爬虫传参
import requestsurl = 'http://www.xxx'# get 或 post 传参数据
data = {"pageNo": 1652,"pageSize": 10,
}headers = {'Cookie': '','Host': '','Origin': '','Referer': '','User-Agent': '',
}# get 请求
# res = requests.get(
# url,
# params=data,
# headers=headers,
# )# post 请求
res = requests.post(url,data=data,headers=headers,
)print(res.content.decode('utf-8'))post 传参的请求可从浏览器复制字典粘贴。
header 请求头参数,提供如下工具脚本:
把请求头参数复制到content.txt 文件中
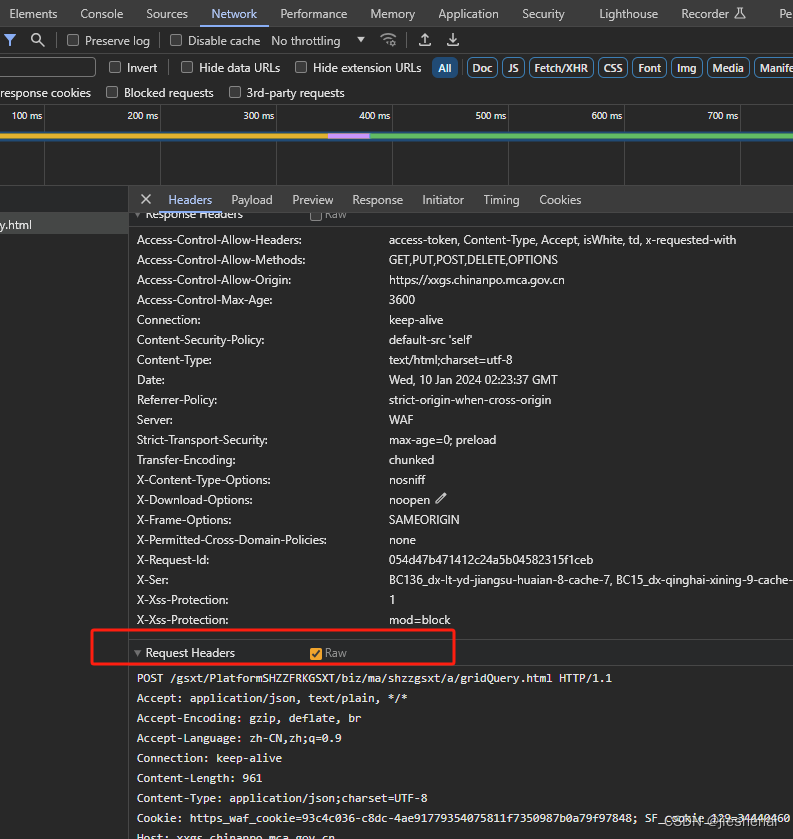
content.txt:
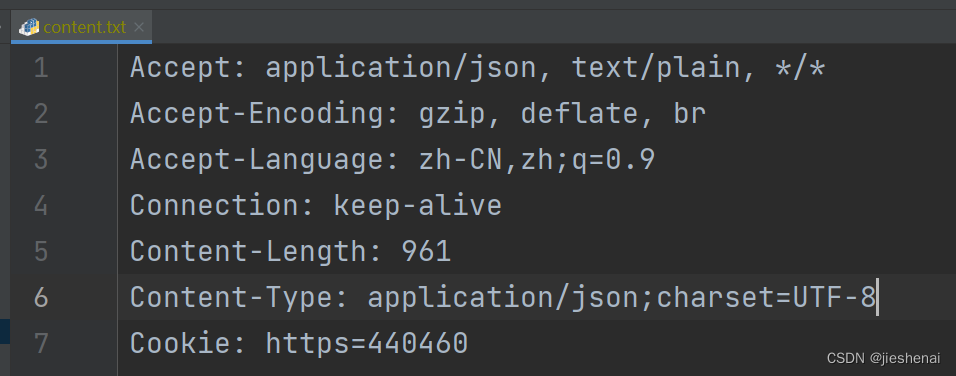
工具:
# 假设txt文件内容如下
txt = open('content.txt').read()# 使用splitlines()方法将txt内容分割为行,然后使用json.loads()方法将每一行转换为字典
lines = txt.splitlines()
data = [line.split(': ') for line in lines]
headers_dict = {k: v for k, v in data}# 输出字典
print(headers_dict)