从现在开始,我们来讨论redis集群的问题,在前面我们介绍了RDB和AOF两种同步机制,那你是否考虑过这两个机制有什么用呢?其中的一个重要作用就是为了集群同步设计的。
Redis是一个高性能的键值存储系统,广泛应用于Web应用、缓存、消息队列等领域。在实际应用中,为了保证Redis的高可用性,通常需要使用主从复制来进行数据备份和故障转移。本文将介绍Redis主从复制的概念、原理和实现方式,以及主从复制中的一些问题和解决方案。
1.主从配置实战
Redis支持集群的架构,集群的节点有主节点和从节点之分。主节点叫master,从节点叫slave。slave会通过复制的技术,自动同步master的数据。
redis】配置主从非常简单 ,只要在配置文件里增加一行即可,例如如果是一主多从,186是主结点,在每个slave结点的redis.conf配置文件增加一行即可:
replicaof 127.0.0.1 6379从节点启动之后,会自动连接到master结点,开始同步数据。如果master结点变了,比如宕机了,选举出了新的master,则这个配置会被重写。
当然我们也可以在执行命令中增加参数的方式来配置,这个就不赘述了。
一个从结点也可以是其他结点的主结点,从而形成级联复制的关系。如果想看集群的状态,可以使用如下命令:
info replication需要注意的是,从结点是只读的,不能执行写操作,否则会报错
在主几点写入后,slave会自动从master同步数据。
如果小弟想单飞了怎么办?也可以通过一行命令搞定:
slaveof no one此时结点会变成自己的主节点,不再复制数据。
2.主从复制的原理
主从复制就是指将一个Redis实例(主服务器)的数据复制到其他Redis实例(从服务器)的过程。主服务器将自己的数据变化通过网络发送给从服务器,从服务器接收到数据后进行更新,从而保证从服务器的数据和主服务器的数据保持一致。主从复制可以实现数据备份、故障转移和读写分离等功能。
