一.容错机制
在Flink中,有一套完整的容错机制来保证故障后的恢复,其中最重要的就是检查点。
1.1 检查点(Checkpoint)
在流处理中,我们可以用存档读档的思路,将之前某个时间点的所有状态保存下来,这份存档就被称为“检查点(CkeckPoint)”。
当Flink程序异常重启时,我们就可以在检查点中“读档”,恢复出异常之前的状态。
1.1.1 检查点的保存
(1) 周期性的触发保存
在Flink中,检查点的保存是周期性触发的,间隔时间可以进行设置。但是不建议保存太频繁,会消耗很多资源来做检查点。
(2) 保存的时间点
我们应该在所有任务(算子)都恰好处理完一个相同的输入数据的时候,将它们的状态保存下来。
这样做可以实现一个数据被所有任务(算子)完整地处理完,状态得到了保存。
如果出现故障,我们恢复到之前保存的状态,故障时正在处理的所有数据都需要重新处理;我们只需要让源(source)任务向数据源重新提交偏移量、请求重放数据就可以了(即重新将故障时的数据读入Flink)。当然这需要源任务可以把偏移量作为算子状态保存下来,而且外部数据源能够重置偏移量;kafka就是满足这些要求的一个最好的例子。
(3) 保存的具体流程
检查点的保存,最关键的就是要等所有任务将“同一个数据”处理完毕。
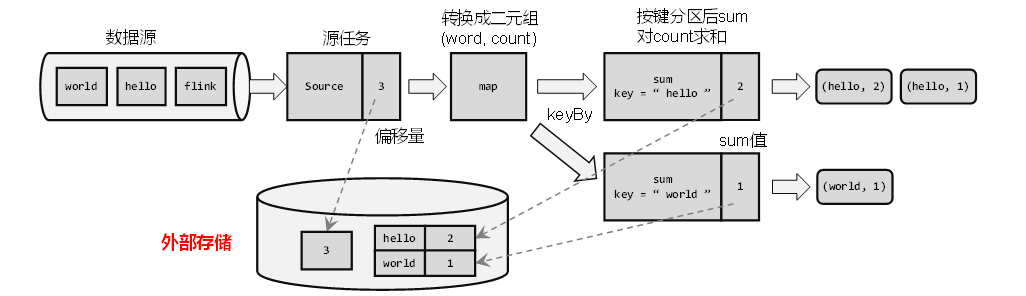
例如词频统计,依次输入“hello”,“world”,“hello”,“flink”,“hello”,“world”,“hello”,“flink”…
例如每个任务算子都处理完“hello”之后,可以保存自己的状态。
1.1.2 从检查点恢复状态
(1)检查点的保存具体流程
接着上面的例子,当我们需要保存检查点时,就是在所有任务算子将“同一个数据”处理完毕后,对所有状态进行快照并保存。例如输入“hello”,“world”,“hello”,“flink”,“hello”,“world”,“hello”,“flink”…在第三个数据“hello”被所有任务处理完时,做了检查点,保存了当前所有状态。
(2) 处理数据过程发生故障
当发生故障时,就需要找到最近一次成功保存的检查点来恢复状态。
例如在第三条数据“hello”处理完后保存了一次检查点,然后继续运行,正常处理了第四条数据“flink”,随即在处理第五条数据“hello”时发生故障。

此时,source任务处理完毕,偏移量为5,map任务也处理完毕,处理到KeyBy时发生故障,此时状态未保存。
(3) 重启应用 -> 读取检查点,重置状态
1.重启应用
遇到故障后,需要重启Flink程序,届时,重启后的所有任务的状态会被清空。

2.读取检查点,重置状态
找到最近一次保存的检查点,从中读出每个算子的快照,并分别填充到对于的算子状态中,这样Flink内部算子的状态就恢复到了保存检查点的那一刻,就是处理完第三条数据时。

3.重置偏移量
此时从检查点恢复状态后还存在一个问题,如果接着处理故障后的数据也就是第6、7条数据,那么从最后一次检查点到故障前的数据(第4、5条的“flink”,“hello”)则被丢弃了,就造成了计算结果错误。
