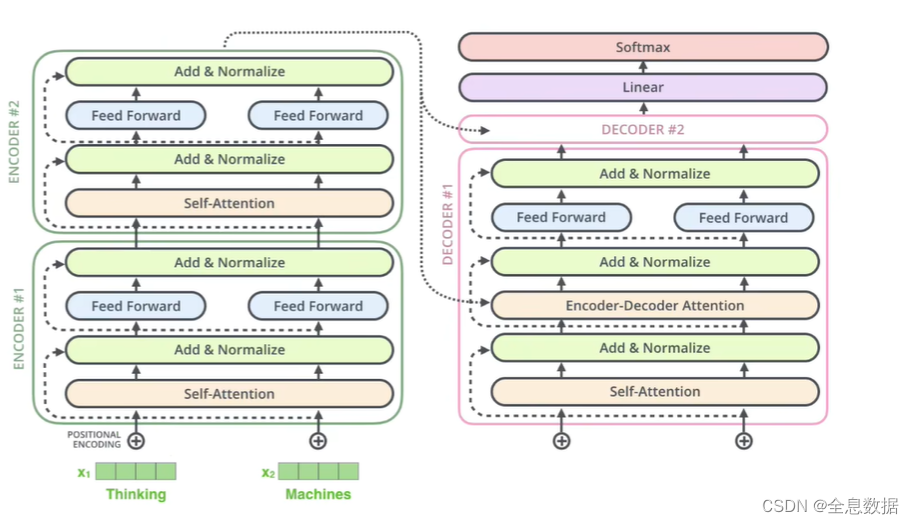
一、说明
栏目《NLP入门到精通》本着从简到难得台阶式学习过度。将自然语言处理得知识贯穿过来。本栏目得前导栏目是《深度学习》、《pytorch实践》,因此,读者需要一定得深度学习基础,才能过度到此栏目内容。
二、博客建设理念
本博客基地,将建成人工智能领域的参考资料库;这个资料库收集的是AI的关键技术、AI最新技术。博客文章来源有三:1 博主本人所作,2 另一些是学习中的笔记文档,3 追踪当前全球AI前缘技术论文,这些所谓的前缘性技术,就是尚没有编程印刷书籍的技术文章。对于这些他人文章,博主进行二次创作,如:多文合并、追加段落、重新组织。因而无版权之忧。
另外,本博客基地文章必须保证有一定技术和理论高度,大致与硕士生水平相当。
三、收费栏目订阅方法
3.1 付费价格标准
本博客基地,原则上收费文章为每篇0.5-1元左右。以下表标示栏目的标价信息。
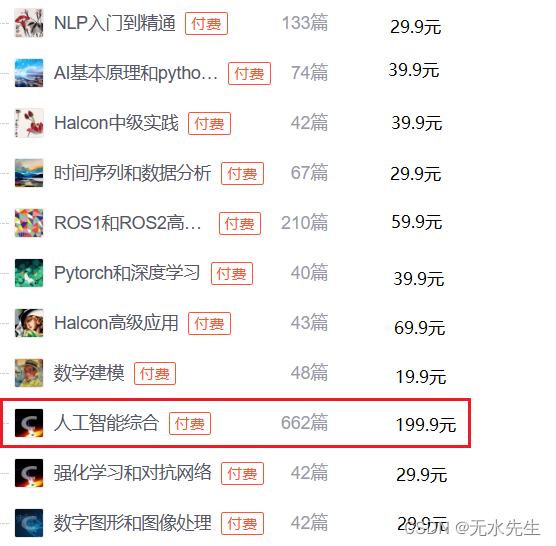
3.2 人工智能综合栏目
【人工智能综合】栏目文章最多,收费最高。而【人工智能综合】不是一个新栏目,是其他栏目的合编。它包含了七个AI题目的栏目,如下图:
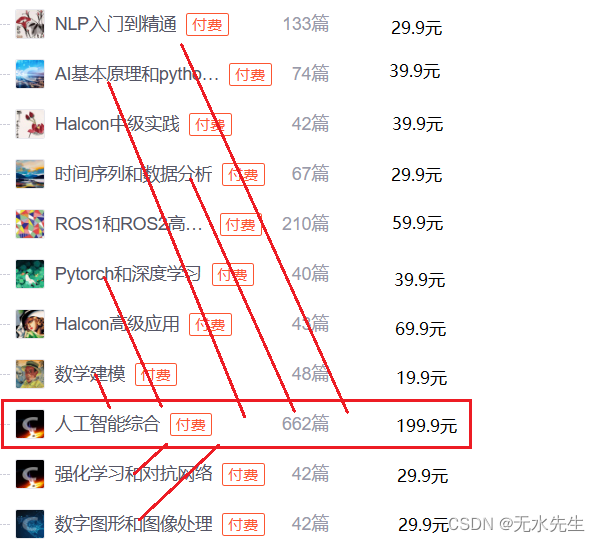
3.3 栏目中有些文章与栏目不符合
有些NLP栏目出现与本栏目不符的题目,似乎栏目管理不专业。情况是这样的,付费栏目只能追加,系统不允许删除,一旦操作失误就无法调整和改正,因此也就无法严格管理了,请大家见谅。
四、 栏目《NLP入门到精通》-基础文章
| 单元内容范围 | 专题描述 | 备注 |
|---|---|---|
| 第一单元: | 文本分类,基于统计学模型。 | 待续 |
| 第二单元 | 词嵌入,基于深度学习网络。 | |
| 第三单元: | CNN。LSTM,序列神经网络,句法分析。 | |
| 第四单元: | 在词嵌入基础上,对上下文进行分析。 | |
| 第五单元: | Bert词法,词性分析。 | |
| 第六单元 | transformers语言翻译,词法、句法综合。 | |
| 第七单元 | LLM大语言模型。 | |
| 第八单元 | 主题模型,文本摘要提取,语义分解。 | |
| 第九单元 | 综合知识。 |
第一单元:文本分类
该专题专门针对 基础学员,对基本的pytorch内容、语法、类和属性等进行了解,以便以后能明确无疑地应用。此专题在不断更新中,目前的全部文章是:
【NLP模型】文本建模(2)TF-IDF关键词提取原理
【NLP概念源和流】 02-稠密文档表示(第 2/20 部分)
【NLP】 实施文本分类器
【NLP】 文本技术方法指南
【NLP】PageRank、TextRank算法的原理解析_textrank和pagerank
第二单元:词嵌入
【NLP概念源和流】 06-编码器-解码器模型(6/20 部分)
【NLP概念源和流】 03-基于计数的嵌入,GloVe(第 3/20 部分)
【深度学习】编码器专题(01)
【深度学习】编码器专题(02)
【NLP】基础工程:词嵌入_nlp词嵌入
【深度学习】 NLP和神经网络表示
【NLP】Word2vec概念和演进史_word2vec的发展
