如何使用 Navicat 新建 MySQL 数据库,并选择字符集与排序规则
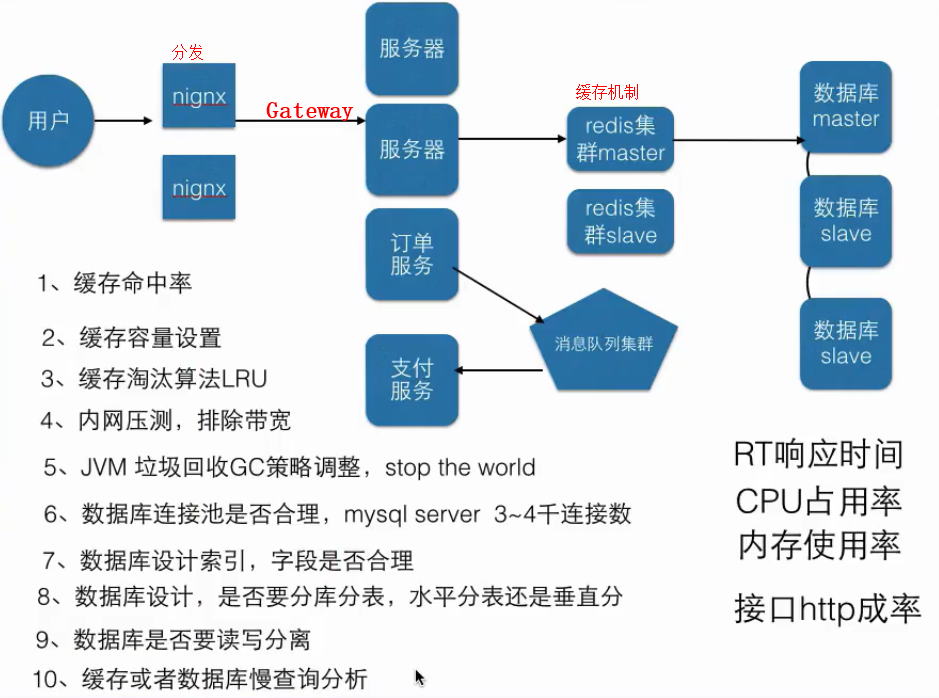
- 如何使用 Navicat 新建 MySQL 数据库并选择字符集与排序规则
- 1. 开始之前
- 2. 新建数据库
- 步骤 1: 打开 Navicat
- 步骤 2: 创建新数据库
- 步骤 3: 填写数据库名称
- 常见的字符集和排序规则及其选择场景
- 1. 字符集(Character Sets)
- UTF-8 / UTF8MB4
- Latin1
- ASCII
- 2. 排序规则(Collations)
- utf8_bin
- utf8_general_ci
- 其他相关排序规则
- utf8mb4_unicode_ci / utf8mb4_general_ci
- utf8_general_cs
- utf8_unicode_ci
- latin1_swedish_ci
- binary
- 小结
- 3. 选择字符集和排序规则
- 字符集(Character Set)
- 排序规则(Collation)
- 步骤 4: 选择字符集和排序规则
- 4. 完成创建
- 5. 验证数据库
- 结论

如何使用 Navicat 新建 MySQL 数据库并选择字符集与排序规则
在数据库管理和开发中,Navicat 是一个强大且用户友好的图形界面工具,它支持多种数据库系统,包括 MySQL。本文将指导您如何使用 Navicat 新建 MySQL 数据库,并着重介绍如何选择合适的字符集和排序规则。
1. 开始之前
确保您已经安装了 Navicat 和 MySQL 服务器,并且能够在 Navicat 中成功连接到您的 MySQL 服务器。如果您是第一次使用 Navicat,您需要创建一个新的数据库连接,输入数据库的地址、端口、用户名和密码。
2. 新建数据库
步骤 1: 打开 Navicat
启动 Navicat 并连接到您的 MySQL 服务器。
步骤 2: 创建新数据库
在 Navicat 的界面中,右击 MySQL 连接,选择“新建数据库”。这时会弹出一个对话框,让您输入数据库的名称。
步骤 3: 填写数据库名称
在对话框中输入您希望创建的数据库的名称。
常见的字符集和排序规则及其选择场景
在数据库设计中,选择合适的字符集(Character Set)和排序规则(Collation)是至关重要的。这些选择会影响数据的存储、检索以及比较。以下是一些常见的字符集和排序规则,以及它们的适用场景。
1. 字符集(Character Sets)
UTF-8 / UTF8MB4
- 描述: UTF-8 是一种针对 Unicode 的可变长度字符编码,而 UTF8MB4 是 UTF-8 的超集,支持更多的字符,包括表情符号。
- 适用场景: 当您的应用需要支持多种语言或特殊字符(如表情符号)时,UTF8MB4 是最佳选择。它是MySQL推荐的字符集。
Latin1
- 描述: Latin1(或称为 ISO 8859-1)是一种单字节字符集,支持西欧语言。
- 适用场景: 如果您的数据主要是英文或西欧语言,并且不包含特殊字符或表情符号,Latin1 是一个轻量且高效的选择。
ASCII
- 描述: ASCII 是最基本的字符编码,只支持英文字符和一些基本符号。
- 适用场景: 当您的数据仅包含基本的英文字符和符号时,ASCII 是足够的。这通常适用于一些非常特定和受限的应用场景。
2. 排序规则(Collations)
例如,当你运行:
SELECT * FROM table WHERE txt = 'a'
在讨论数据库字符集和排序规则时,理解不同类型的排序规则及其适用场景是非常重要的。以下是针对 MySQL 的 UTF-8 字符集的两种常见排序规则的优化格式说明:
utf8_bin
- 特性: 在
utf8_bin排序规则中,字符串是通过二进制数据进行编译和存储的。 - 大小写区分: 是。在这种排序规则下,
a和A被视为不同的字符。 - 适用场景: 当您需要严格区分大小写或者需要存储二进制内容时。例如,如果您有一个字段需要确切地区分大小写,如密码字段,使用
utf8_bin是一个合适的选择。
utf8_general_ci
- 特性:
utf8_general_ci是一种不区分大小写的排序规则。它在比较字符串时,不会区分字符的大小写。 - 大小写区分: 否。在这种排序规则下,
a和A被视为相同的字符。 - 适用场景: 这个排序规则适用于那些不需要区分大小写的场景,如用户登录时的用户名或邮箱地址。使用
utf8_general_ci可以确保即使用户在输入时改变了字母的大小写,仍然能够被正确地识别。
其他相关排序规则
utf8mb4_unicode_ci / utf8mb4_general_ci
- 描述: 这些排序规则用于 UTF8MB4 字符集。
ci表示不区分大小写(case-insensitive)。 - 区别:
utf8mb4_unicode_ci基于标准的 Unicode 来排序,而utf8mb4_general_ci是一种性能更优的简化排序算法。 - 适用场景: 当您需要确保在多种语言环境下的文本比较和排序的准确性时,
utf8mb4_unicode_ci是更好的选择。如果性能是主要考虑因素,且可以接受稍微粗糙的排序,则可以选择utf8mb4_general_ci。
utf8_general_cs
- 区分大小写: 是。这个规则在处理字符串时会区分大小写,这在某些场景下可能导致问题,尤其是在不应区分大小写的字段(如邮箱地址)中使用时。
utf8_unicode_ci
- 特性:
utf8_unicode_ci在校对时的准确度更高,但速度稍慢。 - 中英文处理: 对中文和英文来说,与
utf8_general_ci没有实质性的差别。 - 选择建议: 如果对准确性有较高要求,可以考虑使用
utf8_unicode_ci。
latin1_swedish_ci
- 描述: 这是 Latin1 字符集的默认排序规则,不区分大小写。
- 适用场景: 主要用于处理西欧语言数据,当使用 Latin1 字符集时,默认会采用此排序规则。
binary
- 描述: 这是一种区分大小写的排序规则,按照字节值进行比较。
- 适用场景: 当您需要严格区分大小写和特殊字符,或者对数据进行精确的字节级比较时,适合选择 binary 排序规则。
小结
在选择字符集和排序规则时,需要考虑数据的类型、语言和特殊需求。通常,UTF8MB4 是现代应用程序的安全选择,因为它支持广泛的字符并提供灵活的排序选项。然而,对于更特定的需求和优化,其他字符集和排序规则可能更为适宜。始终确保您的选择能够支持您的应用现在和未来的需求。
在选择排序规则时,需要考虑应用的具体需求,特别是对大小写的处理以及性能与准确度之间的权衡。通常,utf8_general_ci 因其较快的校对速度和足够的准确度,被广泛用于一般场景。而在需要严格的大小写区分或特殊的数据存储需求时,utf8_bin 或 utf8_unicode_ci 可能是更好的选择。
3. 选择字符集和排序规则
创建数据库的关键部分是选择正确的字符集和排序规则,这将影响数据的存储和检索方式。
字符集(Character Set)
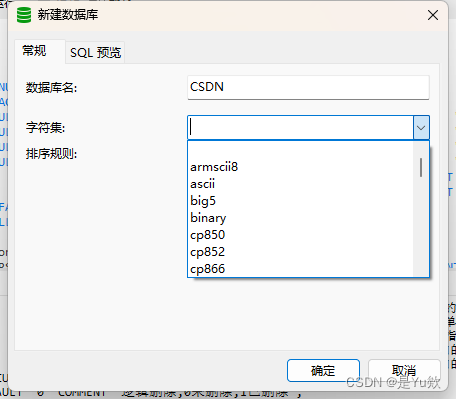
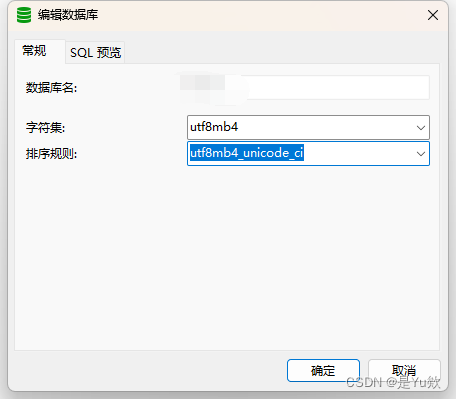
字符集决定了数据库可以存储哪些字符。例如,utf8mb4 是一个流行的选择,它支持包括表情符号在内的几乎所有Unicode字符。
排序规则(Collation)
排序规则定义了字符的比较和排序方式。例如,utf8mb4_unicode_ci 是一种常用的排序规则,它以不区分大小写的方式进行排序。
步骤 4: 选择字符集和排序规则
在新建数据库的对话框中,您会看到字符集和排序规则的选项。从下拉列表中选择最适合您需求的字符集和排序规则。
4. 完成创建
确认无误后,点击“确定”按钮,Navicat 将创建新的数据库,并根据您的选择应用字符集和排序规则。
5. 验证数据库
创建完成后,您可以在 Navicat 的左侧面板中找到新创建的数据库。点击它,您可以查看数据库的属性,确认字符集和排序规则是否正确设置。
结论
使用 Navicat 创建 MySQL 数据库是一个简单直观的过程。选择合适的字符集和排序规则对于确保数据库能够正确处理和存储数据至关重要。通过以上步骤,即使是初学者也可以轻松完成这一过程。记住,根据您的具体需求选择字符集和排序规则,可以避免未来可能遇到的许多问题。