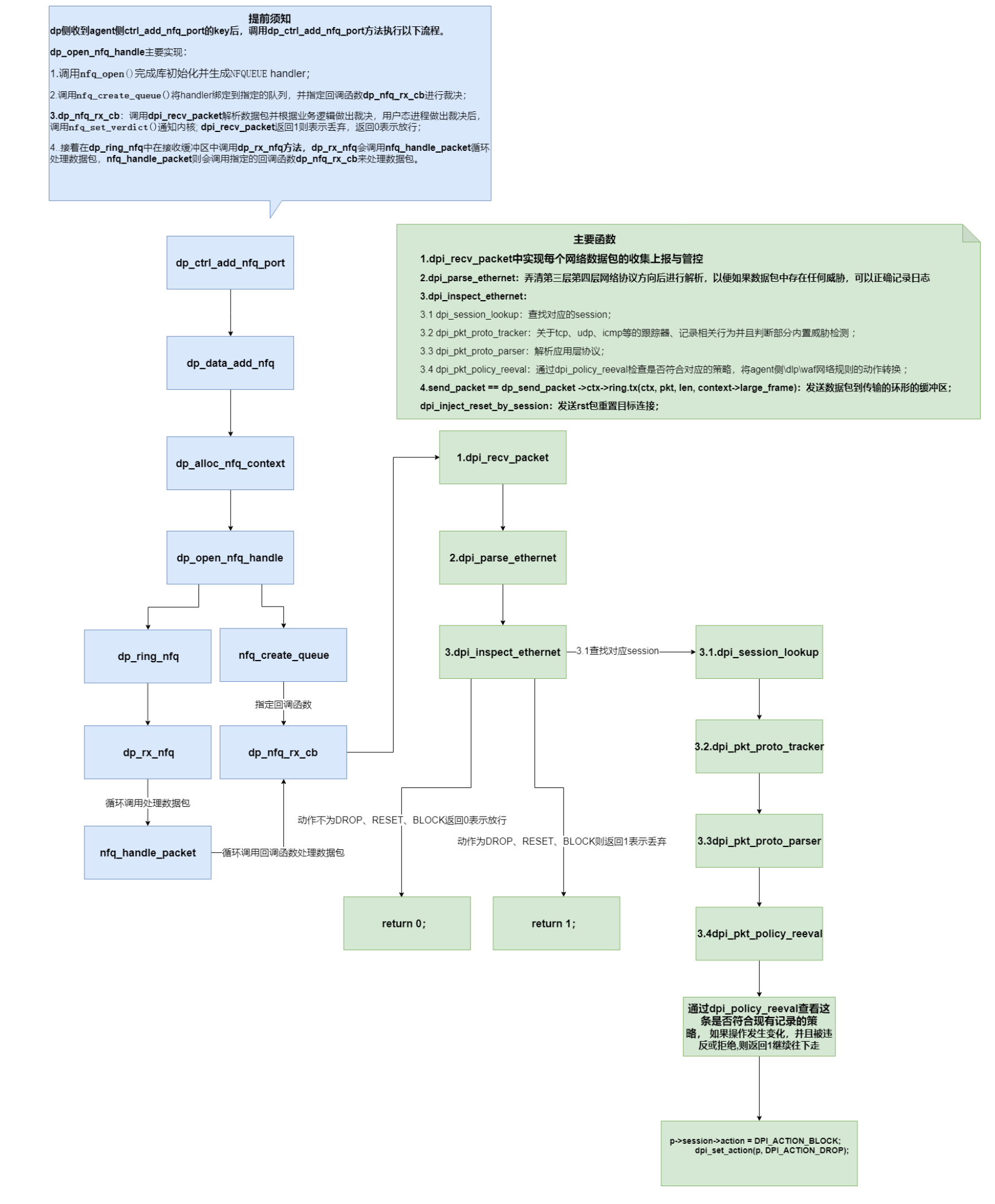
🎉欢迎您来到我的MySQL基础复习专栏
☆* o(≧▽≦)o *☆哈喽~我是小小恶斯法克🍹
✨博客主页:小小恶斯法克的博客
🎈该系列文章专栏:重拾MySQL
🍹文章作者技术和水平很有限,如果文中出现错误,希望大家能指正🙏
📜 感谢大家的关注! ❤️