主从复制分为全量复制和增量复制两种方式。全量复制是指从主服务器将整个数据集发送到从服务器,而增量复制则是指只发送主服务器的增量变化数据到从服务器。
整个过程其实不复杂,至少比Mysql要容易一些的,在网上找到一张不错的图,已经说得很清楚了:
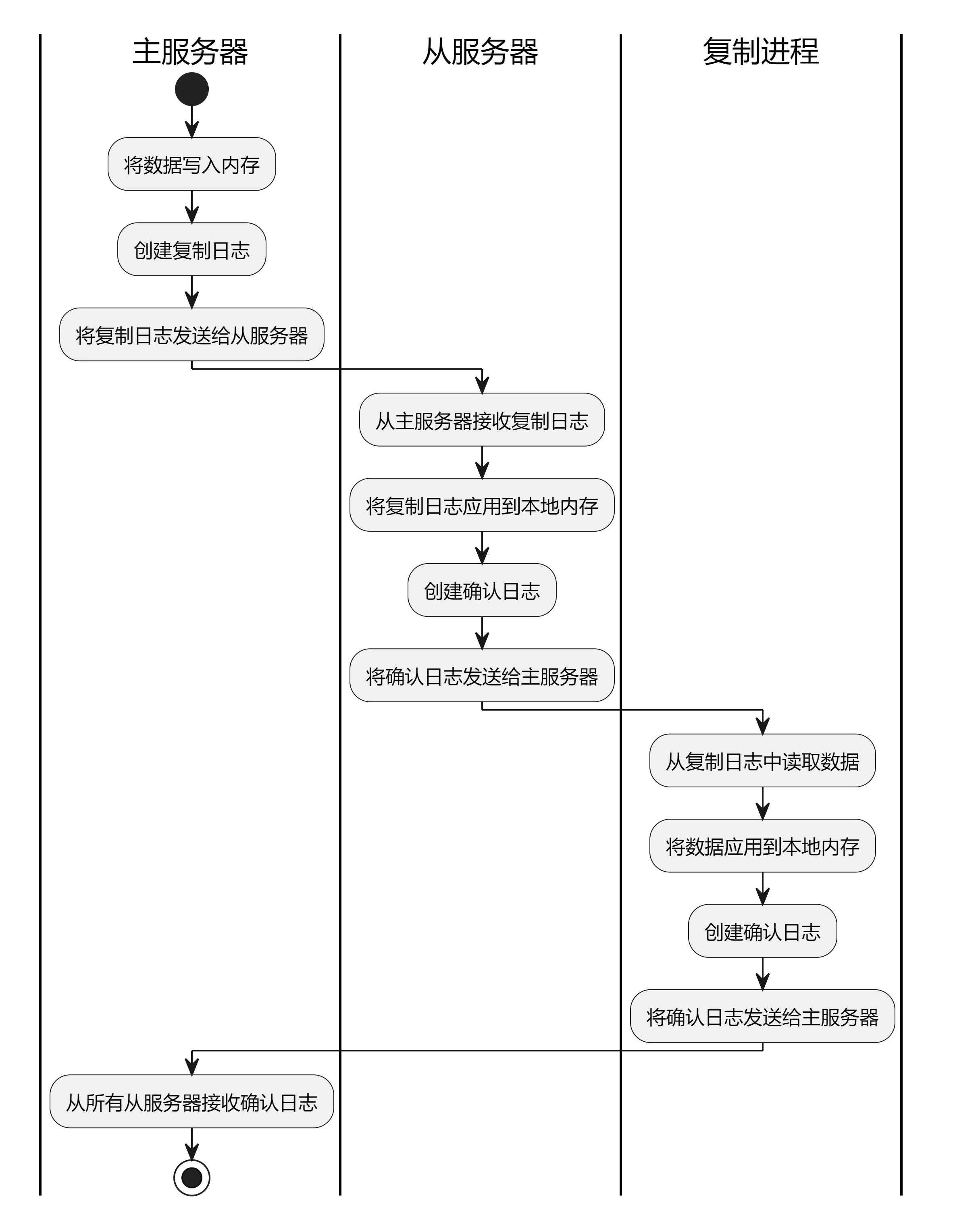
2.1 全量复制
全量复制的流程如下:
- (1)从服务器向主服务器发送SYNC命令,请求进行复制。
- (2)主服务器接收到SYNC命令后,创建一个RDB文件,将当前的数据集保存到RDB文件中,并向从服务器发送RDB文件。
- (3)从服务器接收到RDB文件后,将其保存到本地,并加载到内存中。
- (4)主服务器将从SYNC命令到复制完成期间的所有写命令记录到内存缓冲区中,并在复制完成后将这些写命令发送给从服务器。
- (5)从服务器接收到写命令后,执行这些命令,更新自己的数据集。
我们再图示一下:
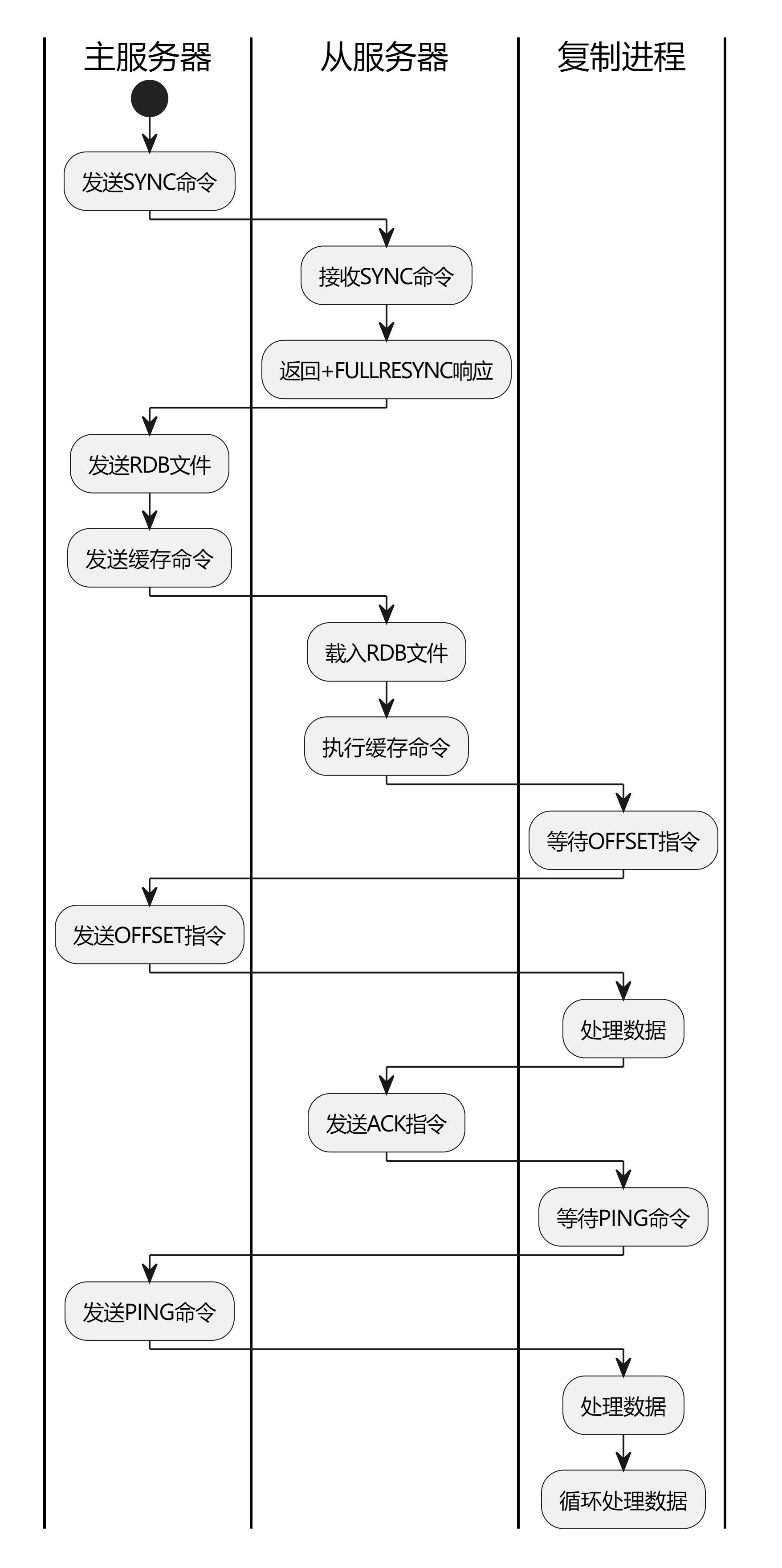
2.2 增量复制
增量复制的流程如下:
- (1)从服务器向主服务器发送PSYNC命令,请求进行复制。
- (2)主服务器记录从服务器复制的偏移量,并将从这个偏移量开始的所有写命令发送给从服务器。
- (3)从服务器接收到写命令后,执行这些命令,更新自己的数据集。
我们看下面的图,更直观的理解一下:
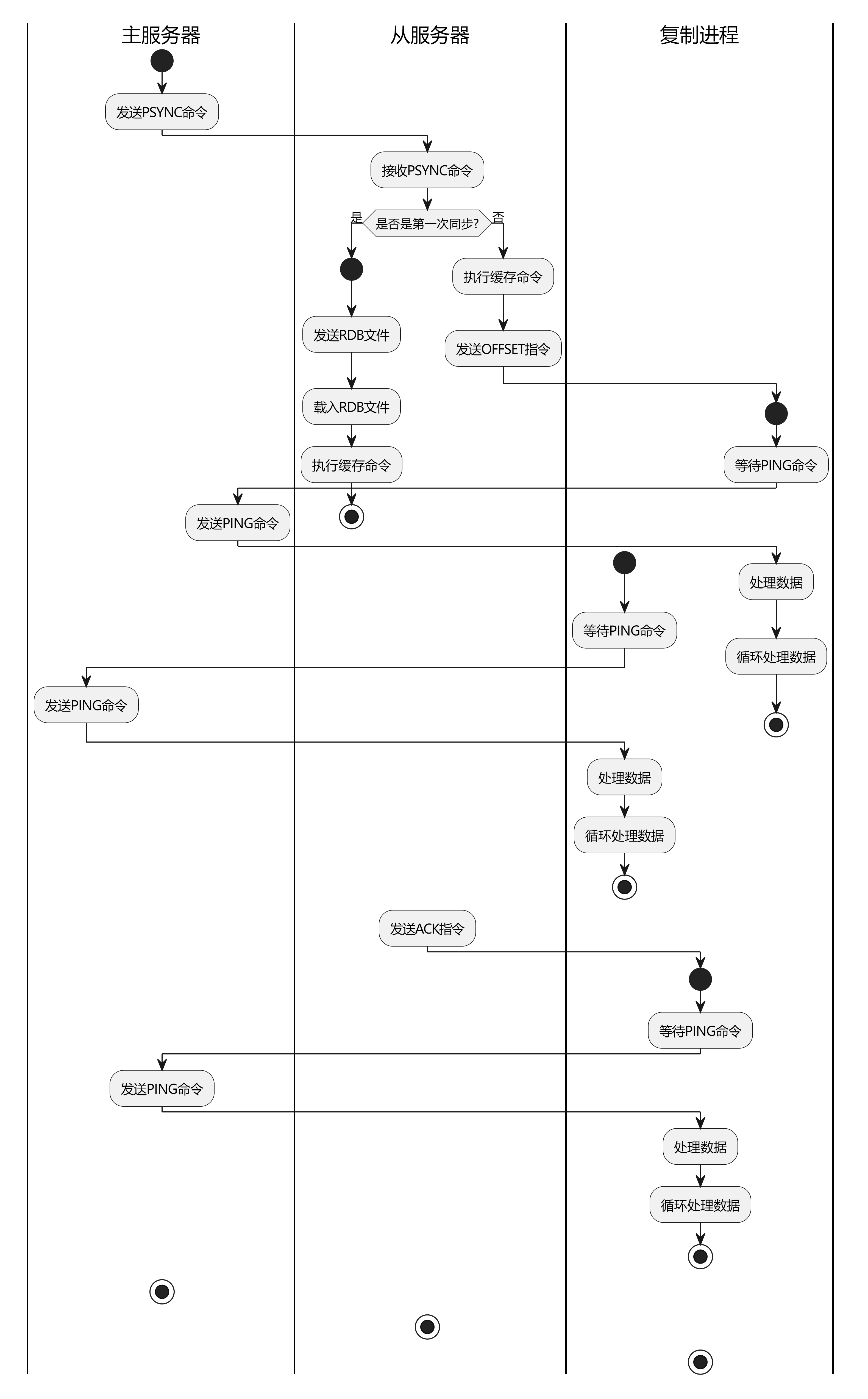
首先,从服务器向主服务器发送PSYNC命令,请求进行复制。PSYNC命令包含两个参数:一个是复制的标识符,用于标识从服务器当前的复制状态;另一个是复制的偏移量,用于指定从哪个位置开始进行复制。在PSYNC命令中,如果标识符为0,表示从服务器是第一次进行复制,主服务器会进行全量复制;如果标识符不为0,表示从服务器已经进行过复制,主服务器会根据标识符和偏移量进行增量复制。
