今天推荐一个黑科技开源项目,只需要你 5 秒钟的声音对话,就能克隆出你的声音,而且能够实时的生成你任意语音。
是不是很顶?
我举个例子,如果我这里有 300 条你说话的语音,我把你的语音数据用这个开源项目去训练,训练完成后,我就可以使用这个训练好的模型生成任何你说的语音了。
你会听到一个声音和你一模一样的人说你没说过的话,那种感觉真的细思极恐。
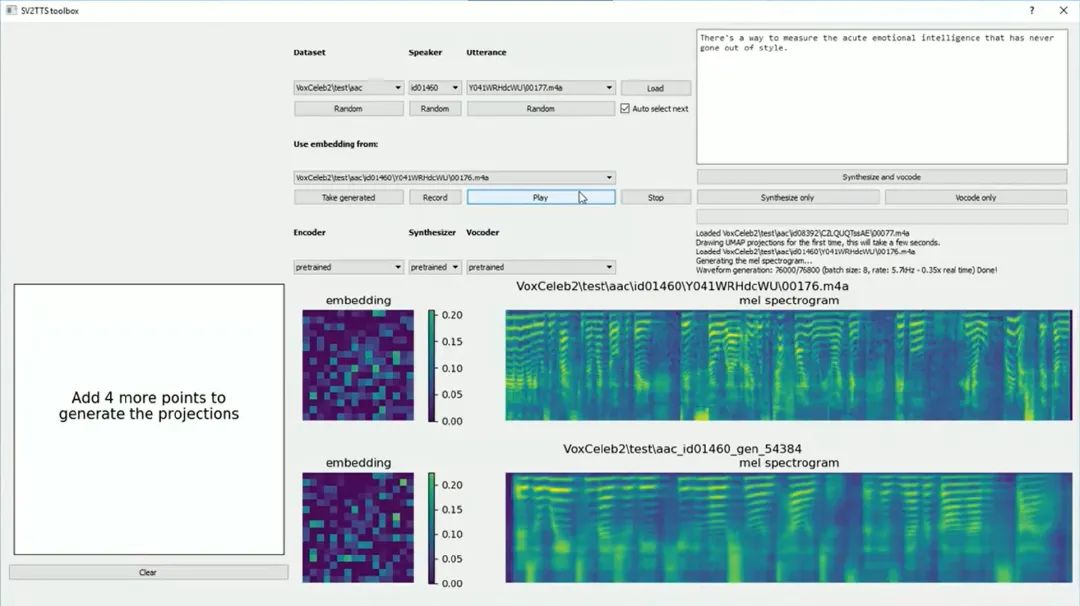
这个黑科技就是:Real-Time-Voice-Cloning,现在已经开源,GitHub 24K 的 Star,最重要的是,这个项目提供了 GUI 界面,交互傻瓜式操作,语音采集、训练、生成都可以交互完成,很方便。
地址:https://github.com/CorentinJ/Real-Time-Voice-Cloning
环境配置
首先你需要 Python 3.6 的环境、安装 PyTorch(要求版本 > = 1.0.1)。Pytorch 是深度学习框架,你可以通过这个站点来安装这个库。
https://pytorch.org/get-started/locally/
紧接着需要安装 ffmpeg:
地址 https://ffmpeg.org/download.html#get-packages。除此之外,你还需要安装其他的依赖包。将项目下载下来,在包含 requirements.tx 目录下运行命令 pip install -r requirements.txt 就行了。
下载预训练的模型
把开源作者训练好的模型下载下来,我们不用自己训练,直接拿来用就行了:https://github.com/CorentinJ/Real-Time-Voice-Cloning/wiki/Pretrained-models,
下载完毕要放到如下的文件夹里面。
encoder\saved_models\pretrained.pt
synthesizer\saved_models\pretrained\pretrained.pt
vocoder\saved_models\pretrained\pretrained.pt
Details about model training and audio samples can be found here: https://blue-fish.github.io/experiments/RTVC-7.html启动
当你配完了环境,就可以尝试使用这个黑科技了。运行命令 python demo_toolbox.py 就能启动这个黑科技啦!
下面是比较详细的使用教程,遇到问题可以查看帮助:
https://www.bilibili.com/video/av79481223?zw
https://blog.csdn.net/weixin_41010198/article/details/113186232
最后结尾说一下,我用这个模型试了一下,因为这个模型是老外开源的,所以训练的数据是英语的语音,我试了一下说中文,简直就是不会说中文的老外讲中文一个味道,现在我怀疑世界的真实性了。
开源地址:https://github.com/CorentinJ/Real-Time-Voice-Cloning
原文链接:
这个 GitHub 项目能克隆你的声音











![[GN] 微服务开发框架 --- Docker的应用 (24.1.9)](https://img-blog.csdnimg.cn/direct/5e2e0e00b1894bea9f94b4b269c015ce.png)