为了不丢数据,我们应该从最后一次保存的检查点后重新读取数据(重放),这可以通过Source任务向外部系统提交偏移量(offset)来解决。

这样,整个系统的状态已经完全回退到了检查点保存完成的那一时刻。
4.继续处理数据
接下来继续处理重放的第4、5条数据,接着处理后续的数据。
在处理完上次发生故障的数据时,就已经完全恢复了正常,似乎没有发生过故障,也没有造成重复计算导致计算错误,这就保证了计算结果的准确性。在分布式系统中,这叫做实现了“精准一次”(exactly-once)的状态一致性保证。
1.1.3 检查点算法
在Flink中,采用了基于Chandy-Lamport算法的分布式快照,可以在不暂停整体流处理的前提下,将状态备份保存到检查点。
1.1.3.1 检查点分界线(Barrier)
借鉴水位线的设计,在数据流中插入一个特殊的数据结构,专门用来表示触发检查点保存的时间点。收到保存检查点的指令后,Source任务可以在当前数据流中插入这个结构;之后的所有任务只要遇到它就开始对状态做持久化快照保存。由于数据流是保持顺序依次处理的,因此遇到这个标识就代表之前的数据都处理完了,可以保存一个检查点;而在它之后的数据,引起的状态改变就不会体现在这个检查点中,而需要保存到下一个检查点。
这种特殊的数据形式,把一条流上的数据按照不同的检查点分隔开,所以就叫做检查点的“分界线”(Checkpoint Barrier)。
具体实现:
在JobManager中有一个“检查点协调器”,专门用来协调处理检查点相关的工作。检查点协调器会定期向TaskManager发出指令,要求保存检查点(携带检查点ID)。TaskManager会让所有的Source任务把自己的偏移量(Source任务状态)保存起来,并将带有检查的ID的分界线插入当前数据流中,然后该分界线会像正常数据一样向下游传递,当下游算子任务遇到分界线则保存自己的状态。

简单来说,就是在该需要保存检查点时,JobManager中的“检查点协调器”会向TaskManager发出指令要求保存检查点,这时,TaskManager会在会让所有的Source任务保存自己的状态,并在当前流插入一个特殊的数据(分界线),分界线会依次向下游传递,当下游的算子遇到分界线就保存自己的状态,这个分界线后面到达的数据则属于下一个检查点的数据了。这也是很符合“流”的概念。
1.1.3.2 分布式快照算法(Barrier对齐的精准一次)
barrier指示的是“之前所有数据的状态更改保存入当前检查点”:其实是一个“截止时间”的标志。所以在处理多个分区的传递时,也要以是否还会有数据到来作为一个判断标准。
具体实现上,Flink使用了Chandy-Lamport算法的一种变体,被称为“异步分界线快照”算法。算法的核心就是两个原则:
- 当上游任务向多个并行下游任务发送barrier时,需要广播出去;
- 而当多个上游任务向同一个下游任务传递分界线时,需要在下游任务执行“分界线对齐”操作,也就是需要等到所有并行分区的barrier都到齐,才可以开始状态的保存。
检查点算法的并行场景
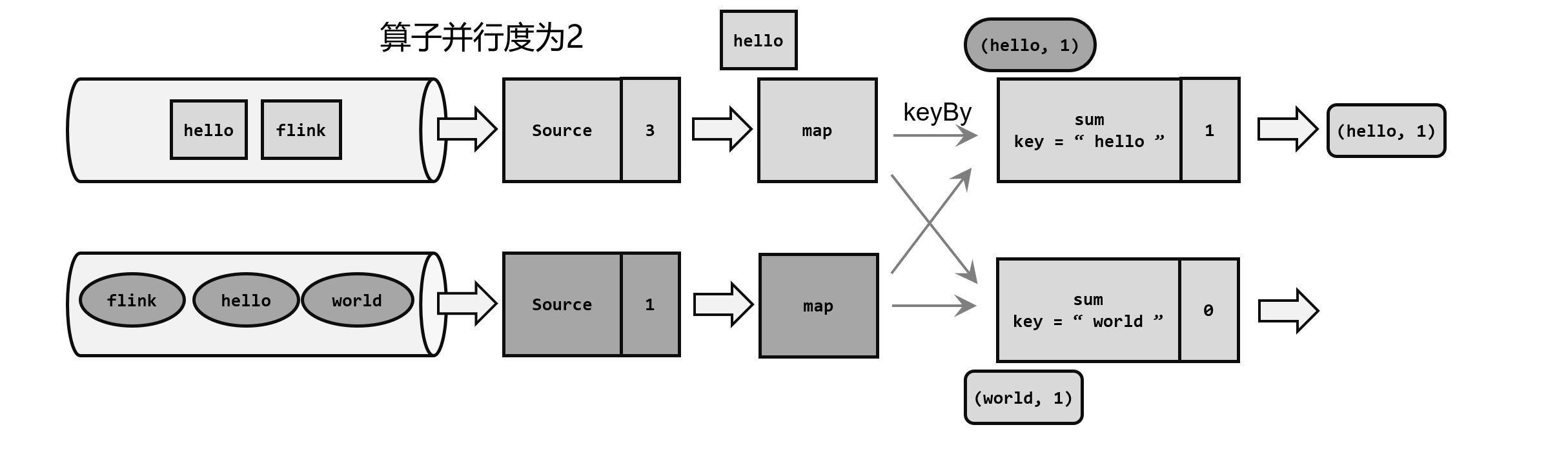
