文章目录
- 概述
- 语音识别原理公式
- 语音识别术语:
- 分帧
- 提取声学特征
- 声学模型
概述
语音识别传统方法主要分两个阶段:训练和识别,训练阶段主要是生成声学模型和语言模型给识别阶段用。传统方法主要有五大模块组成,分别是特征提取(得到每帧的特征向量),声学模型(用GMM从帧的特征向量得到状态,再用HMM从状态得到音素)、发音字典(从音素得到单词)、语言模型(从单词得到句子)、搜索解码(根据声学模型、发音字典和语言模型得到最佳文本输出),即从帧得到特征向量(特征提取干的话),从特征向量得到状态(GMM干的话),从状态得到音素(HMM干的话),从音素得到单词(发音字典干的活),从单词得到句子(语言模型干的活)
语音识别原理公式
arg max w ⃗ p ( w ⃗ ∣ x ⃗ ) = arg max w ⃗ ∑ q ⃗ p ( w ⃗ , q ⃗ ∣ x ⃗ ) = arg max w ⃗ ∑ q ⃗ p ( x ⃗ ∣ w ⃗ , q ⃗ ) p ( w ⃗ , q ⃗ ) p ( x ⃗ ) = arg max w ⃗ ∑ q ⃗ p ( x ⃗ ∣ q ⃗ ) p ( q ⃗ ∣ w ⃗ ) p ( w ⃗ ) \begin{aligned} \arg \max_{\vec{w}} p(\vec{w}|\vec{x}) &=\arg \max_{\vec{w}} \sum_{\vec{q}}p(\vec{w},\vec{q}|\vec{x}) \\ &=\arg \max_{\vec{w}}\sum_{\vec{q}} \frac{p(\vec{x}|\vec{w},\vec{q})p(\vec{w},\vec{q})}{p(\vec{x})} \\ &=\arg \max_{\vec{w}}\sum_{\vec{q}}p(\vec{x}|\vec{q})p(\vec{q}|\vec{w})p(\vec{w}) \end{aligned} argwmaxp(w∣x)=argwmaxq∑p(w,q∣x)=argwmaxq∑p(x)p(x∣w,q)p(w,q)=argwmaxq∑p(x∣q)p(q∣w)p(w)
x ⃗ \vec{x} x:输入的语音的特征
w ⃗ \vec{w} w:输出的词序列
q ⃗ \vec{q} q:音素序列
p ( x ⃗ ∣ q ⃗ ) p(\vec{x}|\vec{q}) p(x∣q):声学模型
p ( q ⃗ ∣ w ⃗ ) p(\vec{q}|\vec{w}) p(q∣w):发音词典。发音词典就是定义每个词由哪些音素组成
p ( w ⃗ ) p(\vec{w}) p(w):语言模型。语言模型一般利用链式法则,把一个句子的概率拆解成其中每个词的概率之积。
省略分母是因为我们要优化的是 w w w,而 p ( x ) p(x) p(x)不含 w w w,是常数。
语音识别术语:
-
什么是声学模型?
声学模型其实就是可以识别单个音素的模型(例如:音素a的模型可以判定一小段语音是否是a); -
什么是语言模型?
