| 32.文献阅读笔记 | ||
| 简介 | 题目 | Flowing convnets for human pose estimation in videos |
| 作者 | Tomas Pfister, James Charles, and Andrew Zisserman, ICCV, 2015. | |
| 原文链接 | https://arxiv.org/pdf/1506.02897.pdf | |
| 关键词 | Human Pose Estimation in Videos | |
| 研究问题 | 视频中的人体姿态估计 | |
| 研究方法 | 总体流程如下: 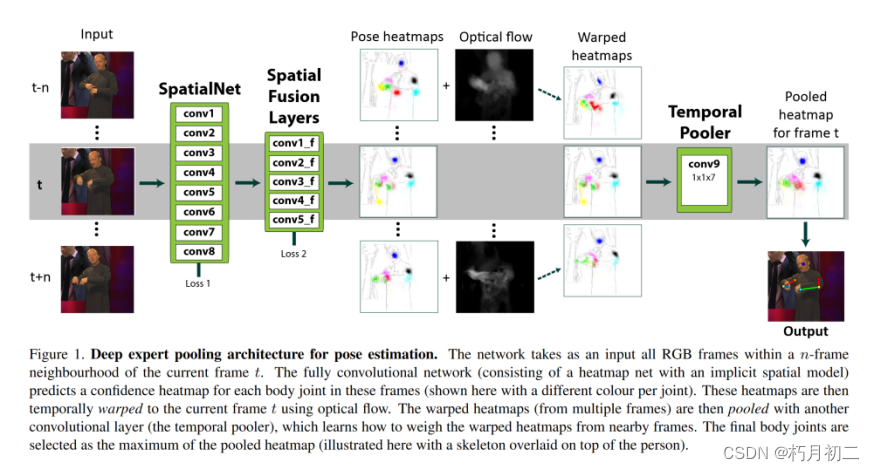 一、使用光流将多帧信息结合起来,从而从时间上下文中获益。 输入t以及其前后n帧rgb图片,相邻帧的热图可以使用光流进行扭曲和对齐,从而有效地在时间上传播位置信息。离t帧越远的帧权重越低。  邻近帧作为强有力的 "专家意见",通过端对端反向传播来学习专家池权重。 分别回归输入图像中每个关节的关节位置热图。该热图(最后一个卷积层 conv8 的输出)是一个固定大小的 i × j × k 维立方体(此处为 64 × 64 × 7,表示 k = 7 个上半身关节)。在训练时,通过在ground truth关节位置放置一个方差固定的高斯,为每个关节分别合成ground truth标签热图 l2 loss:对predicted heatmap and the synthesised(合成) ground truth heatmap.之间的像素平方差进行惩罚 回归热图而不是(x, y)坐标的好处:可以理解失败并直观地看到网络的 "思考过程";由于设计上允许网络的输出是多模态的,即允许在多个空间位置有置信度,因此学习变得更加容易:在训练的早期,一个给定的关节可能会在多个位置发生反应;随着训练的进行,错误的反应会慢慢被抑制。相反,如果输出只有手腕(x,y)坐标,那么网络只有在预测正确时才会有较低的损失(即使它对正确的位置 "越来越有信心")。 提高热图的空间分辨率:(i) 使用最小池化(只有两个 2 × 2 最大池化层);(ii) 所有步长都是统一的(这样分辨率就不会降低)。除 conv9(池化层)外,所有层后都有 ReLU。 卷积层代替全连接层 二、在初始热图之外增加卷积层,以学习人体布局的隐式空间模型。这些层能够学习人体各部位之间的依赖关系。这些 "空间融合 "层可以消除运动学上无法实现的姿势估计失败。 学习关节的空间依赖关系:Spatial fusion layers (conv7)作为输入,学习人体位置之间的依赖关系,将 conv7 和 conv3(跳转层)的连接作为输入,并通过另外五个带有 ReLU 的卷积层进行反馈,大内核用于扩大网络的感受野。在该网络的末端附加了一个单独的损失层,并在整个网络中进行反向传播。 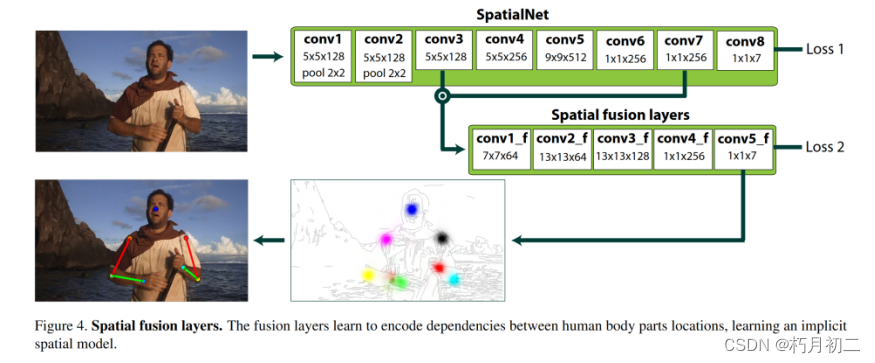 | |
| 研究结论 | 在“野外数据集”上表现远优于目前技术水平。 | |
| 创新不足 | 未涉及多人检测,只检测人物上半身 | |
| 额外知识 | 光流:计算机视觉--光流法(optical flow)简介-CSDN博客 是空间运动物体在观察成像平面上的像素运动的瞬时速度。 光流计算使用FastDeepFlow | |
(论文阅读32/100)Flowing convnets for human pose estimation in videos
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/192561.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