第三单元:CNN和LSTM
【深度学习】看似不合理实则有效的RNN
【NLP概念源和流】 04-过度到RNN(第 4/20 部分)
【BBC新闻文章分类】使用 TF 2.0和 LSTM 的文本分类
【深度学习】深度了解 LSTM
【NLP】LSTM追根溯源
【NLP】理解LSTM的内在逻辑
第四单元:Attension
【NLP】多头注意力概念(01)
【NLP】Attention机制和RNN
第五单元:Bert
【NLP】使用BERT构建一个情绪分析模型
【NLP】BERT和原理揭示
【NLP】一项NER实体提取任务_无水先生的博客
【NLP】用NER自动实现简历摘要提取的案例
第六单元:Transformers
深入了解“注意力”和“变形金刚” -第1部分
用 Pytorch 自己构建一个Transformer
【NLP】机器翻译相关原理
【 NLP 】 句子transformer调用备忘录
【NLP】transformers的位置编码
【NLP】小项目:基于transformer的文本摘要
【NLP】分步图解transformer 数学示例
【NLP】Transformer模型原理(1)
【NLP】Transformer模型原理(2)
第七单元:大语言模型
【NLP】GPT-2:通过可视化了解语言生成
第八单元 :主题模型
【NLP】使用 LSA、PLSA、LDA 和 lda2Vec 进行主题建模
【深度学习】基于BRET的高级主题检测-
通过深度学习进行高级主题检测
第九单元:NLP综合
自然语言入行必知的基础概念
【NLP】KMP匹配算法
【NLP】有限自动机的KMP算法_kmp自动机
【NLP】从双曲面到双曲几何庞加莱盘
【人工智能】人工智能和双曲几何
【NLP】基于庞加莱损失函数的词嵌入模型
【NLP模型】文本建模(1)(BoW、N-gram、tf-idf)
语音识别:时间序列Damerau–Levenshtein距离_damerau-levenshtein
语音识别:时间序列的匹配算法(Needleman-Wunsch 算法)_时间匹配算法
【NLP】斯密斯-沃特曼的对齐算法(python)-CSDN博客
【NLP】自然语言处理之综述_自然语言处理综述-CSDN博客
语音识别:时间序列的Smith–Waterman对齐算法_smith-waterman
五、 栏目《NLP入门到精通》-后追加文章
(以上是该栏目的基本内容,下面是全部文章列出)
《NLP入门到精通》栏目导读(01/2)
【NLP模型】文本建模(2)TF-IDF关键词提取原理_tf-idf 关键词提取
【NLP概念源和流】 02-稠密文档表示(第 2/20 部分)
【NLP】 实施文本分类器_分类器 文本分析
【NLP】 文本技术方法指南
【NLP】PageRank、TextRank算法的原理解析_textrank和pagerank
【NLP概念源和流】 06-编码器-解码器模型(6/20 部分)_nlp解码器和编码器
【NLP概念源和流】 03-基于计数的嵌入,GloVe(第 3/20 部分)
【深度学习】编码器专题(01)
【深度学习】编码器专题(02)_mask: batch size, 1, sequence length (bool)
