01
背景
1、共享变量的提出
前段时间,来自亚马逊 Prime Video 团队的一个案例研究在开发者社区中掀起了轩然大波。大体是这样一件事,作为一个流媒体平台,Prime Video每天都会向客户提供成千上万的直播流。为了确保客户无缝接收内容,Prime Video需要构建一个监控工具来识别客户所查看的每个流中的质量问题,这提出了极高的可扩展性要求。
对此,Prime Video团队优先考虑了微服务架构。由于微服务能够将单体应用分解为多个模块,这不仅能解决工具独立开发和部署的问题,还能为应用提供更高的可用性、可靠性以及技术多样性。最终,Prime Video的服务由三个部分组成,媒体转换器将音视频流发送到检测器的音视频缓冲区;缺陷检测器执行算法,并在发现缺陷时发送实时通知;第三个组件则提供控制服务流程的编排。

当更多流加入到服务中时,成本过高问题开始逐渐显现。由于AWS Step按照函数状态转换向用户收费,当需要处理大量流的时候,大规模运行基础设施的开销会变得非常昂贵,所有构建模块的总成本过高,导致Prime Video团队无法大规模接受最初的解决方案。最终,Prime Video团队重构了基础设施,从微服务迁移到了单体架构,据他们的数据,基础设施成本降低90%。
这件事情也让我们更加的注意到,分布式架构相比单体服务架构同样存在缺点。比如Prime Video 团队遇到问题:分布式架构无法像单体架构那样共享变量,从而导致底层服务处理更多相同的请求进而产生成本飙升的问题。这样的困境在爱奇艺海外架构中同样存在,特别明显的是在策略引擎的调用关系上。
2、爱奇艺海外策略引擎调用关系
2.1 策略引擎调用关系介绍
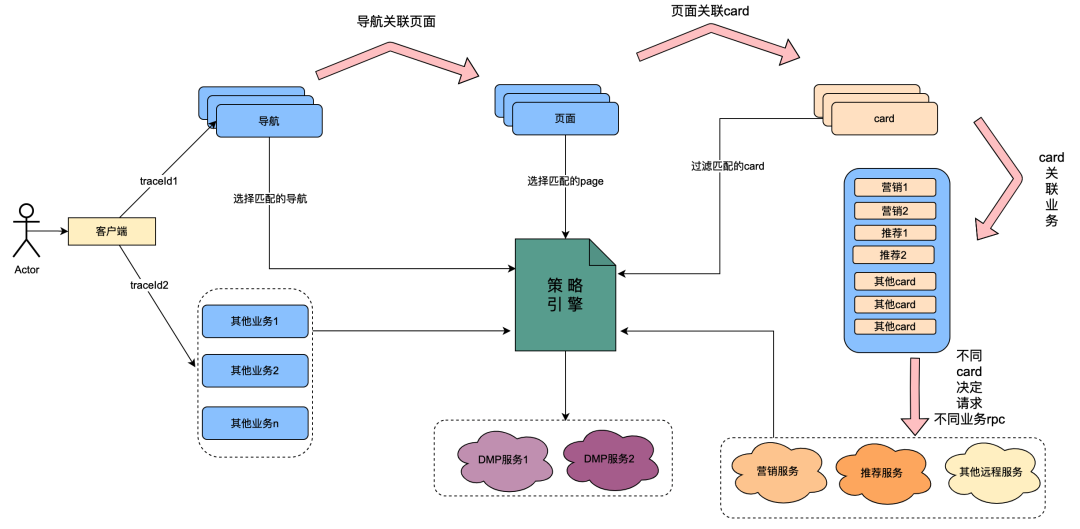
其中,card是页面内的每个栏目的细分模块,通常如电视剧,电影等专栏是一个card。每个card内的数据源都不同,比如有从营销获取营销类数据,有从推荐获取的内容,还有从奇普获取节目内容等。其中这里面有存在关联关系,比如页面关联在导航下面,而card关联在页面下,card内的具体业务数据关联在card下面。