接下来,主服务器记录从服务器复制的偏移量,并将从这个偏移量开始的所有写命令发送给从服务器。主服务器在记录从服务器复制的偏移量时,有两个偏移量需要记录:一个是主服务器最后一次执行的命令的偏移量,另一个是主服务器最后一次执行的命令的复制偏移量。主服务器会将这两个偏移量发送给从服务器,从服务器接收后将其存储在自己的内存中。
从服务器接收到写命令后,执行这些命令,更新自己的数据集。在执行写命令期间,从服务器会不断地将执行的命令的偏移量发送给主服务器,以便主服务器随时记录从服务器的复制进度。此外,如果从服务器在执行写命令时发生了错误,主服务器会根据之前记录的复制进度,重新发送最近的命令,以保证主从数据的一致性。
需要注意的是,增量复制的过程中可能会出现延迟,这是因为主服务器需要缓存一定数量的写命令才会一次性发送给从服务器。如果从服务器在一段时间内没有接收到新的写命令,就会认为主服务器已经断开连接或者出现了故障,从而触发故障转移。此外,增量复制也可能出现主从数据不一致的情况,比如主从服务器之间的网络延迟、主从服务器的时钟不同步等问题。为了避免这些问题,我们需要采用一些额外的措施,如定期检查主从数据的一致性、使用时间戳和序列号等方式保证主从服务器的时钟同步等。
3.主从复制的进一步讨论与常见面试题
在上面的过程中还有不少问题需要进一步研究的,这里我们搜集了几个一起来一下:
3.1. 数据不一致
读写分离会将读操作和写操作分别发送到不同的Redis实例上,因此在进行写操作后,从库的数据不一定会立即更新,可能会存在一定的延迟。如果在这段延迟期间进行读操作,就会读取到旧的数据,导致数据不一致的问题。
解决方案
