一阶段的目的是让 TinyGPT-V 同时接受语言和图像模态输入,并对它们做出响应。经过这一阶段的训练,TinyGPT-V 已能完成大部分图像回答任务。
第 4 阶段:50 个epoch,每个 epoch 迭代 1000 次。采用 linear_warmup_cosine_lr 计划,warmup 阶段 1000 步。学习率从 1e-6 开始,最高达到 1e-5(init_lr),然后经历余弦衰减,最低为 8e-5。训练损失值呈持续下降趋势,从 2.720 开始,最终降至 1.399。这一阶段的目的是让 TinyGPT-V 同时执行各种任务,如 VQA 或 VSR 任务,从而提高 TinyGPT-V 在多模态任务上的泛化性能。
4.2 Evaluation
Evaluation datasets.
- GQA [18] 是一个用于真实世界视觉推理和组合问题解答的数据集,其强大的问题引擎可生成 2200 万个不同的推理问题。
- VSR [28] 包含 1 万多个英文自然文本-图像对,涵盖 66 种空间关系。
- IconQA [30] 包含 107439 个问题,旨在挑战图标图像背景下的视觉理解和推理,包括三个子任务(多图像选择,多文本选择和填空)。
- VizWiz[13]收集了 31000 多个视觉问题,每个问题都来自视障人士使用智能手机拍摄的一张照片,并附有一个与图像相关的发声问题,每个问题还有10个来自人群的答案。
- 由 Facebook AI 开发的 Hateful Memes dataset (HM) [22]是一个全面的多模态数据集,专门用于检测备忘录中的仇恨内容,结合了图像和文本元素,包含 10000 多个新创建的多模态示例。
Visual question answering results.
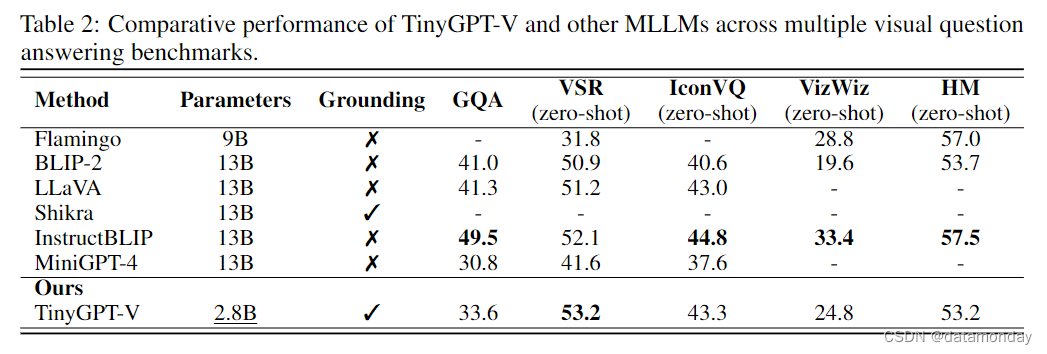
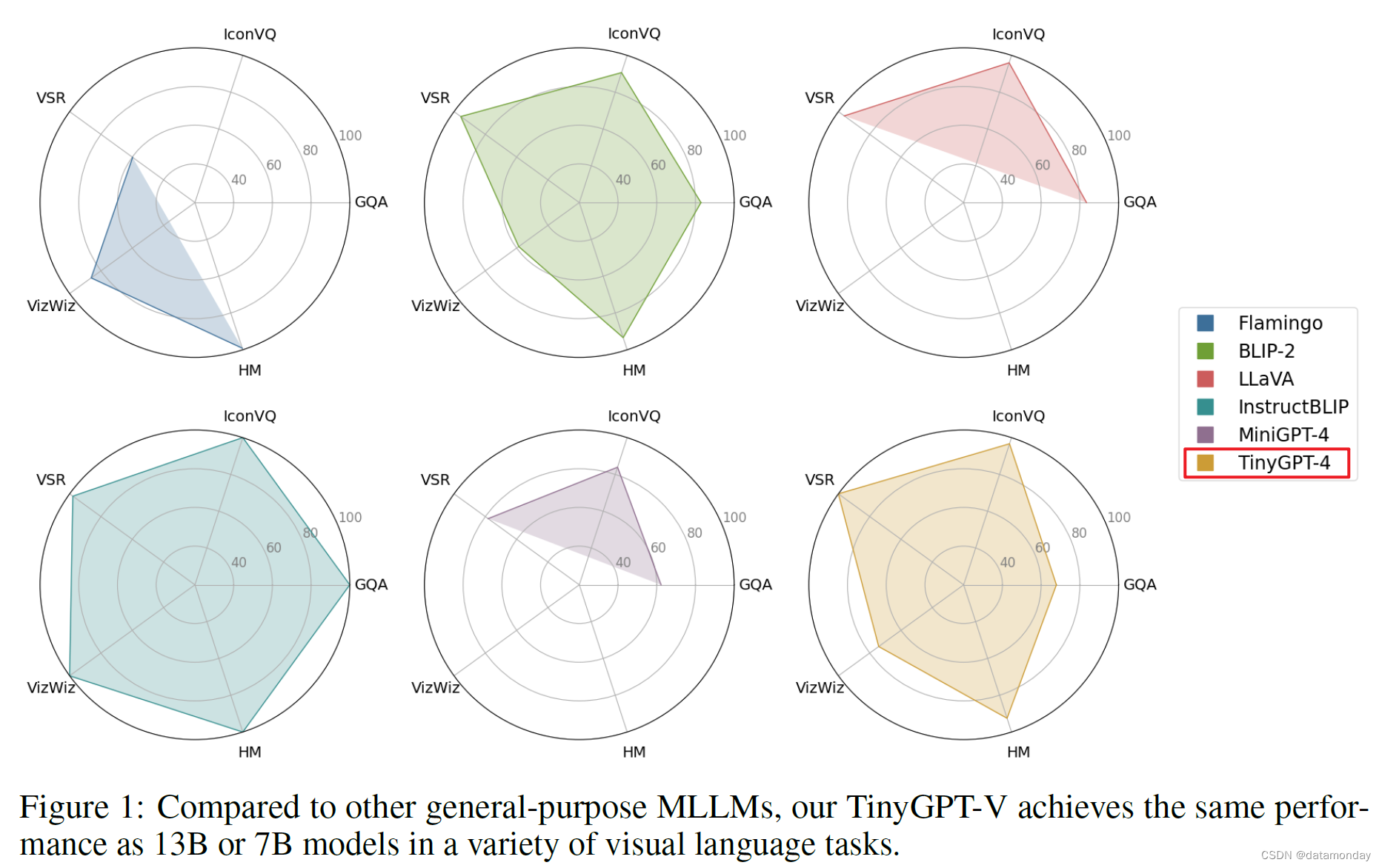
如表 2 所示,TinyGPT-V 作为一个只有 28 亿个参数的模型,在多个基准测试中表现出明显的竞争力,可与拥有近 130 亿个参数的模型相媲美。具体来说,在 VSR(视觉空间推理)零拍任务中,TinyGPT-V 以 53.2% 的最高得分超越了同类产品。考虑到其参数大小约为 BLIP-2,LLaVA 和 InstructBLIP 等其他领先模型的 4.6 倍,这一成绩尤其令人印象深刻。