数据湖技术有较多的应用场景,本篇文章是针对一些典型的痛点场景做了一些介绍和说明。比如说在线数据抽取场景原有模式对线上库表产生较大压力,flink多流join维护的大状态导致的稳定性问题等等,具体场景如下图所示:

场景1:在线数据抽取
业务一般会从线上mysql库表以离线方式抽取全量数据到hive表,供下游业务进行相关关联查询等处理,一般每天周期抽取数据后会放置到hive表的T+1分区上,整体流程如下图所示: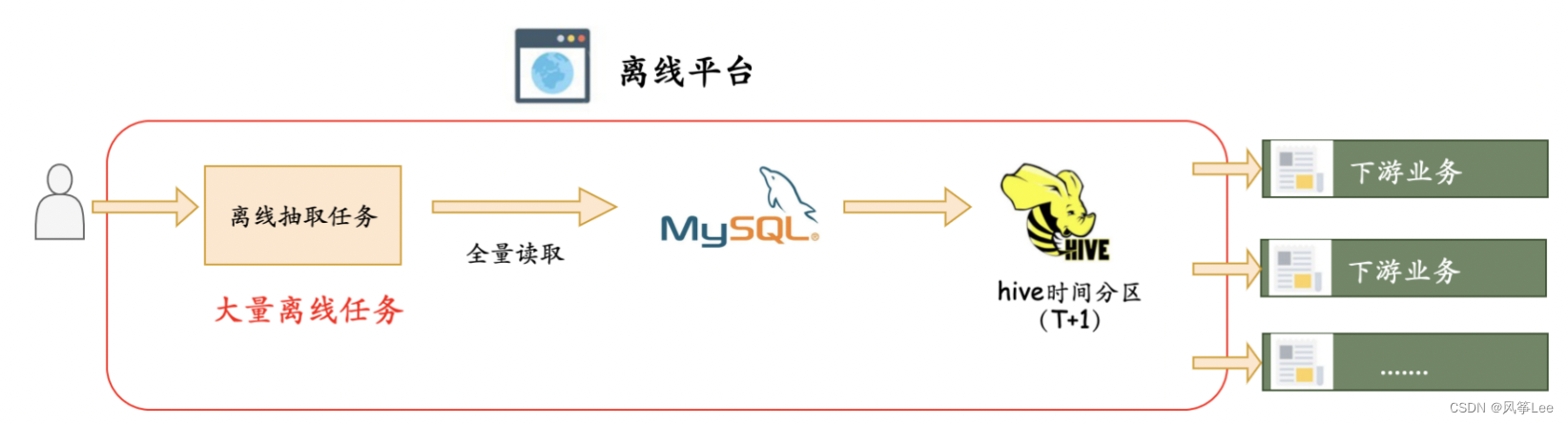
痛点总结:
- 每天全量查询,需要消耗较多资源,业务mysql库压力较大,性能受到影响。
- 业务抽取任务延迟太高,下游业务无法及时获取数据,无法按时产出业务数据。
- 分库分表,维护的离线任务较多,维护成本高,调整代价大。
- 各种因素影响,不够稳定,如果任务出现问题,整体重跑代价大,等待时间过长。
针对此场景的上述痛点问题,可以应用数据湖技术方案进行改造,改造后整体流程如下图所示:

可以看到结合数据湖方案可以准实时的进行入湖,下游进行抽取数据时基本没有太明显的性能瓶颈问题。整体优化可以总结为如下几点:
- 链路更加稳定,不用去全量读取数据访问线上mysql库表,直接通过dds服务拉取binlog数据,减少线上库集群压力。
- 效率提升,直接访问湖表,延迟较低,提升数据时效性。
- 大大降低维护成本,只需要维护较少离线任务,调整代价小。
- 业务扩展:一份存储多种用途,方便扩展到准实时场景。
场景2:部分列更新