可以采用同步延迟、异步延迟、写完立即读、延迟刷新等策略,例如在写入数据后,通过命令等待从库同步完成后再进行读取操作;或者采用写完立即读的方式,即在写入数据后马上进行读取操作,保证数据的一致性;还可以定期刷新从库的数据,避免数据延迟过大。
3.2. 延迟问题
由于网络传输、数据同步等原因,从库的数据更新可能会存在一定的延迟,导致在进行读取操作时出现延迟问题,影响系统的性能和用户体验。
解决方案:可以采用主动刷新、被动刷新等策略,例如定期刷新从库的数据、在从库中设置较短的超时时间等,以保证数据的及时性和准确性。
3.3. 安全性问题
通常情况下从库的安全性其实也要很高,包括数据安全和环境安全。如果从库磁盘损坏也是会影响业务。如果从库被攻击,可能会导致主库的数据泄露,或者被篡改。因此需要采用一些安全措施来保证redis服务的存储安全和环境安全性。
解决方案
可以采用SSL加密、访问控制、数据加密等策略,例如使用SSL协议来保证数据传输的安全,或者在从库上设置密码、限制访问IP等来保证系统的安全性。
3.4. 故障切换问题
当主库出现故障时,需要将从库切换为新的主库,以确保系统的正常运行。但是,在进行切换时可能会存在数据不一致、丢失数据等问题。
解决方案
可以采用哨兵模式或者集群模式来实现故障切换(这个我们后续章节详细讲解),例如哨兵模式可以使用多个监控节点来监测主库的状态,并在主库出现故障时自动切换到从库;集群模式可以使用多个节点来实现数据的分布式存储,从而提高系统的可靠性和容错能力。
3.5. 延迟与不一致问题
在进行读写分离时,由于数据同步的延迟,可能会存在从库中数据不一致的问题,影响系统的性能和用户体验。
解决方案
这个只能是相对的解决方案,延迟是无法避免,这是由设计决定的。可以采用数据同步机制来避免延迟和数据不一致问题,例如使用增量复制机制来加快数据同步速度;或者在从库中使用缓存机制来减少读取延迟等,以提高系统的性能和可靠性。
3.6.当主服务器不进行持久化时复制的安全性
