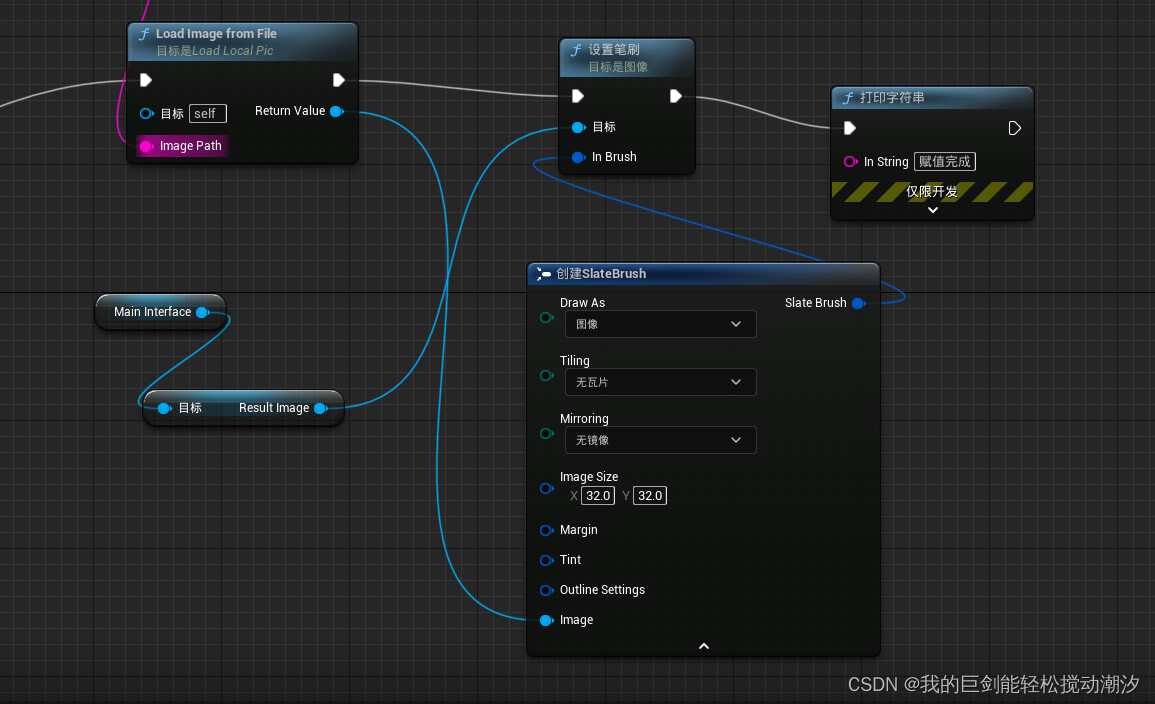
文章目录
- 一.引用
- 1.引例
- 2.注意事项
- 3.应用场景
- 1.做参数(a:输出型参数b:内容较大参数)
- 2.做返回值(a:修改返回值,b:减少拷贝)
- 4.引用和指针的区别
- 二.内联函数
- 1.为什么有内联函数
- 2.用法和底层
- 3.特性
- 三.auto关键字
- 1.基础示例
- 2.弊端
- 四.for循环
- 五. nullptr
一.引用
1.引例
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
语法:
数据类型+&+别名=原数值
如以下例子:
int main()
{int a = 10;int& b = a;return 0;
}
vs调试结果:
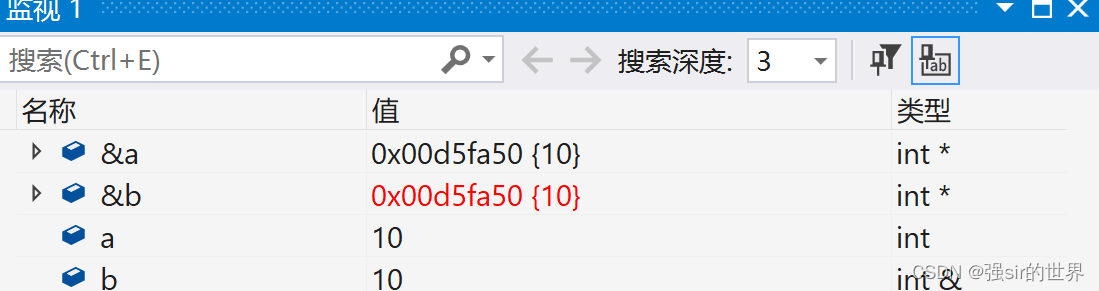
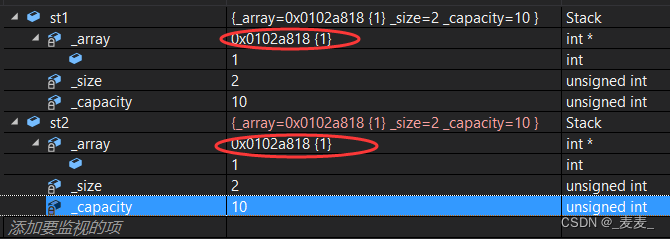
显然在语法层面,a和b的地址和数值大小完全一致。
2.注意事项
- 引用必须初始化,不能空定义一个引用,然后引用。
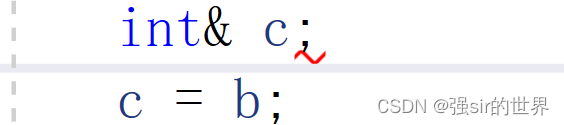

