在数据管理和处理的现代环境中,对能够处理复杂数据结构的复杂数据模型和方法的需求从未如此迫切。图数据的出现以其自然直观地表示复杂关系的独特能力,开辟了数据分析的新领域。
虽然 Neo4j 等成熟的图形数据库为处理图形数据提供了强大的解决方案,但将图形数据集成到 SQL 数据库中的想法提供了值得探索的潜在优势。SQL 数据库因其高效处理结构化数据的能力、提供稳健性、可靠性和熟悉的查询语言 (SQL) 而受到好评。在本文中,我将尝试探索开源分布式 SQL 数据库 OceanBase 中图数据和图查询的潜在实现。
通过利用 SQL 数据库中图数据的强大功能,我们的目标是将两种范式的优势结合起来——SQL 数据库的结构化数据处理与图数据灵活的、以关系为中心的性质。
本文初步探讨了将图数据纳入 OceanBase 生态系统的潜在好处、挑战和影响。我将深入探讨这种集成背后的原因,探索潜在的数据建模策略,并讨论一些示例查询。我们还将严格评估实施过程中可能出现的性能影响和限制。
我的目的不是提供明确的解决方案,而是激发对话并激发对此主题的进一步研究。文章的最后部分将为OceanBase团队提供一些建议,希望为数据库的持续演进做出贡献。
什么是图数据以及为什么它很重要
图数据是一种数据形式,它捕获实体(称为节点或顶点)以及这些实体之间的关系(称为边或链接)。这种灵活的结构使图数据能够以高度保真度对复杂的关系和复杂的系统进行建模,使其成为从社交网络分析到供应链管理等各个领域的强大工具。
图数据的特点是非线性和缺乏预定模式,这使其与传统的关系数据库区分开来。重点不是数据本身,而是数据之间的关系。这种以关系为中心的方法允许进行深入的、多层的分析,并且可以揭示可能隐藏在更传统的数据结构中的见解。
为了说明这一点,请考虑一个社交媒体平台。在这种情况下,单个用户可以表示为节点,而他们之间的连接(友谊、消息、交互)可以表示为边。
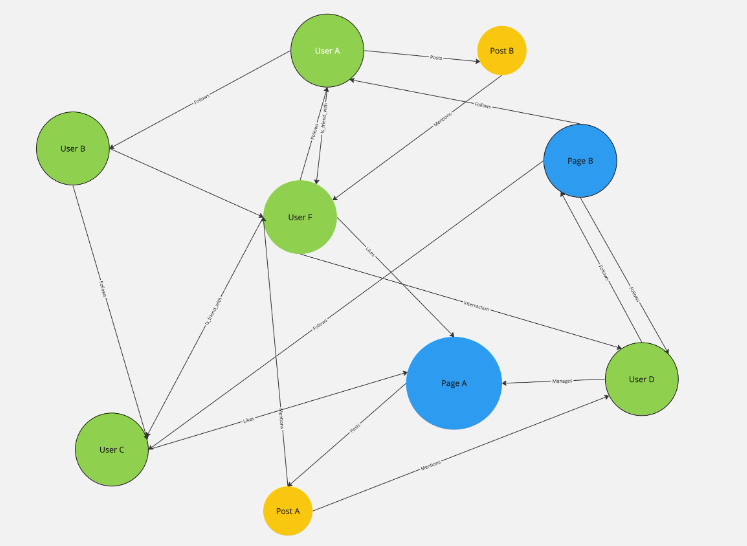
图数据模型使我们能够绘制整个网络,提供用户如何相互交互的详细图片。这可以揭示模式和见解,例如最有影响力的用户、更大网络中的社区以及信息流的潜在路径。
为什么Oceanbase用户应该关心图数据?
