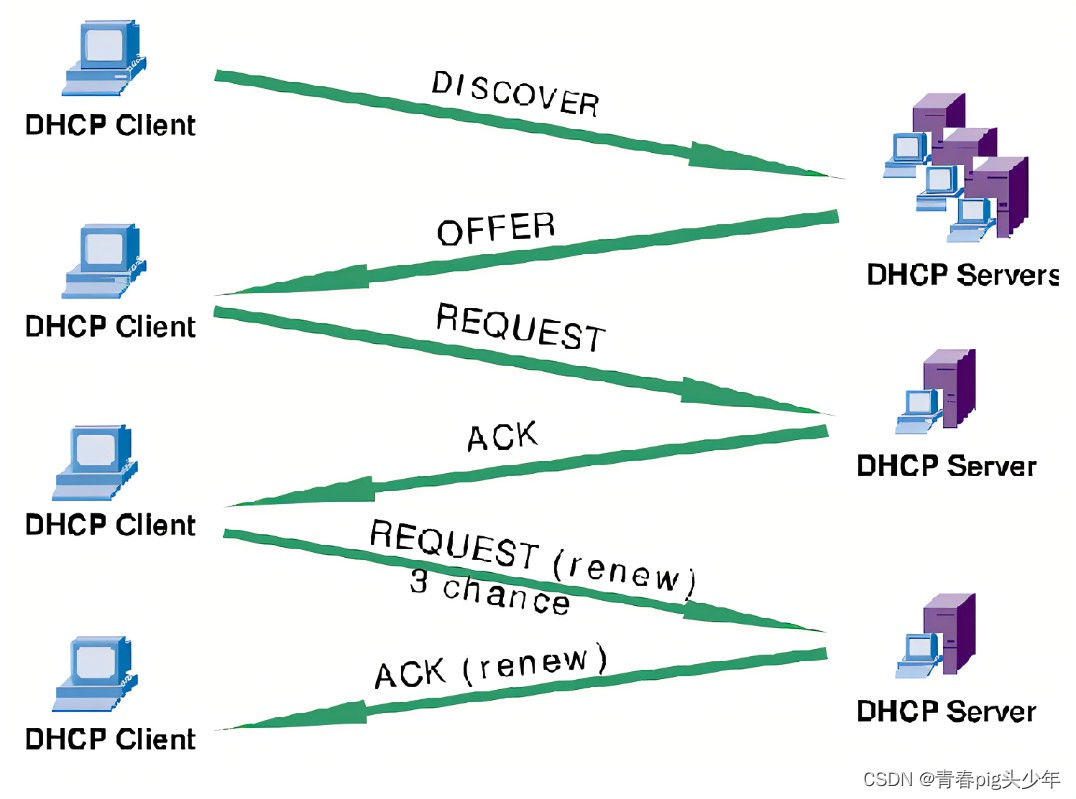
目录
- 一、为什么需要消息序列化?
- 二、常用的消息序列化方式
- 1)Java原生序列化(默认)
- 2)JSON格式
- 3)Protobuf 格式
- 4)Avro 格式
- 5)MessagePack 格式
- 三、总结

RabbitMQ是一个强大的消息中间件,广泛应用于 分布式系统 中。在使用 RabbitMQ 时,选择 合适的方式来序列化 消息可以提高:性能、可靠性、扩展性。
一、为什么需要消息序列化?