在 GQA 基准测试中,TinyGPT-V 的得分率为 33.6%,落后于 InstructBLIP 的最高得分率 49.5%。不过,TinyGPT-V 在 IconVQ 挑战赛中表现强劲,获得了 43.3% 的分数,仅比 InstructBLIP 的领先分数 44.8% 少 1.5%。同样,在 VizWiz 任务中,TinyGPT-V 表现出了值得称赞的能力,得分率为 24.8%,虽然不是最高分,但由于减少了参数数量,得分率还是很高的。在 HM 数据集方面,TinyGPT-V 的得分为 53.2%,与 InstructBLIP 的最高得分 57.5%不相上下,再次证明了它的效率和与更大规模模型竞争的能力。总体而言,TinyGPT-V 在这些多样化和具有挑战性的基准测试中的表现令人瞩目,尤其是考虑到其参数效率时更是如此。
4.3 Ablation Study

如表 3 所示,完整的 TinyGPT-V 模型在所有阶段都实现了低损失,但删除关键模块会导致严重的训练问题。
- 如果没有 LoRA 模块,从第 3 阶段开始就会出现梯度消失。
- 如果没有 Input Layer Norm 会显著增加损失(第 1 阶段为 2.839),并导致第 4 阶段的梯度消失。
- 如果没有 RMS Norm,模型在第 1 阶段的损失会增加(2.747),并在第 2 阶段面临早期梯度消失。
- 没有 QK Norm 会导致梯度立即消失。这些数据清楚地说明了每个模块在防止梯度消失和在整个训练过程中保持低损失方面的关键作用。
5 Conclusion
在本研究中,我们介绍了 TinyGPT-V,它是一种参数高效的 MLLMs,专为一系列真实世界的视觉语言应用而量身定制。我们的模型创新性地建立在紧凑而强大的 Phi-2 小型语言模型框架之上。通过这种方法,TinyGPT-V 在 VQA 和 REC 等各种基准测试中取得了优异成绩,同时保持了可控的计算需求。值得注意的是,TinyGPT-V 可以在 24G GPU 上进行训练,并部署在 8G 设备上,这表明在创建高性价比,高效和强大的 MLLM 方面取得了重大进展。这篇论文标志着我们在为实际应用案例创建更小,更强大的多模态语言模型方面做出了贡献。我们设想,我们的工作将促进进一步探索,为各种应用开发紧凑型 MLLM。

![[HCTF 2018]Warmup](https://img-blog.csdnimg.cn/direct/778e2b7889e047d2ae2e032e30d9a14f.png#pic_center)