看到一个帖子《excel吧-筛选开始时间,结束时间范围内的所有记录》,根据条件表中的开始时间和结束时间构成的时间范围,对数据表中的开始时间和结束时间范围内的数据进行筛选
目录
- 批量删除整行,整体删除
- 批量删除整行,分段删除
- 不同分段行数速度对比
- 数据举例
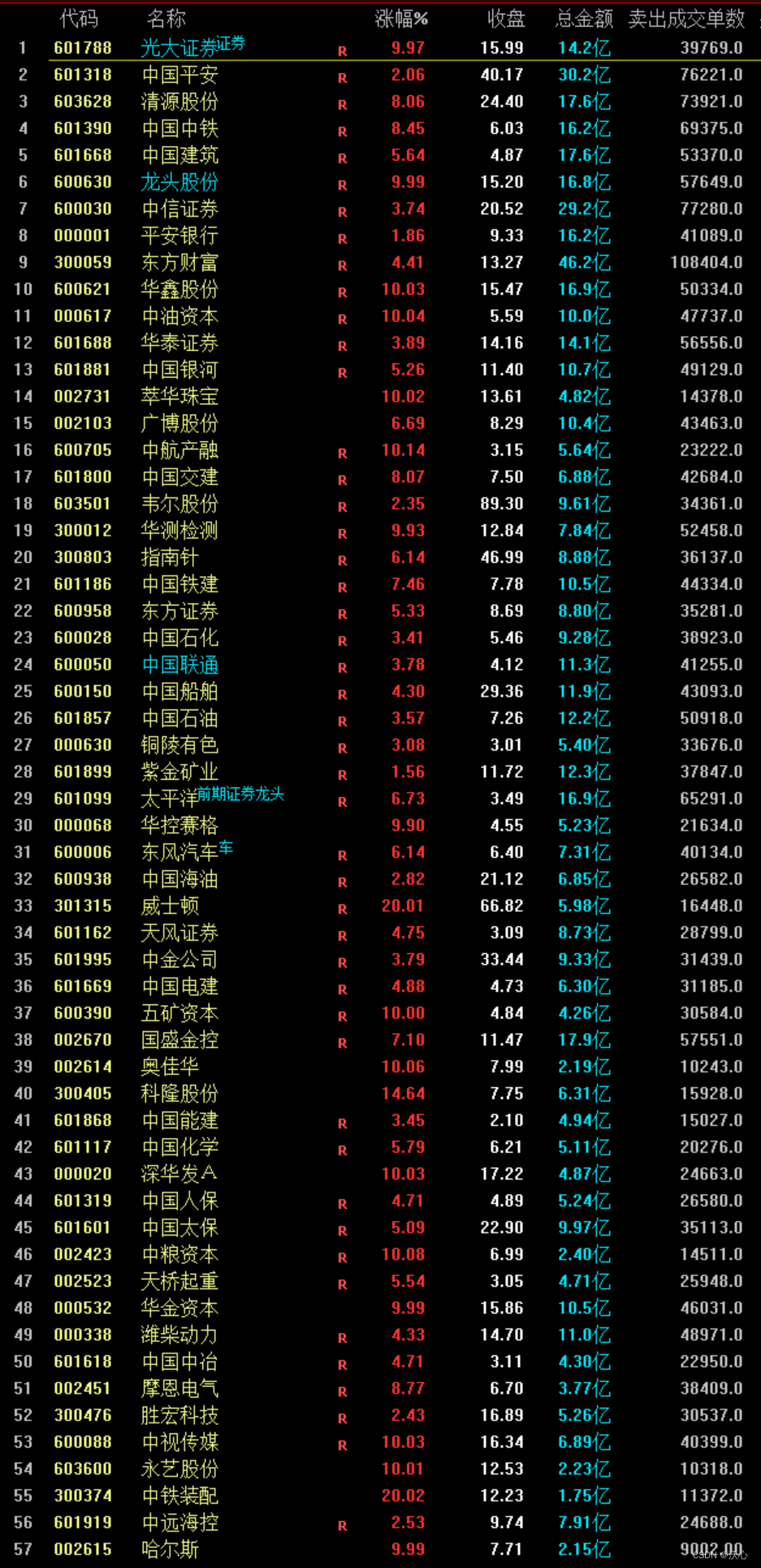
条件表中,开始时间为随机生成,结束时间为开始时间依次增加180、360天。20人,每人50个场所,共1000行条件时间范围(每人的每个地点只有一行时间范围)
数据表中,开始时间为随机生成,结束时间为开始时间依次增加1-12个月。共50万行时间范围

批量删除整行,整体删除
采用《Excel·VBA指定条件删除整行整列》先Union行再删除的方法可大幅提高速度
Sub 时间范围筛选()Dim dict As Object, rng As Range, arr, i&, k$Set dict = CreateObject("scripting.dictionary"): tm = TimerApplication.ScreenUpdating = False '关闭屏幕更新,加快程序运行arr = Worksheets("条件").[a1].CurrentRegionFor i = 2 To UBound(arr)k = arr(i, 1) & "_" & arr(i, 2)dict(k) = Array(CDbl(arr(i, 3)), CDbl(arr(i, 4)))NextWorksheets("数据").Copy after:=Sheets(Sheets.Count)With ActiveSheet.Name = "筛选结果": arr = .[a1].CurrentRegion: ReDim brr(1 To UBound(arr))For i = 2 To UBound(arr)k = arr(i, 1) & "_" & arr(i, 2)If Not dict.Exists(k) Then '不存在的直接删除If rng Is Nothing ThenSet rng = .Rows(i)ElseSet rng = Union(rng, .Rows(i))End IfElse'符合条件时间范围If Not (dict(k)(0) <= CDbl(arr(i, 3)) And CDbl(arr(i, 4)) <= dict(k)(1)) ThenIf rng Is Nothing ThenSet rng = .Rows(i)ElseSet rng = Union(rng, .Rows(i))End IfEnd IfEnd IfNextIf Not rng Is Nothing Then rng.DeleteEnd WithApplication.ScreenUpdating = TrueDebug.Print "筛选完成,用时" & Format(Timer - tm, "0.00") '耗时
End Sub
- 筛选结果:运行几个小时也未能生成结果
这显然不合理,就算是50万行的数据,使用字典也不可能耗时如此之久
将Union行的操作全部注释改为计数后可以发现,遍历50万行并判断是否符合条件时间范围,仅用时2.25秒,而之前的经验都是“先Union行再删除的方法”比“倒序循环依次删除整行的方法”速度更快,但本例中Union行的操作却很慢,那么就是行数太多导致反复Union行消耗太多时间
批量删除整行,分段删除
既然上面的代码运行缓慢可能是“反复Union行消耗太多时间”,那么就应该试试看倒序分段删除