挂耳式运动耳机哪个品牌好?5款公认好用的运动耳机推荐
在现代社会,耳机已经成为了人们生活中必不可少的数码设备。在运动的时候,佩戴耳机更是成为了很多人的标配。但是,市面上的运动耳机种类繁多,如何选择一款适合自己的呢?今天我为大家挑选了5款公认好用的运动耳机&…

PyTorch技术和深度学习——四、神经网络训练与优化
文章目录 1.神经网络迭代概念1)训练误差与泛化误差2)训练集、验证集和测试集划分3)偏差与方差 2.正则化方法1)提前终止2)L2正则化3)Dropout 3.优化算法1)梯度下降2)Momentum算法3)RM…
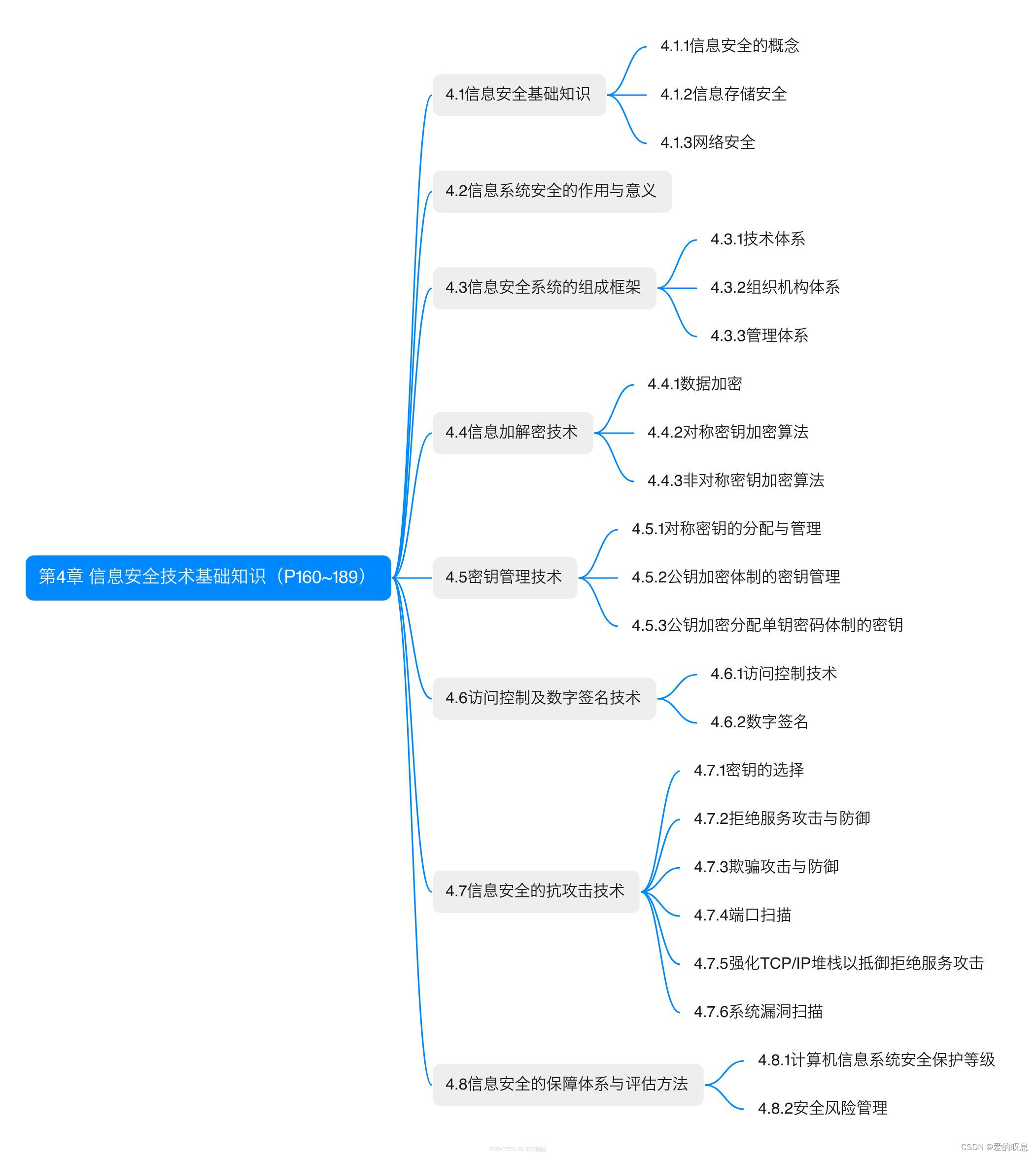
软考-高级-系统架构设计师教程(清华第2版)【第4章 信息安全技术基础知识(P160~189)-思维导图】
软考-高级-系统架构设计师教程(清华第2版)【第4章 信息安全技术基础知识(P160~189)-思维导图】
课本里章节里所有蓝色字体的思维导图
LeetCode(10)跳跃游戏 II【数组/字符串】【中等】
目录 1.题目2.答案3.提交结果截图 链接: 45. 跳跃游戏 II 1.题目
给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。
每个元素 nums[i] 表示从索引 i 向前跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nu…
机器学习-搜索技术:从技术发展到应用实战的全面指南
在本文中,我们全面探讨了人工智能中搜索技术的发展,从基础算法如DFS和BFS,到高级搜索技术如CSP和优化问题的解决方案,进而探索了机器学习与搜索的融合,最后展望了未来的趋势和挑战,提供了对AI搜索技术深刻的…