策略引擎是识别人群的匹配服务,如目前配置一条人群策略,里面内容是日本黄金会员,男性,会员到期天数小于7天,偏爱日本动漫。策略引擎服务可以识别某用户是否属于以上人群策略。
在“一切皆可策略”的技术改造之后,已经实现了导航、页面、card、card内数据的用户画像维度定制的能力。大体的实现方式如下:当客户端发起一个请求时,首先请求导航API。在导航数据配置后台,运营同学配置了不同的导航数据,每条导航数据关联了一个策略。导航API内部获取全部导航数据,然后将导航关联的策略与该用户uid和设备id作为入参请求策略引擎,策略引擎进行匹配将满足匹配的策略返回,导航API内部将满足要求的策略关联的导航数据返回,这样实现了不同用户画像看到了不同的导航数据的能力。页面、card、card内数据实现方式大体相同。
从以上的内容可以总结,在策略引擎的调用链路上存在以下特点:
(1)用户打开页面的一次操作会串联调用多次策略引擎服务。
(2)策略引擎接口性能直接影响用户体验:关联很多页面业务服务的请求。
(3)策略引擎数据要求强实时性 :用户购买会员后应该立刻关联到会员相关策略。
2.2 遇到的困境
从上节调用关系可知,策略引擎作为底层服务,承接了较多业务方的流量,而策略引擎判断人群策略是否匹配需要获取用户画像数据,这又强依赖了DMP(Data Management Platforms)服务。为了减少对DMP服务的流量,我们思考了本地缓存的方案。
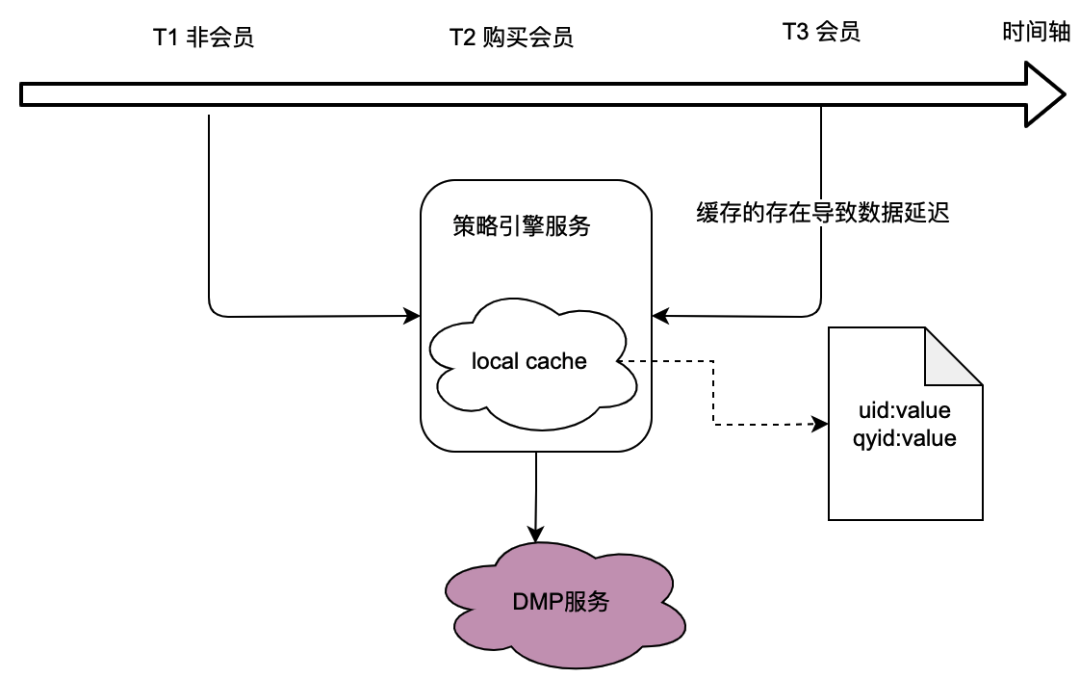
但是这存在的问题很明显,即无法满足数据实时性要求。当用户购买了会员,DMP服务返回的画像数据变更时,因为本地缓存的延迟而导致用户无法看到最新的策略关联数据,这显然是无法忍受的。
同样我们思考了分布式缓存方案。如果使用用户id为key,其痛点和本地缓存一样,无法满足实时性要求。
因此,如何在满足数据实时性要求的情况下,优化对DMP服务的流量是整个策略引擎项目优化的挑战点。
02
共享变量的曙光
1、概述
困境问题的关键在于,分布式服务无法共享变量。用户的一次页面打开行为伴随着多个后端请求,而这些多个后端请求关联的用户画像数据其实是一个,即从DMP服务获取的画像数据一定是相同的。下面我们对策略引擎的调用链路进行抽象分析,看看有哪些特性。