当前应用全局并行度为2,Source也有两个并行任务,分别读取两条数据流,流中数据都是一个一个的单词。此时第一条流读了三条数据,Source偏移量为3.;第二条流读了一条数据,Source偏移量为1。
检查点保存算法具体过程为:
(1)触发检查点:JobManager向Source发送Barrier;
JobManager发送指令,触发检查点保存;所有的Source任务中插入一个Barrier(分界线),并保存Source的偏移量(状态)。

说明:检查点保存时,只会保存分界线到来前的所有状态。并且该操作并不会影响其上下游算子任务的正常运行。
(2)Barrier发送:向下游广播发送;
Source状态保存完成后,会返回通知给Source任务,随后Source任务会像JobManager发送ACK来确认检查点完成,然后继续将Barrier(分界线)向下游传递
此时,由于Source算子和Map算子是一对一的关系,可以直接将Barrier传递给Map算子。
(3)向下游多个并行算子广播分界线,执行分界线对齐;
Map算子没有状态,则直接将Barrier继续向下游传递。这时由于进行到了KeyBy分区操作,会将Barrier广播到下游并行的两个Sum任务,这时,Sum算子可能会收到来自上游两个并行Map任务的Barrier,所以需要执行“分界线对齐”操作。

此时,Sum2接收到了上游Map传来的两个Barrier,说明第一条流的三条数据和第二条流的一条数据都已经处理完毕,则可以进行状态保存。而Sum1只收到了一个Barrier,则必须等待Barrier到齐才可以保存状态,此时Sum1分界线后的数据则会被缓存起来,等到当前检查点保存后再处理。分界线前的所有状态才会被保存。
(4)状态保存:有状态的算子将状态保存至持久化。
各个分区的分界线到齐后,就可以对当前状态做快照,保存到持久化存储。存储完成后,同样继续将Barrier向下游继续传递,并通知JobManager检查点保存完毕。

在这个过程中,每个任务保存自己的状态都是相对独立的,互不影响,并且不影响流中其他算子的正常运行。
说明:
由于分界线对齐要求先到达的分区做缓存等待,一定程度上会影响处理的速度;当出现背压时,下游任务会堆积大量的缓冲数据,检查点可能需要很久才可以保存完毕。
为了应对这种场景,Barrier对齐中提供了至少一次语义以及Flink 1.11之后提供了不对齐的检查点保存方式,可以将未处理的缓冲数据也保存进检查点。这样,当我们遇到一个分区barrier时就不需等待对齐,而是可以直接启动状态的保存了。
1.1.3.3 分布式快照算法(Barrier对齐的至少一次)
之前的精准一次中,在进行“分界线对齐”时,下游算子必须等待上游算子发来的所有的Barrier到齐才可以进行状态保存,并且Barrier后到达的数据都会被缓存起来,不会被当前检查点所计算和保存。
而Barrier对齐的至少一次指的是,但在等待所有的Barrier到齐之前,到达该分区的数据会被直接计算,并被保存至此检查点。这样的话,如果程序重启,数据重放时,介于两个Barrier之间到达的数据会被再次计算。(至少一次)
优点:数据无需阻塞,也就不需要额外的空间对其存储。
缺点:程序重启可能会造成数据重复计算。
