| 30.文献阅读笔记CPMs | ||
| 简介 | 题目 | Convolutional Pose Machines |
| 作者 | Shih-En Wei, Varun Ramakrishna, Takeo Kanade, and Yaser Sheikh, CVPR, 2016. | |
| 原文链接 | https://arxiv.org/pdf/1602.00134.pdf | |
| 关键词 | Convolutional Pose Machines(CPMs)、articulated pose estimation | |
| 研究问题 | Pose Machines provide a sequential prediction framework for learning rich implicit spatial models. Pose Machines为了学习丰富的隐式空间模型提供了序列预测框架。 将CNN应用于pose machine framework 梯度消失的问题: 反向传播梯度在网络的多个层中传播时强度会减弱。 增大感受野,一般有如下几种方式: 增大pool,但是这种做法对图片额外添加的信息过多,会牺牲精度; 增大卷积核,但这种方式会增加参数量; 增加卷积层,但卷积层过多会造成网络的负担,造成梯度消失等问题 | |
| 研究方法 | 将CNN应用于pose machine framework 学习图像特征和图像相关的空间模型的task of pose estimation(姿态估计) CNN直接对来自上阶段的belief maps进行操作,对零件位置做出越来越精确的估计,而无需明确的图形模型式推理。 提供了一个自然的学习目标函数,强制执行中间监督,补充反向传播梯度并调节学习过程,解决了梯度消失的难题。 图像特征和前一阶段生成的belief maps都被用作输入。belief maps为后续阶段提供了每个部件位置空间不确定性的非参数编码,使 CPM 能够学习丰富的、与图像相关的部件间关系空间模型。 不使用图形模型,对belief maps进行操作,所以整个架构完全可微分,可以端对端训练。 为了捕捉longrange interactions:需要较大的感受野  Pose machines 和cnn pose machines对比 输入:裁剪图像归一化为368 × 368 网络结构:五个卷积层和两个1 × 1卷积层组成的网络结构(全卷积结构) 2c:第一阶段仅从局部图像证据中预测部分信念。证据是局部的,因为网络第一阶段的感受野被约束在输出像素位置周围的一个小块上。以一个较小的感受野对图像进行局部检查。 如果人体有p个关节点,那么belief map有p+1层(还有背景层) 其实就是heatmaps,各通道表示各关键点在每个像素位置处的概率 2d:第二阶段网络的输出层获得足够大的感受野,以便学习各部分之间潜在的复杂和long-range correlations。还要输入一个center map。center map是高斯响应,构造响应图的真值。 增大感受野: 增大stride,确实stride越大感受野相应的也增大,并且论文中指出,在高精度区域,8stride和4stride表现一样好。 | |
| 研究结论 | 由卷积网络组成的序列架构能够通过在阶段之间交流日益精炼的不确定性保持信念来隐式地学习姿态的空间模型。 在所有的主要基准上都达到了最先进的准确性。 | |
| 创新不足 | 多人检测失败  | |
| 额外知识 | 高斯响应 | |
(论文阅读30/100)Convolutional Pose Machines
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/191245.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

屏幕截图软件 Snagit mac中文版软件特点
Snagit mac是一款屏幕截图和视频录制软件,它可以帮助用户快速捕捉屏幕上的任何内容,并将其编辑、标注和共享。 Snagit mac软件特点
多种截图模式:支持全屏截图、窗口截图、区域截图、延时截图等多种截图模式,满足不同用户的需求。…

Spark数据倾斜优化
1 数据倾斜现象 1、现象 绝大多数task任务运行速度很快,但是就是有那么几个task任务运行极其缓慢,慢慢的可能就接着报内存溢出的问题。 2、原因 数据倾斜一般是发生在shuffle类的算子,比如distinct、groupByKey、reduceByKey、aggregateByKey…

opencv车牌识别<一>
目录 一、概述
二、ANPR简介 一、概述 本文将介绍创建自动车牌识别(Automatic Number Plate Recognition,ANPR)所需的步骤。对于不同的情形,实现自动车牌识别会用不同的方法和技术,例如,IR 摄像机、固定汽车位置、光照条件等…