在使用 RabbitMQ 时,消息需要在生产者和消费者之间进行传递。由于网络通信只能传输二进制数据,因此需要对消息进行 序列化(将对象转换为二进制数据)和反序列化(将二进制数据转换回对象)。这样才能实现生产者与消费者之间的无缝通信。
消息序列化的目标是:将对象转换为字节流。以便于在网络上进行传输。在选择序列化方式时,我们 需要考虑以下因素:
- 性能: 序列化和反序列化的效率直接 影响消息传输的速度和延迟。
- 空间开销: 序列化后的字节流大小会 影响网络带宽的利用 和 存储空间的占用。
- 可读性: 序列化后的字节流是否 易于解析和理解,方便调试和维护。
- 兼容性: 序列化方式是否 支持不同的编程语言 和 版本之间的交互。
二、常用的消息序列化方式
RabbitMQ 本身不直接处理消息内容的序列化,它主要负责消息的路由、存储和传递。当发送或接收消息时,客户端库(如:Java 中的 RabbitTemplate 或 Spring AMQP 框架)会根据内部配置或默认设置来决定如何对消息体进行序列和反序列化。
1)Java原生序列化(默认)
- Java 自带的 Serializable 接口和
ObjectOutputStream/ObjectInputStream可以将对象转换为字节数组进行传输。在Java Spring AMQP中,默认的消息序列化方式就是 Java 原生序列化。
优点:
- 简单易用: Java 内置支持,只需让需要序列化的类实现 Serializable 接口即可。
缺点:
- 效率低: 生成的数据流可能比 JSON、Protocol Buffers 等二进制格式更大,导致存储和传输效率低。
- 安全风险: 由于序列化机制中包含了类的信息,存在安全风险,如:恶意攻击者可以构造特殊序列化数据以执行任意代码(例如通过 readObject 方法的重写)。
- 语言独立性差: Java 原生序列化只适用于 Java 环境,不便于与其他编程语言间的通信。
为了克服这些限制并提供更好的性能和互操作性,开发者通常会选择更现代和灵活的方式,如 JSON 或 Protobuf 等。
2)JSON格式
