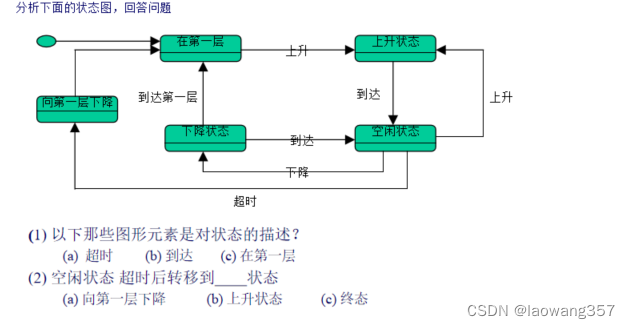
ConcurrentHashMap是如何保证fail-safe的
- ✅典型解析
- ✅拓展知识仓
- ✅分段锁
- ☑️分段锁适用于什么情况
- 🟡分段锁的锁争用情况,是否会带来一定的性能影响
- ✔️分段锁的优缺点
- 🟢 还有哪些其他的线程安全哈希表实现
- 🟠Hashtable和 Collections区别
- 🟡分段锁和锁之间的区别是什么
- 🟢分段锁比锁更加安全吗
- 🟢弱一致性保障
✅典型解析
在JDK 1.8 中,ConcurrentHashMap 作为一个并发容器,他是解决了 fail-fast 的问题的,也就是说他是一个 fail-safe 的容器。通过以下两种机制来实现 fail-safe 特性:
首先,在 ConcurrentHashMap 中,遍历操作返回的是弱一致性选代器,这种跌代器的特点是,可以获取到在选代器创建前被添加到 ConcurrentHashMap 中的元素,但不保证一定能获取到在选代器创建后被删除的元素。
弱一致性是指在并发操作中,不同线程之间的操作可能不会立即同步,但系统会在某个时刻趋于致。这种弱一致性的特性有助于实现
fail-safe行为,即使在选代或操作过程中发生了并发修改,也不会导致异常或数据损坏。即他不会抛出ConcurrentModifiedException
另外。在JDK 1.8 中,ConcurrentHashMap 中的 Segment 被移除了,取而代之的是使用类似于 castsynchronized 的机制来实现并发访问。在遍历ConcurrentHashMap时,只需要获取每个桶的头结点即可,因为每个桶的头结点是原子更新的,不会被其他线程修改。这个设计允许多个线程同时修改不同的桶,这减少了并发修改的概率,从而降低了冲突和数据不一致的可能性。
也就是说,ConcurrentHashMap 通过弱一致性选代器和 Segment 分离机制来实现 fail-safe 特性可以保证在遍历时不会受到其他线程修改的影响。
ConcurrentHashMap 是一种线程安全的哈希表实现,它通过使用分段锁(Segmentation)和无锁(Lock-Free)技术来实现高并发性和线程安全性。下面我将详细解释 ConcurrentHashMap 是如何保证 fail-safe 的:
-
分段锁(Segmentation):
- ConcurrentHashMap 将整个哈希表分成多个段(Segment),每个段都是一个独立的锁。当进行读操作或写操作时,只需要锁定对应的段,而不是整个哈希表。这大大减少了锁的竞争,提高了并发性能。
- 每个段都是一个独立的哈希表,有自己的锁。当一个线程访问某个段时,会先对该段加锁,然后进行相应的操作。其他线程可以同时访问其他段,互不干扰。
-
无锁(Lock-Free)技术:
- ConcurrentHashMap 还使用了无锁技术来进一步优化性能。在某些情况下,不需要加锁就可以进行操作,比如使用 CAS
(Compare-and-Swap)操作来更新节点的值。 - CAS 是一种无锁的原子操作,它比较并交换内存中的值。如果值未被其他线程修改过,则成功更新;否则,该操作失败并重新尝试。通过使用 CAS 操作,ConcurrentHashMap 可以在不加锁的情况下实现线程安全。
- ConcurrentHashMap 还使用了无锁技术来进一步优化性能。在某些情况下,不需要加锁就可以进行操作,比如使用 CAS
-
数据结构优化:
- ConcurrentHashMap 使用了各种数据结构优化来提高性能和减少锁竞争。例如,使用红黑树来处理哈希冲突,以及使用链表、数组等数据结构来存储
键值对。 - 这些优化使得 ConcurrentHashMap 在高并发环境下能够提供更好的性能和更低的锁竞争。
- ConcurrentHashMap 使用了各种数据结构优化来提高性能和减少锁竞争。例如,使用红黑树来处理哈希冲突,以及使用链表、数组等数据结构来存储
-
失败安全:
- ConcurrentHashMap 的设计目标是提供 fail-safe 的保证,即使在并发操作中出现异常,也能保证数据的一致性。
- 由于使用了分段锁和无锁技术,ConcurrentHashMap 能够保证操作的原子性和不可变性。即使一个线程在执行操作时发生异常,也不会影响到其他线程的操作。其他线程仍然可以正常地读取和写入数据,不会导致数据的不一致性。
- 同时,ConcurrentHashMap 还使用了回滚机制来处理异常情况。如果一个线程在执行操作时出现异常,该操作会被回滚,不会对其他线程造成影响。这种回滚机制保证了即使发生异常,也能保持数据的一致性。