在主从复制中,当主服务器不进行持久化时,复制的安全性会受到影响。因为如果主服务器在发送数据之前崩溃,从服务器可能会丢失一些数据,从而导致数据不一致。因此,在使用主从复制时,最好将主服务器进行持久化。
3.7.为什么主从全量复制使用RDB而不使用AOF?
主从全量复制使用RDB而不使用AOF的原因是因为RDB文件是一个快照,包含了Redis实例的整个数据集,它可以很快地恢复Redis实例的数据,而AOF文件只记录了Redis实例的增量操作,恢复数据需要重新执行所有操作,速度较慢。
3.8. 为什么还有无磁盘复制模式?
无磁盘复制模式是指从服务器不需要将主服务器的数据保存到本地磁盘上,而是直接将数据保存到内存中,这样可以减少磁盘I/O的开销,提高复制效率。但是,由于从服务器不进行持久化,如果从服务器崩溃或者重启,数据可能会丢失。
3.9. 为什么还会有从库的从库的设计?
从库的从库设计是为了实现更高的可用性和更好的性能。将从服务器作为主服务器的从服务器,可以构建一个多层级的主从架构,从而提高系统的容错能力和性能。
4.总结
读写分离需要注意解决故障切换、数据过期、延迟和不一致等问题,以保证系统的稳定性和可靠性。
在实际应用中,主从复制是保证高可用性的重要手段之一。了解Redis主从复制的原理和实现方式,可以帮助我们更好地搭建和维护Redis集群,提高系统的稳定性和可靠性。
不过主从复制的弊端是仍然只有一个能写,其他的主要扛读的高并发问题,假如频繁写的场景,此时仍然会有瓶颈,因此读写分离适合并发强度并不是很高的场景。如果真的要应对大规模读写的问题,我们需要建立更严格的redis集群,这个我们下一篇继续介绍。
![服务器感染了.wis[[Rast@airmail.cc]].wis勒索病毒,如何确保数据文件完整恢复?](https://img-blog.csdnimg.cn/direct/4da95382d71b426a8f9686cc1ac31fb1.png)