1.1.3.4 分布式快照算法(非Barrier对齐的精准一次)
知识:数据会先进入算子的输入缓冲区,处理完毕后进入该算子的输出缓存区,再发往下游算子的输入缓冲区。

非Barrier对齐的精准一次指的就是,当下游算子接收到一个Barrier时(到达输入缓冲区时),会直接将第一个Barrier放到输入缓冲区末端,继续向下游传递。被第一个Barrier越过的输入缓冲区和输出缓冲区的数据以及在其他Barrier之前的数据会被标记,在进行状态保存时,这些被标记的数据和状态都会被保存进检查点,在进行恢复时,则直接恢复这些数据和状态。
优点:数据无需阻塞
缺点:增大IO压力
1.1.3.5 检查点算法总结
1.Barrier对齐:一个Task等待所有上游发送同编号Barrier到齐后,才对自己的本地状态做备份。
精准一次:在Barrier对齐过程中,Barrier后面的数据阻塞等待(被缓存),不会越过Barrier。
至少一次:在Barrier对齐过程中,第一个Barrier后的数据不阻塞,接着计算。
2.非Barrier对齐:一个Task收到第一个Barrier时,开始执行备份,最后一个Barrier到达时结束备份。
先到的Barrier,将本地状态备份,后面的数据接着计算
未到的Barrier,之前的数据接着计算,同时将这些数据保存到备份中
最后一个Barrier到达时,该Task备份结束
1.1.4 检查点配置
检查点的作用是为了故障恢复,我们不能因为保存检查点占据了大量时间、导致数据处理性能明显降低。为了兼顾容错性和处理性能,我们可以在代码中对检查点进行各种配置。
1.1.4.1 检查点常用配置
启用检查点
// 启用检查点,周期性保存(5s),默认Barrier对齐,精准一次
env.enableCheckpointing(1000);获取检查点配置,后续配置都需要基于checkPointConfig
CheckpointConfig checkpointConfig = env.getCheckpointConfig();指定检查点存储位置
// 指定检查点存储位置,可以是HDFS,也可以是本地路径
checkpointConfig.setCheckpointStorage("hdfs://hadoop:8001/checkpoint");检查点执行超时时间
// checkPoint执行超时时间,超时则认为失败(默认十分钟)
checkpointConfig.setCheckpointTimeout(60000);checkPoint最大并行数量
// 最大同时运行的checkPoint数量,推荐为1,减少程序压力
checkpointConfig.setMaxConcurrentCheckpoints(1);checkPoint最小等待间隔
// 最小等待间隔,指的是 上一轮checkPoint结束 到 下次checkPoint开始之间的间隔,大于0,则checkPoint最大数量为1
checkpointConfig.setMinPauseBetweenCheckpoints(1000);取消作业时(Cancel),checkPoint的数据是否保存在外部存储系统中