语言模型表示一个个词串(如果结合了词典,就可以成为一个个音素串)它们在语料库中出现的概率大小(比如,不合语法的词串(句子)概率接近0,很合乎语法的词串概率大); -
什么是解码器
解码器就是基于Viterbi算法在HMM模型上搜索生成给定观测值序列(待识别语音的声学特征)概率最大的HMM状态序列,再由HMM状态序列获取对应的词序列,得到结果结果。
如果你只做单个音素识别,(语音很短,内容只是音素),那么只用声学模型就可以做到,不用语言模型。做法就是在每个音素的声学模型上使用解码器做解码(简单的Viterbi算法即可)。
但是,通常是要识别一个比较长的语音,这段语音中包含了很多词。这就需要把所有可能的词串,结合词典展开为音素串,再跟音素的声学模型结合,可以得到解码图(实际上可以看成很多很多HMM模型连接而成),然后在这个解码图上实施Viterbi算法,得到最佳序列,进而得到识别结果。 -
什么是音素
音素:单词的发音由音素构成。对英语,一种常用的音素集是卡内基梅隆大学的一套由39个音素构成的音素集,参见The CMU Pronouncing Dictionary。汉语一般直接用全部声母和韵母作为音素集,另外汉语识别还分有调无调,不详述。 -
什么是状态
状态:这里理解成比音素更细致的语音单位就行啦。通常把一个音素划分成3个状态。 -
声学模型如何训练:
1.数据准备:音频以及对应标注
2.先对数据进行强对齐,去除一些音频和对应标注完全不符的情况,这里需要准备发音词典和音素等资源文件
分帧
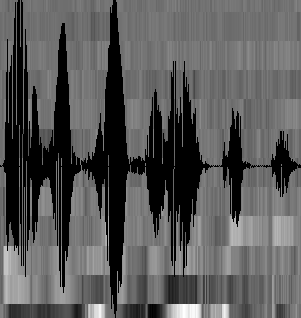
声音实际上是一种波,把波形切开成一小段一小段,每小段称为一帧。帧与帧之间有重叠,就像下图这样:
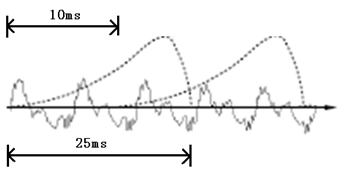
另外还需要做个 VAD 处理,也就是把首尾端的静音切除,降低对后续步骤造成的干扰。这需要用到信号处理的一些技术。
提取声学特征
分帧后,语音就变成了很多小段。但波形在时域上几乎没有描述能力,因此必须将波形作变换。常见的一种变换方法是提取 MFCC 特征,把每一帧波形变成一个 12 维向量。这 12 个点是根据人耳的生理特性提取的,可以理解为这 12 个点包含了这帧语音的内容信息。这个过程叫做声学特征提取。实际应用中,这一步有很多细节,比如差分、均值方差规整、高斯化、降维去冗余等,声学特征还有fbank等。
https://www.jianshu.com/p/06895b38738c
https://www.cnblogs.com/yifanrensheng/p/13510742.html
至此,声音就成了一个 12 行(假设声学特征是 12 维)、N 列的一个矩阵,称之为观察序列,这里 N 为总帧数。观察序列如下图所示,图中,每一帧都用一个 12 维的向量表示,色块的颜色深浅表示向量值的大小。
Fbank:FilterBank:人耳对声音频谱的响应是非线性的,Fbank就是一种前端处理算法,以类似于人耳的方式对音频进行处理,可以提高语音识别的性能。获得语音信号的fbank特征的一般步骤是:预加重、分帧、加窗、短时傅里叶变换(STFT)、mel滤波、去均值等。对fbank做离散余弦变换(DCT)即可获得mfcc特征。
声学模型
- 音节:英语中就是单词,汉语中是汉字。
- 音素:音节的发音由音素构成。对英语,通常使用 39 个音素的音素集。
- 状态:比音素更细致的语音单位。通常一个音素由 3 个状态构成。
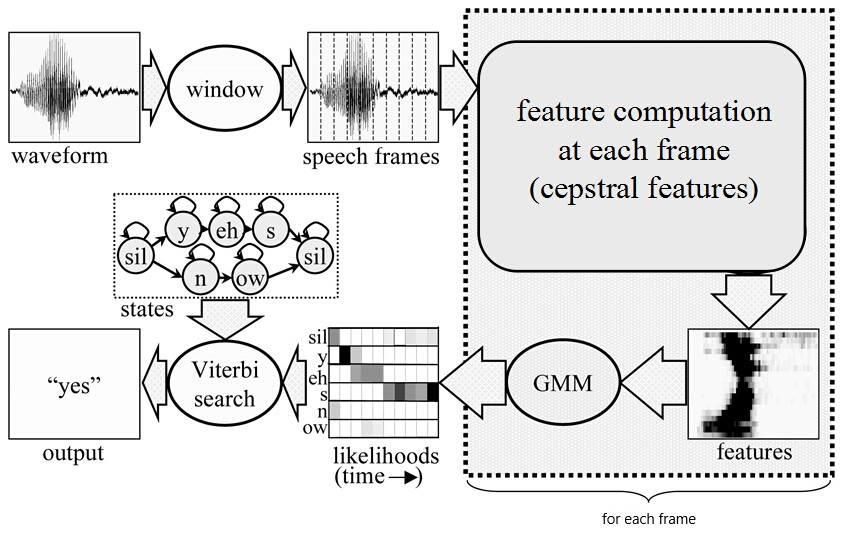
语音识别是怎么工作的呢?