2、策略引擎调用链路分析
策略引擎的调用关系 在1.2.1 策略引擎调用关系介绍章节当中已经介绍,本次主要对其调用链路进行抽象分类。
2.1 串行调用场景
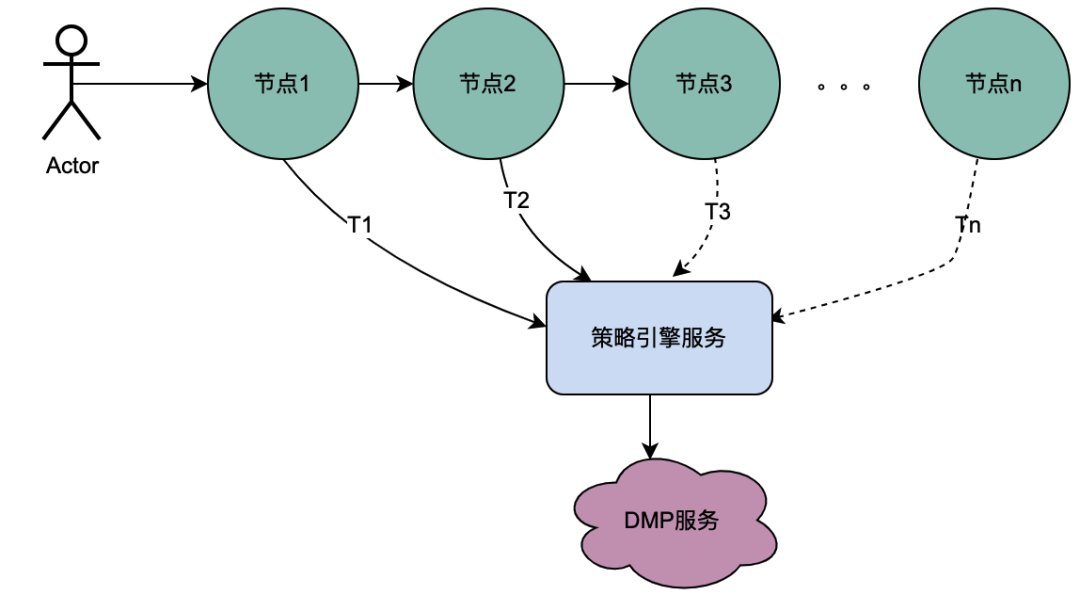
从上图可以看到,一个用户发起一个请求,经过多个节点服务,而节点服务间是串行关系,而每个节点都依赖了策略引擎服务,策略引擎服务都需要获取该用户的画像数据,而很显然,T1到Tn的请求都是同一个用户,DMP服务获取的数据一定是相同的,那么,如果使用共享变量的思路,可以将T1 ~ Tn次对DMP服务的请求优化为1个请求。我们把这里从DMP服务获取到的画像数据命名为分布式共享变量。
2.2 并行调用场景
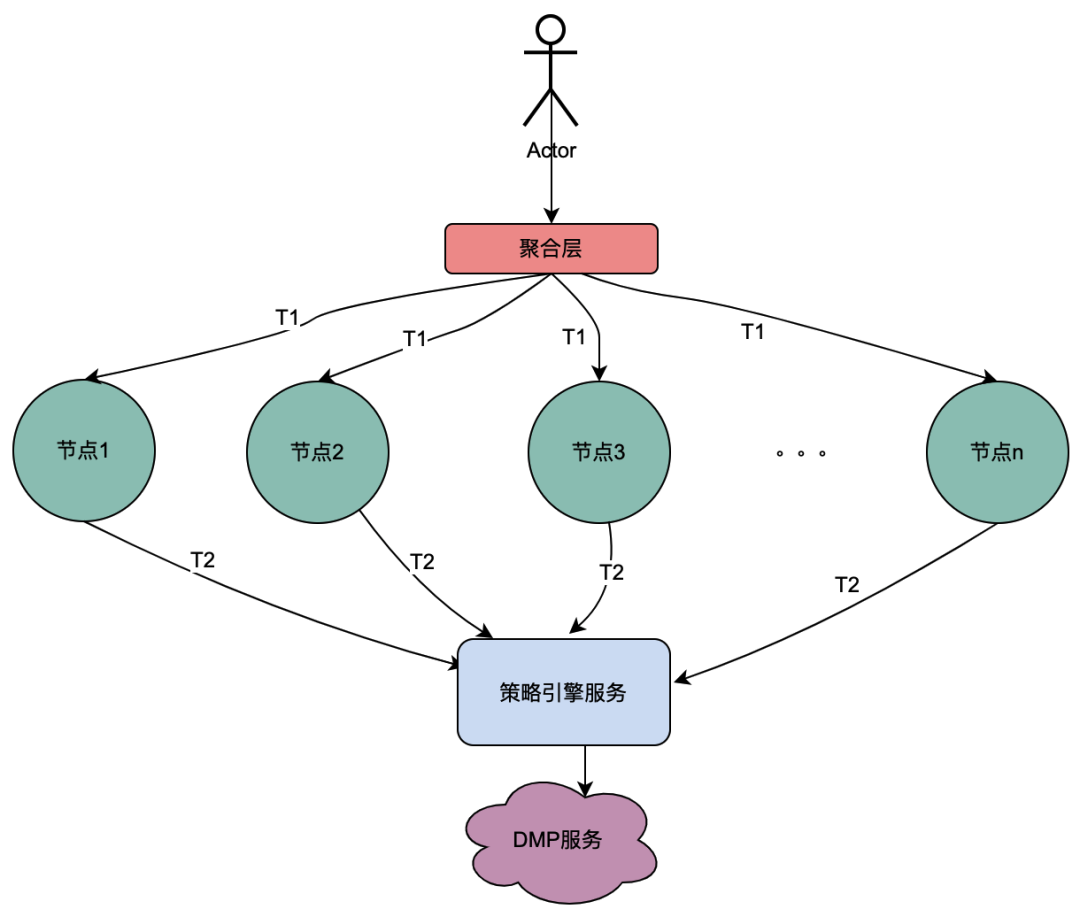
与上面串行调用链不同,串行调用T1到Tn是有时间先后顺序,T1调用一定在T2调用前面。而并行调用没有先后时间顺序,即可能同一个用户发起一次请求,在聚合层业务同时对依赖服务发起请求,依赖服务又依赖了策略引擎,所以,对于同一个用户发起的一次请求,就会同时对策略引擎发起多次请求。那么如果将多次请求放置于一个队列,其中第一个请求去实际的请求DMP服务,其余请求在队列中等待第一个请求的数据,n个请求就可以优化为1个请求。我们把这里从DMP服务获取到的画像数据称为本地共享变量。
03
分布式共享变量介绍
1、原理概述
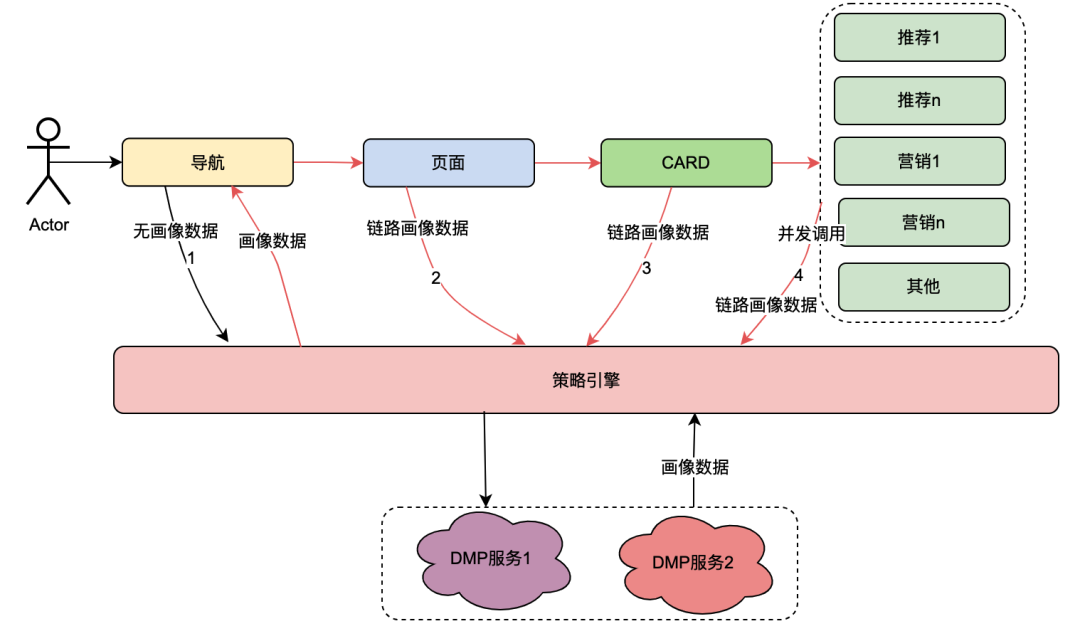
到用户打开页面的时候,客户端会请求导航,然后依次获取特点页面,特定card和特点的card内数据。每个环节都会涉及到策略引擎服务。正常情况下,一次客户端请求将会引发多次策略引擎的调用,从而引起多次对DMP服务的调用。但是很显然,这都是同一个用户的一次请求,这几次对DMP服务的请求获取的用户画像数据一定是相同的。
基于以上分析,分布式共享变量的原理简单描述就是,当【导航】第一次获取到画像数据后,将其内容放在请求链路中,类似于全链路的TraceId一样向下传递。这样下游如【页面】再请求策略引擎时,则可以直接获取链路上下文TraceContext中的链路数据使用,而无需再请求DMP服务。对于CARD,和页面业务同样如此。
