背景
目前大促备战常见备战工作:专项压测(全链路压测、内部压测)、灾备演练、降级演练、限流、巡检(监控、应用健康度)、混沌演练(红蓝对抗),如下图所示。随着平台业务越来越复杂,红蓝对抗的作用愈来愈明显,下面将详细介绍大数据平台在大促备战工作中是如何开展红蓝对抗的。

首先我们先了解一下什么是红蓝对抗,它都有哪些好处?
一、红蓝对抗介绍
红蓝对抗是网络安全领域常见的一种对抗性演练方法,是指为发现并整改企业内外网资产及业务数据深层次安全隐患,在确保业务平稳运行的前提下,整合平台安全威胁监测能力、应急处置能力和防护能力,以真实网络环境开展实兵红蓝对抗演练,提高并完善安全防护技术与管理体系。
蓝方代表攻击方,红方代表防守方。红蓝对抗模拟了真实的网络攻击和防御过程,在受控的环境中进行,蓝方通过模拟各类威胁和攻击手段,对红方进行攻击,测试其防御能力和系统高可用情况。红方则负责防御和应对,寻找并修复系统中的问题,并且收集关于攻击者的信息。

二、红蓝对抗的好处
1.保证监控告警有效性
红蓝对抗可帮助产研验证监控告警的配置有效性,通知及时性,信息准确性。
2.增强系统可靠性
红蓝对抗通过识别可能导致系统发生错误的潜在问题,帮助提高系统的可靠性。
3.降低风险
红蓝对抗通过识别可能被恶意攻击者利用的潜在弱点,帮助降低发生线上问题的相关风险。
4.经济高效的测试
红蓝对抗模拟了生产环境的场景,但却不会对生产环境产生风险,从测试角度来看保障系统的质量。

三、红蓝对抗实践
红蓝对抗演练实践主要包括:演练公告、人员指定与任务分配、演练前场景梳理、红蓝对抗过程、演练结果收集、演练复盘共6个部分。
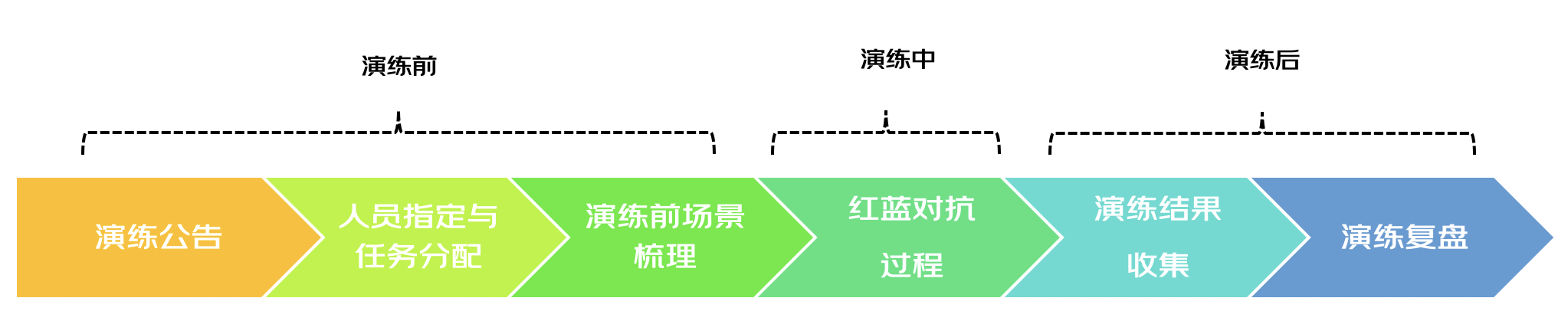
1、演练公告
主要包括两个部分:
第一、本次红蓝对抗主负责人组织对抗演练启动会、确定对抗演练时间范围、指定实时|离线演练接口人。
第二、实时|离线产品提前邮件|咚咚通知业务用户将进行红蓝对抗演练。