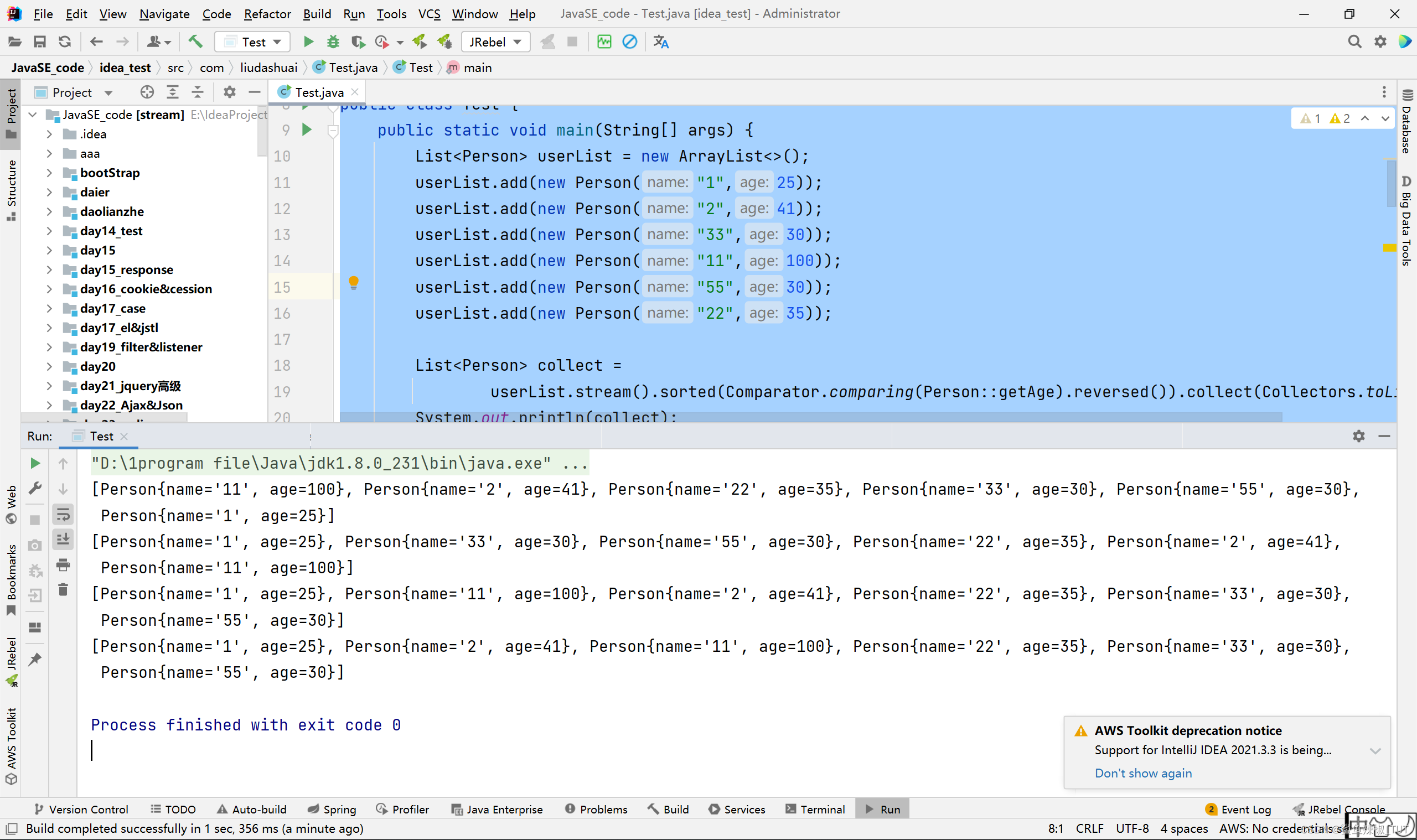
Java Stream 的常用API
Java Stream 的常用API
遍历(forEach)
package com.liudashuai;import java.util.ArrayList;
import java.util.List;public class Test {public static void main(String[] args) {List<Person> userList new ArrayList<>();userList.ad…