JSON(JavaScript Object Notation):是一种轻量级的数据交换格式,易于阅读和编写。它以键值对的形式表示数据,并且在不同的编程语言中都有广泛的支持。
优点:
- 易于使用和调试。
- 兼容性好,支持不同编程语言和版本之间的交互。
缺点:
- 性能较差,相比其他序列化方式,JSON 的序列化和反序列化速度较慢。
- 字节流相对较大,占用网络带宽较多。
在 Spring AMQP 中,可以配置 MessageConverter 来替换默认的序列化器,例如使用 Jackson 库提供的 Jackson2JsonMessageConverter 将消息转换为 JSON 格式。
Spring Boot 可以通过以下方式更改默认的消息序列化策略:
spring:rabbitmq:message-converter: org.springframework.amqp.support.converter.Jackson2JsonMessageConverter
或者在 Java 配置类中定义:
@Bean
public MessageConverter jsonMessageConverter() {return new Jackson2JsonMessageConverter();
}@Autowired
public void configureRabbitTemplate(RabbitTemplate rabbitTemplate) {rabbitTemplate.setMessageConverter(jsonMessageConverter());
}
这样,消息体就会被自动转换成 JSON 字符串发送到 RabbitMQ,并在接收端反序列化回对应的 Java 对象。
补充:
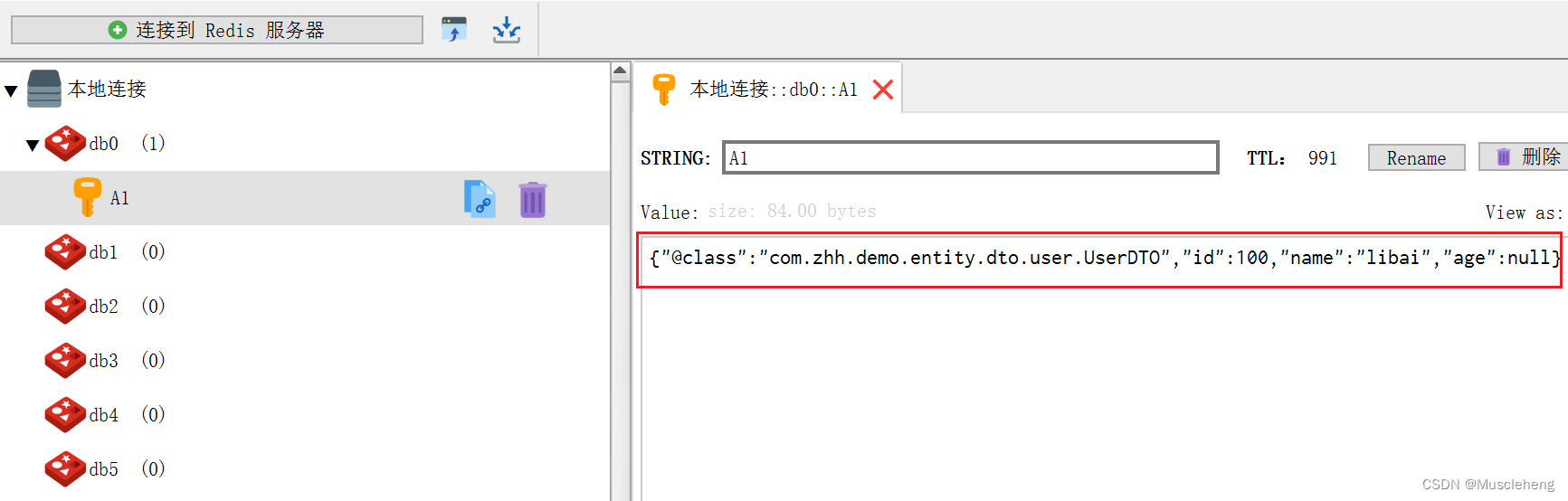
如果对象中使用了 LocalDateTime,在反序列化的时候会报错:InvalidDefinitionException: Cannot construct instance of java.time.LocalDateTime (no Creators, like default constructor, exist): cannot deserialize from Object value (no delegate- or property-based Creator)