2、人员指定与任务分配
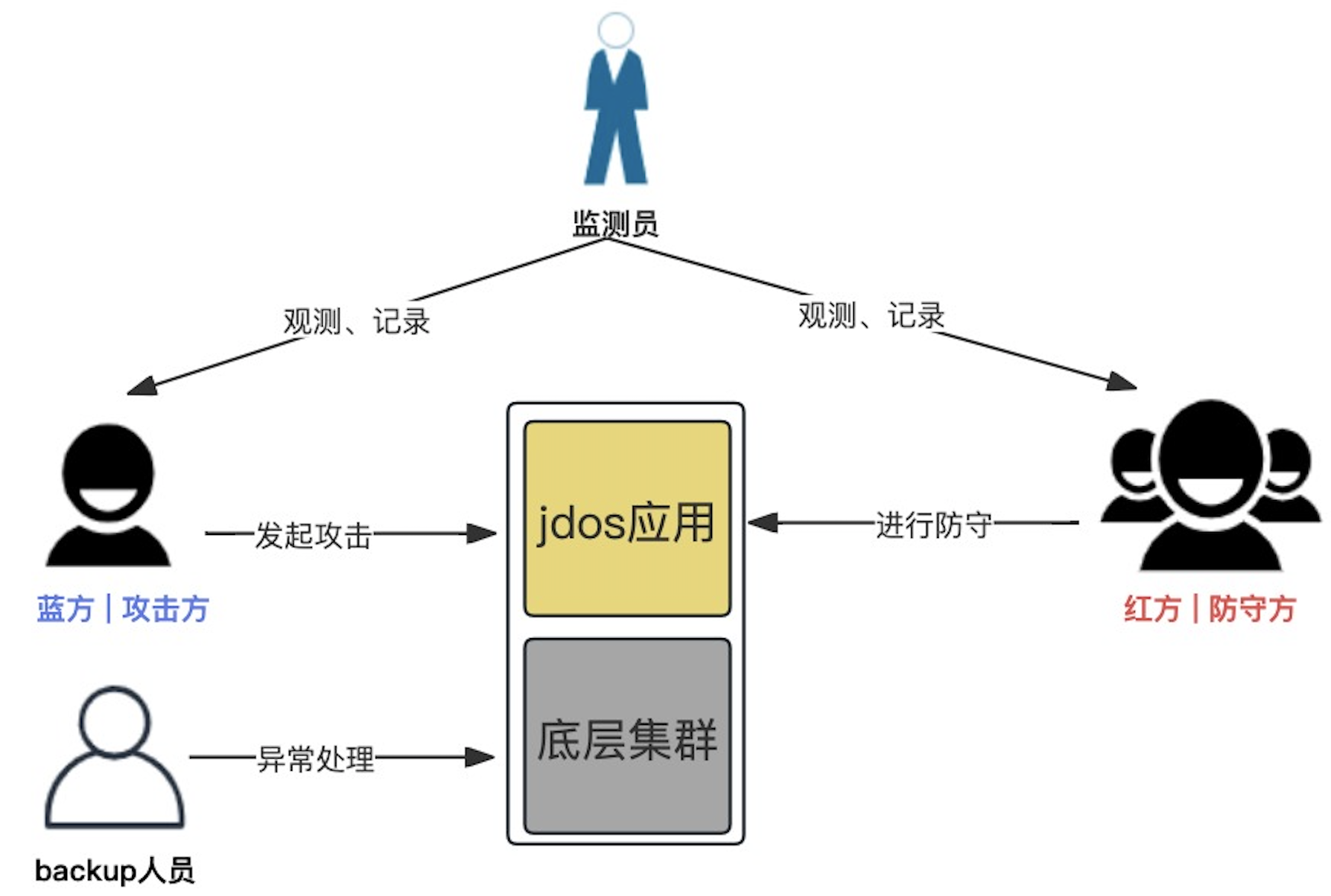
首先,指定本次红蓝对抗的主负责人。负责整个红蓝对抗演练的统筹工作,包括方案制定、演练对抗文档落地、场景收集通知及复核、组织攻击方发起及防守方防御过程、演练复盘工作。
其次,分别指定实时和离线侧备战接口人。充当蓝方攻击方,主要是指定演练攻击场景、发起系统攻击。
再次,分别指定实时和离线侧backup兜底人员。一般为核心研发人员,由于发起攻击的具体时间是不确定,为避免蓝方发起攻击后,红方由于各种特殊原因不能及时处理故障导致影响线上正常业务,backup兜底人员可快速的恢复系统。
最后,分别指定实时和离线侧演练监测员。一般为测试人员,主要是记录演练过程中发出的告警信息(mdc、ump)以及复核演练记录文档。
3、演练前场景收集
该部分是演练前最重要的环节,主要包括确定演练应用范围、确定攻方演练场景。
3.1、确定演练应用范围
演练应用建议优先选取应用等级L0和L1的应用,具体可根据业务需要进行选取。另外,可通过以下两种方式快速查询对应的应用:
http://XXX.jd.com/dashboard/4/node/XXX
http://XXX.jd.com/health
详细演练应用列表由实时|离线接口人(经过C3领导复核通过)提供,输出:攻方批量注入场景收集,