【NLP】基础工程:词嵌入_nlp词嵌入
【深度学习】 NLP和神经网络表示
【NLP】Word2vec概念和演进史_word2vec的发展
【深度学习】看似不合理实则有效的RNN
【NLP概念源和流】 04-过度到RNN(第 4/20 部分)
【BBC新闻文章分类】使用 TF 2.0和 LSTM 的文本分类
【深度学习】深度了解 LSTM 网络
【NLP】LSTM追根溯源
【NLP】理解LSTM的内在逻辑_lstm时间轴nlp的理解
【NLP】多头注意力概念(01)
【NLP】Attention机制和RNN_rnn attention机制
【NLP】使用BERT构建一个情绪分析模型_bert情绪分析模型
【NLP】BERT和原理揭示
【NLP】一项NER实体提取任务_nlp 给定一段新闻文本,本任务的目标是抽取出文本中的实体 代码
【NLP】用NER自动实现简历摘要提取的案例
深入了解“注意力”和“变形金刚” -第1部分
用 Pytorch 自己构建一个Transformer
【NLP】机器翻译相关原理
【 NLP 】 句子transformer调用备忘录_现在如何调用transformer
【NLP】transformers的位置编码
【NLP】小项目:基于transformer的文本摘要_transformer文本摘要
【NLP】分步图解transformer 数学示例
【NLP】Transformer模型原理(1)_a mathematical framework for transformer circuits.
【NLP】Transformer模型原理(2)
【NLP】GPT-2:通过可视化了解语言生成
【NLP】使用 LSA、PLSA、LDA 和 lda2Vec 进行主题建模
【深度学习】基于BRET的高级主题检测
通过深度学习进行高级主题检测
自然语言入行必知的基础概念
【NLP】KMP匹配算法
【NLP】从双曲面到双曲几何庞加莱盘_双叶双曲面 庞加莱圆盘 投影
【人工智能】人工智能和双曲几何_人工智能 几何
【NLP】基于庞加莱损失函数的词嵌入模型
【NLP模型】文本建模(1)(BoW、N-gram、tf-idf)_n-gram和bow
语音识别:时间序列Damerau–Levenshtein距离_damerau-levenshtein
语音识别:时间序列的匹配算法(Needleman-Wunsch 算法)_语音识别needleman-wunsch
【NLP】斯密斯-沃特曼的对齐算法(python)_python 实现smith-waterman算法局部比对
【NLP】自然语言处理之综述_nlp的综述最新
语音识别:时间序列的Smith–Waterman对齐算法_smith-waterman
Ubuntu系统如何连接WiFi_ubuntu wifi
Ubuntu知识: 文件压缩和解压?(zip指令)_ubuntu zip
【机器学习】了解 AUC - ROC 曲线_auroc曲线
机器视觉:ransac算法详解
halcon知识:常见三种模板匹配方法总结_halcon 模板匹配
《AI基本原理和python实现》栏目介绍
Simpy简介:python仿真模拟库-03/5
深度学习在语义分割中的进展与应用
机器学习指南:如何学习机器学习?