checkpointConfig.setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION
);// DELETE_ON_CANCELLATION:任务主动取消,不保留checkPoint;程序异常退出,则不会删除
// RETAIN_ON_CANCELLATION:任务主动取消,保留checkPoint允许checkPint连续失败次数
// 允许checkPint连续失败次数,默认为0 ,超过时任务会挂掉
checkpointConfig.setTolerableCheckpointFailureNumber(10);开启非对齐检查点(barrier非对齐)
// 开启非对齐检查点(barrier非对齐)
// 开启要求:checkPoint最大并发为1,并且checkPoint模式为精准一次
checkpointConfig.enableUnalignedCheckpoints();// 设置对齐超时时间
// 默认为0,默认直接使用非Barrier对齐
// 当对齐超时时间>1时,会先使用Barrier对齐,对齐时间超过这个参时,则切换为非Barrier对齐
checkpointConfig.setAlignedCheckpointTimeout(Duration.ofSeconds(1000));1.1.4.2 最终检查点
如果数据源是有界的,就可能出现部分Task已经处理完所有数据,变成finished状态,不继续工作。从 Flink 1.14 开始,这些finished状态的Task,也可以继续执行检查点。自 1.15 起默认启用此功能,并且可以通过功能标志禁用它(不推荐禁用):
Configuration config = new Configuration();
config.set(ExecutionCheckpointingOptions.ENABLE_CHECKPOINTS_AFTER_TASKS_FINISH, false);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(config);
1.1.5 保存点(Savepoint)
除了检查点外,Flink还提供了另一个非常独特的镜像保存功能——保存点(savepoint)。
从名称就可以看出,这也是一个存盘的备份,它的原理和算法与检查点完全相同,只是多了一些额外的元数据。
1.1.5.1 保存点的用途
保存点与检查点最大的区别,就是触发的时机。检查点是由Flink自动管理的,定期创建,发生故障之后自动读取进行恢复,这是一个“自动存盘”的功能;而保存点不会自动创建,必须由用户明确地手动触发保存操作,所以就是“手动存盘”。
保存点可以当作一个强大的运维工具来使用。我们可以在需要的时候创建一个保存点,然后停止应用,做一些处理调整之后再从保存点重启。它适用的具体场景有:
- 版本管理和归档存储
- 更新Flink版本
- 更新应用程序
- 调整并行度
- 暂停应用程序
需要注意的是,保存点能够在程序更改的时候依然兼容,前提是状态的拓扑结构和数据类型不变。我们知道保存点中状态都是以算子ID-状态名称这样的key-value组织起来的,算子ID可以在代码中直接调用SingleOutputStreamOperator的.uid()方法来进行指定:
DataStream<String> stream = env.addSource(new StatefulSource()).uid("source-id") // 指定算子Uid.map(new StatefulMapper()).uid("mapper-id").print();
对于没有设置ID的算子,Flink默认会自动进行设置,所以在重新启动应用后可能会导致ID不同而无法兼容以前的状态。所以为了方便后续的维护,强烈建议在程序中为每一个算子手动指定ID。
1.1.5.2 使用保存点
保存点的使用非常简单,我们可以使用命令行工具来创建保存点,也可以从保存点恢复作业。
1.创建保存点
要在命令行中为运行的作业创建一个保存点镜像,只需要执行:
bin/flink savepoint :jobId [:targetDirectory]这里jobId需要填充要做镜像保存的作业ID,目标路径targetDirectory可选,表示保存点存储的路径。
对于保存点的默认路径,可以通过配置文件flink-conf.yaml中的state.savepoints.dir项来设定:
state.savepoints.dir: hdfs:///flink/savepoints当然对于单独的作业,我们也可以在程序代码中通过执行环境来设置:
env.setDefaultSavepointDir("hdfs:///flink/savepoints");由于创建保存点一般都是希望更改环境之后重启,所以创建之后往往紧接着就是停掉作业的操作。除了对运行的作业创建保存点,我们也可以在停掉一个作业时直接创建保存点:
bin/flink stop --savepointPath [:targetDirectory] :jobId2.从保存点重启应用
我们已经知道,提交启动一个Flink作业,使用的命令是flink run;现在要从保存点重启一个应用,其实本质是一样的:
bin/flink run -s :savepointPath [:runArgs]这里只要增加一个-s参数,指定保存点的路径就可以了,其它启动时的参数还是完全一样的,如果是基于yarn的运行模式还需要加上 -yid application-id。当使用web UI进行作业提交时,可以填入的参数除了入口类、并行度和运行参数,还有一个“Savepoint Path”,这就是从保存点启动应用的配置。
1.1.5.3 使用保存点切换状态后端
在命令行重新恢复作业时,在命令行中添加以下命令以切换状态后端
-D state.backend=rocksdb1.2 状态一致性
1.2.1 一致性的概念和级别
一致性其实就是结果的正确性,一般从数据丢失、数据重复来评估。
流式计算本身就是一个一个来的,所以正常处理的过程中结果肯定是正确的;但在发生故障、需要恢复状态进行回滚时就需要更多的保障机制了。我们通过检查点的保存来保证状态恢复后结果的正确,所以主要讨论的就是“状态的一致性”。
一般说来,状态一致性有三种级别:
- 最多一次(At-Most-Once)