3.2、收集演练故障场景
jdos应用 主要是借助【混沌工程】平台进行故障注入,采用以下演练场景:
cpu使用率高、内存使用率高、磁盘使用率高、网络延迟、网络丢包、进程终止、mysql请求延迟异常、jimdb请求延迟异常等。
底层集群 主要是运维人员通过脚本、命令等方式进行故障注入。主要包括以下演练场景:
数据库实例CPU打高、hdfs队列打满、计算任务pending、RSS集群繁忙、zk节点宕机异常等。
4、红蓝对抗过程
有了演练场景,产品也发送了演练通知邮件后,就可以进行红蓝对抗了。这里要说明几点:
① 不能将具体的攻击时间“透露”给蓝方。
② 建议选择生产环境应用或集群进行攻击,尽可能真实的模拟线上问题。
4.1、【主负责人】演练前通知
主负责人在蓝方攻击方正式演练前提前在群里发消息,模板如下:
@全体成员
【重要通知】
今天17:30~21:30大数据平台(实时+离线)进行红蓝对抗演练,不定时进行故障突袭。请各位同学将跟进处理过程在本群进行同步。 分三个阶段:问题发现、原因分析诊断、故障处理。
每个环节(问题发现、故障诊断、故障处理)确定后立马发消息,不要最后发总结!
每个环节(问题发现、故障诊断、故障处理)确定后立马发消息,不要最后发总结!1、问题发现
【问题发现】
产品-服务名称:
(1)收到电话/咚咚告警,告警内容xxx
或
(2)雷达大屏飘红,截图xx 开始排查处理2、原因分析
【故障诊断】
产品-服务名称:xx问题原因已查到,原因概要描述。3、故障处理
【故障处理】
产品-服务名称::xx问题已处理,已恢复,并给出告警恢复/监控截图。