- 引用不同于指针,一旦引用不能中途更换指向。
int main()
{int a = 10;int c = 20;int& b = a;b = c;return 0;
}
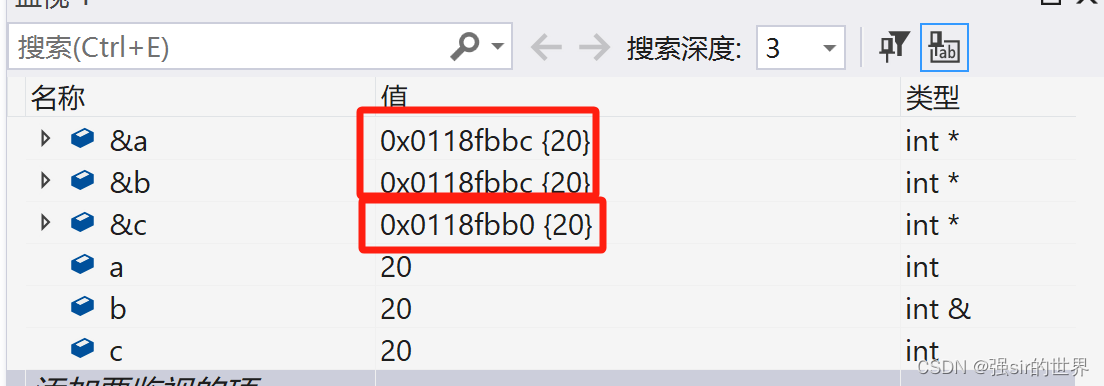
这里只是赋值而不是重引用
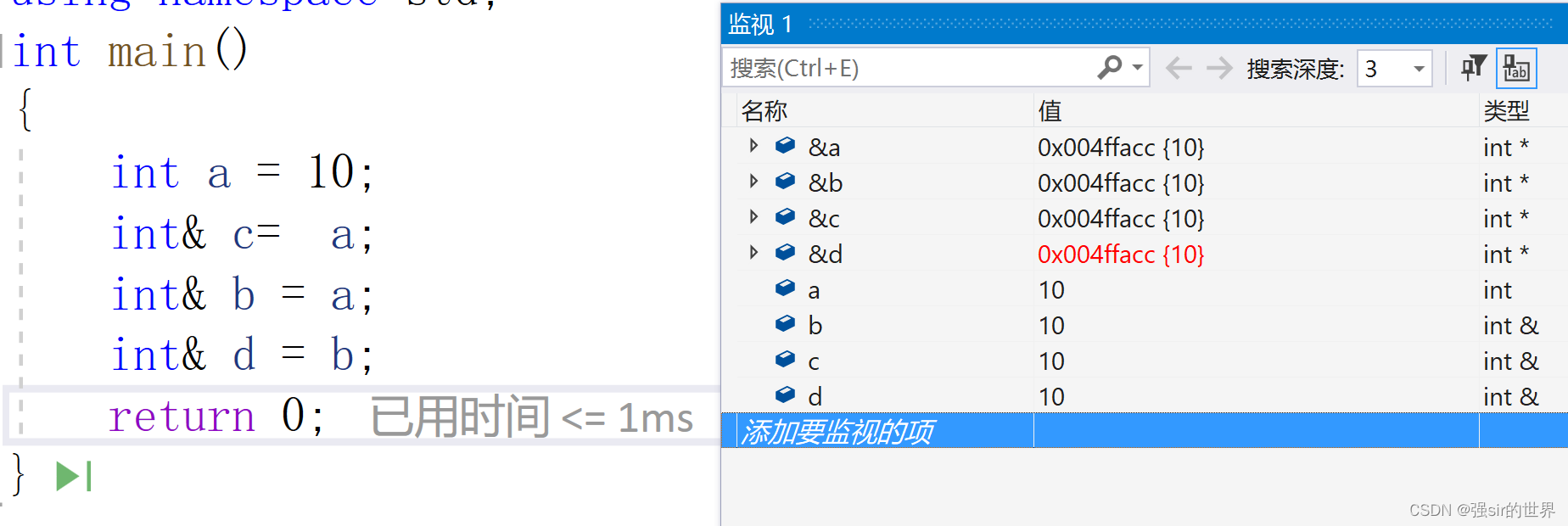
- 一个变量可以有多个引用多个别名,也可以给引用在引用。
- 不可修改的常量不能被引用

3.应用场景
值得注意的是引用和指针在许多场景功能是重复的,但又各自有独特的妙用
1.做参数(a:输出型参数b:内容较大参数)
- a:
输出型参数是一种函数参数,用于在函数调用结束后将结果传递出来。这种参数通常用于返回函数的计算结果或状态信息。
如交换函数:
void Swap(int& x, int& y)
{int temp = x;x = y;y = temp;
}
int main()
{int a = 10, b = 20;cout << a<< " " << b << endl;Swap(a, b);cout << a <<" "<< b << endl;return 0;