值得一提的是,TraceContext只能通过request向下传递。这样在存放链路数据的时候只能是在【导航】获取到策略引擎数据后,将画像数据放置到链路上下文TraceContext中。
如果导航没有关联策略数据,无需请求策略引擎,但是后面的页面、CARD等又关联了策略引擎,那该怎么处理呢?我们参考了TraceId的处理方式,在每个调用策略引擎服务的节点(不同业务如页面、CARD等)进行判断是否有链路数据,如果没有,则获取策略引擎数据后放置进去,如果有则忽略。这样就保证最前置的节点拿到画像数据后,进行向后传递,减少后续节点对于DMP服务的流量。很明显,这些逻辑有一些业务侵入性,所以我们将调用策略引擎的方式优化为SDK调用,在SDK内部做了一些统一的逻辑处理,让业务调用方无感知。
2、全链路追踪 — 基于SkyWalking
skywalking 是分布式系统的应用程序性能监视工具,专为微服务、云原生架构和基于容器化技术(docker、K8s、Mesos)架构而设计,它是一款优秀的 APM(Application Performance Management)工具。skywalking 是观察性分析平台和应用性能管理系统。提供分布式追踪、服务网格遥测分析、度量聚合和可视化一体化解决方案。对于为什么选择skywalking,除去skywalking本身的优势以外,业务上的理由是爱奇艺海外项目目前已经接入SkyWalking,开发成本最低,维护更加便利。所以,使用skywalking传递分布式共享变量只需要引入一个Maven依赖,调用其特有的方法,就可以将数据进行链路传递。
分布式共享变量的方案会增加网络传递数据的大小,增加网络开销;当链路数据足够大的时候甚至会影响服务响应性能。因此控制链路数据大小、链路数据的控制和评估链路数据对网络性能造成影响是尤为重要的。下面将详细介绍。
3、链路传输优化 — 压缩解压缩
3.1 压缩基本原理