- 至少一次(At-Least-Once)
- 精确一次(Exactly-Once)
1.2.2 端到端的状态一致性
在Flink中可以通过检查点机制来保障内部状态的一致性,但往往在实际应用中,Flink是从外部系统(Source)中读取数据,最终输出到外部系统(Sink)中,并不是Flink可以做到精确一次,整个程序在异常时就不会出现如何问题。例如外部数据源并不支持数据重放。这就要求我们不仅要考虑Flink内部数据的处理转换,还涉及到从外部数据源读取,以及写入外部持久化系统,整个应用处理流程从头到尾都应该是正确的。
所以完整的流处理应用,应该包括了数据源、流处理器和外部存储系统三个部分。这个完整应用的一致性,就叫做“端到端(end-to-end)的状态一致性”,它取决于三个组件中最弱的那一环。一般来说,能否达到at-least-once一致性级别,主要看数据源能够重放数据;而能否达到exactly-once级别,流处理器内部、数据源、外部存储都要有相应的保证机制。
1.3 端到端精确一次(End-To-End Exactly-Once)
实际应用中,最难做到、也最希望做到的一致性语义,无疑就是端到端(end-to-end)的“精确一次”。我们知道,对于Flink内部来说,检查点机制可以保证故障恢复后数据不丢(在能够重放的前提下),并且只处理一次,所以已经可以做到exactly-once的一致性语义了。
所以端到端一致性的关键点,就在于输入的数据源端和输出的外部存储端。
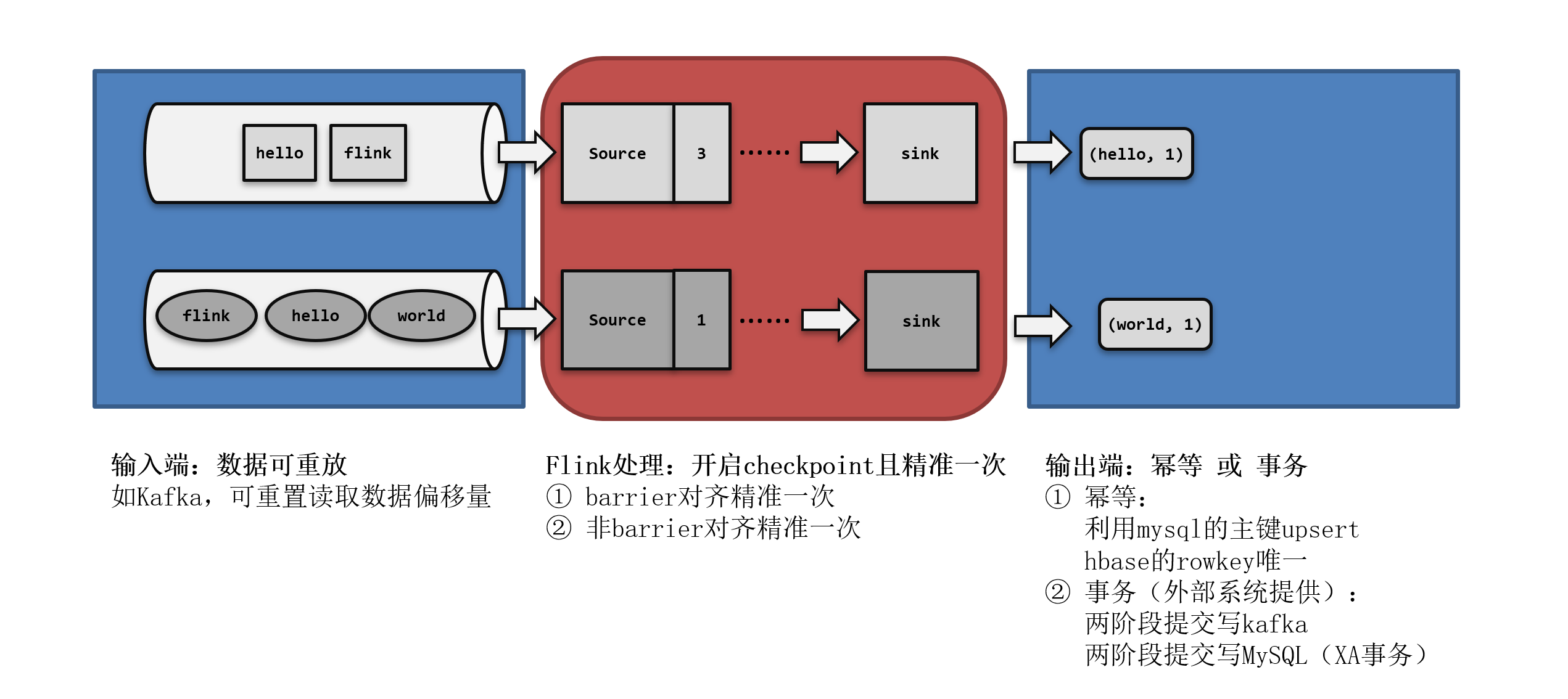
1.3.1 输入端保证
输入端主要指的就是Flink读取的外部数据源。对于一些数据源来说,并不提供数据的缓冲或是持久化保存,数据被消费之后就彻底不存在了,例如socket文本流。对于这样的数据源,故障后我们即使通过检查点恢复之前的状态,可保存检查点之后到发生故障期间的数据已经不能重发了,这就会导致数据丢失。所以就只能保证at-most-once的一致性语义,相当于没有保证。
想要在故障恢复后不丢数据,外部数据源就必须拥有重放数据的能力。例如Fafka可以重置偏移量来达到数据重放,这也是实现端到端exactly-once的基本要求。
1.3.2 输出端保证
有了Flink的检查点机制,以及可重放数据的外部数据源,我们已经能做到at-least-once了。但是想要实现exactly-once却有更大的困难:数据有可能重复写入外部系统。
为了防止数据重复写入外部系统,保证exactly-once一致性的写入方式有两种:
- 幂等写入
- 事务写入
1.幂等(Idempotent)写入
所谓“幂等”操作,就是说一个操作可以重复执行很多次,但只导致一次结果更改。也就是说,后面再重复执行就不会对结果起作用了。
例如使用Redis中的键值存储、MySQL中的唯一约束等。
2.事务(Transactional)写入
事务有两种实现方式:预写日志(WAL)和两阶段提交(2PC)
(1)预写日志(write-ahead-log,WAL)
我们发现,事务提交是需要外部存储系统支持事务的,否则没有办法真正实现写入的回撤。那对于一般不支持事务的存储系统,能够实现事务写入呢?