原有的flink多流实时join场景,如下图所示,一般的处理模式是针对多流的数据在一定的时间窗口内关联state进行join,最终产出结果输送到下游进行处理。本身存在一些痛点,多个指标数据进行关联,不同指标数据可能会出现时间差比较大的异常情况。维持大的状态不仅会给内存带来的一定的压力,同时 Checkpoint 和 Restore 的时间会变得更长,可能会导致任务背压。
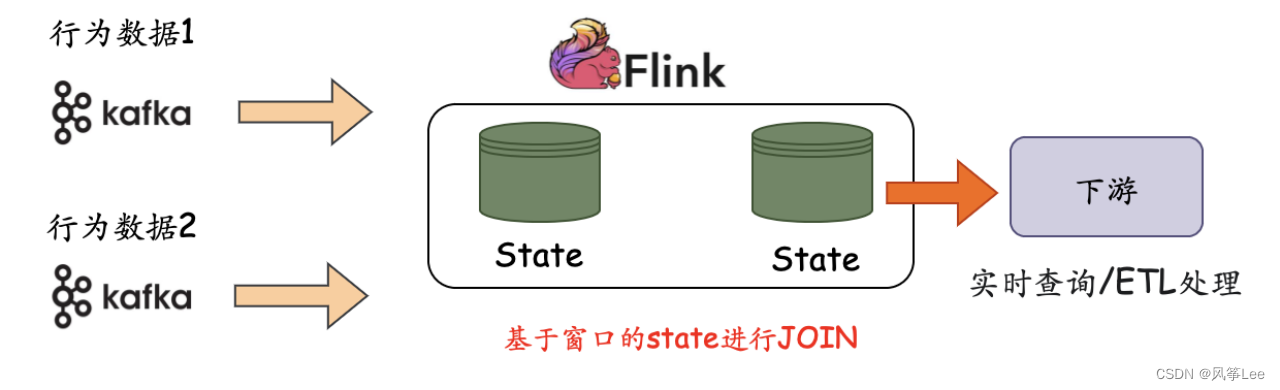
针对于上述场景痛点问题,可以结合数据湖方案进行改造,具体改造后的整体流程如下图所示:
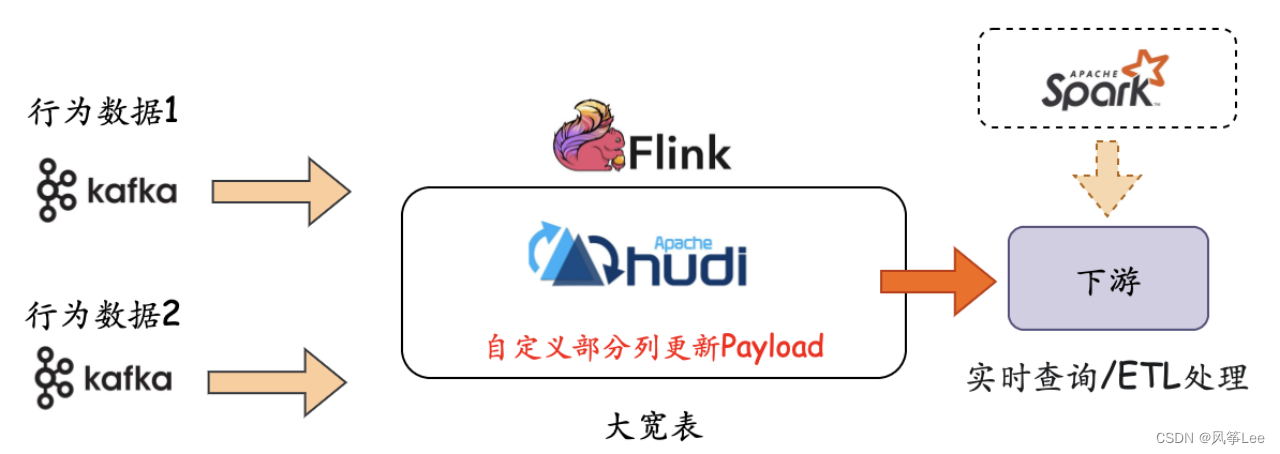
可以看到,应用数据湖hudi技术方案后,将原有的计算侧进行join改成了存储侧自动进行处理,通过hudi 的自定义的payload策略可以很方便的进行关联处理,效率高而且稳定。具体优化可以总结为如下几点:
- 简化业务逻辑,链路更加稳定,减少业务开发与维护成本。
- 效率更高,节省资源成本,不需要大状态等。
- 数据准确性方面:配合dds服务(按照数据主键进行分区)可以保证数据的最终准确性。
三. 总结:
本篇文章主要介绍了一些数据湖技术应用的场景,针对于两个常见的痛点场景,做了改造前后的对比说明,可以很清晰的对比出来应用数据湖技术方案后的稳定性等方面的优势,所以随着数据湖技术的不断成熟与稳定,后续会在越来越多的应用场景中帮助到业务解决实际问题,同时在降本增效方面的作用也会越来越明显。