目前用处最为广泛的压缩算法包括Gzip等大多是基于DEFLATE,而DEFLATE 是同时使用了 LZ77 算法与哈夫曼编码(Huffman Coding)的一种无损数据压缩算法。其中 LZ77 算法是先通过前向缓冲区预读取数据,然后再向滑动窗口移入(滑动窗口有一定的长度), 不断寻找能与字典中短语匹配的最长短语,然后通过标记符标记,依次来缩短字符串的长度。哈夫曼编码主要是用较短的编码代替较常用的字母,用较长的编码代替较少用的字母,从而减少了文本的总长度,其较少的编码通常使用构造二叉树来实现。
3.2 压缩选型
由于BI获取的用户画像TAG固定且个数较少,因此这里选择DMP数据作为实验对比数据。以下是不同场景下压缩大小对比数据

由上表分析可得
方案3得到的数据最小,因此选择方案3作为分布式共享变量的压缩方案。
4、数据大小导致的网络消耗分析和极端情况控制
4.1 背景概述
这种方案也存在一些弊端,即需要把用户画像数据通过网络传递,显然这增加了网络开销。理论上,网络数据量与传输速度成正比,但是在工程实践中,带宽肯定是有上限的,因此,对于DMP画像数据存入大小进行压测试验,以确定分布式共享变量对于网络性能的影响。
4.2 压测方案
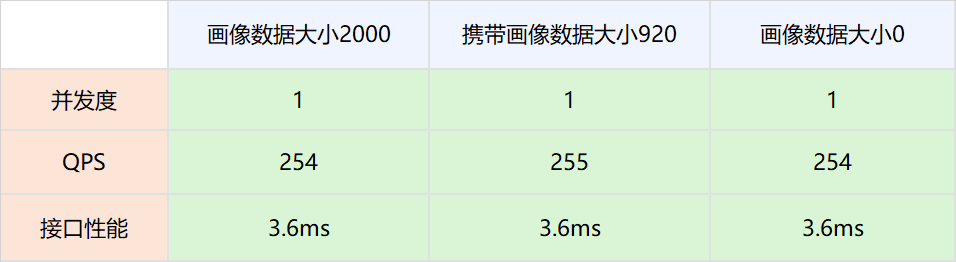
1.测试网络,画像数据不被策略引擎使用,策略引擎依然请求DMP服务。
实验组是请求策略引擎服务的时候带入压缩后的画像数据,对照组是请求策略引擎服务的时候不带入压缩后的画像数据。调整并发值,比较在不同QPS场景下两者的接口性能。
2.分布式共享变量的画像数据被策略引擎使用,策略引擎在有分布式共享变量画像数据的时候,不再请求DMP服务。
4.3结论
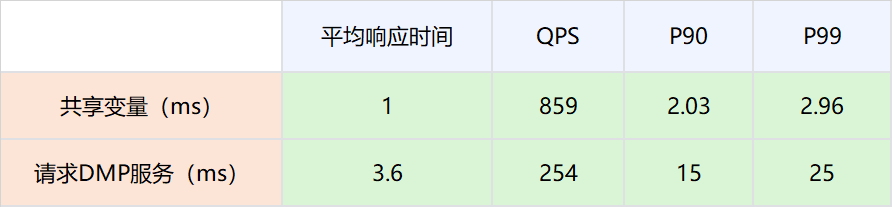
网络链路上存放数据大小在2000以下,对网络性能的影响可以忽略不计。
因为分布式共享变量的存在而减少对DMP服务的请求,接口性能可以有比较大的提升。具体数值为P99从25ms提升到2.96ms。
4.4 极端情况控制
因为DMP数据与用户行为相关,比如一个用户在海外站点所有站点都有购买会员的行为,那么其DMP画像数据就会很大。为了防止这种极端情况所以在判断压缩后的用户画像数据足够大的时候,将自动舍弃,而不是放入网络当中,防止大数据对整个网路数据的性能损耗。