ConcurrentHashMap 通过分段锁、无锁技术和数据结构优化等手段,实现了线程安全和 fail-safe 的保证。即使在并发操作中出现异常,也能保证数据的一致性,提供了高效的并发访问和数据处理能力。
来看一段代码Demo,帮助理论知识的理解:
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.AtomicInteger; /**
* @author xinbaobaba
* Demo展示了ConcurrentHashMap如何实现更高级的线程安全和"fail-safe"功能
*/public class ConcurrentHashMapAdvancedExample { public static void main(String[] args) { // 创建一个 ConcurrentHashMap 实例 ConcurrentHashMap<String, AtomicInteger> map = new ConcurrentHashMap<>(); // 模拟多个线程同时访问和修改 map Thread thread1 = new Thread(() -> { for (int i = 0; i < 100; i++) { map.put("A", new AtomicInteger(i)); System.out.println("Thread 1: " + map.get("A").get()); } }); Thread thread2 = new Thread(() -> { for (int i = 0; i < 100; i++) { map.put("B", new AtomicInteger(i)); System.out.println("Thread 2: " + map.get("B").get()); } }); thread1.start(); thread2.start(); }
}
在这个Demo中,创建了一个 ConcurrentHashMap 实例 map,并使用两个线程 thread1 和 thread2 同时访问和修改这个映射。这次我们使用 AtomicInteger 作为映射的值类型,而不是简单的Integer。AtomicInteger是一个线程安全的整数类型,它提供了原子操作,可以在并发环境下安全地进行增加、减少等操作。
在每个线程中,我们使用一个循环来多次执行操作。每个线程都向映射中添加一个键值对,并使用get()方法获取并打印相应的值。由于ConcurrentHashMap的内部锁和分段锁机制,这些操作仍然是线程安全的。即使在并发环境下,也不会出现数据竞争或不一致的情况。同时,由于使用了AtomicInteger作为值类型,我们可以保证对整数值的操作是原子的,进一步增强了线程安全性。
即使一个线程在执行操作时出现异常,也不会影响其他线程的操作。每个线程操作的是不同的键,互不干扰。即使一个线程的操作被中断或回滚,也不会对其他线程造成影响,因为每个线程都有自己的数据副本,并且操作是原子的。这样就能保证在整个并发操作过程中的数据一致性和"fail-safe"。
✅拓展知识仓
✅分段锁
分段锁是一种用于实现高并发性能的锁策略,通常在数据库和并发编程中使用。它将数据分成多个段,并对每个段加锁,允许多个线程同时访问不同的段,而不会相互阻塞。
分段锁的优点在于它能够提高并发性能,通过将数据分成多个段并使用锁来保护每个段,允许多个线程同时访问不同的段,而不会相互阻塞。这种策略能够减少锁的竞争,从而提高并发性能。另外,分段锁还可以通过细化锁的粒度来提高并发性能,使得在多线程环境下能够更好地利用系统资源。
分段锁的缺点在于实现较为复杂,需要处理多个段之间的同步和通信,增加了代码的复杂性和出错的可能性。另外,分段锁需要更多的锁资源,因为每个段都需要一个锁来保护。这可能会导致更多的锁竞争和上下文切换,从而降低性能。
分段锁是一种用于实现高并发性能的锁策略,通过将数据分成多个段并使用锁来保护每个段,允许多个线程同时访问不同的段,而不会相互阻塞。它能够提高并发性能,但实现较为复杂,需要谨慎处理多个段之间的同步和通信。
看一个Demo,帮助理解分段锁:
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
import java.util.concurrent.locks.Condition;
/**
* 如何使用`java.util.concurrent.locks.ReentrantLock`和`java.util.concurrent.locks.Condition`来实现一个线程安全的计数器
*/
