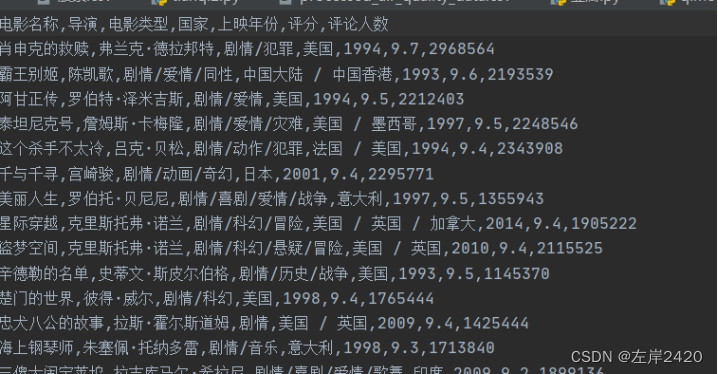
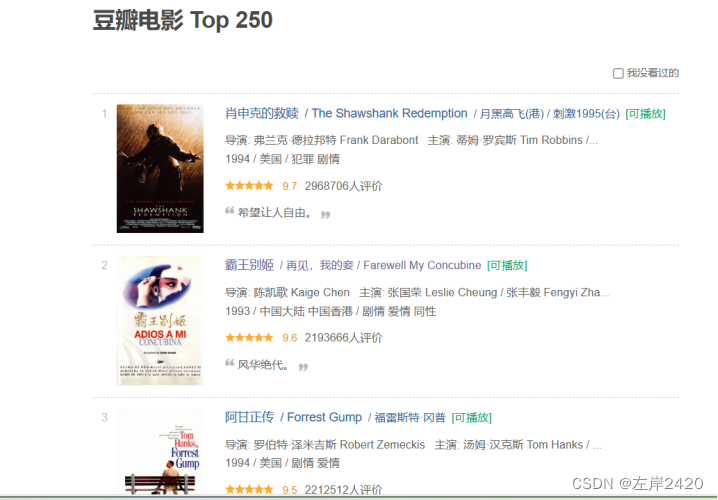
一:爬虫1、爬取的目标将豆瓣电影网上的电影的基本信息,比如:电影名称、导演、电影类型、国家、上映年份、评分、评论人数爬取出来,并将爬取的结果放入csv文件中,方便存储。 2、网站结构 图1豆瓣网网站结构详情 此次实验爬取豆瓣网中电影页面中的电影的基本信息。 每一个电影包括电影名称、导演、电影类型、国家、上映年份、评分、评论人数。页面具体情况如图2所示。
图2豆瓣网电影基本信息详情 3、爬虫技术方案1)、所用技术: 网站解析的使用的是Xpath、数据存储使用的是csv。 2)、爬取步骤: 1、导入所需的库,如re、time、requests、lxml、random和csv。 2、定义一个名为main的函数,该函数接受两个参数:page(页码)和f(文件对象)。 3、在main函数中,构造请求URL,设置请求头,并发送GET请求以获取网页内容。 4、使用lxml库解析网页内容,提取电影详情页的链接列表和电影名称列表。 5、遍历链接列表和名称列表,对于每个链接和名称,调用get_info函数来获取电影的详细信息。 6、在get_info函数中,同样构造请求URL,设置请求头,并发送GET请求以获取电影详情页的内容。 7、使用lxml库解析电影详情页的内容,提取导演、电影类型、国家、上映时间、评分和评论人数等信息。 8、打印提取到的信息,并将其写入CSV文件中。 9、在主程序中,创建一个CSV文件,并写入表头标题。 10、使用for循环遍历10个页面,调用main函数来爬取每一页的电影信息。 11、在每次循环之间,让程序休息一段时间,以避免过于频繁的请求导致IP被封禁。 4、爬取过程:
1)、导入所需要的包
import re:导入正则表达式模块,用于处理字符串。 from time import sleep:从time模块导入sleep函数,用于让程序暂停执行一段时间。 import requests:导入requests模块,用于发送HTTP请求。 from lxml import etree:从lxml模块导入etree函数,用于解析HTML文档。 import random:导入random模块,用于生成随机数。 import csv:导入csv模块,用于操作CSV文件。 2)、设置请求头,定义min函数接收参数,访问连接提取列表