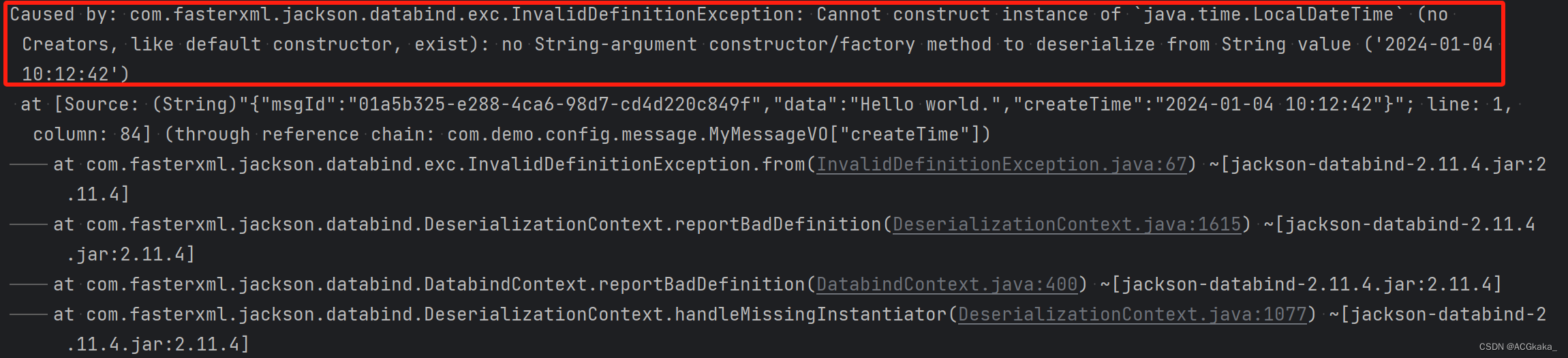
解决方式:
- 首先,需要引入
jackson-datatype依赖,如果之前已经引入了spring-boot-starter-web依赖则不需要手动添加。

<!-- LocalDateTime反序列化 -->
<dependency><groupId>com.fasterxml.jackson.datatype</groupId><artifactId>jackson-datatype-jsr310</artifactId><version>2.4.0</version>
</dependency>
- 需要在 LocalDateTime 类型的字段上面添加
@JsonDeserialize注解和@JsonSerialize注解来指定如何序列化和反序列化java.time.LocalDateTime类型的数据,如下所示:
import com.fasterxml.jackson.annotation.JsonFormat;
import com.fasterxml.jackson.databind.annotation.JsonDeserialize;
import com.fasterxml.jackson.databind.annotation.JsonSerialize;@JsonDeserialize(using = LocalDateTimeDeserializer.class)
@JsonSerialize(using = LocalDateTimeSerializer.class)
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
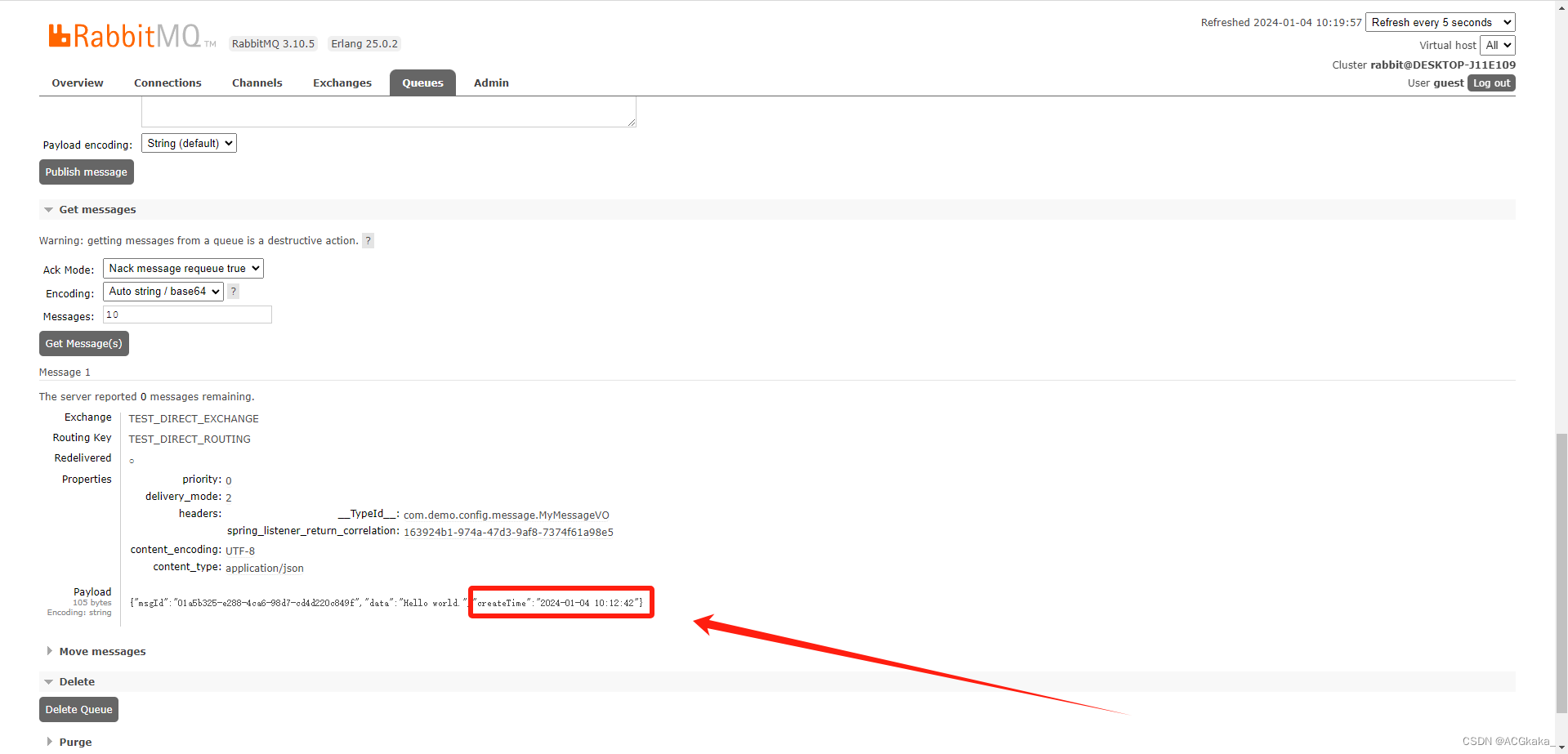
private LocalDateTime createTime;
补充: 上述代码中,@JsonFormat 注解是完善显示形式。
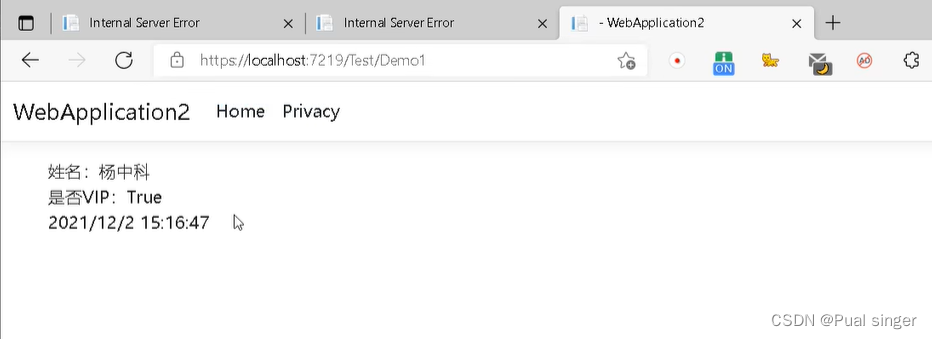
使用
@JsonFormat注解前:

使用