预写日志(WAL)就是一种非常简单的方式。具体步骤是:
①先把结果数据作为日志(log)状态保存起来
②进行检查点保存时,也会将这些结果数据一并做持久化存储
③在收到检查点完成的通知时,将所有结果一次性写入外部系统。
④在成功写入所有数据后,在内部再次确认(ack)相应的检查点,将确认信息也进行持久化保存。这才代表着检查点的真正完成。
我们会发现,这种方式类似于检查点完成时做一个批处理,一次性的写入会带来一些性能上的问题;而优点就是比较简单,由于数据提前在状态后端中做了缓存,所以无论什么外部存储系统,理论上都能用这种方式一批搞定。在Flink中DataStream API提供了一个模板类GenericWriteAheadSink,用来实现这种事务型的写入方式。
需要注意的是,预写日志这种一批写入的方式,有可能会写入失败;所以在执行写入动作之后,必须等待发送成功的返回确认消息。在成功写入所有数据后,在内部再次确认相应的检查点,这才代表着检查点的真正完成。这里需要将确认信息也进行持久化保存,在故障恢复时,只有存在对应的确认信息,才能保证这批数据已经写入,可以恢复到对应的检查点位置。
但这种“再次确认”的方式,也会有一些缺陷。如果我们的检查点已经成功保存、数据也成功地一批写入到了外部系统,但是最终保存确认信息时出现了故障,Flink最终还是会认为没有成功写入。于是发生故障时,不会使用这个检查点,而是需要回退到上一个;这样就会导致这批数据的重复写入。
(2)两阶段提交(two-phase-commit,2PC)
前面提到的各种实现exactly-once的方式,多少都有点缺陷;而更好的方法就是两阶段提交(2PC)。
顾名思义,它的想法是分成两个阶段:先做“预提交”,等检查点完成之后再正式提交。这种提交方式是真正基于事务的,它需要外部系统提供事务支持。
具体的实现步骤为:
①当第一条数据到来时,或者收到检查点的分界线时,Sink任务都会启动一个事务。
②接下来接收到的所有数据,都通过这个事务写入外部系统;这时由于事务没有提交,所以数据尽管写入了外部系统,但是不可用,是“预提交”的状态。
③当Sink任务收到JobManager发来检查点完成的通知时,正式提交事务,写入的结果就真正可用了。
简单来说,就是第一条数据达到,或者分界线到达的时候开启事务,数据被写入外部系统(预提交)。检查点保存成功,则提交事务,此时数据真正可用;否则事务回滚,外部系统的数据也被回滚。
当事务中发生故障时,事务将会回滚,被写入外部系统的数据也应该被撤回。两阶段提交充分的利用了Flink的检查点机制,当分界线到来时,则开启一个事务;当检查点成功时,则提交该事务,并且该方法不用预写日志的批处理,减少了很多开销。
在我们使用Flink官方提供的连接器时,无需自己实现两阶段提交(P2P)。
不过两阶段提交虽然精巧,却对外部系统有很高的要求。这里将2PC对外部系统的要求列举如下:
- 外部系统必须提供事务支持,或者Sink任务必须能够模拟外部系统上的事务。
- 在检查点的间隔期间里,必须能够开启一个事务并接受数据写入。
- 在收到检查点完成的通知之前,事务必须是“等待提交”的状态。在故障恢复的情况下,这可能需要一些时间。如果这个时候外部系统关闭事务(例如超时了),那么未提交的数据就会丢失。
- Sink任务必须能够在进程失败后恢复事务(持久化事务至检查点)。
- 提交事务必须是幂等操作。也就是说,事务的重复提交应该是无效的。