5、线上运行情况
5.1 性能优化
P99 | P90 |
|
|
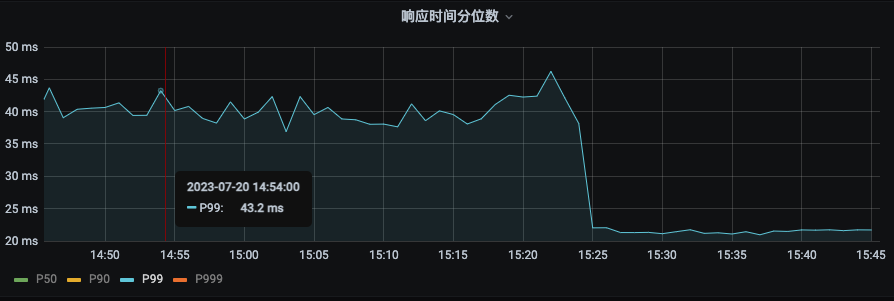
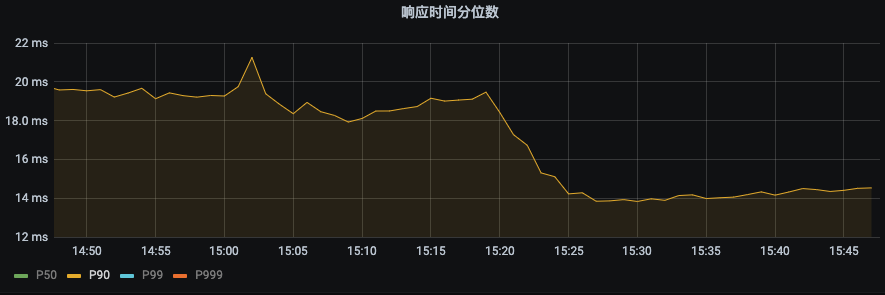
P99 由之前的43ms下降到22ms。下降幅度 48.8% | P90由之前19ms下降到14ms,下降幅度26.3% |
5.2 对DMP服务的流量优化
监控 | 结论 |
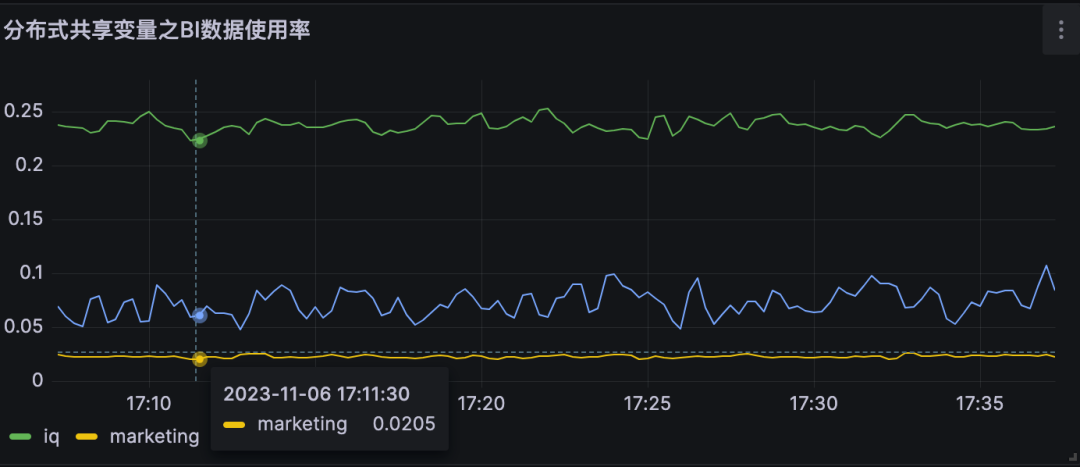
| 分布式共享变量使用率即为对不同DMP服务优化流量。 A业务节约大约25%的流量,B业务节约约10% 的流量, C业务节约约2%的流量 |
| |
|
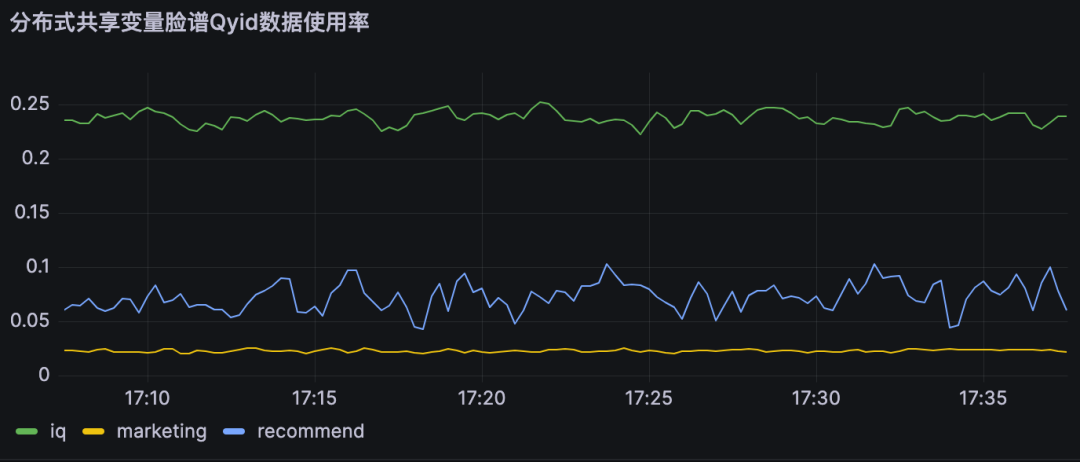
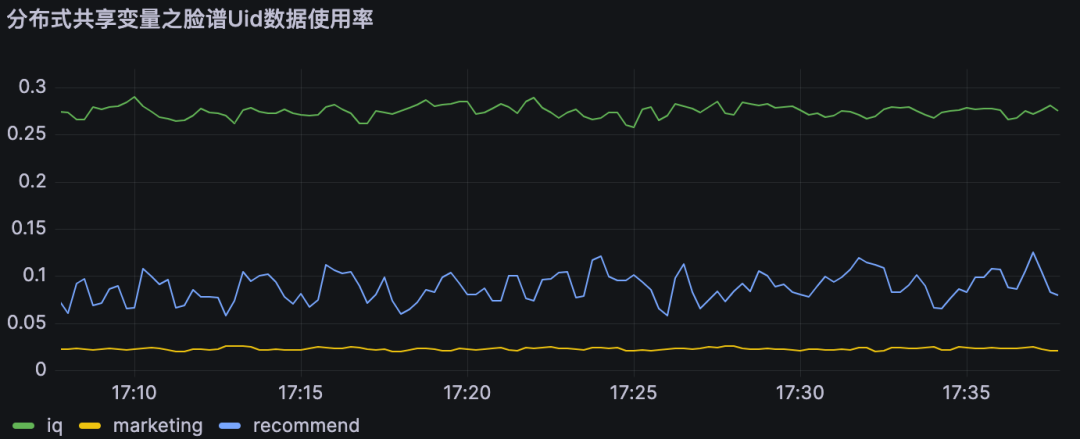
6、结论
分布式共享变量在满足数据实时性要求的前提下,减少了对DMP服务的流量,同时提高了策略引擎服务的接口性能,具体优化指标见上节。
04
本地共享变量介绍
1、原理概述
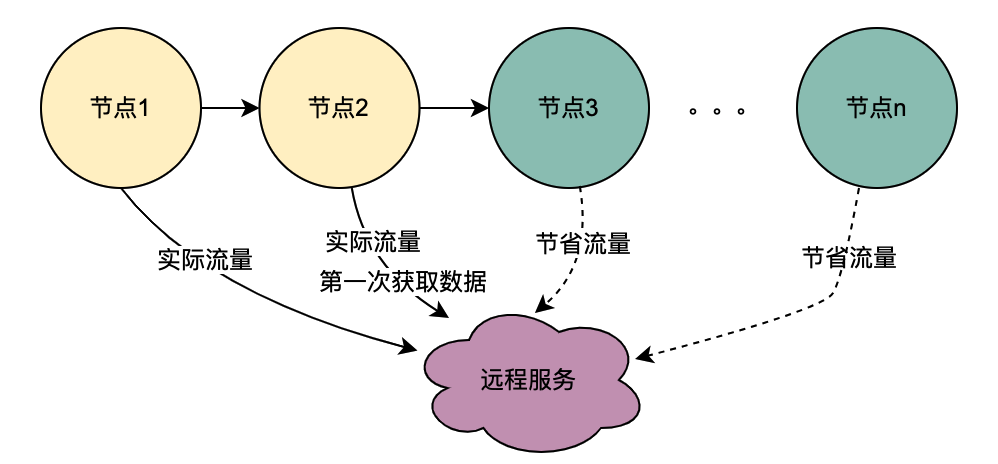
在2.2.2 并行调用场景章节对本地共享变量解决的调用场景进行了阐述,主要解决的是同一个用户并发请求策略引擎带来的多次请求DMP服务问题。如何区分是同一个用户的同一次请求呢?答案是TraceId。在一个请求下,TraceId一定是相同的,如果TraceId相同,那么策略引擎则可以认为是同一个用户的一次请求。
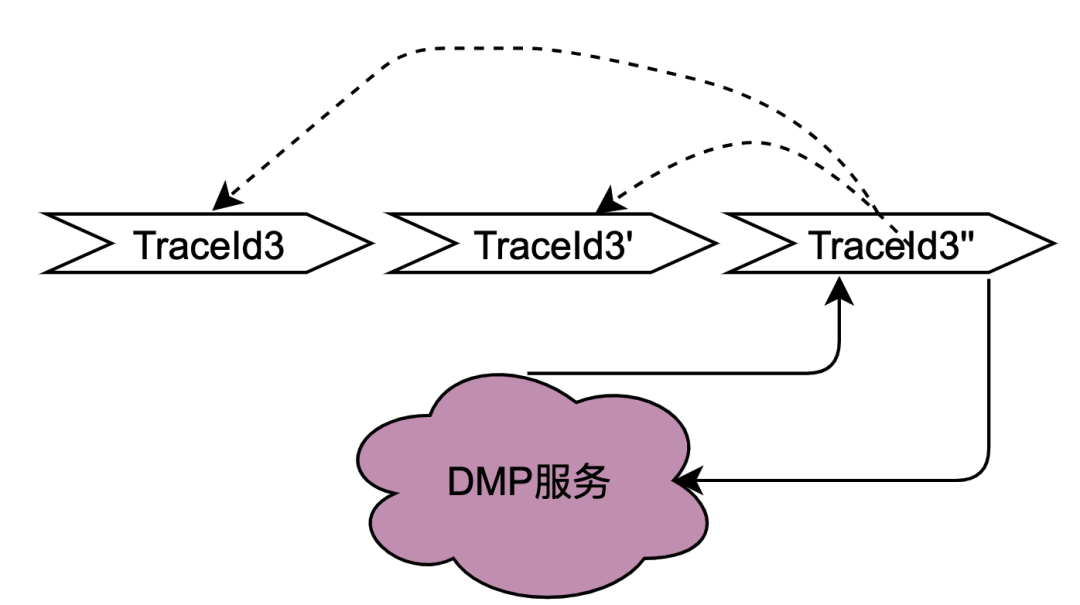
如上图,如果同时多个TraceId3的请求到达策略引擎,将这些请求放入队列,只要其中一个去获取用户画像数据(此处为TraceId3''),其余的请求TraceId3和TraceId3'在队列中等待TraceId3''的结果拿来用即可。
