作者:娜米
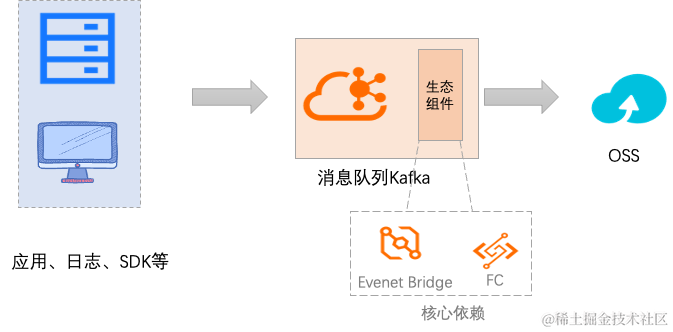
云消息队列 Kafka 版为什么需要做无代码转储
云消息队列 Kafka 版本身是一个分布式流处理平台,具有高吞吐量、低延迟和可扩展性等特性。它被广泛应用于实时数据处理和流式数据传输的场景。然而,为了将云消息队列 Kafka 版与其他数据源和数据目的地集成,需要额外的开发/组件来实现数据的传输和同步,客户需要大量的研发、运维等投入。
为了提升研发效率,云消息队列 Kafka 版联合阿里云产品支持到无代码、全托管、Serverless 化的功能特性,支持从云消息队列 Kafka 版到 OSS 的转储。该功能特性的优势有:
- 简单
-
- 敏捷开发,简单配置就可以支持该能力
- 轻松转储不同应用程序的 OSS 数据
- 无需复杂的软件和基础设施
- 全托管
-
- 提供 Serverless 计算能力
- 免运维
- 成熟功能
- 低成本
-
- 云消息队列 Kafka 版本身不额外收费,底层依赖函数计算按量收费
- 函数计算为该场景做深度优化,结合架构实现低成本:引入 CDN 缓存机制,动态计算配合衍生副本存储成本
- 产品集成链路一定的减免费用
云消息队列 Kafka 版+OSS 主要应用场景
-
数据备份和归档
OSS 提供了数据备份和归档的功能。客户可以选择将重要数据备份到 OSS 中,以提供数据灾难恢复的能力。OSS 提供了数据持久性和可靠性的保证,可以确保数据的安全性和可用性。同时,OSS 还提供了归档存储的功能,用于长期存储不经常访问的数据。客户可以将数据归档到 OSS 的归档存储类别中,以节省存储成本,并根据需要进行数据恢复。
-
大数据分析
阿里云的对象存储 OSS 可以作为大数据的存储平台。客户可以将各种类型的大数据文件(如日志文件、传感器数据、用户行为数据等)存储在 OSS 中,以便后续进行数据分析、数据挖掘和机器学习等任务。客户可以在阿里云上完成大数据的存储、处理和分析任务,实现弹性扩展和高性能的大数据处理。
