接上篇《45、Scrapy框架核心组件介绍》
上一篇我们学习了Scrapy框架的核心组件的使用。本篇我们进入实战第一篇,以58同城的Scrapy项目案例,结合实际再次巩固一下项目结构以及代码逻辑的用法。
一、案例网站介绍
58同城是一个生活服务类平台,涉及广泛的服务领域,从找工作、租房、买卖二手物品,到寻找兴趣伙伴,它都为用户提供了便捷的通道。58同城网站的信息量巨大,每天都有大量的用户在这里发布和浏览信息,包含丰富的生活服务选择。无论是家政服务、维修服务,还是教育培训、旅游出行,用户都能在58同城上找到对应的合作伙伴。
二、抓取案例分析
我们在58同城首页上方的搜索框中,搜索“后端开发”词条,可以看到跳转到了招聘板块,并在下方可以看到相应的职位推荐信息: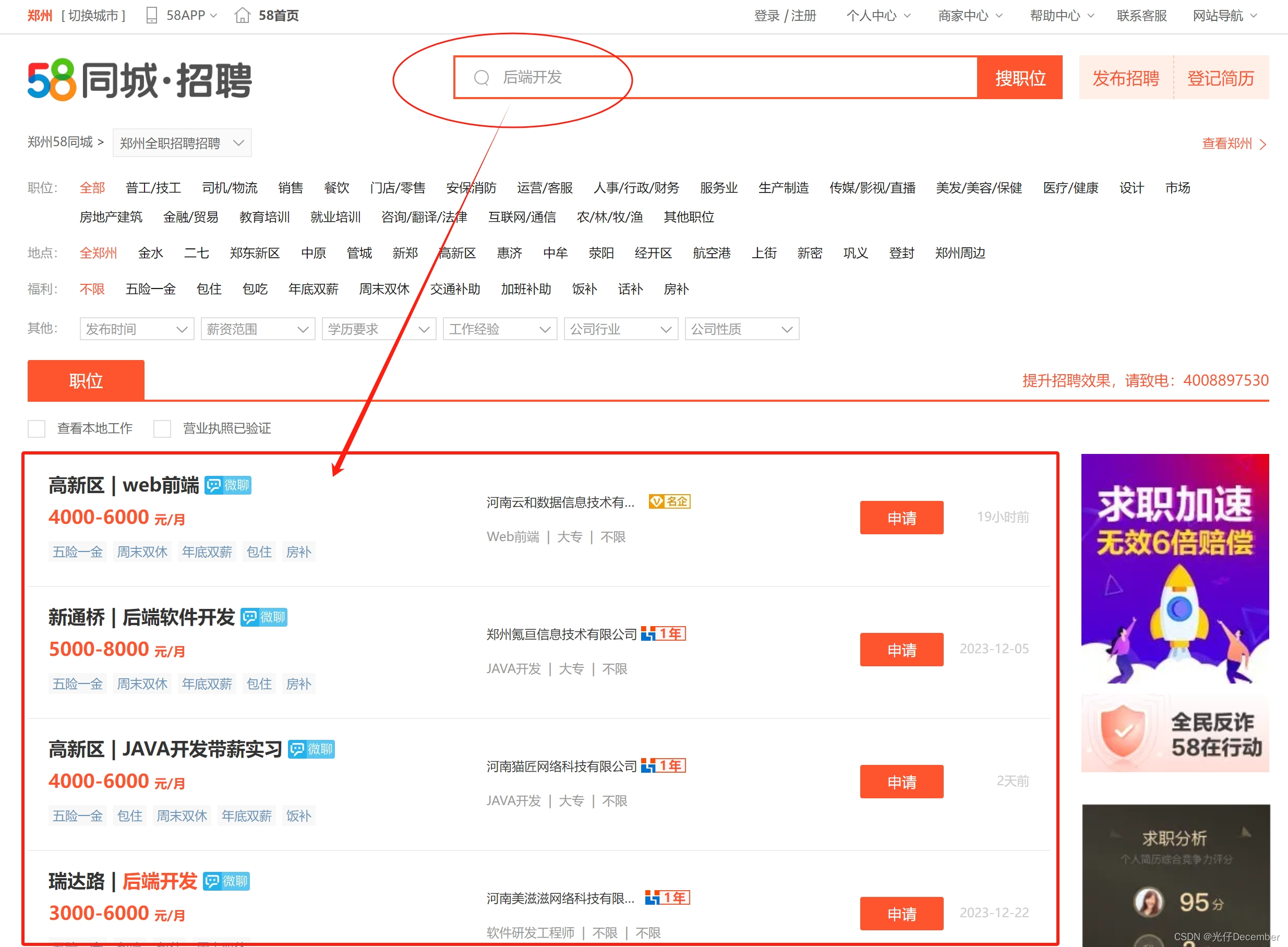
该信息是一个自上而下的列表,我们F12查看开发者信息,再次点击“搜职位”按钮,发现没有找到对饮的接口信息:
这说明该页面的搜索结果不是ajax异步的,而是请求服务器后,直接渲染出带结果的html界面了。所以该页面的地址栏信息,就是我们需要获取数据的请求地址:
https://zz.58.com/quanzhizhaopin/?key=%E5%90%8E%E7%AB%AF%E5%BC%80%E5%8F%91&classpolicy=strategy%2Cuuid_939eb358a0a14d338d323bb1480419b1%2Cdisplocalid_342%2Cfrom_674%2Cto_jump%2Ctradeline_job%2Cclassify_E&search_uuid=939eb358a0a14d338d323bb1480419b1&final=1
这个地址返回的就是带有职位信息的html报文:
三、创建58同城的Scrapy项目
我们来创建一下58同城Scrapy爬虫项目。首先我们打开PyCharm编辑器,在命令控制台咱们的代码文件夹下,运行“scrapy startproject scrapy_58tc_01”指令,创建Scrapy项目:
前往左侧项目区域,可以看到项目已经创建成功: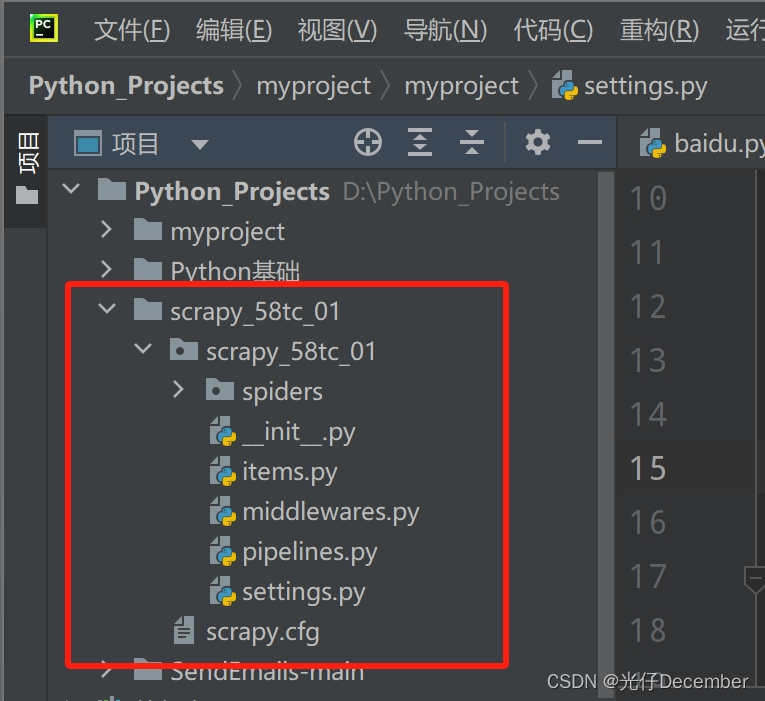
这里我们再回顾一下项目下每一个目录和文件的作用:
然后我们创建爬虫文件,进入项目文件夹的spiders文件夹,然后通过“scrapy genspider tc https://zz.58.com/quanzhizhaopin/?key=%E5%90%8E%E7%AB%AF%E5%BC%80%E5%8F%91&classpolicy=strategy%2Cuuid_939eb358a0a14d338d323bb1480419b1%2Cdisplocalid_342%2Cfrom_674%2Cto_jump%2Ctradeline_job%2Cclassify_E&search_uuid=939eb358a0a14d338d323bb1480419b1&final=1”指令,创建一个58同城招聘页面的爬虫文件:
我们发现报错了,需要咱们将&符号,用双引号括起来,因为&是scrapy命令中的的运算符,需要与字符串作区分:
scrapy genspider tc https://zz.58.com/quanzhizhaopin/?key=%E5%90%8E%E7%AB%AF%E5%BC%80%E5%8F%91"&"classpolicy=strategy%2Cuuid_939eb358a0a14d338d323bb1480419b1%2Cdisplocalid_342%2Cfrom_674%2Cto_jump%2Ctradeline_job%2Cclassify_E"&"search_uuid=939eb358a0a14d338d323bb1480419b1"&"final=1
我们修改后重新执行:
发现创建成功:
基础代码:
import scrapyclass TcSpider(scrapy.Spider):name = "tc"allowed_domains = ["zz.58.com"]start_urls = ["https://zz.58.com/quanzhizhaopin/?key=%E5%90%8E%E7%AB%AF%E5%BC%80%E5%8F%91&classpolicy=strategy%2Cuuid_939eb358a0a14d338d323bb1480419b1%2Cdisplocalid_342%2Cfrom_674%2Cto_jump%2Ctradeline_job%2Cclassify_E&search_uuid=939eb358a0a14d338d323bb1480419b1&final=1"]def parse(self, response):pass然后我们把setting.py配置文件的遵守robot协议的配置,改成False,防止反扒协议导致爬取不成功:
ROBOTSTXT_OBEY = False接下来我们就可以在爬虫文件中,编写我们获取职位列表信息的代码了。
四、编写爬虫的案例
这里我们在上面创建好的爬虫程序中,编写获取职位列表的代码逻辑。这里我们主要用到了response的以下几个方法:
response的属性和方法
●response.text 获取的是响应的字符串
●response.body 获取的是二进制数据
●response.xpath 可以直接使用xpath方法来解析response中的内容
●response.extract() 提取seletor对象的data属性值
●response.extract_first() 提取的seletor列表的第一个数据
下面我们先来通过网页的xpath工具,获取职位列表的xpath语句(具体xpath使用及浏览器插件安装,详见我之前的博文《【Python从入门到进阶】28、xpath的安装以及使用》)。