4.2、【蓝方】创建&执行演练任务
蓝方在混沌工程平台,按照之前收集的演练场景创建演练任务或批量创建演练任务。如下图
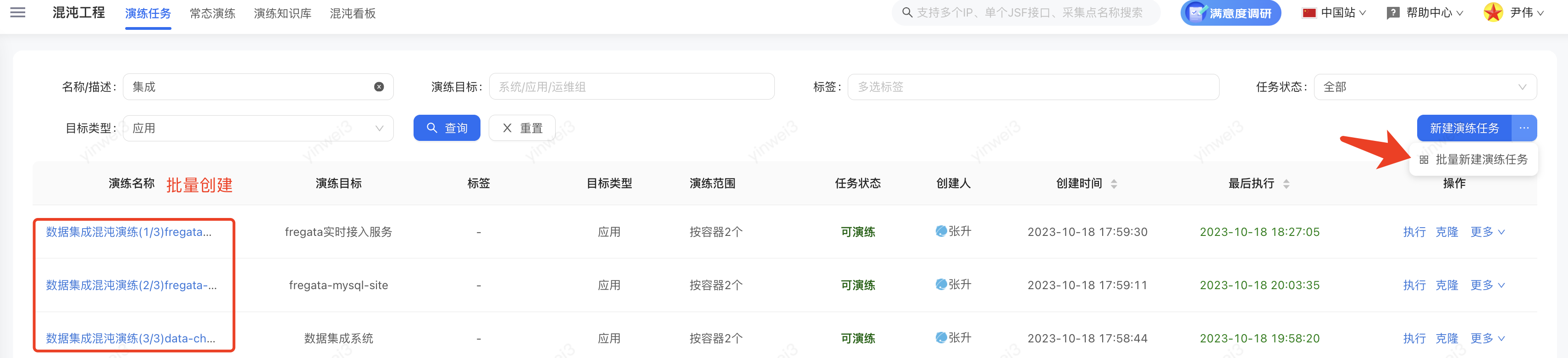
说明以下几点:
① 底层集群的攻击主要通过命令、脚本实现,这里暂不详细叙述。
② 网络延迟、丢包故障可能演练失败,原因:限制网络故障演练(该宿主机内核版本存已知BUG不能演练) “4.18.0-80.11.2.el8_0.x86_64”。
③ 内存利用率100%场景,因为linux内存满了会触发oom kill,所以建议设置90%。
④ 演练时长建议大于5分钟,原因:有些应用配置的mdc报警周期范围是5分钟内,如果演练时长小于5分钟可能收不到报警。
4.3、【红方】防守修复故障
蓝方发起攻击后,红方会收到咚咚报警,按照既定预案进行故障修复。部分截图如下:
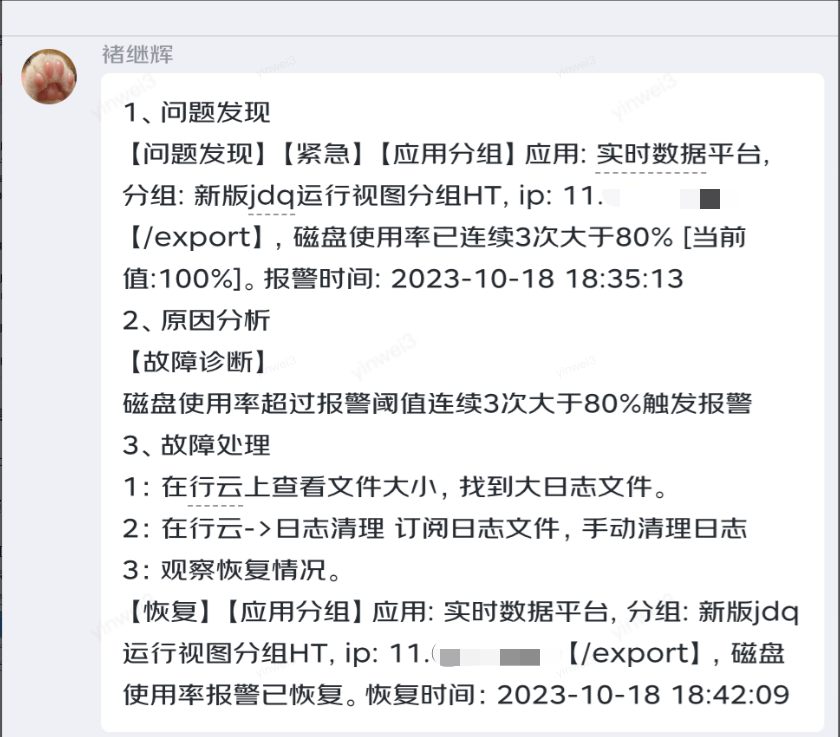
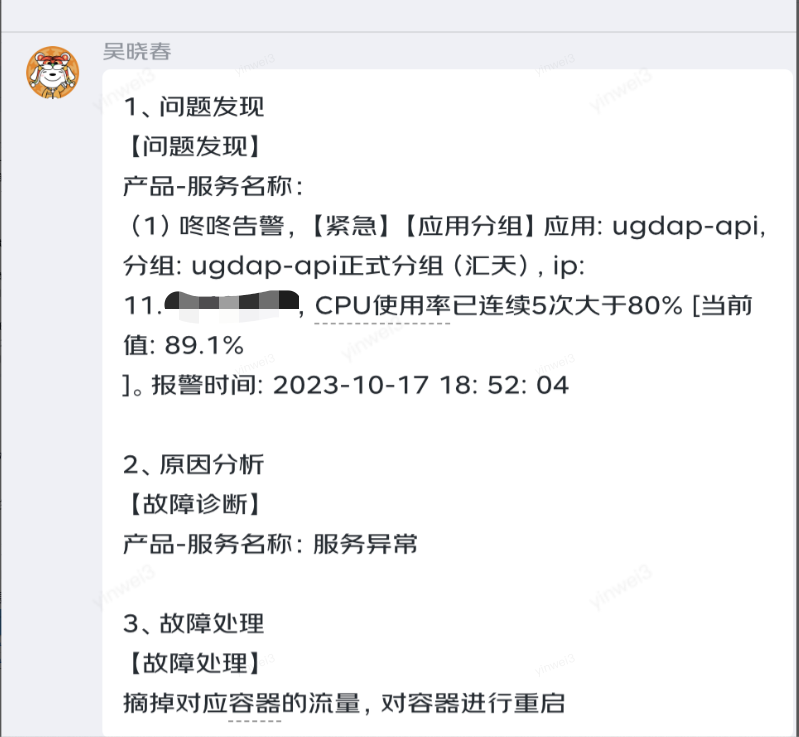
4.4、【红方】系统恢复
有些演练场景(进程终止)不会自动恢复,需要红方手动重启系统应用服务,确保生产应用服务均正常。
4.5、【红方+蓝方】演练结束
红蓝对抗演练结束后,红蓝双方均填写“红蓝对抗演练场景”文档,蓝方填写:混沌任务链接、混沌演练场景、演练状态、混沌演练执行开始时间、混沌演练执行结束时间。红方填写:排查人、告警信息、根因、排查到原因时间、排查过程描述(包含排查过程,使用工具,辅助决策判断)、计划解决方案&应急预案、预估影响 处理时间。如下图所示:

5、演练结果收集主负责人复核演练结果、梳理分离演练问题,让红蓝双方尽早完善。主要存在以下问题:
**1) 未及时处理:**红方收到告警后, 由于种种原因(开会、未在工位等)未及时处理故障。
**2) 处理不完整:**红方处理完ns失败问题后,未通知用户处理失败任务。
3) 未收到报警:
① 未配置报警规则。例,mdc或ump平台未配置报警。
② 未触发告警阈值。例,蓝方攻击时cpu利用率90%但mdc报警规则配置的是95%。
③ mdc平台禁用告警。例,mdc暂时禁用了模版中心的MDC监控与告警。

6、演练复盘
主负责人组织红蓝对抗复盘会议,提供演练结果、问题列表,实时+离线架构师均参加,从演练过程、演练效果等角度对本次演练进行评价或建议。
① 告警级别需要自查修正。目前部分告警级别配置偏低,cpu利用率大于90%时,报【警告】,建议改为【紧急】。
② 延长攻击时间。找某几个应用,攻击时间为30+分钟,验证防守人员是否真正摘流量。
③ 混沌演练常态化。可通过混沌工程平台-常态演练进行,并结合值班表增加演练频次,以战养兵。
④ 分步演练【警告】、【紧急】场景。第一步先攻击10分钟触发【警告】的场景,第二步再攻击10分钟触发【紧急】的场景。
⑤ java方法异常、延迟场景未演练。后续期望测试人员通过forcebot压测来支持流量流入。
期望混沌平台的支持:
① 混沌工程平台支持一次批量选择多个应用创建、启停混沌演练任务。 可提高创建任务效率,目前的批量创建演练任务功能,只能一个一个的添加应用进行创建。
② 混沌工程平台提供常态化混沌演练api。方便用户自定义创建常态化演练任务。
③ 混沌工程平台支持在平台内查看mdc、ump告警。减少用户在多个平台系统来回切换。
四、总结
通过本次红蓝对抗演练,既有效的增强了大数据平台系统应用的抗风险能力,降低了生产环境系统发生故障的概率,又大大的提升了研发人员解决问题故障的能力,也沉淀了一套快速高效的演练的方案。
作者:京东零售 尹伟
来源:京东云开发者社区 转载请注明来源



![[极客大挑战 2019]LoveSQL1](https://img-blog.csdnimg.cn/direct/28129c907eb94c789e119067bbc1d049.png)







![【C++入门到精通】智能指针 shared_ptr循环引用 | weak_ptr 简介及C++模拟实现 [ C++入门 ]](https://img-blog.csdnimg.cn/direct/ad0cc2887ce140ed8f11e8276788b498.png#pic_center)