第一步,把帧识别成状态(难点)。(GMM)
第二步,把状态组合成音素。(HMM)
第三步,把音素组合成单词。(发音字典)
如下图所示:
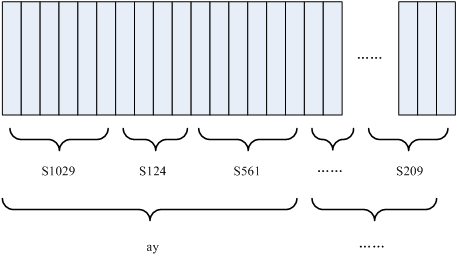
图中,每个小竖条代表一帧,若干帧语音对应一个状态,每三个状态组合成一个音素,若干个音素组合成一个单词。也就是说,只要知道每帧语音对应哪个状态了,语音识别的结果也就出来了。
那每帧音素对应哪个状态呢?有个容易想到的办法,看某帧对应哪个状态的概率最大,那这帧就属于哪个状态,这叫做“最大似然”。比如下面的示意图,这帧对应 S3 状态的概率最大,因此就让这帧属于 S3 状态。
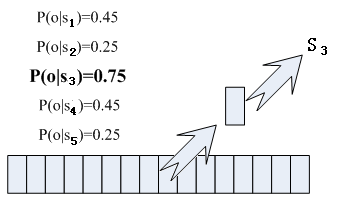
那这些用到的概率从哪里读取呢?有个叫“声学模型”的东西,里面存了一大堆参数,通过这些参数,就可以知道帧和状态对应的概率(GMM)。声学模型是使用巨大数量的语音数据训练出来的。
但这样做有一个问题:每一帧都会得到一个状态号,最后整个语音就会得到一堆乱七八糟的状态号,相邻两帧间的状态号基本都不相同。假设语音有 1000 帧,每帧对应 1 个状态,每 3 个状态组合成一个音素,那么大概会组合成 300 个音素,但这段语音其实根本没有这么多音素。实际上如果真这么做,得到的状态号可能根本无法组合成音素。实际上,相邻帧的状态应该大多数都是相同的,因为每帧很短。解决这个问题的常用方法就是使用隐马尔可夫模型(Hidden Markov Model,HMM)。这东西听起来很复杂,实际上没什么神秘的。基于 HMM 的语音识别,其基本原理无非是:
第一步,构建一个状态网络。
第二步,从状态网络中寻找与声音最匹配的路径。
这样就把结果限制在预先设定的网络中,避免了刚才说到的问题,当然也带来一个局限,比如你设定的网络里只包含了“今天晴天”和“今天下雨”两个句子的状态路径,那么不管说些什么,识别出的结果必然是这两个句子中的一句。
具体是这样的,首先构造音节级网络,然后展开成音素网络,然后展开成状态网络。然后在状态网络中搜索一条最佳路径,这条路径和语音之间总的概率,称之为累积概率最大。搜索的算法是一种动态规划剪枝的算法,称之为 Viterbi 算法,寻找全局最优路径。感兴趣的同学可以到 Wikipedia 上搜一下。
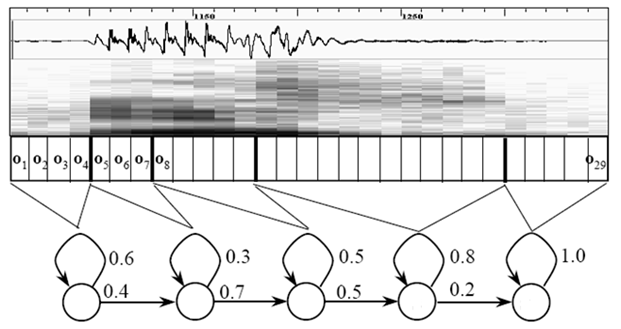
这里所说的累积概率,分为三部分,分别是:
- 观察概率:每帧和每个状态对应的概率
- 转移概率:每个状态转移到自身或转移到下个状态的概率
- 语言概率:根据语言统计规律得到的概率
其中,前两种概率从声学模型中获取,最后一种概率从语言模型中获取。语言模型是使用大量的文本训练出来的,存储的是任意单词、任意两个单词、任意三个单词(通常也就到三个单词)在大量文本中的出现机率。
这样基本上语音识别过程如下。
https://www.cnblogs.com/talkaudiodev/p/10635656.html