探索将图数据集成到 OceanBase 的想法是由现代应用程序中混合数据模型的日益普及所驱动的。随着企业和组织解决更复杂的问题并寻求从数据中提取更多价值,他们经常发现自己需要将 SQL 数据库提供的结构化表格数据模型与图形数据结合起来。由于我已经基于OceanBase开发了多个项目,因此它是我做这样的实验的理想平台。
许多潜在的用例可以从这种集成中受益。例如,在在线金融和推荐系统中,有效跟踪和分析连接的能力可能是无价的。换句话说,通过尝试在OceanBase中实现图数据,我们不仅试图丰富其功能,而且还扩展了其潜在的应用。
然而,挑战仍然存在。图数据的独特性质及其关注各个数据点之间的关系,在数据建模、查询语言和性能优化方面提出了新的问题。以下各节将深入探讨这些问题,全面分析这种集成的可行性和潜在好处。
Oceanbase中图数据的建模
为了在 OceanBase 中对图数据进行建模,我们本质上是创建图的关系表示。该图被分解为其基本组成部分:顶点(或节点)和边(或关系)。这种方法通常称为邻接列表模型。
邻接表模型涉及两张表:一张用于顶点,一张用于边。该Vertices表存储有关每个顶点的信息,而该Edges表存储有关每个边的信息,包括它连接的顶点。
让我们看看OceanBase中这些表是如何构建的:
创建顶点表:
CREATE TABLE Vertices (VertexID INT PRIMARY KEY,VertexProperties JSON);
在此表中,VertexID是唯一标识每个顶点的主键。VertexProperties是一个 JSON 字段,存储每个顶点的属性。这种结构使我们能够表示各种数据类型和复杂性。
边缘表架构:
CREATE TABLE Edges (EdgeID INT PRIMARY KEY,SourceVertexID INT,TargetVertexID INT,EdgeProperties JSON,FOREIGN KEY (SourceVertexID) REFERENCES Vertices(VertexID),FOREIGN KEY (TargetVertexID) REFERENCES Vertices(VertexID));
在 Edges 表中,EdgeID是唯一标识每条边的主键。SourceVertexID并TargetVertexID标识该边连接的顶点,EdgeProperties是一个存储每条边属性的 JSON 字段。这些FOREIGN KEY约束确保每条边都对应于 Vertices 表中的有效顶点。
有了每个表集的架构,我们尝试在数据库中创建一些虚拟数据以供以后查询。在 Vertices 表中,我将尝试创建 1,000 行来代表在线交易应用程序中的用户。
CREATE FUNCTION random_ip() RETURNS TEXT DETERMINISTICBEGINRETURN CONCAT(FLOOR(RAND() * 255) + 1, '.',FLOOR(RAND() * 255) + 0, '.',FLOOR(RAND() * 255) + 0, '.',FLOOR(RAND() * 255) + 0);END;CREATE FUNCTION random_device() RETURNS TEXT DETERMINISTICBEGINDECLARE device TEXT;SET device = CASE FLOOR(RAND() * 6)WHEN 0 THEN 'IPHONE'WHEN 1 THEN 'ANDROID'WHEN 2 THEN 'PC'WHEN 3 THEN 'IPAD'WHEN 4 THEN 'TABLET'ELSE 'LAPTOP'END;RETURN device;END;CREATE PROCEDURE InsertRandomUsers()BEGINDECLARE i INT DEFAULT 0;WHILE i < 1000 DOINSERT INTO Vertices (VertexID, VertexProperties)VALUES (i+1, CONCAT('{"name": "User', i+1,'", "email": "user', i+1,'@email.com", "ip":"', random_ip(),'", "DEVICE": "', random_device(), '"}'));SET i = i + 1;END WHILE;END;CALL InsertRandomUsers();
表中的“用户”具有诸如IP、device和 之类的属性email。通过此设置,可以探索如何在在线交易应用程序中实施反洗钱和欺诈检测算法。然而,现实世界中的情况会复杂得多,因此这些节点将具有更多的属性可供分析。