首先我们获取职位的list列表,这里我们F12打开开发者模式,定位到职位列表代码,copy一下职位列表的xpath: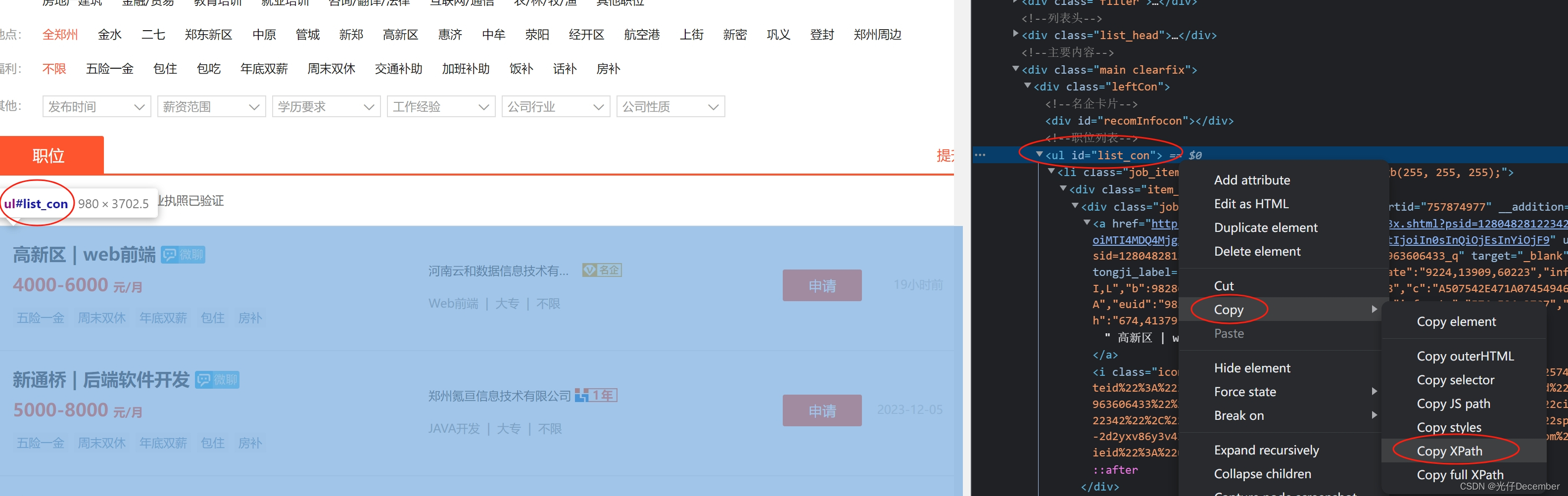
代码://*[@id="list_con"]
然后我们剖析里面的每一个li,发现他们的对应关系:
此时我们用xpath工具测试一下,我们获取其中一个字段的效果:
此时我们就知道了每个内容的获取方式,下面开始写代码:
import scrapyclass TcSpider(scrapy.Spider):name = "tc"allowed_domains = ["zz.58.com"]start_urls = ["https://zz.58.com/quanzhizhaopin/?key=%E5%90%8E%E7%AB%AF%E5%BC%80%E5%8F%91&classpolicy=strategy%2Cuuid_939eb358a0a14d338d323bb1480419b1%2Cdisplocalid_342%2Cfrom_674%2Cto_jump%2Ctradeline_job%2Cclassify_E&search_uuid=939eb358a0a14d338d323bb1480419b1&final=1"]def parse(self, response):print("=======爬虫结果开始=======")text = response.textif text.find("访问过于频繁") != -1:print("访问过于频繁,等5-10分钟后再试")else:list_con = text.xpath('//*[@id="list_con"]/li')_id = 0for con in list_con:_id += 1print(f"【第{_id}份工作信息】:")job_name = con.xpath('.//div[@class="job_name clearfix"]/a/text()') # 获取工作名称print("【工作名称】:",str(job_name[0]).replace('\r', '').replace('\n', '').replace(' ', '')) # 去除换行符和回车符,以及多余空格job_salary = con.xpath('.//p[@class="job_salary"]/text()') # 获取工作薪水print("【工作薪水】:", job_salary[0])job_wel_list = con.xpath('.//div[@class="job_wel clearfix"]/span') # 获取工作标签job_wel = ""for job_wel_item in job_wel_list:job_wel += str(job_wel_item.text).strip() + " "print("【工作标签】:", job_wel)comp_name = con.xpath('.