@JsonFormat注解后:
3)Protobuf 格式
Protobuf(Protocol Buffers)是 Google 开发的一种高效的数据序列化格式。它以 二进制格式 存储数据,可以通过定义消息结构和 IDL(Interface Description Language)文件来实现消息的序列化和反序列化。
优点:
- 高性能,比 JSON 和 XML 等方式更快速和高效。
- 字节流较小,占用网络带宽和存储空间较小。
缺点:
- 由于二进制格式存储,不易读和调试。
4)Avro 格式
Avro 是一种基于 Schema 的数据序列化系统,由 Apache 开发。Avro 使用简单的动态 Schema 来定义消息格式,并支持多种编程语言。它具有高效的压缩和快速的序列化/反序列化性能。
优点:
- 高性能,支持快速的序列化和反序列化。
- 字节流小,占用网络带宽和存储空间较小。
缺点:
- Schema 管理较为复杂,需要定义并维护 Schema。
5)MessagePack 格式
MessagePack 是一种快速、紧凑且可读写的二进制序列化格式。它以键值对的形式表示数据,并支持多种编程语言。MessagePack的主要目标是提供高性能的序列化和反序列化。
优点:
- 高性能,比 JSON 和 XML 等方式更快速和高效。
- 字节流较小,占用网络带宽和存储空间较小。
缺点:
- 不易读和调试。
三、总结
RabbitMQ消息序列化是构建 分布式系统 的关键环节之一。在选择序列化方式时,需要综合考虑性能、空间开销、可读性和兼容性等因素。根据具体需求 选择合适的序列化方式,并遵循最佳时间,可以提高系统的性能、可靠性和扩展性。通过测试、优化和监控,不断改进序列化方案,使其更好地 适应实际应用场景。
整理完毕,完结撒花~ 🌻
参考地址:
1.Spring boot使用Rabbitmq注解及消息序列化,https://blog.csdn.net/cristianoxm/article/details/114883340
2.RabbitMQ消息序列化的终极指南,https://baijiahao.baidu.com/s?id=1773630009654004953&wfr=spider&for=pc