前言
爬虫(英文:spider),可以理解为简单的机器人,如此一个“不为名利而活,只为数据而生,目标单纯,能量充沛,不怕日晒雨淋,不惧寒冬酷暑”的家伙,真讨人喜欢~

在博主的历史文章中,已对爬虫的原理机制、实践操作做了基本的介绍。
如感兴趣,可直接拖到文末,双击666~
今天我们从爬虫日常中使用的工具,进行简单介绍,希望各位盆友有所收获。
一、网站分析
| 网站类型 | 网站特点 |
|---|---|
| 动态网站 | 数据通过一定的前端框架封装输出,且必须经过后台API获得 |
| 静态网站 | 数据静态填充,所见即所得 |
我们通常遇到的数据源网站,不外乎以上两类,要么静态网页,要么动态网页。当然从爬虫的角度,静态有静态的处理方式,动态有动态的处理方式。
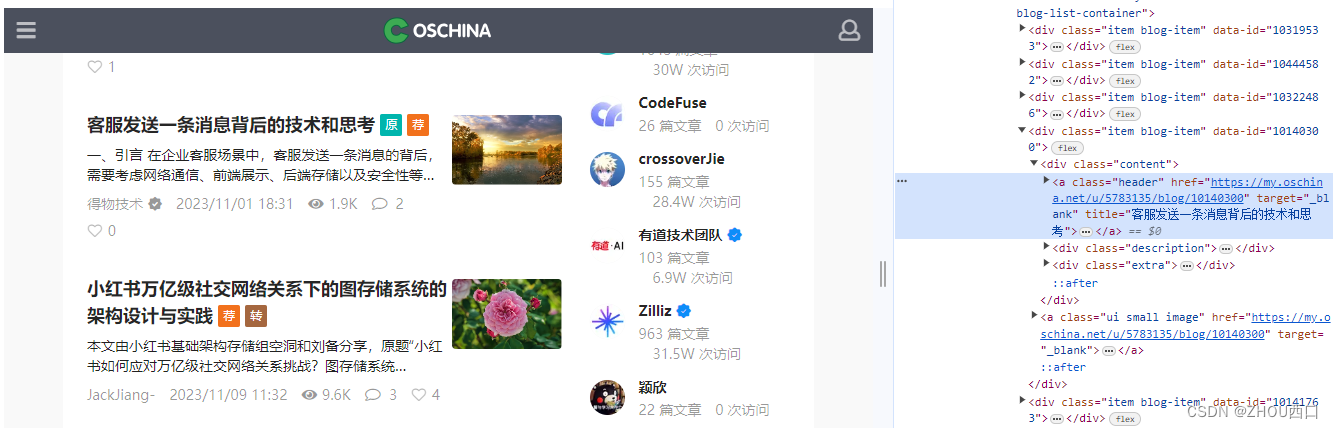
这里,举个栗子。以开源中国-博客为例,https://www.oschina.net/blog/recommend,这就是纯静态网站,可以直接进行数据获取。
二、数据抓包
对网站进行初步分析后,即可发起数据抓包了。此刻,可能有些同学不懂了,什么是抓包呀?