}

- b:
使用引用做参数,在语法层面就少去了函数传参,进行临时拷贝这一过程,所以增加了效率
2.做返回值(a:修改返回值,b:减少拷贝)
在讲用法之前,我需要细说一下函数返回值是如何传回主函数的。系统知识我会后续推出函数栈帧的创建与销毁。
int Func()
{int a = 10;return a;
}
int main()
{cout << Func() << endl;
}
在主函数内调用Func()函数,需要开辟一块内存称为Func()的函数栈帧。
在c/c++中,局部变量储存在栈中,随着函数生命周期结束,栈帧也随之销毁,在程序后期这片内存会清理分配给其他局部变量使用
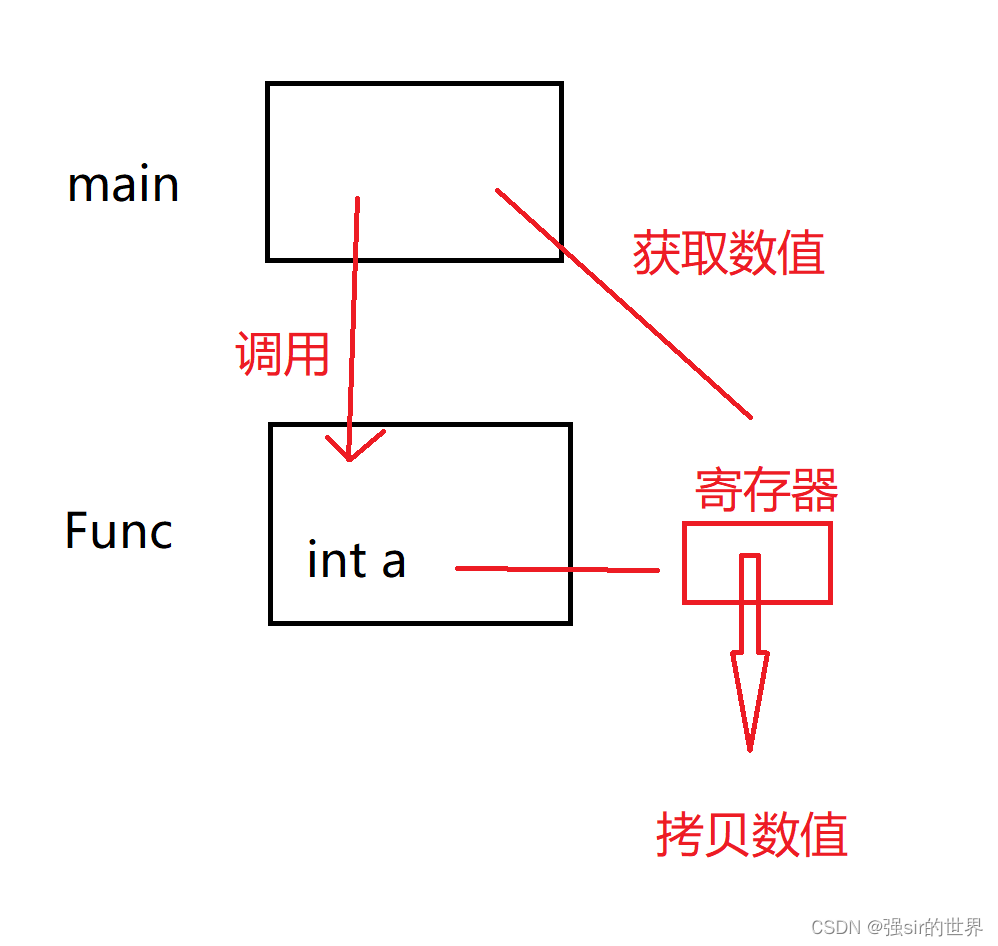
由此可见,虽然是return ,但返回的也是一份拷贝,并不是a这个量
- 错误写法:
int& Func()
{int a = 10;return a;
}

在代码量较少函数栈区未清理时,会存在正确情况,但一旦清理,将意味着引用将指向一个无效的内存地址。这将导致未定义的行为,可能会导致程序崩溃或产生不可预测的结果。
- 所以引用返回值,在堆区使用更加合理,脱离了局部变量返回的束缚:
int& Func(int x)
{int* a = (int*)malloc(sizeof(int)*10);for (size_t i = 0; i < 10; i++){a[i] = i;}return a[x];
}

4.引用和指针的区别
- 语法:
1.引用是别名不开空间,指针是地址需要开空间
2.引用必须初始化,指针不要求
3.引用不能改变指向,指针可以
4.引用相对更安全没有空引用,指针有空指针,野指针。
5.sizeof()内的意义,引用指指向的值,指针则指本身指针大小
6.引用没有±数值的用法 - 底层:
在汇编代码角度二者实现方法是相同的,都是指针,都需要开空间
二.内联函数
1.为什么有内联函数
内联函数(inline function)是一种在调用处直接展开执行的函数。在C++中,使用关键字inline声明的函数就是内联函数。内联函数的目的是减少函数调用的开销,提高程序的执行效率。
内联函数通常适用于函数体较小且频繁调用的情况,可以减少函数调用时的开销,但也可能增加代码的大小。
内联函数的定义通常放在头文件中,以便在需要的地方直接展开执行。
在c语言中我们通常使用宏替换去写频繁调用的小函数,不建立函数栈帧。
宏的缺点:
1.语法复杂,不易控制
2.本质是替换,不能调试
3.没有类型安全检查
所以c++中引入了内联函数的概念
2.用法和底层
- 在未使用内联
int Add(int x, int y)
{return x + y;
}
int main()
{int ret = Add(1, 2);return 0;
}

call代表调用函数,证明此时建立了函数栈帧
- 使用内联函数
inline int Add(int x, int y)
{return x + y;
}
int main()
{int ret = Add(1, 2);return 0;
}
在需要展开的函数前加上inline

这里就没有call指令,即没有调用函数栈帧
3.特性
inline本质为空间换时间,但是一旦函数大小过大,编译器将自动忽略内联不在展开,防止代码膨胀。所以超过范围大小的,和递归类型的函数不适用于内联。
多文件项目函数实现的方法:
1.声明和定义分离
2.static静态实现函数
3.inline函数展开
前两种方法适用于大一些的函数,第三种适用于短小型函数。
三.auto关键字
auto关键字通常用于声明变量,它让编译器根据变量的初始化值自动推断出变量的类型。这样可以简化代码,减少重复输入类型名称的工作量。