这种思路可以很好的优化并发请求的数据,符合策略引擎调用特性。实现起来有点类似AQS,开发落地有一些难点,比如Trace3''什么时候去请求DMP服务,当拿到数据后,后面仍然有其他trace3进来该如何处理,等待多少时间?这么一思考,这个组件的实现将会耗费我们很多的开发时长,那么有没有现成的中间件可以用呢?答案是本地缓存框架。
无论是本地缓存Caffeine 还是Guava Cache,有相同key的多个请求,只有一个key会请求下游服务,而其他请求会等待拿现成的结果。另外存放的时间可以通过配置缓存的失效时间来确定,至于失效时间的计算方法,将在下面章节会介绍。
2、网关层Hash路由方式的支持
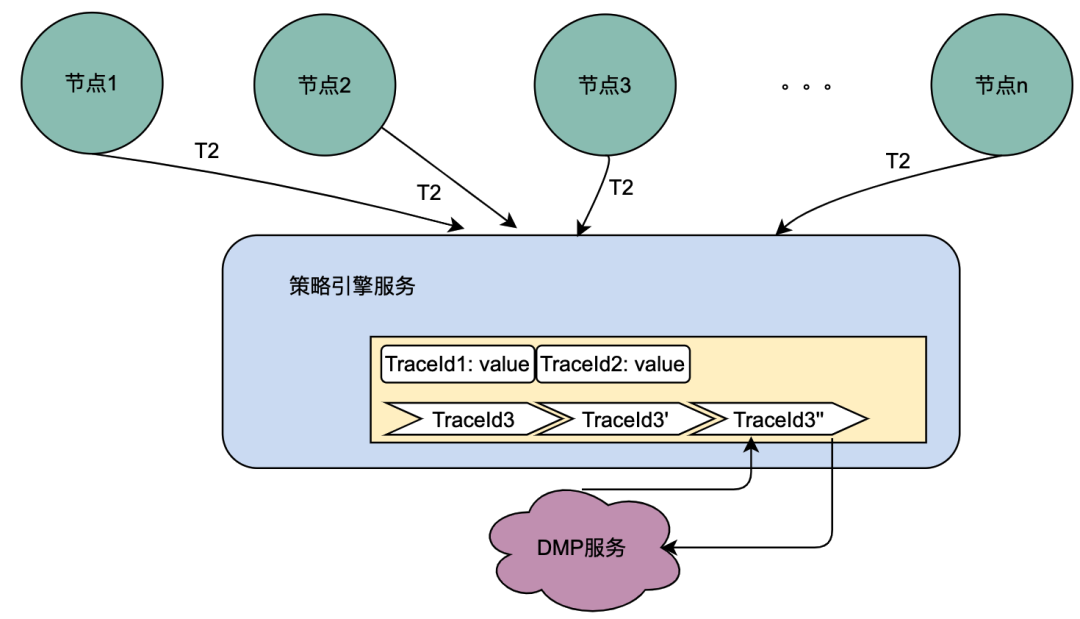
目前,主流的服务一般都是多机房多机器部署,这样有水平扩展能力可以应对业务增长带来的流量增加的问题。但同一个用户的同一个请求,很可能到不同的服务实例,这样上一次获取到的本地缓存数据在下一次请求当中就无法获取。
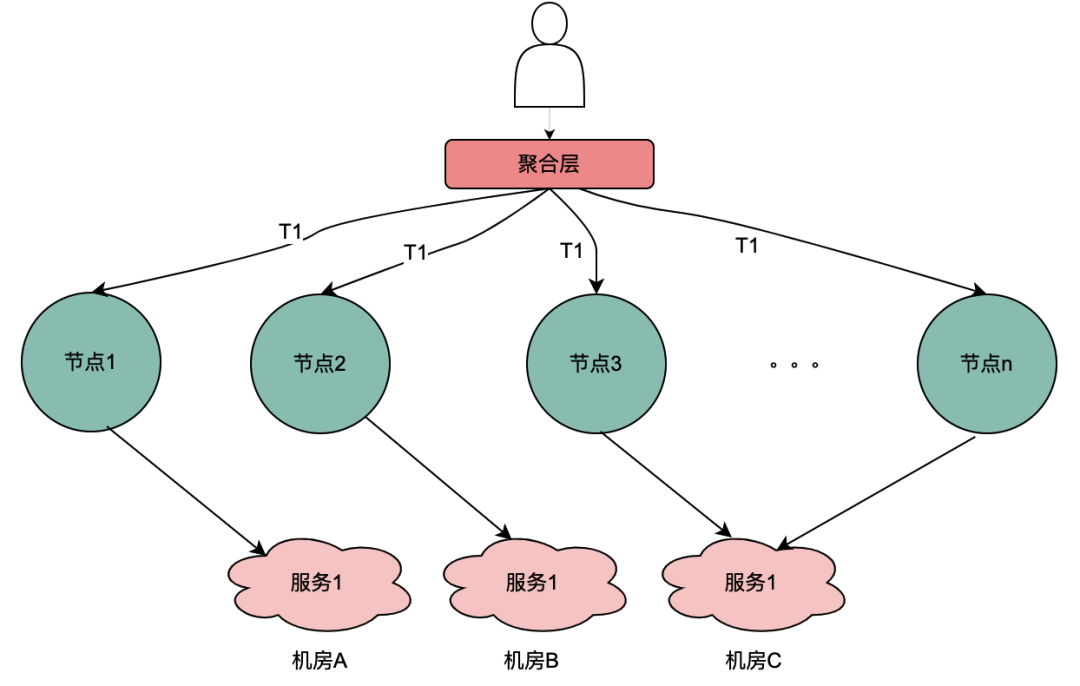
如上图,同一个用户的同一次请求,被聚合层并发请求到不同业务节点1到节点n。由于策略引擎服务是多实例部署,那么不同节点的请求可能到不同实例,那么本地共享变量的命中率就会大大降低,对DMP服务的流量节约数据就会小很多。因此,需要一个方案使得用户的多次请求能到同一个机房的同一个实例。
最终落地的方案是网关支持按照业务自定义字段Hash路由。策略引擎使用qyid进行hash路由,即同一个设备的所有请求到策略引擎服务,那么路由到的机器实例一定是同一个。这样可以很好的提升本地共享变量的命中率。这里提一下,相比轮询请求,字段Hash方式存在如流量偏移的问题,需要配合服务实例流量的监控和报警,避免某些实例流量过多而导致不可用。由于和本次主题无关,实例流量的监控和报警在这里就不做介绍。
3、本地共享变量个数和有效时间设计
和本地缓存不同,本地共享变量的最大个数和过期时间与命中率不成正比,这和具体业务指标相关。
假设策略引擎服务QPS10000,服务实例有50台,那么每台实例的QPS是200,即一台服务实例每秒的请求是200个。只需要保证,同一个TraceId的一批请求,在个数区间内不被淘汰,在时间区间内不被过期即可。我们通过网关日志查找历史上同一个traceId的请求时间戳,几乎都在100ms内。