可视化技术专栏100例教程导航帖—学习可视化技术的指南宝典
🎉🎊🎉 你的技术旅程将在这里启航! 🚀🚀 本文专栏:可视化技术专栏100例 可视化技术专栏100例领略各种先进的可视化技术,包括但不限于大屏可视化、图表可视化等等。订阅专栏用户在文章…

Stable Diffusion 是否使用 GPU?
在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 3D数字孪生场景编辑器 Stable Diffusion 已迅速成为最流行的生成式 AI 工具之一,用于通过文本到图像扩散模型创建图像。但是,它需…

解决:element ui表格表头自定义输入框单元格el-input不能输入问题
表格表头如图所示,有 40-45,45-50 数据,且以输入框形式呈现,现想修改其数据或点击右侧加号增加新数据编辑。结果不能输入,部分代码如下
<template v-if"columnData.length > 0"><el-table-colu…
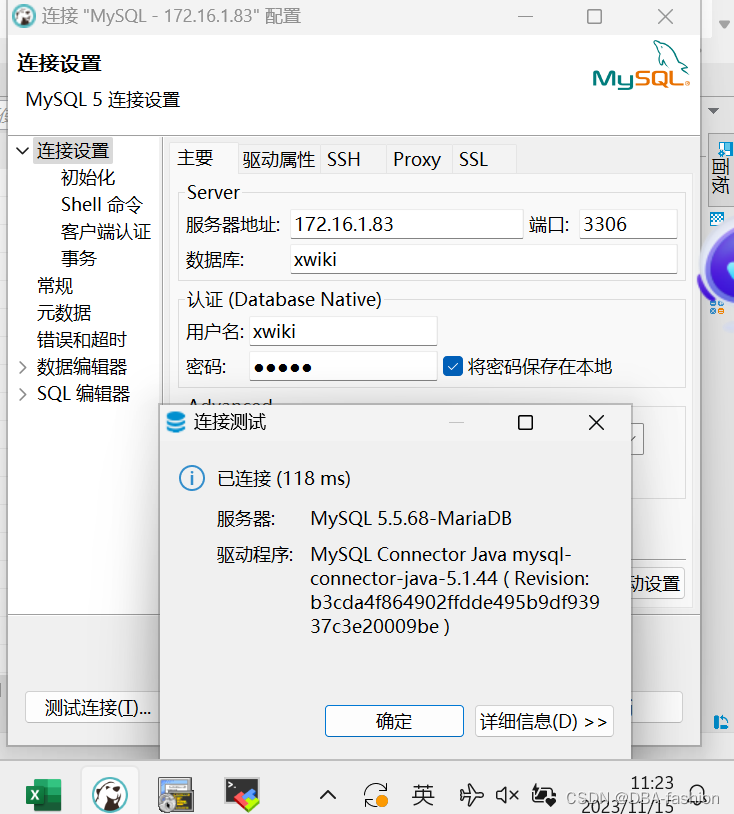
一则DNS被重定向导致无法获取MySQL连接处理
同事反馈xwik应用端报java exception 获取MySQL连接超时无法连接到数据库实例 经过告警日志发现访问进来的IP地址数据库端无法被解析,这里可以知道问题出现在Dns配置上了 通过以上报错检查/etc/resolve.conf 发现namesever 被重定向设置成了114.114.114.114 域名 …