public class SafeCounter {private int count = 0;private Lock lock = new ReentrantLock();private Condition countCondition = lock.newCondition();public void increment() {lock.lock();try {while (count == Integer.MAX_VALUE) {try {countCondition.await(); // 等待其他线程重置count} catch (InterruptedException e) {Thread.currentThread().interrupt();throw new RuntimeException(e);}}count++;System.out.println("Count: " + count);countCondition.signalAll(); // 通知其他等待的线程} finally {lock.unlock();}}public void decrement() {lock.lock();try {while (count == 0) {try {countCondition.await(); // 等待其他线程增加count} catch (InterruptedException e) {Thread.currentThread().interrupt();throw new RuntimeException(e);}}count--;System.out.println("Count: " + count);countCondition.signalAll(); // 通知其他等待的线程} finally {lock.unlock();}}public int getCount() {return count;}
}
示例中,使用
ReentrantLock和Condition来实现一个线程安全的计数器。我们使用了lock来保护共享变量count的访问,并使用Condition来协调线程之间的等待和通知。在increment()和decrement()方法中,我们使用while循环来检查count的值,并在需要时使用await()方法等待其他线程的操作。一旦满足条件,我们使用signalAll()方法通知其他等待的线程。通过这种方式,我们确保了线程安全和数据的一致性。
☑️分段锁适用于什么情况
分段锁是一种用于实现高并发性能的锁策略,通常在缓存系统和并发容器等场景中使用。它将数据分成多个段,并对每个段加锁,允许多个线程同时访问不同的段,而不会相互阻塞。
分段锁适用于以下情况:
- 缓存系统:在缓存系统中,使用分段锁可以将缓存数据分为多个段,每个段使用独立的锁控制。这样,不同的线程可以同时读取或修改不同的缓存数据段,从而提高缓存访问的并发度和性能。
- 并发容器:并发容器是用于存储和管理多个数据项的容器,如集合、列表等。使用分段锁可以将容器中的数据分成多个段,并使用独立的锁来控制每个段。这样可以避免锁的竞争和锁的粒度过大导致的性能问题,从而提高容器的并发性能。
- 高性能数据库:在一些高性能数据库中,为了提高并发性能,可以使用分段锁来控制对数据的并发访问。通过将数据分成多个段并使用独立的锁来控制每个段,可以允许多个线程同时访问不同的数据段,从而提高数据库的并发性能。
- 路由器和操作系统:在一些并发访问场景中,如路由器和操作系统等,也可以使用分段锁来提高系统的并发度和性能。通过将数据分成多个段并使用独立的锁来控制每个段,可以避免锁的竞争和性能问题,从而提高系统的并发性能。
分段锁适用于需要高并发访问数据的情况,特别是在缓存系统、并发容器、高性能数据库、路由器和操作系统等场景中。通过将数据分成多个段并使用独立的锁来控制每个段,可以允许多个线程同时访问不同的数据段,从而提高并发性能。
🟡分段锁的锁争用情况,是否会带来一定的性能影响
分段锁的锁争用情况可能会导致一定的性能影响。当多个线程同时访问分段锁所保护的数据时,如果多个线程试图同时访问同一数据段,就会发生锁争用。此时,线程将会被阻塞,直到锁被释放。
锁争用会导致线程等待,增加了线程的上下文切换开销和CPU资源的消耗,从而可能降低程序的并发性能和响应速度。在高并发环境下,锁争用情况可能会导致更为显著的性能下降。
为了避免锁争用对性能的影响,可以采用一些策略和技术:
- 优化数据分布:通过合理地分布数据,使得线程尽可能访问不同的数据段,从而减少锁争用的可能性。例如,可以使用散列函数来分配数据到不同的段。
- 减小锁粒度:通过将数据分成更小的段,可以减小锁的粒度,从而减少锁争用的可能性。例如,可以使用更小的数据结构或更精细的锁控制。
- 使用更高效的锁机制:例如,使用读写锁、自旋锁或乐观锁等更高效的锁机制,可以减少线程等待锁的时间和上下文切换的开销。
- 避免长时间持有锁:通过减少线程持有锁的时间,可以减少其他线程等待该锁的时间,从而减少锁争用的可能性。例如,尽可能地减少在持有锁时的计算和I/O操作。