那么过期时间设置为1s,最大个数设置为200个就可以保证绝大多数同一个TraceId的批次请求,只有一个请求下游服务,其余从缓存获取数据。我们为此也进行了实验,设置不同的过期时间和缓存最大个数,结论和以上分析完全一致。
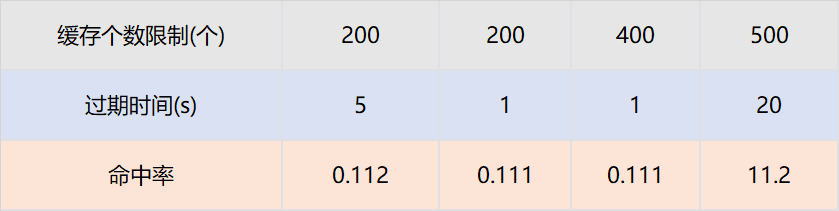
本地共享变量命中率与接口QPS和相同TraceId并发时间相关。
4、结论
本地共享变量上线后,优化数据如下
对于DMP服务1,优化流量15.8%。对于DMP服务2,优化流量 16.7%。对于DMP服务3,优化流量16.2%。
与分布式共享变量一样,本地共享变量同样可以满足数据实时性要求,即不会存在1.2.2 遇到的困境 所遇到的缓存导致的数据实时性不够的问题。
05
总结和展望
本次优化是比较典型的技术创新项目。是先从社区看到一篇技术博客,然后想到爱奇艺海外遇到相同痛点问题的的项目,从而提出优化因为微服务导致的策略引擎对于DMP服务流量压力的目标。
在落地过程中,遇到使用本地缓存进行优化而无法克服数据实效性问题的挑战。最终沉下心分析策略引擎的调用链路,将调用链路一分为二:串行调用和并行调用,最终提出了共享变量的解决方案。因为串行调用和并行调用的特点迥异,依次针对两者进行分期优化,其中第一期通过分布式共享变量优化了串行调用DMP服务的流量,在第二期通过本地共享变量优化了并行调用DMP服务的流量。
由于作者水平有限,疏漏之处欢迎读者批评指正。
参考文章:
猎户座-持续打造爱奇艺海外高扩展性的策略引擎项目
Scaling up the Prime Video audio/video monitoring service and reducing costs by 90%
从微服务转为单体架构、成本降低 90%,亚马逊内部案例引发轰动!CTO:莫慌,要持开放心态
分布式系统日志打印优化方案的探索与实践

也许你还想看
低代码、中台化:爱奇艺号微服务工作流实践
揭秘内存暴涨:解决大模型分布式训练OOM纪实