目录
🚀联合查询
🚀子查询
🚀标量子查询
🚀列子查询
🚀行子查询
🚀表子查询
🚀联合查询
union查询,就是把多次查询的结果合并起来,形成一个新的查询结果集
主要代码:
SELECT 字段列表 FROM 表 A ...UNION [ ALL ]SELECT 字段列表 FROM 表B ;
联合查询的多张表的列数必须保持一致,字段类型也需要保持一致。
union all 会将全部的数据直接合并在一起,并不会去重
union 会对合并之后的数据去重。
案例:将薪资低于 5000 的员工 , 和 年龄大于 50 岁的员工全部查询出来.
思路:
1.直接使用多条件查询,使用逻辑运算符 or 连接
2.通过union/union all来联合查询
select * from empcp where salary < 5000union allselect * from empcp where age > 50; --联合查询的多张表的列数必须保持一致,字段类型也需要保持一致。执行:
第一部分
第二部分

联合(即要薪资低于5000的员工,又要年龄大于50的员工,那么就意味着这两条数据要合并,关键字union all)
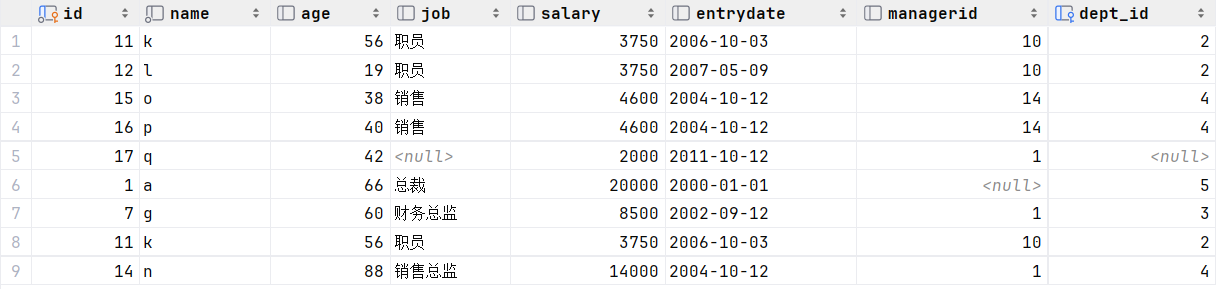
我们发现union all查询出来的结果,有一个员工k是重复的,k的薪资低于5000,年龄又大于50,所以查询了两次,数据直接合并,仅仅进行简单的合并,并未去重。
select * from empcp where salary < 5000unionselect * from empcp where age > 50;
执行:
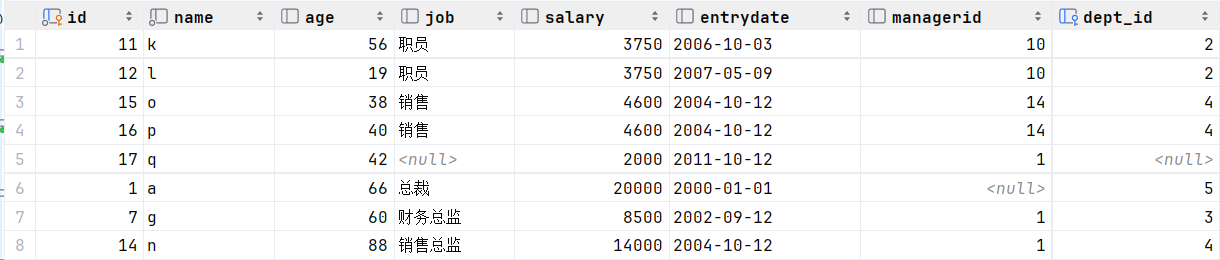
我们发现union联合查询,会对查询出来的结果进行去重处理。
注意:
如果多条查询语句查询出来的结果,字段数量不一致,在进行union/union all联合查询时,将会报错。如:

🚀子查询
SQL语句中嵌套的SELECT语句,称为嵌套查询,又称子查询。
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 ); 注意!子查询外部的语句可以是INSERT / UPDATE / DELETE / SELECT 的任何一个。
此时,子查询因为存在嵌套关系,逻辑性较强,代码是比较变通的,切不可死记硬背,根据逻辑去思考问题
根据子查询结果不同,可分为:
1.标量子查询(子查询结果为单个值)
2.列子查询(子查询结果为一列)
3.行子查询(子查询结果为一行)
4.表子查询(子查询结果为多行多列)
根据子查询位置,可分为:
1.WHERE之后
2.FROM之后
3.SELECT之后
🚀标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。 常用的操作符:= <> > >= < <=
案例:
查询 "销售部" 的所有员工信息
思路:
拆解为两步 (因为在员工表中是没有存储销售部这个部门名称的,仅仅只有部门id)
1.查询"销售部" 部门ID
select id from dept where name = '销售部';2.根据 "销售部" 部门ID, 查询员工信息,用*返回员工所有信息的字段
select * from empcp where dept_id = (select id from dept where name = '销售部'); 或者 select * from empcp where dept_id = 4 ;
执行:
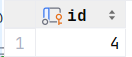
执行:

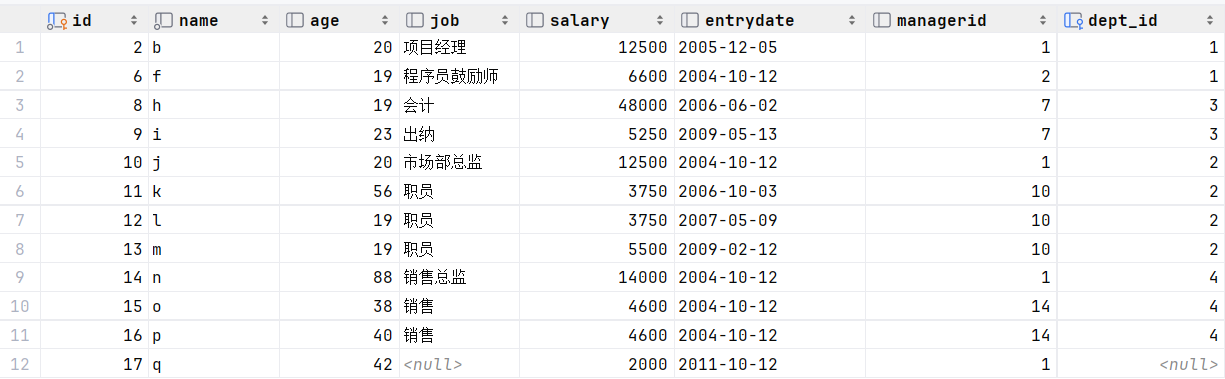
查询在 "e"这个员工 入职之后的员工信息
思路:
拆解为两步
1.查询 e 的入职日期
select entrydate from empcp where name = 'e';2.查询指定入职日期之后入职的员工信息
select * from empcp where entrydate > (select entrydate from empcp where name = 'e'); 或者 select * from empcp where entrydate > 2004-9-7 ;
执行:
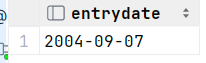
执行:
当然,我们需要了解entrydate是如何比较呢?
在SQL中,
entrydate是一个字段名,通常表示一个日期或日期时间类型的数据。要比较
entrydate字段,你可以使用各种比较运算符,如=、<、>、<=、>=、<>或!=。以下是一些示例,说明如何比较
entrydate字段:1.等于,大于,小于,小于等于,大于等于,不等于就不过多演示了,因为直接更改比较运算符即可
SELECT * FROM your_table WHERE entrydate = '2023-10-23'; -- =可以改为<,>,<>,<=,>=......2.BETWEEN: 如果你想选择一个日期范围内的记录,你可以使用BETWEEN:
SELECT * FROM your_table WHERE entrydate BETWEEN '2023-10-01' AND '2023-10-31';这个查询会返回所有
entrydate在'2023-10-01'和'2023-10-31'之间的记录。注意,BETWEEN运算符是包含边界值的。
3. LIKE 和日期: 如果你想基于日期的部分部分进行比较,例如查找以特定年份开始的日期,你可以使用LIKE:SELECT * FROM your_table WHERE entrydate LIKE '2023%';这个查询会返回所有以'2023'开头的
entrydate的记录。LIKE运算符通常与通配符一起使用,如%表示任何数量的任何字符。
4. DATE() 函数: 如果你只想比较日期部分而忽略时间部分,你可以使用DATE()函数:SELECT * FROM your_table WHERE DATE(entrydate) = '2023-10-23';这个查询只会比较日期部分,忽略时间部分。这对于只关心日期而不关心具体时间的情况很有用。
5. 时间间隔: 如果你想基于两个日期之间的时间间隔进行比较,你可以使用减法:
SELECT * FROM your_table WHERE DATEDIFF(day, entrydate, '2023-10-23') > 5;这个查询会返回所有与'2023-10-23'相差超过5天的
entrydate的记录。DATEDIFF()函数根据指定的时间间隔返回两个日期之间的差异。在这个例子中,我们使用天作为时间间隔单位。不同的数据库系统可能有不同的函数来计算日期差异,所以请根据你使用的系统查阅相应的文档。
🚀列子查询
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询
常用的操作符:IN 、NOT IN 、 ANY 、SOME 、 ALL
| 操作符 | 描述 |
| IN | 在指定的集合范围之内,多选一 |
| NOT IN | 不在指定的集合范围之内 |
| ANY | 子查询返回列表中,有任意一个满足即可 |
| SOME | 与ANY等同,使用SOME的地方都可以使用ANY |
| ALL | 子查询返回列表的所有值都必须满足 |
案例:
查询 "销售部" 和 "市场部" 的所有员工信息
思路:
分解为两步
1.查询 "销售部" 和 "市场部" 的部门ID
select id from dept where name = '销售部' or name = '市场部';2.根据部门ID, 查询员工信息 (由于是两个元素,所以用到了in)
select * from empcp where dept_id in (select id from dept where name = '销售部' or name = '市场部'); 或者 select * from empcp where dept_id in(2,4) --2.4是上述语句查询的结果,所以我们可以把2,4替换掉,让上面的语句作为子查询存在
而由于内部的sql查询出来不再是一个单个值了,而是一列,多行。所以这种子查询称为列子查询
执行:

执行:

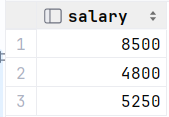
查询比 财务部 所有人工资都高的员工信息
思路:
分解为以下两步
1.查询所有 财务部 人员工资
select id from dept where name = '财务部'; select salary from empcp where dept_id = (select id from dept where name = '财务部'); 或者 select salary from empcp where dept_id = 3;2.比 财务部 所有人工资都高的员工信息 (这个salary要大于这三个工资的所有值,比其中任何一个大,此时就要大于这个列表中所有值,要加上all)
select * from empcp where salary > all ( select salary from empcp where dept_id =(select id from dept where name = '财务部') );
执行:
执行:

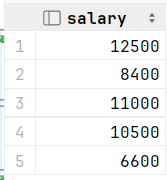
查询比 研发部 其中任意一人工资高的员工信息
思路:
分解为两步
1.查询研发部所有人工资
select salary from empcp where dept_id = (select id from dept where name = '研发部');2.比研发部其中任意一人工资高的员工信息 (关键字any)
select * from empcp where salary > any ( select salary from empcp where dept_id =(select id from dept where name = '研发部') );
执行:
执行:
🚀行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
常用的操作符:= 、<> 、IN 、NOT IN
案例:
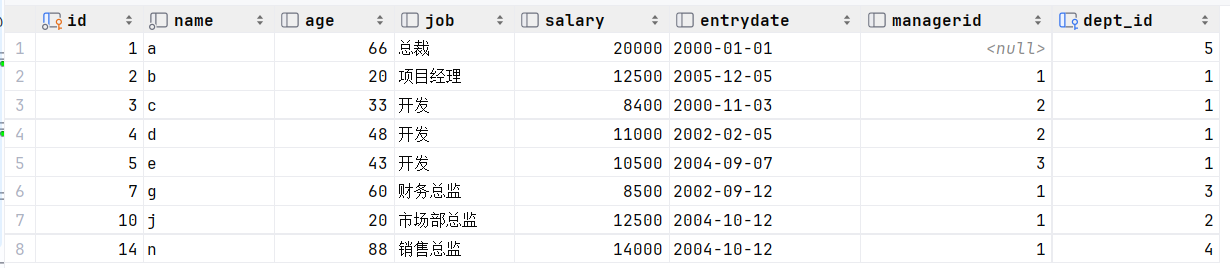
查询与 "b" 的薪资及直属领导相同的员工信息 ;
思路:行子查询一般来说,左边要给组合条件,右边再给子查询的结果,不能把条件分开,再给子查询结果
拆解为两步:
1.查询 "b" 的薪资及直属领导
select salary, managerid from empcp where name = 'b';2.查询与 "b" 的薪资及直属领导相同的员工信息 ;
第三个代码就是使用salary和managerid作为了一个组合条件,然后这个组合条件等于一个组合值
select * from empcp where (salary,managerid) = (select salary, managerid from empcpwhere name = 'b');或者select * from empcp where salary = 12500 and managerid = 1 ;或者select * from empcp where (salary , managerid) = (12500 ,1) ;
执行:

执行:

🚀表子查询
子查询返回的结果是多行多列,这种子查询称为表子查询。(子查询查询返回的结果就类似于一张表)
常用的操作符:IN
表子查询经常在from之后,把表子查询返回的结果作为一张临时表,再和其他表联查操作
案例:1.查询与 "k" , "p" 的职位和薪资相同的员工信息
拆解为两步:
1.查询与 "k" , "p" 的职位和薪资
select job, salary from empcp where name = 'k' or name = 'p';2.查询与 "k" , "p" 的职位和薪资相同的员工信息 (注意,这里where之后给的是组合条件。如果where之后条件如果是单行,那么我们之前在这一块的写法是(job,salary)= 子查询的结果就ok了,但是现在查询的不是一个单行数据,而是一个多行数据吗,此时就不能等于了,这时候我们要使用的是in)
3.解读,这一块的含义指的是job和salary这个组合要么满足上面的,要么满足下面的,在这个列表里面多选一,只要能够满足一个这个员工的数据就可以查询出来
select * from empcp where (job,salary) in ( select job, salary from empcp where name ='k' or name = 'p' );
执行:
执行:

查询入职日期是 "2006-01-01" 之后的员工信息 , 及其部门信息
思路:
分解为两步
1.入职日期是 "2006-01-01" 之后的员工信息
select * from empcp where entrydate > '2006-01-01';2.查询这部分员工, 对应的部门信息;
3.要查询部门的相关信息就要再去联查另一个表,dept表
4.所以我们需要把第一次查询的结果作为一张表,再去联查dept表
✨先暂时写为*
select * from [刚刚查询的一个结果作为一张表放进来,子查询的结果作为一张临时表存在,取一个别名e] ;
select * from (select * from empcp where entrydate > '2006-01-01') e ;
✨接着查询部门信息,有一个员工q,id为17的没有部门信息,我们要不要查出来,也需要,所以要查全部数据我们要使用到左外连接,此时我们顺便把dept表取名为d
select * from (select * from empcp where entrydate > '2006-01-01') e left join dept d on e.dept_id = d.id ;
执行:
✨总结:此时我们就在from之后用到了子查询,它会把这个子查询的结果作为一张表来与另一张表做
select e.*, d.* from (select * from empcp where entrydate > '2006-01-01') e leftjoin dept d on e.dept_id = d.id ;或者select * from (select * from empcp where entrydate > '2006-01-01') e left join dept don e.dept_id = d.id ;

执行:

执行:

总结:本篇博客到这里就结束了,希望能帮到你,谢谢你这么好看还来看我