大家好,我是可夫小子,关注AIGC、读书和自媒体。解锁更多ChatGPT、AI绘画玩法。加:keeepdance,备注:chatgpt,拉你进群。
提示:本案例虽然不需要写代码,但需要有一定的软件开发基础,能够搭建环境,调整代码。我使用的是Pycharm IDE,Python版本为v3.8
获得代码
你现在是一名资深的软件工程师,请用Python写一个爬虫程序,要求爬取豆瓣电影Top250每一页的电影名和评分,保存到excel表格中。

加上角色定位的话,它就会考虑浏览器的请求头,否则就没办法正常运行。
复制出来,粘贴到Pycharm IDE,或者其他文本文件,重命名为douban_top250.py即可。
完整代码:
import requests
import openpyxl
from bs4 import BeautifulSoup# 设置请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}# 创建 Excel 表格
workbook = openpyxl.Workbook()
worksheet = workbook.active
worksheet.title = 'Top250'# 爬取每一页的电影名和评分
for i in range(10):url = f'https://movie.douban.com/top250?start={i * 25}&filter='response = requests.get(url, headers=headers)soup = BeautifulSoup(response.text, 'html.parser')items = soup.find_all('div', class_='hd')for item in items:title = item.a.span.textrating = item.parent.find('span', class_='rating_num').textworksheet.append([title, rating])# 保存表格
workbook.save('douban_top250.xlsx')
安装依赖包
pip3 install openpyxl
pip3 install beautifulsoup4
运行
在IDE中,右键执行RUN

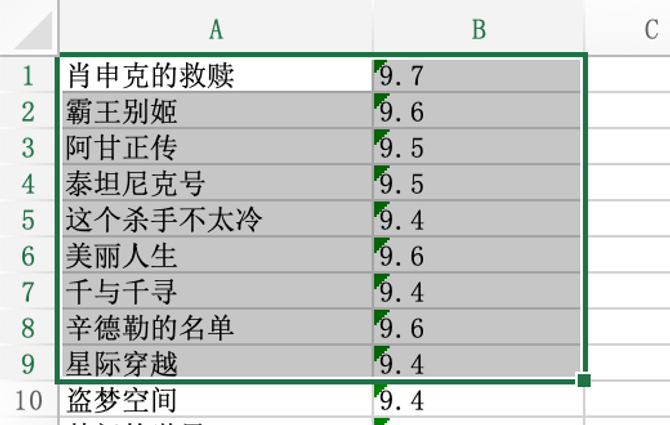
检查结果
运行完之后,就在douban_250.py文件的同级目录下,生成一个名为douban_top250.xlsx文件,打开就能看到爬取结果了。
总结
在整个过程,我没有写一行代码,我真心感叹:太强了。另外,还可以给出其他要求,增加类似导演、年代这样的字段。只要跑通了这个Demo,ChatGPT在软件开发上的想象空间巨大。
📣通知
我的《小白玩转ChatGPT》小册上线啦,已有180多位同学在里面学习,诸多福利一起赠送。只需一杯奶茶钱,让我们联系更紧密。