模拟接口数据之使用Fetch方法实现
文章目录 前言一、package.json配置mock执行脚本二、封装接口,区分走ajax还是fetch三、创建mock目录,及相关接口文件四、定义接口五、使用mock数据使用模拟数据优化fetch返回数据 六、不使用模拟数据七、对比其他需要使用依赖相关配置如有启发࿰…
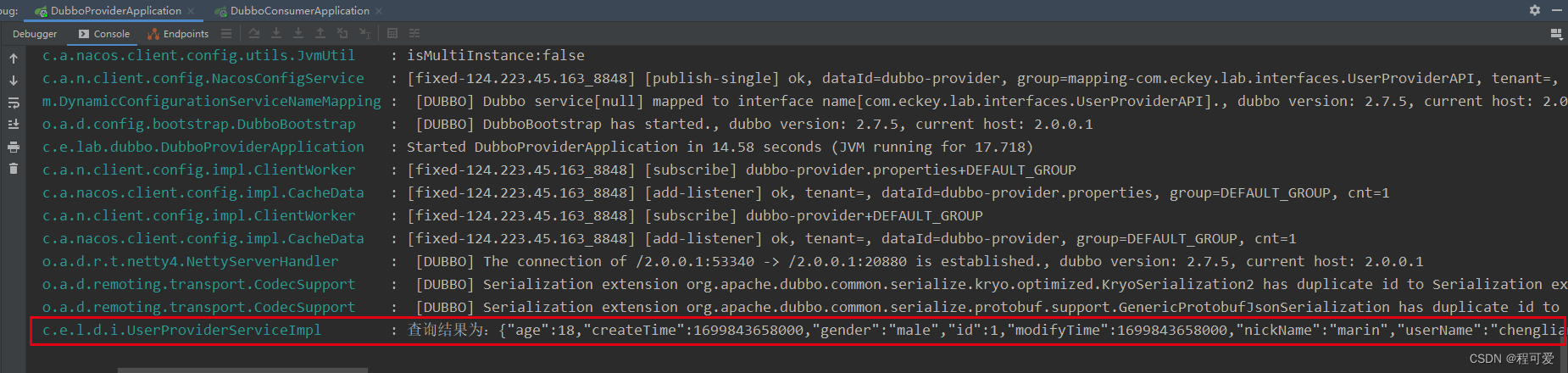
SpringBoot整合Dubbo和Nacos
1.概述
dubbo是一个高性能、轻量级的开源分布式服务框架,早期由阿里巴巴进行开源。它提供了服务注册、发现、调用和负载均衡等分布式服务治理功能,为分布式开发提供了极大便利。dubbo核心概念包括:Provider(消费提供者࿰…

代驾预约小程序系统源码 :提起预约,避免排队 带完整搭建教程
大家好啊,又到罗峰来给大家分享好用的源码系统的时间了。今天要给大家分享的第一款代驾预约小程序源码系统。传统的代驾服务中,用户往往需要在酒后代驾、长途驾驶等场景下,面对排队等待代驾司机空闲时间的繁琐过程。这不仅浪费了用户的时间和…

Centos7安装mysql8.0.35(亲测)
今天在centos7上安装了mysql8,特此记录以作备忘。 说明: - 我安装的mysql版本:8.0.35 - centos版本:7 - 我的虚拟机没安装过mysql,如果之前安装过mysql记得卸载干净 - 卸载步骤: - rpm -qa|grep mysql (搜索mysql)比如…

uniapp——项目day04
购物车页面——商品列表区域
渲染购物车商品列表的标题区域
1. 定义如下的 UI 结构: 2.美化样式 渲染商品列表区域的基本结构
1. 通过 mapState 辅助函数,将 Store 中的 cart 数组映射到当前页面中使用: import badgeMix from /mixins/tab…

sqli-labs关卡16(基于post提交的双引号加括号闭合的布尔盲注)通关思路
文章目录 前言一、回顾上一关知识点二、靶场第十六关通关思路1、判断注入点2、猜数据库长度3、猜数据库名字4、猜表名长度5、猜表名名字6、猜列名长度7、猜列名名字8、猜数据长度9、猜数据名字 总结 前言
此文章只用于学习和反思巩固sql注入知识,禁止用于做非法攻击…
多机器人群体的任务状态与机器人状态同步设计思路
背景技术 近年来,随着科学技术的发展需要,机器人技术不断进步。面临任务的日益复杂化,单机器人在很多环境下已经无法满足生产要求,于是国内外科研工作者对多机器人技术投入了大量关注,提出了利用多机器人协作来代替单机…

【LLMs】从大语言模型到表征再到知识图谱
从大语言模型到表征再到知识图谱 InstructGLMLLM如何学习拓扑?构建InstructGLM泛化InstructGLM补充参考资料 2023年8月14日,张永峰等人的论文《Natural Language is All a Graph Needs》登上arXiv街头,轰动一时!本论文概述了一个名…
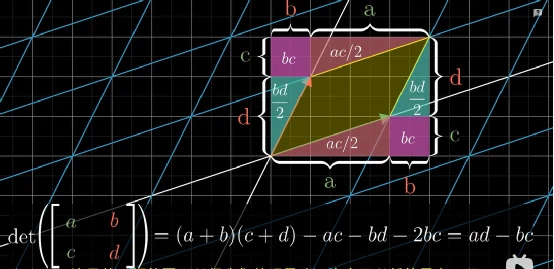
线性代数本质系列(二)矩阵乘法与复合线性变换,行列式,三维空间线性变换
本系列文章将从下面不同角度解析线性代数的本质,本文是本系列第二篇
向量究竟是什么? 向量的线性组合,基与线性相关 矩阵与线性相关 矩阵乘法与复合线性变换 三维空间中的线性变换 行列式 逆矩阵,列空间,秩与零空间 克…

BEVFormer 论文阅读
论文链接
BEVFormer BEVFormer,这是一个将Transformer和时间结构应用于自动驾驶的范式,用于从多相机输入中生成鸟瞰(BEV)特征利用查询来查找空间/时间,并相应地聚合时空信息,从而为感知任务提供更强的表示…