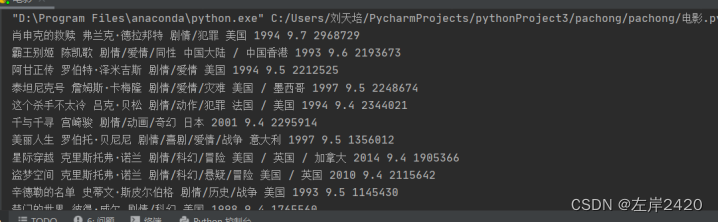
3)、使用正则表达式开始爬取网页信息4)、将爬取结果放入csv文件中5、爬虫结果
 二:预处理1、删除列
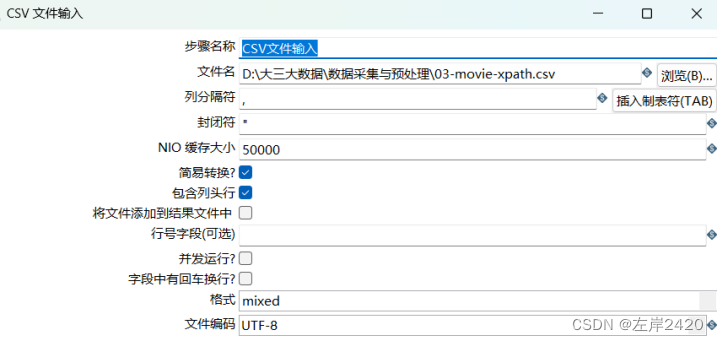
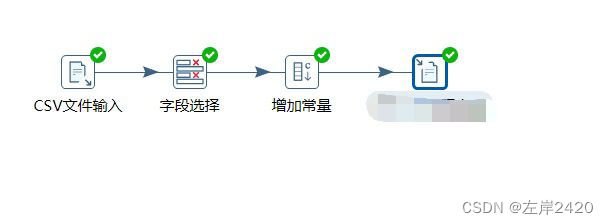
1)、新建转换,之后使用文件输入,将csv文件输入进行处理
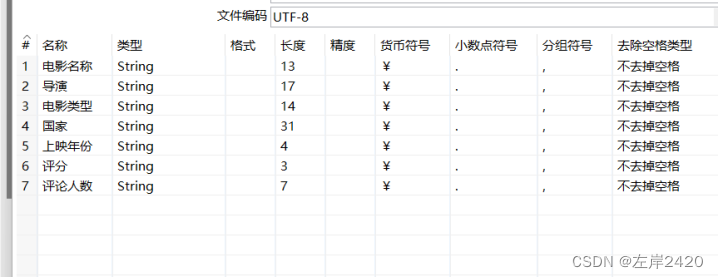
之后进行字段获取。
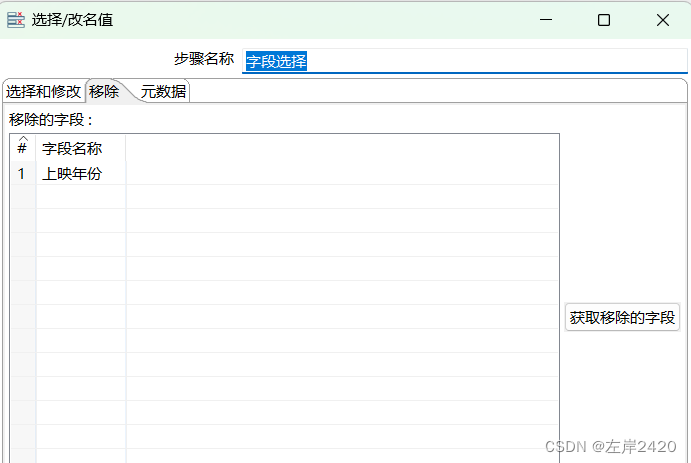
2)、选择转换中的字段选择进行列删除,将上映时间这个列进行删除。
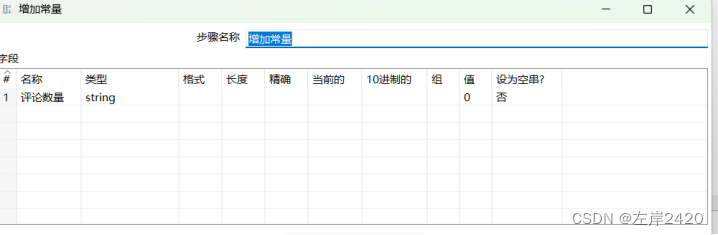
2、选择转换中的增加常量,增加评论数量这一列,查询电影评论的数量这一情况。
4、预处理完全处理全流程:
三:爬虫数据源代码代码: |
基于爬虫和Kettle的豆瓣电影的采集与预处理
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/239272.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
Parallel patterns: convolution —— An introduction to stencil computation
在接下来的几章中,我们将讨论一组重要的并行计算模式。这些模式是许多并行应用中出现的广泛并行算法的基础。我们将从卷积开始,这是一种流行的阵列操作,以各种形式用于信号处理、数字记录、图像处理、视频处理和计算机视觉。在这些应用领域&a…
尚硅谷离线数仓之采集平台
1. 用户行为日志
数据流向流程图如下,其中红框表示用户行为日志数据的流向图。
1.1 行为日志内容
行为日志主要包括以下几个内容
页面浏览记录动作记录曝光记录启动记录错误记录 页面浏览记录 动作记录 曝光记录 启动记录 1.2 用户行为日志格式
页面日志启动…
Radzen Blazor Studio 脚手架框架解读
背景
组织管理管理准备使用Blazor这个工具实现,因为其有对应的 scaffold 脚手架,先构建数据库,然后通过向导,生成CRUD以及对应的接口,那么有必要看一下,其内部的代码结构是什么样的。
结构 接口层
有两类…