现在,让我们尝试为 Edges 表创建一些虚拟数据,每行代表每个“用户”之间的“交易”。每笔交易只会有一个属性——交易金额。
-- Create a temporary table to hold a series of numbersCREATE TEMPORARY TABLE temp_numbers (number INT);-- Stored procedure to fill the temporary tableDELIMITER //CREATE PROCEDURE FillNumbers(IN max_number INT)BEGINDECLARE i INT DEFAULT 1;WHILE i <= max_number DOINSERT INTO temp_numbers VALUES (i);SET i = i + 1;END WHILE;END //DELIMITER ;-- Call the procedure again to fill the temporary table with numbers from 1 to 1000CALL FillNumbers(10000);-- Use the temporary table to insert 1000 edgesINSERT INTO Edges (EdgeID, SourceVertexID, TargetVertexID, EdgeProperties)SELECTnumber,FLOOR(1 + RAND() * 1000),FLOOR(1 + RAND() * 1000),CONCAT('{"amount": ', FLOOR(10 + RAND() * 1000), ', "date": "', DATE(NOW() - INTERVAL FLOOR(1 + RAND() * 365) DAY), '"}')FROM temp_numbers;
此 SQL 查询将在Edges表中创建 10,000 个随机事务。该数据还将指示交易的发送者( SourceVertexID)和接收者( )。TargetVertexID
现在这是我们的数据库的样子。
顶点:
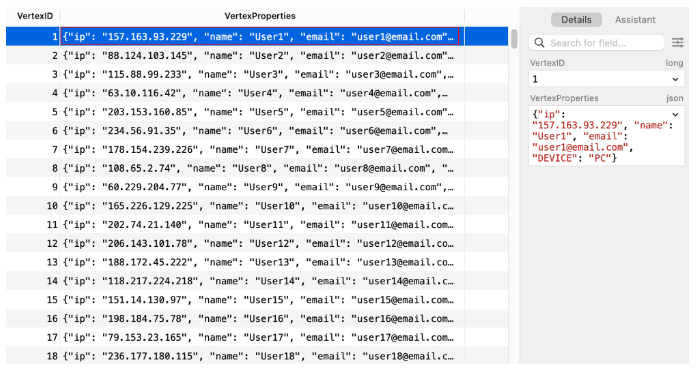

本示例演示了在 OceanBase 中对图数据进行建模的基本方法。它表明,即使没有原生图支持,也可以在 OceanBase 中实现类似图的结构。然而,这种方法有其局限性,特别是当涉及到复杂的图操作和性能时,我们将在后续部分中讨论。
一些示例查询
基于我们在 OceanBase 中实现的邻接表模型,我们现在可以执行各种图查询。在本节中,我将尝试使用典型的图形算法运行一些示例查询。值得注意的是,OceanBase对递归公共表表达式(CTE)的支持使得递归查询成为可能,这对于许多图算法来说至关重要。
广度优先搜索 (BFS)
广度优先搜索是图数据中常用的算法,用于查找从起始节点到目标节点的最短路径。它对于探索图中节点之间的连接特别有用。我们可以在OceanBase中使用递归CTE来实现BFS。
假设我们想要找到从特定用户(VertexID= 1)起 3 个步骤(或事务)内可到达的所有用户,我们可以使用以下查询:
WITH RECURSIVE bfs AS (SELECT SourceVertexID, TargetVertexID, 1 AS depthFROM EdgesWHERE SourceVertexID = 1UNION ALLSELECT Edges.SourceVertexID, Edges.TargetVertexID, bfs.depth + 1FROM Edges JOIN bfs ON Edges.SourceVertexID = bfs.TargetVertexIDWHERE bfs.depth < 3)SELECT * FROM bfs;
在此查询中,WITH RECURSIVE子句创建一个名为 的递归 CTE bfs。CTE 从源自VertexID= 1 的节点的所有边开始。然后,它重复添加从先前找到的节点连接的边,直到达到深度 3。
VertexIDBFS 查询返回一组可以在 3 个事务内从具有= 1 的用户(或基于您选择的其他节点)到达的所有用户。
此结果提供了对初始用户交易网络的洞察,揭示了与初始用户密切相关(在 3 笔交易内)的用户。此信息可用于各种应用,例如欺诈检测,其中紧密联系的用户可能会指示可疑活动。
在针对虚拟数据库的查询中,我用 131 毫秒检索了 871 行数据。考虑到它包含 1,000 个节点和 10,000 个边,这还算不错。
检测循环交易
循环交易,即资金围绕账户循环进行转移,可能是欺诈或洗钱活动的信号。识别此类循环可能是检测可疑活动的有用方法。我们可以使用深度优先搜索(DFS)算法来查找此类循环。以下是如何在最大路径长度为 5 的情况下完成此操作的示例:
WITH RECURSIVE dfs AS (SELECT SourceVertexID, TargetVertexID, CAST(CONCAT(SourceVertexID, '-', TargetVertexID) AS CHAR(1000)) AS path, 1 AS depthFROM EdgesWHERE SourceVertexID = 1UNION ALLSELECT dfs.SourceVertexID, Edges.TargetVertexID, CONCAT(dfs.path, '-', Edges.TargetVertexID), dfs.depth + 1FROM Edges JOIN dfs ON Edges.SourceVertexID = dfs.TargetVertexIDWHERE dfs.depth < 5 AND dfs.SourceVertexID != Edges.TargetVertexID AND dfs.path NOT LIKE CONCAT('%-', Edges.TargetVertexID, '-%')
)
SELECT * FROM dfs WHERE SourceVertexID = TargetVertexID;在此查询中,WITH RECURSIVE子句创建一个名为 的递归 CTE dfs。CTE 从源自VertexID= 1 的节点的所有边开始。然后,它重复添加从先前找到的节点连接的边,直到达到深度 5 或找到循环事务(其中SourceVertexID= TargetVertexID)。该path列跟踪 DFS 所采取的路径,这确保同一节点不会被访问两次。
识别高频交易对
在在线交易系统中,如果两个用户频繁相互交易,则可能表明他们之间存在牢固的关系,也可能是可疑活动的迹象。我们可以使用简单的 SQL 查询来查找彼此交易次数超过一定次数的用户对:
SELECT SourceVertexID, TargetVertexID, COUNT(*) AS transaction_countFROM EdgesGROUP BY SourceVertexID, TargetVertexIDHAVING transaction_count > 5ORDER BY transaction_count DESC;
该查询按源顶点和目标顶点(即涉及的用户)对事务进行分组,并计算每对的事务数量。然后,它会过滤掉少于 5 笔交易的交易对,并按交易数量对结果进行排序。
在此示例中,算法花费了 127 毫秒来完成查询所有 10,000 笔交易。
发现异常大额交易
有时,异常大的交易可能是潜在欺诈的迹象。我们可以使用 SQL 来识别金额高于某个阈值的交易(在本例中,阈值设置为 990,因为虚拟数据在 1 到 1,000 之间是随机的。但您可以根据您的情况设置更实际的阈值) 。
假设我们不仅想要查找金额高于特定阈值的交易,还想要包含有关发送者和接收者的信息,例如他们的设备、IP 和交易日期。我们还想按交易金额和日期对结果进行排序。我们可以这样做:
SELECTe.SourceVertexID,e.TargetVertexID,JSON_EXTRACT(e.EdgeProperties, '$.amount') AS transaction_amount,JSON_EXTRACT(e.EdgeProperties, '$.date') AS transaction_date,JSON_EXTRACT(s.VertexProperties, '$.DEVICE') AS sender_device,JSON_EXTRACT(s.VertexProperties, '$.ip') AS sender_ip,JSON_EXTRACT(r.VertexProperties, '$.DEVICE') AS recipient_device,JSON_EXTRACT(r.VertexProperties, '$.ip') AS recipient_ipFROMEdges AS eJOINVertices AS s ON e.SourceVertexID = s.VertexIDJOINVertices AS r ON e.TargetVertexID = r.VertexIDWHEREJSON_EXTRACT(e.EdgeProperties, '$.amount') > 990ORDER BYtransaction_amount DESC,transaction_date DESC;