- 使用缓存和缓冲技术:通过使用缓存和缓冲技术,可以减少对数据的直接访问,从而减少对分段锁的竞争。例如,可以使用缓存池或缓冲队列等技术来存储常用的数据项。
分段锁的锁争用情况可能会导致一定的性能影响。通过优化数据分布、减小锁粒度、使用更高效的锁机制、避免长时间持有锁以及使用缓存和缓冲技术等策略和技术,可以减少锁争用的可能性并提高程序的并发性能。
✔️分段锁的优缺点
分段锁优点:
- 高并发性:允许并发访问不同段的数据,提高了并发性能。通过将数据分成多个段,并使用独立的锁控制每个段,允许多个线程同时访问不同的数据段,从而减少了线程之间的竞争和阻塞。
- 细粒度控制:提供更精细的锁控制,提高了系统的灵活性和可扩展性。与全局锁或较大粒度的锁相比,分段锁可以将锁的粒度减小,从而更好地满足不同场景的需求。
- 减少锁竞争:如果数据分布均匀,每个锁控制的数据区域不会太大,从而减少了锁的竞争。通过合理地分布数据到不同的段,可以降低线程对同一数据段的竞争,从而提高并发性能。
分段锁缺点:
- 内存碎片化:将数据分成多个段可能会导致内存碎片化。每个段可能需要独立的内存空间,并且可能需要非连续的内存分配,这可能会导致内存碎片和空间浪费。
- 锁竞争概率低:当数据分布不均匀时,某些段上的锁竞争概率可能会很高,导致性能下降。尽管可以通过合理地分布数据来减少这种情况的发生,但在极端情况下仍然可能存在锁竞争的问题。
- 实现复杂性:分段锁需要维护多个锁的控制和管理,增加了实现的复杂性和潜在的错误风险。需要确保正确地管理每个段的锁定和解锁操作,以避免出现死锁或竞态条件等问题。
- 扩展性问题:分段锁的数量是固定的,这可能导致在某些情况下难以扩展。如果需要更多的段来容纳更多的数据或线程,可能需要重新设计整个锁机制。
🟢 还有哪些其他的线程安全哈希表实现
除了 ConcurrentHashMap,还有其他几种线程安全的哈希表实现。其中一种是 Hashtable,另一种是 Collections.synchronizedMap。然而,这些实现方法都存在性能问题,因为它们在多线程环境下容易造成锁竞争,导致性能下降。
具体来说,Hashtable 是早期 Java 中的线程安全哈希表实现,它使用一个内部锁来保护整个哈希表的操作。这意味着在多线程环境下,只有一个线程能够访问哈希表,其他线程必须等待锁释放。因此,Hashtable 的性能在竞争激烈的场景下较差。
另外,Collections.synchronizedMap 方法提供了一个线程安全的包装器,可以用于将普通的 Map 转换为线程安全的版本。然而,它也是对整个哈希表进行加锁,因此在多线程环境下性能同样较差。
相比之下,ConcurrentHashMap 的设计更加先进,它通过分段锁技术将数据分成多个段,并对每个段进行加锁。这样可以在多线程环境下同时访问不同的段,提高了并发性能。因此,在需要线程安全的哈希表时,推荐使用 ConcurrentHashMap。
🟠Hashtable和 Collections区别
Hashtable和Collections的主要区别在于同步性、历史背景以及使用场景。
- 同步性:Hashtable是线程安全的,所有的公共方法都有synchronized关键字,这意味着在多线程环境下,Hashtable是安全的。而Collections则提供了一系列帮助方法,如排序、搜索、线程安全化等,但它本身并不是线程安全的。
- 历史背景:Hashtable是基于陈旧的Dictionary类,它在Java 1.1中就已经存在。而Collections类是Java 1.2中引入的,它为集合类提供了一系列静态方法。
- 使用场景:如果对同步性或与遗留代码的兼容性没有任何要求,建议使用HashMap,因为它在效率上可能更高。而Collections主要用于对集合类进行各种操作,如排序、搜索等。
Hashtable和Collections在同步性、历史背景和使用场景上存在明显的差异。需要根据具体的使用场景和需求来选择使用哪种方式。
看一下具体的使用Hashtable和Collections的示例:
使用Hashtable的示例:
import java.util.Hashtable;public class HashtableExample {public static void main(String[] args) {Hashtable<String, String> hst = new Hashtable<>();String sid = "SID1";String name = "Name1";hst.put(sid, name);System.out.println("添加成功,是否继续添加? (Y/N)");String temp = Console.ReadLine();if (temp == "Y" || temp == "y") {continue;} else {break;}// 输出键为奇数的元素System.out.println("奇数键的元素:");for (var iteminhst : hst) {if (iteminhst.Key % 2 == 1) {System.out.println("{0}, {1}", iteminhst.Value, iteminhst.Key);}}}