Sub 时间范围筛选2()Dim dict As Object, rng As Range, arr, brr, i&, j&, k$, x&Set dict = CreateObject("scripting.dictionary"): tm = TimerApplication.ScreenUpdating = False '关闭屏幕更新,加快程序运行arr = Worksheets("条件").[a1].CurrentRegionFor i = 2 To UBound(arr)k = arr(i, 1) & "_" & arr(i, 2)dict(k) = Array(CDbl(arr(i, 3)), CDbl(arr(i, 4)))NextWorksheets("数据").Copy after:=Sheets(Sheets.Count)With ActiveSheet.Name = "筛选结果": arr = .[a1].CurrentRegion: ReDim brr(1 To UBound(arr))For i = 2 To UBound(arr)k = arr(i, 1) & "_" & arr(i, 2)If Not dict.Exists(k) Then '不存在的直接删除j = j + 1: brr(j) = iElse'符合条件时间范围If Not (dict(k)(0) <= CDbl(arr(i, 3)) And CDbl(arr(i, 4)) <= dict(k)(1)) Thenj = j + 1: brr(j) = iEnd IfEnd IfNextFor i = j To 1 Step -1 '倒序分段删除x = x + 1If rng Is Nothing ThenSet rng = .Rows(brr(i))ElseSet rng = Union(rng, .Rows(brr(i)))End IfIf x = 1000 Then rng.Delete: Set rng = Nothing: x = 0NextIf Not rng Is Nothing Then rng.DeleteEnd WithApplication.ScreenUpdating = TrueDebug.Print "筛选完成,用时" & Format(Timer - tm, "0.00") '耗时
End Sub
- 筛选结果:成功生成符合条件时间范围的筛选结果,共保留57668行数据

不同分段行数速度对比
| 分段行数 | 100 | 500 | 1000 | 5000 | 10000 |
|---|---|---|---|---|---|
| 耗时秒数 | 697.84 | 643 | 629.43 | 687 | 888.17 |
可以发现,分段在1万行以内时,运行速度差异还不明显,而总共需要删除的行数为442332行,因此以上“行数太多导致反复Union行消耗太多时间”的猜测是对的
而如果将筛选条件改为,时间范围完全不重叠
'条件开始时间 > 筛选结束时间,或条件结束时间 < 筛选开始时间
If dict(k)(0) > CDbl(arr(i, 4)) Or dict(k)(1) < CDbl(arr(i, 3)) Then
总共需要删除的行数为242931行时,可能是需要删除的行与行之间分散的更稀碎,导致比上面的删除442332行耗时差异更加明显,测试如下图
| 分段行数 | 100 | 500 | 1000 | 5000 | 10000 |
|---|---|---|---|---|---|
| 耗时秒数 | 1233.98 | 1234.9 | 1268.61 | 1939.34 | 4079.09 |
需要删除的行数变少,但在同样的分段下不仅消耗时间更多,而且分段为1万行时消耗时间增长率也更高,那么可以得出结论,不仅反复Union行消耗太多时间,而且行与行之间太分散也会消耗更多时间