在C++11及以后的标准中,auto关键字还可以用于迭代器的声明和lambda表达式的返回类型推断。
1.基础示例
void func(int x, int y)
{return;
}int main()
{void(*pf1)(int ,int) = func;//函数指针auto pf2 = func;//自动推导cout << typeid(pf1).name ()<< endl;cout << typeid(pf2).name() << endl;return 0;
}
在很长的函数指针定义时很复杂,所以可以使用auto自动推导
typeid是C++中的一个操作符,用于获取一个对象的类型信息。

2.弊端
过分使用auto,会误导程序员的判断,相当于一些关键信息会被省略,建议慎用。
四.for循环
C++11引入了范围for循环,它提供了一种简洁的方法来遍历容器、数组或其他可迭代对象的元素。范围for循环的语法如下:
for (auto element : container) {// 在这里使用 element
}
其中,auto关键字用于自动推断element的类型,container是要遍历的容器或可迭代对象。在循环的每次迭代中,element将依次代表container中的每个元素,直到遍历完所有元素为止。
日常使用中,这里容器可指数组,所以在c++中遍历数组又有了更简洁的使用方法。
int main()
{int arr[5] = { 1,2,3,4,5};for (auto e : arr){//遍历数组cout << e << " ";}cout << endl;return 0;
}
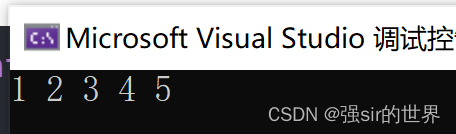
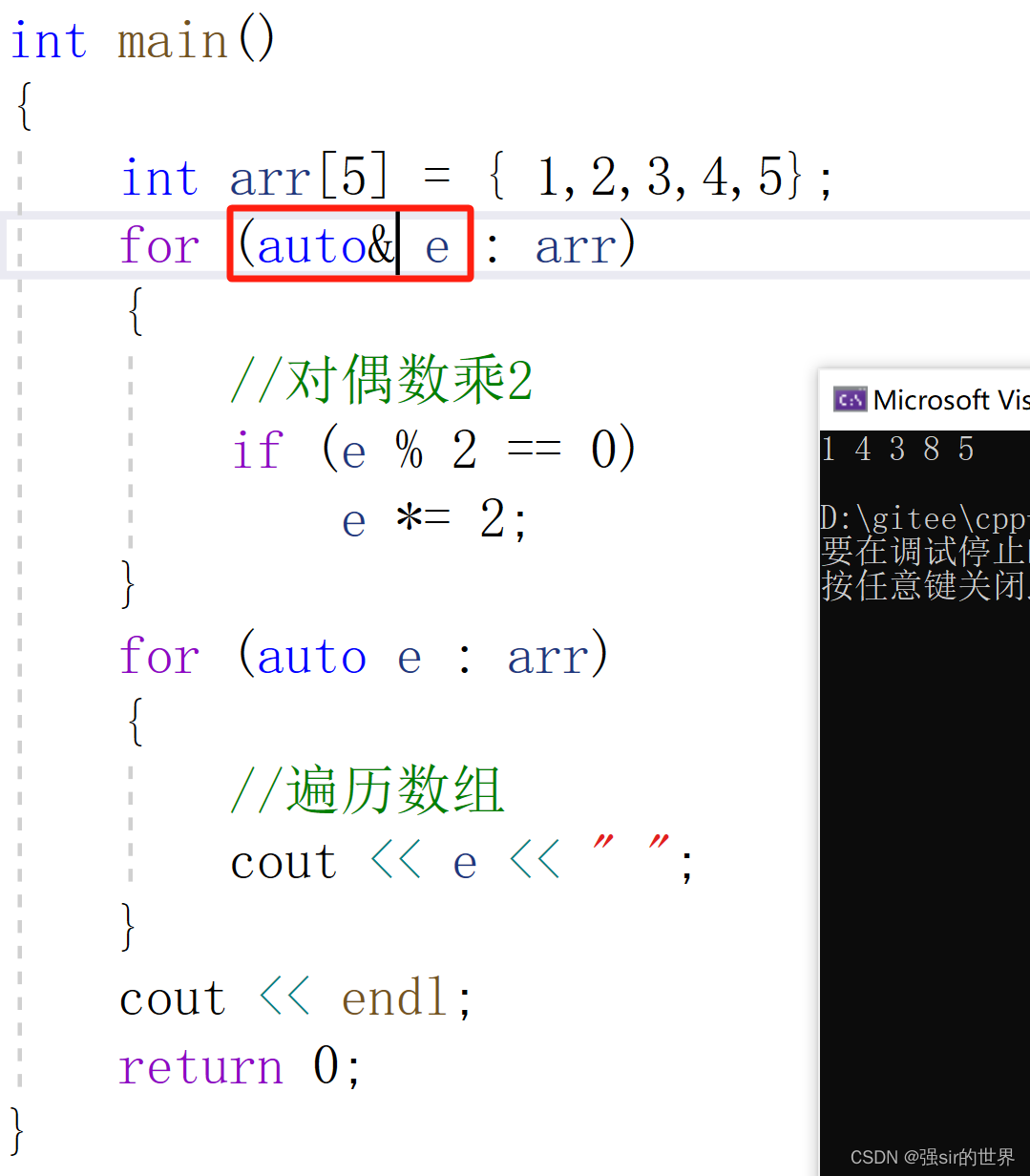
注意的一点:这里的e是对数组元素的一份临时拷贝,修改e对数组无效
那么怎么修改呢我们可以尝试使用引用对数组元素取别名
五. nullptr
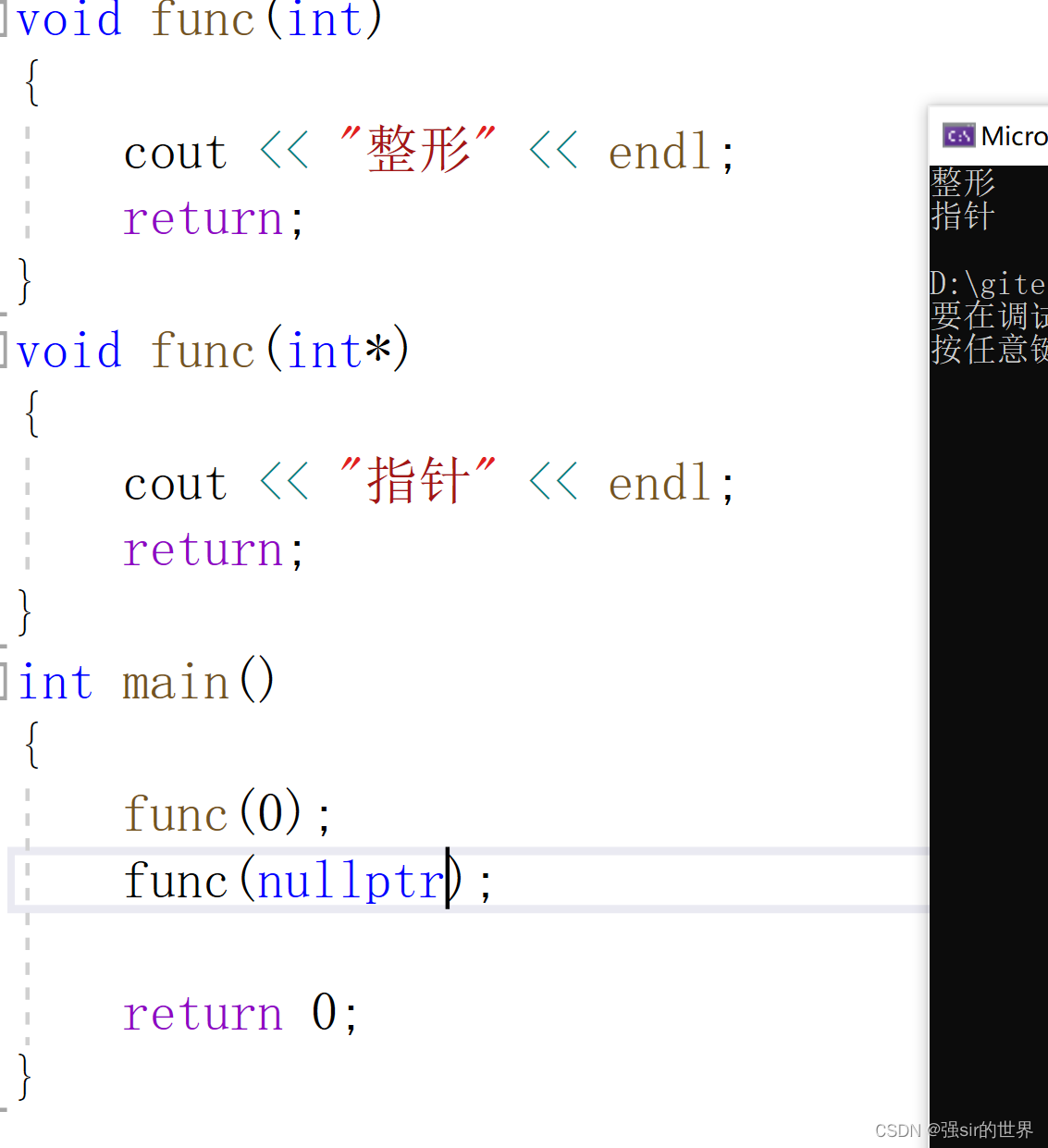
在c++98中有一个bug,将NULL直接宏定义为0,所以在函数重载上会有误判。
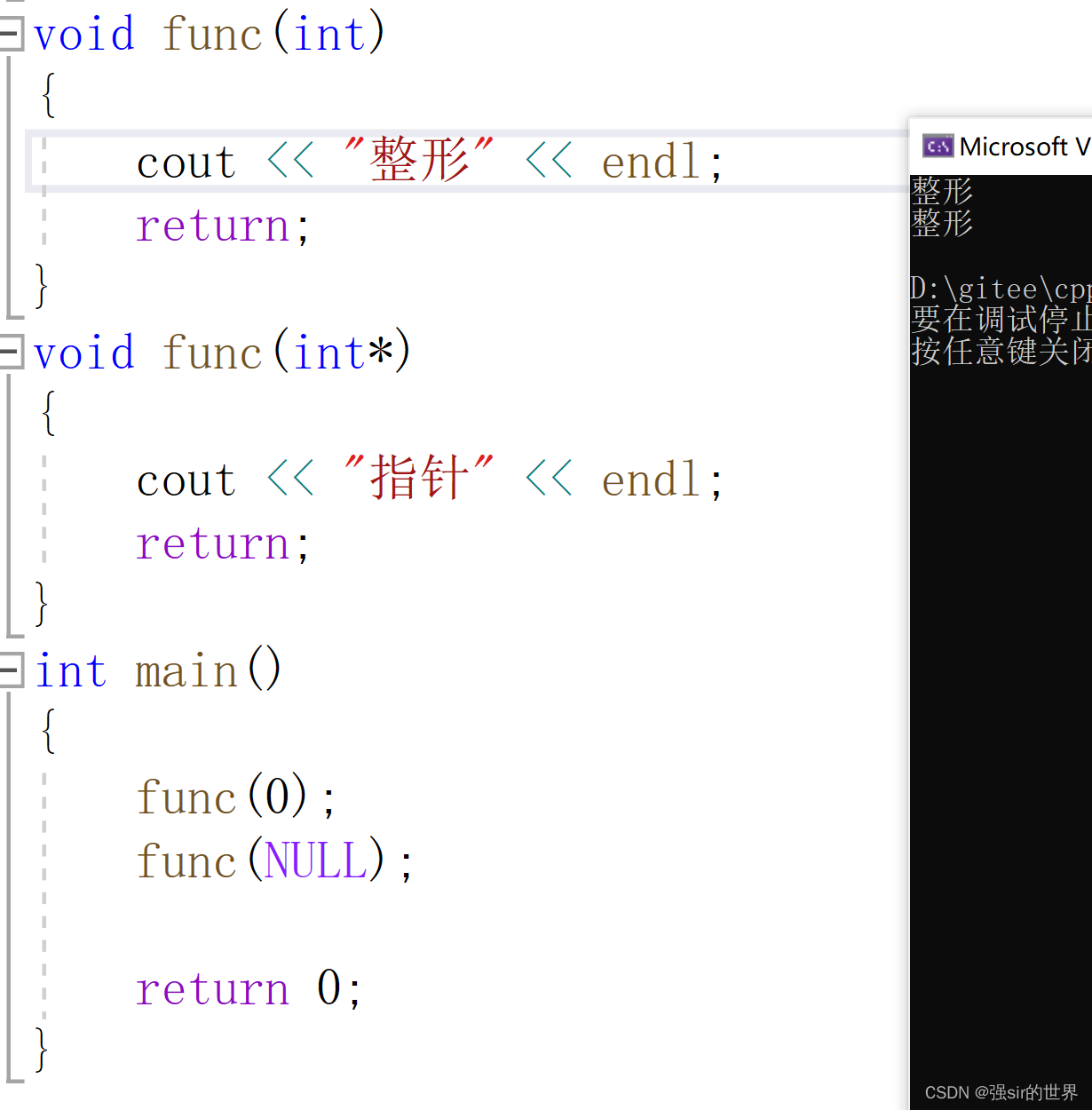
如图所示,输出皆为第一个函数,并没有达到重载效果。
所以c++11,引入关键字nullptr进行修正。
本期文章就分享到这里,感谢收看!