抓包(packet capture)就是将网络传输发送与接收的数据包进行截获、重发、编辑、转存等操作,也用来检查网络安全。抓包也经常被用来进行数据截取等。——百度百科
简单一句话:作为程序员,如果不会抓包,就去钻研一下吧。抓包工具主要有:
| 工具名称 | 工具简介 |
|---|---|
| 浏览器 | 作为互联网的窗口,浏览器是最简单也是最直接的抓包工具,比如FF/Chrome |
| Fiddler | Fiddler是一个http协议调试代理工具,它能够记录并检查访问互联网之间的http通讯 |
| Postman | Postman是一款功能超级强大的用于发送 HTTP 请求的工具,开适用于开发/测试 |
| HttpWatch | HttpWatch是一个可用于录制HTTP请求信息的工具,由Simtec Limited公司开发 |
| Wireshark | Wireshark是非常流行的网络封包分析软件,可以截取各种网络数据包 |
以上工具,各有特色,也有各自适用的环境,各位盆友可自由选之。
三、数据解析
通过前两步准备后,即可进行数据解析和结构化处理。而通常使用的工具也不少,博主重点介绍几个。
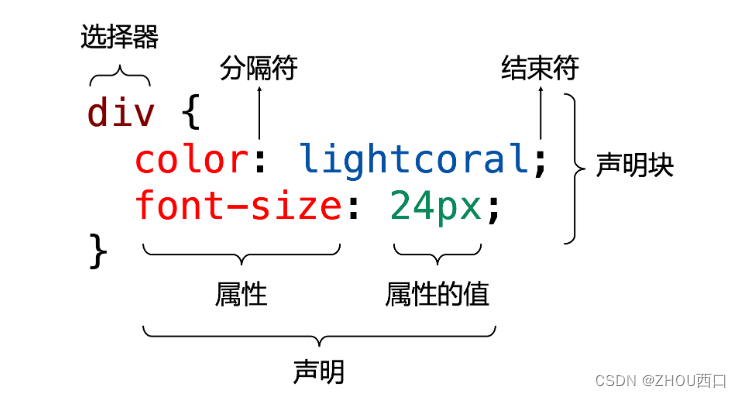
1. Css selector
css 选择器,可划分为基本选择器、关系选择器、伪选择器三种类型不同的选择器。这是CSS开发的基础语法和规范。
2. Jsoup
Jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
这是一个来自官网的示例:通过设置select实现对document的遍历。
Document doc = Jsoup.connect("https://en.wikipedia.org/").get();
log(doc.title());
Elements newsHeadlines = doc.select("#mp-itn b a");
for (Element headline : newsHeadlines) {log("%s\n\t%s", headline.attr("title"), headline.absUrl("href"));
}
3. Xpath
XPath 表示 XML 路径语言。它使用非 XML 语法来提供一种灵活地定位(指向)XML 文档的不同部分的方法。
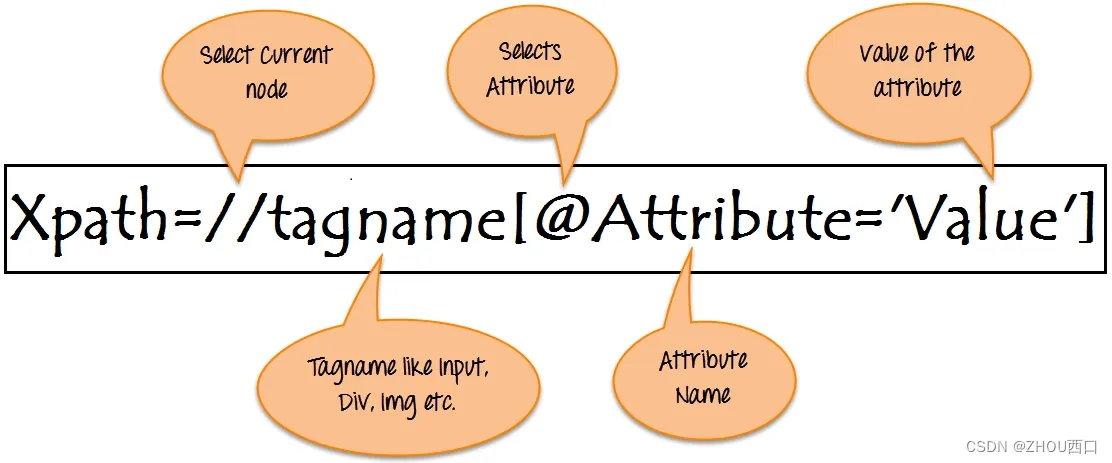
目前主流浏览器均已集成xpath插件,可快速定位所需的节点。
结语
一个优质的爬虫,从不拒绝贪婪,也不会肆无忌惮。虽然我们通过以上工具可以基本完成所需的数据抓取,但道亦有道,也需以“礼”服人。拒绝滥用爬虫,拒绝暴力破解~
精彩回顾
一文图解爬虫(spider)
一文图解爬虫_姊妹篇(spider)