//div[@class="comp_name"]/a/text()') # 获取招聘公司名称print("【招聘公司名称】:",str(comp_name[0]).replace('\r', '').replace('\n', '').replace(' ', '')) # 去除换行符和回车符,以及多余空格job_require_list = con.xpath('.//p[@class="job_require"]/span') # 获取招聘要求job_require = ""for job_require_item in job_require_list:job_require += str(job_require_item.text).strip() + " "print("【招聘要求】:", job_require)print("=======爬虫结果结束=======")执行“scrapy crawl tc”运行爬虫程序,效果:
结果信息(以前三个为例):
=======爬虫结果开始=======
【第1份工作信息】:
【工作名称】: 高新区|web前端
【工作薪水】: 4000-6000
【工作标签】: 五险一金 周末双休 年底双薪 包住 房补
【招聘公司名称】: 河南云和数据信息技术有限公司
【招聘要求】: Web前端 大专 不限
【第2份工作信息】:
【工作名称】: 新通桥|后端软件开发
【工作薪水】: 5000-8000
【工作标签】: 五险一金 周末双休 年底双薪 包住 房补
【招聘公司名称】: 郑州氪亘信息技术有限公司
【招聘要求】: JAVA开发 大专 不限
【第3份工作信息】:
【工作名称】: 高新区|JAVA开发带薪实习
【工作薪水】: 4000-6000
【工作标签】: 五险一金 包住 周末双休 年底双薪 饭补
【招聘公司名称】: 河南猫匠网络科技有限公司
【招聘要求】: JAVA开发 大专 不限
................
如果调试次数过多,会报这个错:
这是58同城前端为了防止爬虫抓取的屏蔽措施,这里我们需要等一段时间再实验(或者换一个网络或者使用代理访问,换网络后,上面的url地址要重新复制)。
注:如果访问不到页面,可以下载我保存好的html页面,并用直接获取html文件的方式先测试一下,下面是html文件和测试爬虫逻辑代码的下载:
58同城搜索页静态html代码爬虫xpath测试demo![]() https://download.csdn.net/download/u013517797/88713719
https://download.csdn.net/download/u013517797/88713719
至此,58同城的Scrapy项目案例讲解完毕。
转载请注明出处:https://guangzai.blog.csdn.net/article/details/135440258