-
FC 计算结果的缓存
阿里云函数计算(Function Compute,简称 FC)是一种事件驱动的无服务器计算服务,用于帮助用户以更低的成本和更高的弹性运行代码。而阿里云对象存储 OSS 是一种云端数据存储服务,提供安全、稳定、高扩展性的云端存储能力。FC 是无状态的计算服务,不提供持久化的本地存储。因此,如果需要在函数执行期间存储和访问数据,可以通过与 OSS 结合使用,将数据存储在 OSS 中。这样可以实现数据的持久化存储,确保数据不会因为函数计算的瞬时性而丢失。
代码转储产品能力介绍
1. 0 代码开发: 转储/Connector 提供了与各种数据源和数据目的地的集成功能。通过使用云消息队列 Kafka 版转储/Connector 能力,研发人员无需编写复杂的数据集成代码,只需配置相应的 Connector 即可实现数据的传输和同步,大大简化了数据集成的过程。
2. 配置化支持: 用户可以根据自己的需求和业务场景,灵活配置转发规则和存储策略。无论是按照时间、关键字、主题等维度进行转发,支持按照文件夹、文件名等维度进行存储,都可以通过简单的配置实现,满足的个性化需求。
3. 高可靠性和容错性: 转储/Connector 保证了数据的高可靠性和容错性。数据在传输过程中,Connector 会自动处理数据的冗余和故障恢复,确保数据不会丢失或损坏。这样,用户不需要关注数据传输的细节和异常处理,可以更加专注于业务逻辑的开发。
4. Serverless 化: 可以根据请求的负载自动扩展和缩减计算资源。与传统的预分配服务器相比,Serverless 化可以更灵活地适应实际需求,降低资源浪费和成本。组件负责管理和维护底层基础架构,客户无需关心服务器的配置和管理。
使用步骤说明
前提条件
1. 云消息队列 Kafka 版实例准备 [ 1]