图卷积网络:GNN 简介【01/4】_pyg to_dense_adj
【NLP的python库(01/4) 】: NLTK_nltk.download('punkt') nltk.download('stopwords')
单词故事嵌入:通过自然语言处理解开叙事
RNN 单元:分析 GRU 方程与 LSTM,以及何时选择 RNN 而不是变压器
如何使用BERT生成单词嵌入?_bert如何做词向量嵌入
GPT 内部 — I : 了解文本生成
探索意义的深度:自然语言处理中的语义相似性
解码自我注意的魔力:深入了解其直觉和机制_注意力层的查询、键、值是模型参数吗
NLP项目:维基百科文章爬虫和分类【02】 - 语料库转换管道
谷歌BERT:从自然语言处理(NLP)初学者到高级的综合指南_google bert
LLM;超越记忆《第 2 部分 》
LLM:《第 3 部分》从数学角度评估封闭式LLM的泛化能力
深入了解前馈网络、CNN、RNN 和 Hugging Face 的 Transformer 技术!_前馈神经网络和cnn的区别
保留网络[02/3]:大型语言模型转换器的继任者”_retnet中的γ是如何实现的
NLP:从头开始的文本矢量化方法_nlp 文本向量化
3 — NLP 中的标记化:分解文本数据的艺术_标记化技术的参数
LLM:《第 1 部分》只是一个记忆技巧吗?
深入理解注意力机制(上)-起源
大型语言模型:DistilBERT — 更小、更快、更便宜、更轻_中文大语言模型参数最小的是什么
ConvNets 与 Vision Transformers:数学深入探讨
情感分析工具: TextBlob 与 VADER 的对比_用textblob、vader,采用离散表示法,按照正面、负面、中性进行划分,以得出量化的数
用于自然语言处理的 Python:理解文本数据_python文本分析 提取数据含义
Ultra:知识图谱推理的基础模型
用于智能图像处理的计算机视觉和 NLP_图像 nlp
NLP 项目:维基百科文章爬虫和分类 - 语料库阅读器_wiki爬虫
使用大型语言模型进行文本摘要_大语言模型 多文档理解 摘要
ChatGPT 在机器学习中的应用_chartgpt机器学习
【TensorFlow Hub】:有 100 个预训练模型等你用_model = hub.keraslayer() 行人检测
变分自动编码器【03/3】:使用 Docker 和 Bash 脚本进行超参数调整
【NLP的python库(02/4) 】:Spacy_pycharm spacy语言模型
2、NLP文本预处理技术:词干提取和词形还原_nlp文本大纲提取
从NLP到聊天机器人_java nlp 聊天机器人
NLP:使用 SciKit Learn 的文本矢量化方法
【NLP的Python库(04/4)】:Flair_flair分类器
【Gensim概念】01/3 NLP玩转 word2vec_gensim.downloader.load
如何将转换器应用于时序模型
掌握 AI 和 NLP:深入研究 Python — 情感分析、NER 等
深入了解“注意力”和“变形金刚”-第2部分
【NLP概念源和流】 05-引进LSTM网络(第 5/20 部分)
【NLP概念源和流】 01-稀疏文档表示(第 1/20 部分)
【NLP】多头注意力概念(02)
【NLP】理解LSTM的内在逻辑
【人工智能数学:01 高等概率论】(2) 离散型概率空间_离散概率空间