STM32-04-STM32时钟树
STM32时钟树 什么是时钟? 时钟是具有周期性的脉冲信号,最常用的是占空比50%的方波。(时钟是单片机的脉搏,搞懂时钟走向及关系,对单片机使用至关重要)。 时钟树 时钟源 2个外部时钟源 高速外部振荡器(HSE…
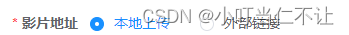
vue中el-radio无法默认选中
页面上不生效,默认什么都不选中
<el-radio-group v-model"queryParams.videoUrlType"><el-radio :label"1">本地上传</el-radio><el-radio :label"2">外部链接</el-radio>
</el-radio-group>da…
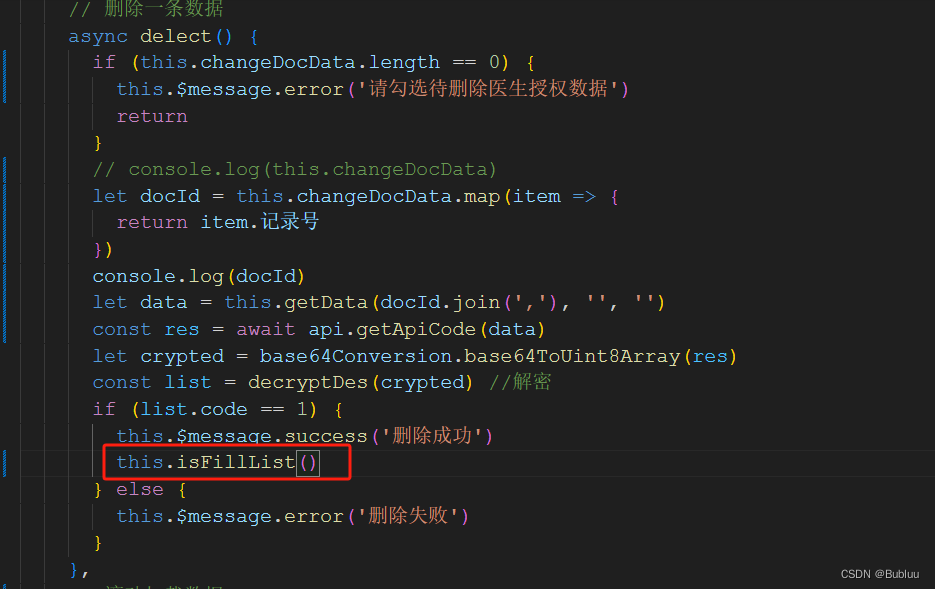
vue el-table最后一页所有数据批量删除或者单个删除,自动回到上一页,包括单条删除
批量删除单条删除//判断数据是否可以满一页isFillList () {const totalPage Math.ceil((this.docDateTotal - this.changeDocData.length) / this.docPageSize) // 总页数this.docPage this.docPage > totalPage ? totalPage : this.docPagethis.docPage this.docPage &…