- 依赖开放,请参见创建前提 [ 2]
步骤一:创建目标服务资源
在对象存储 OSS 控制台创建一个存储空间(Bucket)。详细步骤,请参见控制台创建存储空间 [ 3] 。
本文以 oss-sink-connector-bucket Bucket 为例。
步骤二:创建 OSS Sink Connector 并启动
登录云消息队列 Kafka 版控制台 [ 4] ,在概览页面的资源分布区域,选择地域。
在左侧导航栏,选择 Connector 生态集成 > 消息流出(Sink)。
在消息流出(Sink)页面,单击创建任务。
在消息流出创建面板,配置以下参数,单击确定。
在基础信息区域,设置任务名称,将流出类型选择为对象存储 OSS。
在资源配置区域,设置以下参数。
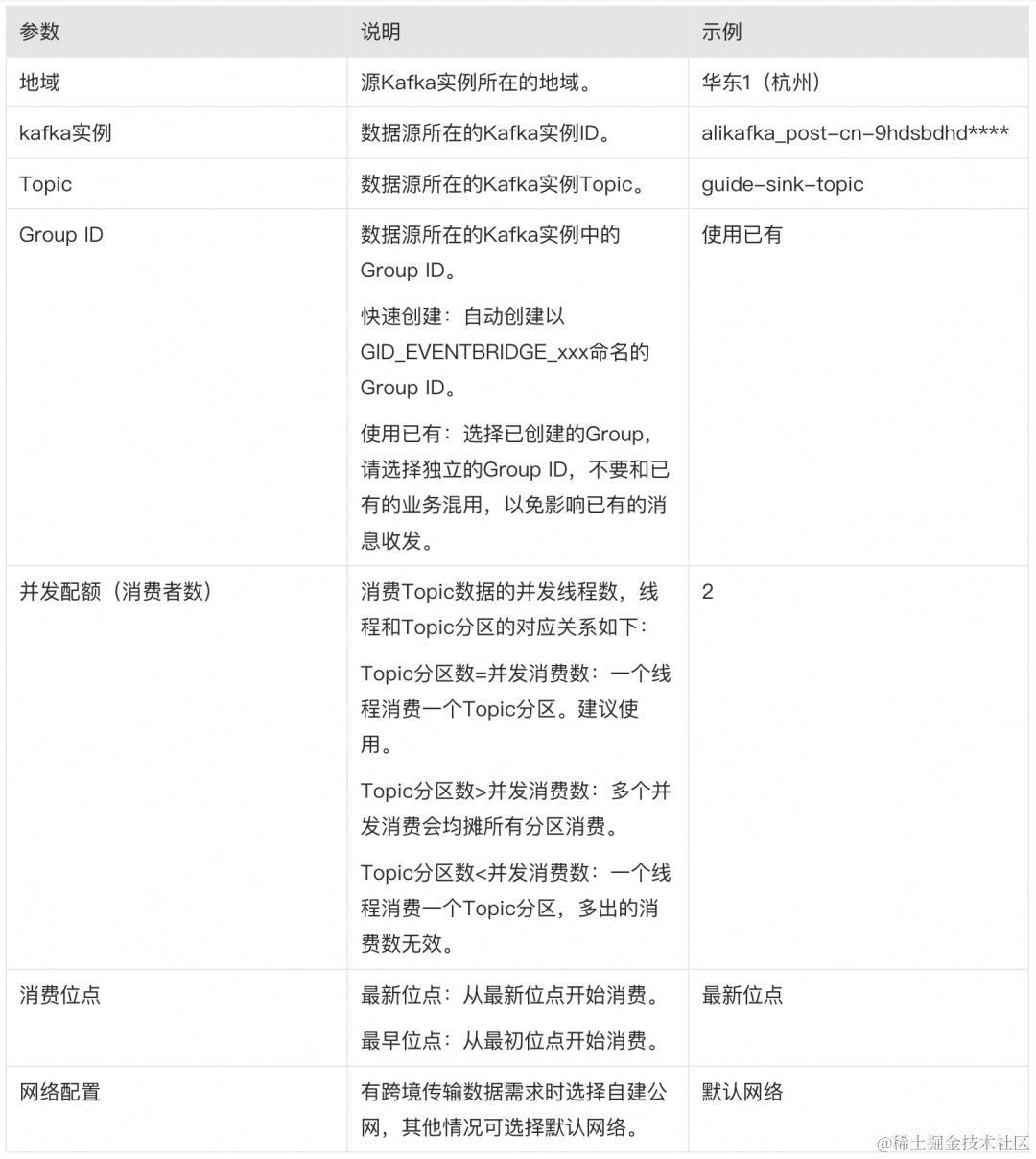
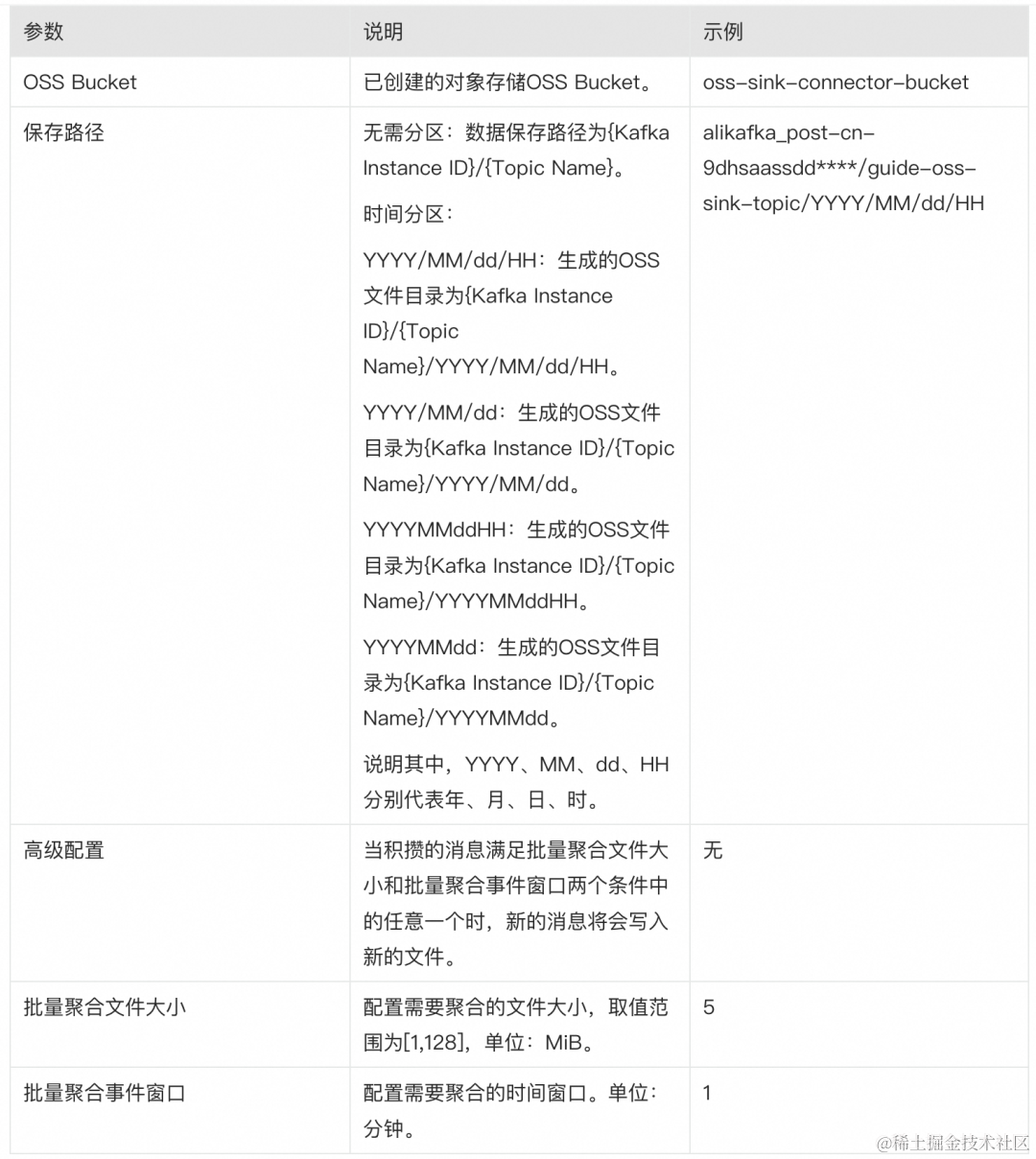
完成上述配置后,在消息流出(Sink)页面,找到刚创建的 OSS Sink Connector 任务,单击其右侧操作列的启动。当状态栏由启动中变为运行中时,Connector 创建成功。
步骤三:测试 OSS Sink Connector
在消息流出(Sink)页面,在 OSS Sink Connector 任务的事件源列单击源 Topic。
在 Topic 详情页面,单击体验发送消息。
在快速体验消息收发面板,按照下图配置消息内容,然后单击确定。
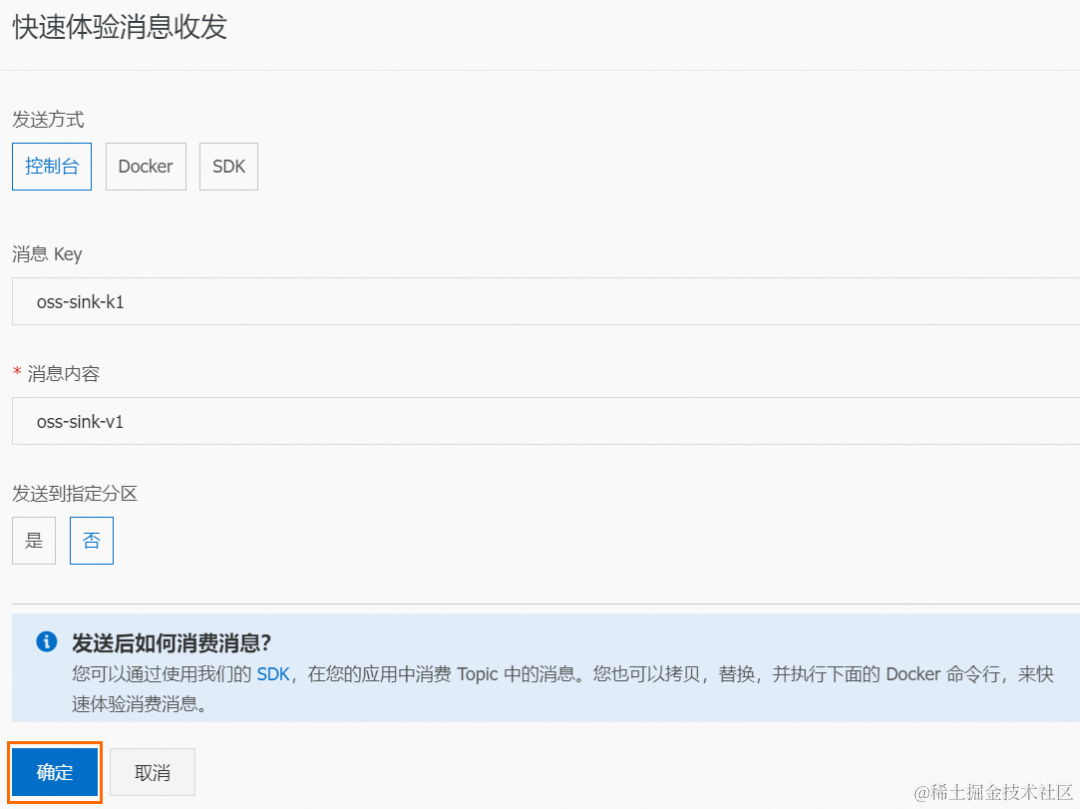
在消息流出(Sink)页面,在 OSS Sink Connector 任务的事件目标列单击目标 Bucket。
在 Bucket 页面,选择左侧导航栏的文件管理 > 文件列表,然后进入 Bucket 的最深层路径。

可以看到此路径中有如下两类 Object:
- 系统 meta 文件: 格式为 .oss_meta_file_partition_{partitionID},文件数量和上游 Topic 的 Partition 数量相同,用于记录攒批信息,您无需关注。
- 数据文件: 格式为 partition_{partitionID}offset{offset}_{8位Random 字符串},如果一个 Object 中聚合了一个 Partition 的多条消息,Object 名称中的 Offset 为这批消息中的最小 Offset 值。
在对应 Object 右侧操作列,选择 > 下载。
> 下载。
打开下载的文件,查看消息内容。
 如图所示,多条消息之间通过换行分隔。
如图所示,多条消息之间通过换行分隔。
相关链接:
[1] 云消息队列 Kafka 版实例准备
https://help.aliyun.com/zh/apsaramq-for-kafka/getting-started/getting-started-overview
[2] 创建前提
https://help.aliyun.com/zh/apsaramq-for-kafka/user-guide/prerequisites#concept-2323967
[3] 控制台创建存储空间
https://help.aliyun.com/zh/oss/getting-started/console-quick-start#task-u3p-3n4-tdb
[4] 云消息队列 Kafka 版控制台
https://account.aliyun.com/login/login.htm?oauth_callback=https%3A%2F%2Fkafka.console.aliyun.com%2F%3Fspm%3Da2c4g.11186623.2.22.6bf72638IfKzDm&lang=zh
点击此处,云消息队列 Kafka 版 V3 公测正式开启!