Zigbee智能家居方案设计
背景
目前智能家居物联网中最流行的三种通信协议,Zigbee、WiFi以及BLE(蓝牙)。这三种协议各有各的优势和劣势。本方案基于CC2530芯片来设计,CC2530是TI的Zigbee芯片。 网关使用了ESP8266CC2530。
硬件实物 节点板子上带有继电器…

java,springboot钉钉开发连接器,自定义连接器配合流程使用,流程加入连接器,连接器发送参数,然后你本地处理修改值,返回给流程
1.绘制连接器,注意出餐入参的格式,
2.绘制流程,绑定连接器,是提交后出发还是表单值变化后
3.编写本地接口(内网穿透),绑定连接器 钉钉开发连接器,自定义连接器配合流程使用&#x…
学【Java多态】-- 写高质量代码
多态的实现条件
在java中要实现,必须要满足如下几个条件,缺一不可。
1.必须在继承体系下2.子类必须要对父类中的方法进行重写3.通过父类的引用调用冲写的方法。 想要真正的学好多态需要去学习一些前置知识,那我们直接开始吧!
…
Sealos 云操作系统一键集成 runwasi,解锁 Wasm 的无限潜力
WebAssembly (通常缩写为 Wasm) 是一种为网络浏览器设计的低级编程语言。它旨在提供一种比传统的 JavaScript 更快、更高效的方式来执行代码,以弥补 JavaScript 在性能方面的不足。通过使用二进制格式,WebAssembly 能够提供比传统 JavaScript 更快的解析…

基于态、势、感、知的人机协同机理
基于态、势、感、知的人机协同机理是一种以人类的状态、动机、感觉和知觉为基础,与机器系统进行协同合作的机理。这种机理将人类的主观算计能力与机器系统的客观计算功能相结合,以实现更加智能、自适应和人性化的人机协同。下面是对基于态、势、感、知的…

防爆五参数气象仪的科技力量
WX-FBQ2 随着科技的不断进步,气象监测设备也在不断升级和完善。
防爆五参数气象仪是一种可以同时监测温度、湿度、压力、风速和风向五个基本气象参数的仪器。它采用了气象监测技术,不仅可以实时监测气象数据,还可以对数据进行分析和处理。
…
推荐文章
- ElasticSearch
- time --- 时间的访问和转换
- 软考-高级-系统架构设计师教程(清华第2版)【第2章 计算机系统基础知识-思维导图】
- # RocketMQ 实战:模拟电商网站场景综合案例(六)
- (C++)复原IP地址
- (leetcode学习)50. Pow(x, n)
- (Note)机器学习面试题
- (笔记六)利用opencv进行图像滤波
- (补)算法刷题Day19:BM55 没有重复项数字的全排列
- (代码详解)饼图绘制+参数讲解+饼图内外标签字体大小设置+添加图例,并调整图例大小与位置+调整标题与图之间的距离
- (论文阅读13/100)R-CNN minus R
- (四)关系模型之关系代数