高级 Python 面试问题与解答
文章目录 专栏导读1.什么是PIP?2.什么是 zip 函数?3.Python 中的 __init __ () 是什么?4.Python 中的访问说明符是什么?5.Python 中的单元测试是什么?6.Python全局解释器锁(GIL)?7.P…

docker-consul部署
目录 一、环境
二、consul服务器
三、registrator服务器
四、consul-template 一、环境
consul服务器 192.168.246.10 运行consul服务、nginx服务、consul-template守护进程 registrator服务器 192.168.246.11 运行registrator容器、运行ngi…
看完这篇你就知道了!人气爆表的6款Sketch插件大揭秘!
Sketch作为一种在线设计工具,一直是许多设计师的最爱。它不仅能快速建立原型,还能提供丰富的插件,以满足不同的需求。
今天,小抄将与大家分享6款流行的Sketch插件供参考。这些插件都是小抄精心挑选的,支持Windows、Ma…
flink1.14.5使用CDH6.3.2的yarn提交作业
使用CDH6.3.2安装了hadoop集群,但是CDH不支持flink的安装,网上有CDH集成flink的文章,大都比较麻烦;但其实我们只需要把flink的作业提交到yarn集群即可,接下来以CDH yarn为基础,flink on yarn模式的配置步骤…

React18-树形菜单-递归
文章目录 案例分析技巧通信展示效果实现代码技巧点技巧点 Refer to 案例分析
https://github.com/dL-hx/manager-fe/commit/85faf3b1ae9a925513583feb02b9a1c87fb462f7 从接口获取城市数据,渲染出一个树形菜单 要求: 可以展开和收起 技巧 学会递归渲染出一个树形菜单, 并点击后…

加密经济学:Web3时代的新经济模型
随着Web3技术的迅猛发展,我们正迈入一个全新的数字经济时代。加密经济学作为这一时代的核心,不仅在数字货币领域崭露头角,更是重新定义了传统经济模型,为我们开启了一个充满创新和机遇的新纪元。 1. 去中心化的经济体系
Web3时代…
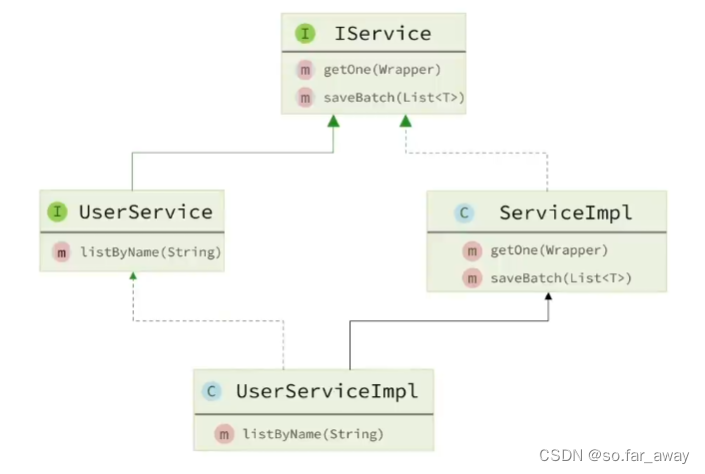
MybatisPlus框架入门级理解
MybatisPlus 快速入门入门案例常见注解常用配置 核心功能条件构造器自定义SQLService接口 快速入门
入门案例
使用MybatisPlus的基本步骤: 1.引入MybatisPlus的起步依赖 MybatisPlus官方提供了starter,其中集成了Mybatis和MybatisPlus的所有功能&#…