AI 绘画 | Stable Diffusion精确控制ControlNet扩展插件
ControlNet ControlNet是一个用于控制AI图像生成的插件,通过使用Conditional Generative Adversarial Networks(条件生成对抗网络)的技术来生成图像。它允许用户对生成的图像进行更精细的控制,从而在许多应用场景中非常有用&#…

工业数据的“最后一公里”怎么走?
随着工业互联网的迅猛发展,工业数据已经成为推动制造业转型升级的重要动力。然而,面对海量的工业数据,如何高效、准确地走过数据的“最后一公里”,成为制约企业发展的关键问题。本文将探讨工业数据“最后一公里”所面临的挑战&…
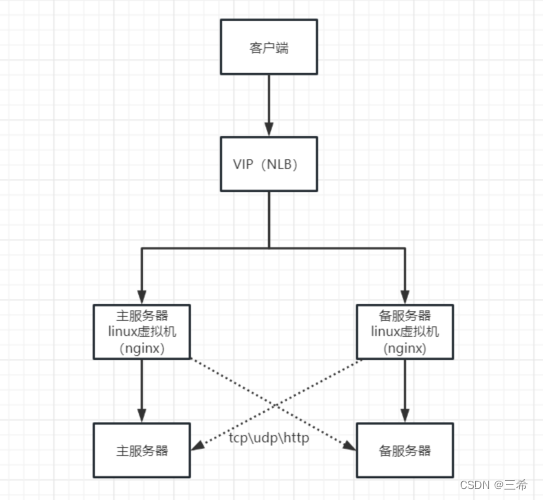
nginx四层tcp负载均衡及主备、四层udp负载均衡及主备、7层http负载均衡及主备配置(wndows系统主备、负载均衡)
准备工作
服务器上安装、配置网络负载平衡管理器
windows服务器热备、负载均衡配置-CSDN博客
在windows服务器上安装vmware17 在windows上利用vmware17 搭建centos7 mini版本服务器 设置好静态ip地址(因为windows 服务器上的网络负载平衡管理器不支持dhcp的服务器…
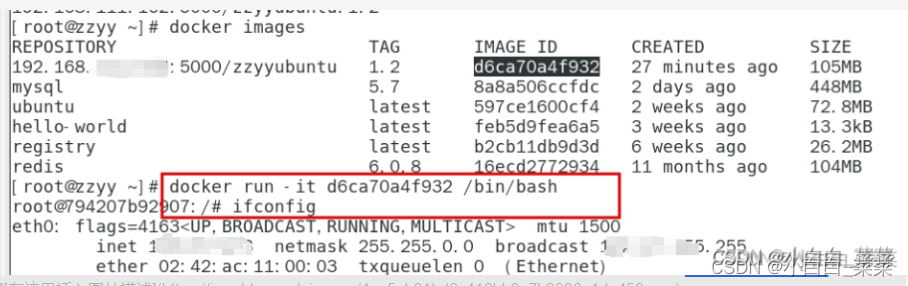
Docker的本地镜像发布到阿里云或者私有库步骤
学习笔记来源Docker
本地镜像发布到阿里云
1、生成镜像(使用commit命令) 创建阿里云仓库镜像
阿里云开发者平台 https://promotion.aliyun.com/ntms/act/kubernetes.html
创建仓库镜像 选择控制台,进入容器镜像服务 选择个人实例 命名空…


雅虎、美客多、Temu、Allegro、亚马逊跨境平台选品技巧方法,测评养号攻略。
(1) Best Sellers选品法
这个方法顾名思义,就是大家熟悉的热销榜单选品法。
不做过多解释,在自己熟悉的品类,隔几天就会观察一下前100名里有没有冒出什么新品。
它和现有的产品相同还是不同,自己做哪些搭配或者迭代…
asp.net core mvc之模型绑定、特性约束模型绑定、模型验证(服务器/客户端/远程)
一、不用模型绑定
数据类型都是string
1、UserController.cs
public class UserController : Controller
{public IActionResult Register(){return View();}[HttpPost]public IActionResult DoRegister(){//不用模型绑定 以前的方法取表单数据或Url的参数//数据类型都是s…
推荐文章
- css的优先级排序?
- Kubernetes的演变:从etcd到分布式SQL的过渡
- # ChatGpt: 从语言模型到智能语音助手的进化之路
- # notepad++ 编辑器英文版,如何打开自动换行
- # 利刃出鞘_Tomcat 核心原理解析(三)
- #Css篇:实现一个元素水平和垂直居中实现左右固定,中间自身适应布局 左侧固定 右侧自适应
- #基于一个小车项目的FREERTOS分析(一)系统时钟
- $.ajax #fm,【图片】95范加尔Ajax的荣光,95Ajax战术在FM的复刻。战术以及思想讨论【fm2017吧】_百度贴吧...
- (14)关于docker如何通过防火墙做策略限制
- (BERT蒸馏)TinyBERT: Distilling BERT for Natural Language Understanding
- (Linux驱动学习 - 8).信号异步通知
- (排序) 剑指 Offer 21. 调整数组顺序使奇数位于偶数前面 ——【Leetcode每日一题】