}
使用Collections的示例:
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Scanner;public class CollectionsExample {public static void main(String[] args) {List<String> list = new ArrayList<>();Scanner scanner = new Scanner(System.in);while (true) {System.out.println("请输入一个字符串(输入exit退出):");String input = scanner.nextLine();if (input.equalsIgnoreCase("exit")) {break;} else {list.add(input);}// 对列表进行排序并输出Collections.sort(list);System.out.println("排序后的列表:");for (String str : list) {System.out.println(str);}}}
}
🟡分段锁和锁之间的区别是什么
分段锁和锁之间的区别:
分段锁是ConcurrentHashMap中使用的锁策略,实质是一种锁的设计策略,并不是指某一个特定的锁。它不是对整个数据结构加锁,而是通过hashcode来判断该元素应该存放的分段,然后对这个分段进行加锁。这种策略的优点在于细化锁的粒度,提高并发性能。当多个线程同时访问不同的分段时,可以实现真正的并行插入,提高并发性能。而当统计size时,需要获取所有的分段锁才能统计。
而锁则是指用于保证线程安全的机制,通过加锁来防止多个线程同时访问某一共享资源,以避免数据不一致的问题。常见的锁有公平锁和非公平锁。公平锁按照申请锁的顺序来获取锁,而非公平锁则不是按照申请锁的顺序来获取锁,其优点在于吞吐量比公平锁大。
分段锁是一种设计策略,通过对数据进行分段并加锁来提高并发性能;而锁则是一种保证线程安全的机制,通过加锁来避免数据不一致的问题。
🟢分段锁比锁更加安全吗
分段锁和锁都是线程安全哈希表实现中使用的技术,它们各自具有不同的优缺点,无法简单地判断哪个更加安全。
分段锁的优点在于它能够提高并发性能,通过将数据分成多个段并使用锁来保护每个段,允许多个线程同时访问不同的段,而不会相互阻塞。这种策略能够减少锁的竞争,从而提高并发性能。另外,分段锁还可以通过细化锁的粒度来提高并发性能,使得在多线程环境下能够更好地利用系统资源。
然而,分段锁也存在一些缺点。首先,它需要更多的锁,因为每个段都需要一个锁来保护。这可能会导致更多的锁竞争和上下文切换,从而降低性能。其次,分段锁的实现较为复杂,需要处理多个段之间的同步和通信,增加了代码的复杂性和出错的可能性。
锁的优点在于实现简单,使用方便。通过加锁来保证线程安全,可以避免多个线程同时访问共享资源,从而避免数据不一致的问题。但是,锁的缺点在于它可能会降低并发性能,因为多个线程访问共享资源时需要等待获取锁。如果锁的粒度较大,可能会导致大量的锁竞争和上下文切换,从而降低系统的吞吐量。
分段锁和锁都是线程安全哈希表实现中使用的技术,它们各有优缺点。选择使用分段锁还是锁取决于具体的应用场景和需求,需要根据实际情况进行权衡和选择。
🟢弱一致性保障
ConcurrentHashMap 提供的是弱一致性保障,这是因为在多线程并发修改 ConcurrentHashMap时,可能会出现一些短暂的不一致状态,即一个线程进行了修改操作,但是另一个线程还没有看到这个修改。因此,在并发修改 ConcurrentHashMap 时,不能保证在所有时刻 ConcurrentHashMap 的状态都是一致的。
首先就是因为前面提到的弱一致性迭代器,在 ConcurrentHashMap 中,使用选代器遍历时,不能保证在迭代器创建后所有的元素都被迭代器遍历到。这是因为在迭代器遍历过程中,其他线程可能会对ConcurrentHashMap 进行修改,导致迭代器遍历的元素发生变化。为了解决这人问题ConcurrentHashMap 提供了一种弱一致性选代器,可以获取到在迭代器创建后被添加到ConcurrentHashMap 中的元素,但是可能会获取到迭代器创建后被删除的元素。