接口测试用例设计 - 实战篇
一.接口测试流程
1.需求讨论
2.需求评审
3.场景设计
4.数据准备
5.执行 二.分析接口文档中哪些元素
1.接口名称
2.接口地址
3.支持格式
4࿰…

APM链路监控: Linux 部署 pinpoint
目录
一、实验
1.环境
2. 准备
3.HBase单机部署
4.pinpoint部署
二、问题
1.pinpoint有哪些功能
2.pinpoint架构是如何组成的
3.Linux中自带的jdk 如何设置JAVA_HOME
4. hbase启动报错
5.hbase的master启动失败
6.JPS命令如何安装和使用 一、实验
1.环境
&#x…

IPKISS ------ 远程服务器 IPKISS 内置示例安装问题
IPKISS ------ 远程服务器示例安装问题 引言正文 引言
很多时候,如果我们在服务器上使用管理员权限安装了 IPKISS 证书,而我们使用个人账号登录服务器时有时候会显示如下界面: 我们会看到这个 PyCharm (Luceda Academy) 是灰色的。那么该怎…
eclipse ADT安装及abap cds模版创建
文章目录 1.前提2.安装3.创建cds模版 abap cds 常用语法 https://blog.csdn.net/weixin_49198221/article/details/135531478?spm1001.2014.3001.5501
1.前提
需要了解版本关系:
**1.eclipse:**2023-06 (4.28), 2023-09 (4.29), 2023-12 (4.30)
2.Windows:
1.Windows …

短视频怎么截取gif动画?一个方法教你快速截取gif
电影、电视剧已经是我们日常生活中最常见最普遍的消遣娱乐方式了,当我们看到好看的画面想要截图里面的画面做成gif动画是应该如何制作gif动态图片(https://www.gif.cn/)呢?很简单,通过使用专业的gif在线制作工具&#…

VUE生命周期和生命周期四个阶段
Vue生命周期:一个Vue实例从 创建 到 销毁 的整个过程。 生命周期四个阶段:① 创建 ② 挂载 ③ 更新 ④ 销毁 vue的生命周期如图所示: Vue 生命周期函数(钩子函数):Vue生命周期过程中,会自…

世微AP5160宽电压 LED 降压型恒流芯片14-18V 3A 电源PCB线路
这是一款14-18V 3A 电流的PCB设计方案.
运用的是世微AP5160 电源驱动IC,这是一款效率高,稳定可靠的 LED 灯恒流驱动控制芯片,内置高精度比较器,固定 关断时间控制电路,恒流驱动电路等,特别适合大功率 LED 恒流驱动。 …
推荐文章
- 【项目实战】犬只牵绳智能识别:源码详细解读与部署步骤
- AI + 非遗文化传播,人工智能师资培训重磅招募
- JavaScript 数据类型转换
- # RocketMQ 实战:模拟电商网站场景综合案例(十一)
- # 利刃出鞘_Tomcat 核心原理解析(十)-- Tomcat 性能调优--1
- #[量化投资-学习笔记018]Python+TDengine从零开始搭建量化分析平台-正态分布与收益率
- #与##的用法
- (16)线程的实例认识:Await,Async,ConfigureAwait
- (18)时间序列预测之FiLM
- (c语言)简易计算器
- (JAVA)贪心算法、加权有向图与求得最短路径的基本论述与实现
- (保姆级教学)ADS设计高频微波整流电路之二——版图联合仿真