在此查询中,我们将Edges表与Vertices表连接两次 - 一次用于发送者(源顶点),一次用于接收者(目标顶点)。然后,我们从现场提取有关发件人和收件人的其他信息VertexProperties。最后,我们按照交易金额和日期对结果进行降序排列。此查询使我们能够更全面地了解大型交易,包括涉及的人员以及他们使用的设备。
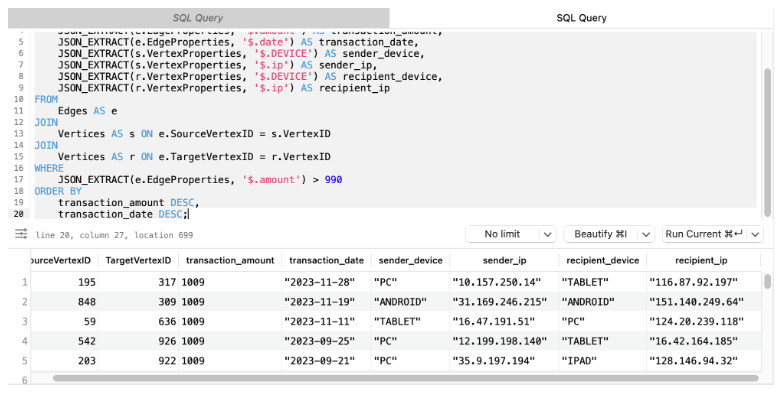
此查询的性能受到连接两个表和提取 JSON 属性的复杂性的影响。虽然使用较小的数据集可以快速执行查询,但随着数据量的增加,查询会显示出明显的减慢。具体来说,随着事务(边)和用户(顶点)数量的增加,连接表和解析 JSON 属性所需的时间增加,导致执行时间更长。因此,尽管查询提供了有价值的见解,但其在较大数据集上的可扩展性和性能可能令人担忧。
表现
根据实验,OceanBase 中实现图数据的性能参差不齐。从积极的一面来看,邻接表模型被证明是可以实现的,并且基本的图操作(例如 BFS 和识别高频事务对)可以高效运行。对于包含 1,000 个节点和 10,000 个边的数据集,这些查询的执行时间不到 200 毫秒,这对于许多实际应用程序来说已经非常令人满意。
然而,更复杂的图操作(例如 DFS)的性能还有很多不足之处。这些操作的执行时间随着操作的深度或复杂性呈指数增长,这表明邻接列表模型可能无法针对大型或复杂的图进行扩展。
在DFS示例中,当我将深度设置为5时,查询在428毫秒内完成。然而,将深度增加到 6 导致查询时间激增至近 4.785 秒,大约增加了 11 倍。将搜索深度进一步增加到 7 导致查询需要 67.843 秒才能完成,比之前的深度增加了 14 倍。这种模式表明查询时间随着深度的增加呈指数增长。
DFS 算法的查询时间随着深度的增长呈指数增长。
这种性能下降可能是实时或近实时应用程序的一个重大障碍,在这些应用程序中,快速响应至关重要。此外,具有数千或数百万个节点和边的大规模图可能会加剧这些性能问题,使得查询在生产数据库中使用不切实际。
另一个性能问题是 JSON 处理的开销。虽然使用 JSON 字段为图形数据建模提供了极大的灵活性,但它也给数据库操作增加了显着的开销。涉及多个 JSON 提取或操作的查询明显变慢,并且这种开销可能会随着 JSON 对象的增大和复杂性而增加。
SQL 的固有局限性给执行某些图形操作带来了重大挑战。例如,需要跨迭代维护状态的图算法(例如Dijkstra 算法)无法单独使用 SQL 来实现。
有趣的是,阿里巴巴团队在 2019 年进行的一项研究展示了关系数据库在针对 100 亿规模的海量图数据集实现图数据方面的性能。该研究强调了 PostgreSQL 的 CTE 语法在实现 N 深度搜索、最短路径搜索以及控制和显示层深度等图搜索需求方面的效率。
根据阿里巴巴的研究,在 50 亿个点边网络的背景下,N 深度搜索和最短路径搜索的响应时间都在“毫秒范围内”。尤其是在每层限制 100 条记录的 3 深度搜索时,响应时间仅为 2.1 毫秒,每秒事务数 (TPS) 达到 12,000。这一令人印象深刻的性能可以作为OceanBase团队优化图数据实现的基准。
OceanBase 中的图形数据:下一步是什么?
尽管 OceanBase 在提供健壮、可靠和可扩展的 SQL 数据库服务方面取得了重大进展,但图形数据处理功能的集成可以进一步增强其价值主张。本文证明了在 OceanBase 中基本的图数据处理确实是可能的,但仍有一些需要改进的地方。
根据这次探索的发现,给OceanBase团队一些建议:
-
优化图数据的 JOIN 操作:图查询通常涉及复杂的 JOIN 操作。专门针对图形数据优化这些操作可以显着提高性能。这可能涉及为图形数据创建专门的索引或为 JOIN 操作实现更有效的算法。
-
提高 JSON 解析性能:JSON 解析可能是图形查询中的一个重要瓶颈。预解析 JSON 字段、缓存解析结果或实现更高效的 JSON 解析算法等技术可以帮助提高性能。
-
实施特定于图的索引:索引极大地提高了 SQL 数据库中的查询性能。为图数据创建专门的索引,例如边属性上的索引或(源、目标)顶点对上的复合索引,可以使图查询运行得更快。
这种将图数据纳入 OceanBase 的探索揭示了一条充满希望但充满挑战的道路。在现有 SQL 结构中利用图数据的力量的潜力为扩展应用程序范围和提高数据分析能力提供了令人兴奋的可能性。然而,复杂图形操作的性能和 JSON 数据的处理开销存在需要克服的重大障碍。
这次探索仅仅触及了可能性的表面,还有更多的东西有待发现。我希望这篇文章能够激发进一步的讨论,为 OceanBase 和类似数据库的持续发展做出贡献。
作者:Wayne S
更多技术干货请关注公号【云原生数据库】
squids.cn,云数据库RDS,迁移工具DBMotion,云备份DBTwin等数据库生态工具。
irds.cn,多数据库管理平台(私有云)。