redis的五个基本数据类型。
redis字符串(String)
string是redis最基本的类型,一个key对应一个Tvalue。
string类型是二进制安全的,意思是redis的string可以包含任何数据,比如jpg图片或者序列化的对象。
string类型是Redis最基本的数据类型,一个redis中字符串value最多可以是512M
redis列表(List)、
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
它的底层实际是个双端链表,最多可以包含2^32- 1个元素(4294967295,每个列表超过40亿个元素)
redis哈希表(Hash)
Redis hash是一个string类型的field(字段)和 value(值)的映射表,hash 特别适合用于存储对象。
Redis中每个hash可以存储2个32-1键值对(40多亿)
redis集合(Set)
Redis的Set是String类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据,集合对象的编码可以是intset或者hashtable。
Redis中Set集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
集合中最大的成员数为2^32-1(4294967295,每个集合可存储40多亿个成员)
redis有序集合(ZSet、Sorted Set)
Redis zset和 set一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数,redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
zset集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。集合中最大的成员数为2^32-1(40亿)
主动更新策略
操作缓存和数据库时有三个问题需要考虑
1.删除缓存还是更新缓存?
更新缓存:每次更新数据库都要更新缓存,100个更新操作就要更新100次缓存,可能其中99个中间的数据版本没有一点作用,无效写的操作太多了。
删除缓存:更新数据库时让缓存失效,查询时再更新缓存,这样子的效果较好,这种方案写的频率会更低,有效更新会更多。
2.如何保证缓存与数据库的操作的同时成功或者失败?
单体系统:将缓存与数据库操作放在一个事务
分布式系统:利用TCC等分布式事务方案
3.先操作缓存还是先操作数据库?
- 先删除缓存,再操作数据库
这种会出现缓存无效更新的情况,就是再删除缓存之后,更新数据库还未成功的时候,有查询请求查询缓存,未命中,就会查询数据库,此时因为数据库还未更新成功,查询到的值是未更新的值,最后将这个未更新的值写入缓存,最后当数据库更新成功之后,就出现了数据不一致的问题(这种情况出现的概率较高) - 先操作数据库,再删除缓存
这种也会出现缓存无效更新,当我接收到更新数据库的请求的时候,还没有将数据库的数据更新完,此时一条查询语句打到redis,并且此时刚好数据过期,未命中,就会去查询数据库,此时查询到的数据是还未修改的旧数据,然后更新操作结束,删除了缓存,最后查询请求将在数据库中查到的数据写入缓存,这个数据是数据库未更新前的数据,就出现了数据不一致的问题(这种情况出现的概率很小)
缓存面临问题
1.缓存穿透
缓存穿透是指客户端请求的数据再缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
解决方案
- 缓存空对象
思路就是如果数据库中也没有这个数据,就将null存进redis中,这样后面的请求就不会达到数据库了。
优点:实现简单,维护方便
缺点:1.额外的内存消耗。2.可能造成短期的不一致
简单解决方案,就是对null的数据的TTL设置为很短时间,例如5分钟等 - 布隆过滤
思路就是请求先打到布隆过滤器中判断数据存不存在,存在就放行,不存在就拒绝请求继续下发。
优点:内存占用较少,没有多余的key
缺点:1.实现复杂(redis自带有)2.存在误判可能(不存在就真的不存在,存在不一定真的存在)。
2.缓存雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案
- 给不同的key的TTL添加随机值
这个是当前我会的一种,就是在向redis中缓存数据时,存储的时间用随机数生成,这样就可以将一个时间点的缓存的数据的过期时间分散,降低缓存雪崩风险。 - 利用redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
3.缓存击穿
缓存击穿问题也叫热点key问题,就是一个被高并发访问并且缓存重建业务比较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。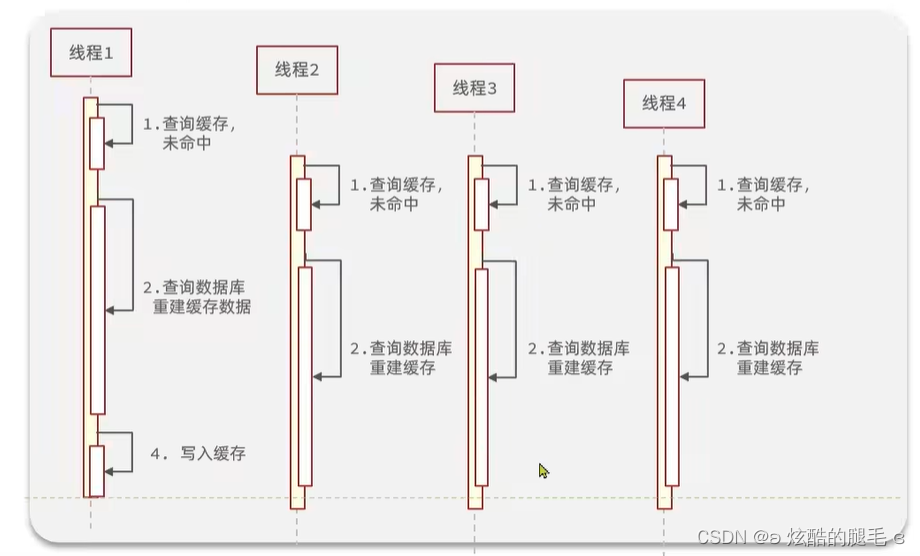
解决方案
- 互斥锁
当一个线程查询这个热点失效key的时候,查询为命中,然后就获取互斥锁,获取互斥锁获取成功之后就去查询数据库重建缓存数据,然后在写入缓存,最后再释放锁,在这个线程拿到互斥锁一直到释放锁的过程中,其他线程查询这个热点失效key的时候尝试去获取互斥锁失败,就返回到查询缓存,一直重复,知道拿到锁的线程写入缓存之后,查询命中,其他线程拿到的就是更新后的数据。
- 逻辑过期
不在设置TTL,在存储数据的时候加一个过期时间的字段,这是一个逻辑上需要我们通过代码维护的过期时间。这样的话查询缓存就一定会命中,拿到缓存中的数据之后,判断逻辑时间是否过期,如果发现已经过期,就获取互斥锁,然后开启一个新线程,在那个新线程中执行查询数据库重建缓存数据,然后再写入缓存,重置逻辑过期时间,最后再释放锁,然后之前那个线程就返回过期的数据,相当于异步同步数据,然后其他的数据在获取互斥锁失败之后返回过期数据。
互斥锁优点:1.没有额外的内存消耗。2.保证一致性。3.实现简单。
互斥锁缺点:1.线程需要等待,性能受影响。2.可能有死锁风险。
逻辑过期优点:线程无需等待,性能较好
逻辑过期缺点:1.不保证一致。2.有额外的内存消耗。3.实现复杂。





 实现音频数据解码并且用SDL播放](https://img-blog.csdnimg.cn/direct/185cb854fb7543ca9331791f1f48ec50.png)