什么是正则表达式
正则表达式,又称规则表达式(Regular Expression)。正则表达式通常被用来检索、替换那些符合某个规则的文本
正则表达式的作用
- 验证数据的有效性
- 替换文本内容
- 从字符串中提取子字符串
匹配单个字符
| 字符 | 功能 |
|---|---|
| . | 匹配任意1个字符(除了\n) |
| [ ] | 匹配[ ]中列举的字符 |
| \d | 匹配数字,即0-9 |
| \D | 匹配非数字,即不是数字 |
| \s | 匹配空白,即 空格,\t-tab键 \n-换行 |
| \S | 匹配非空白 |
| \w | 匹配单词字符,即a-z、A-Z、0-9、_ |
| \W | 匹配非单词字符 |
匹配多个字符
| 字符 | 功能 |
|---|---|
| * | 匹配前一个字符出现0次或者无限次,即可有可无 |
| + | 匹配前一个字符出现1次或者无限次,即至少有1次 |
| ? | 匹配前一个字符出现1次或者0次,即要么有1次,要么没有 |
| {m} | 匹配前一个字符出现m次 |
| {m,n} | 匹配前一个字符出现从m到n次 |
匹配开头结尾
| 字符 | 功能 |
|---|---|
| ^ | 匹配字符串开头,注意^[4-7] 和 [ ^4-7](这个是取反)的区别 |
| $ | 匹配字符串结尾 |
re模块
re.match(pattern, string, flags=0)
从头匹配一个符合规则的字符串,从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None
- pattern: 正则模型
- string : 要匹配的字符串
- falgs : 匹配模式
注:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符'$'
match() 方法一旦匹配成功,就是一个match object对象,而match object对象有以下方法:
- group() 返回被 RE 匹配的字符串
- start() 返回匹配开始的位置
- end() 返回匹配结束的位置
- span() 返回一个元组包含匹配 (开始,结束) 的位置
匹配分组
| 字符 | 功能 |
|---|---|
| | | 匹配左右任意一个表达式 |
| (ab) | 将括号中字符作为一个分组 |
\num | 引用分组num匹配到的字符串 |
(?P<name>) | 分组起别名 |
| (?P=name) | 引用别名为name分组匹配到的字符串 |
re模块的高级用法
search,搜索匹配
match()和search()的区别:
match是开头匹配,search是全文搜索
match()函数只检测RE是不是在string的开始位置匹配,search()会扫描整个string查找匹配;
也就是说match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回none。
findall,查找所有,返回列表
re.findall遍历匹配,可以获取字符串中所有匹配的字符串,返回一个列表。
格式:re.findall(pattern, string, flags=0)
sub 将匹配到的数据进行替换
使用re替换string中每一个匹配的子串后返回替换后的字符串。
格式:re.sub(pattern, repl, string, count)
split 根据匹配进行切割字符串,并返回一个列表
可以使用re.split来分割字符串,如:re.split(r'\s+', text);将字符串按空格分割成一个单词列表。
格式:re.split(pattern, string[, maxsplit])
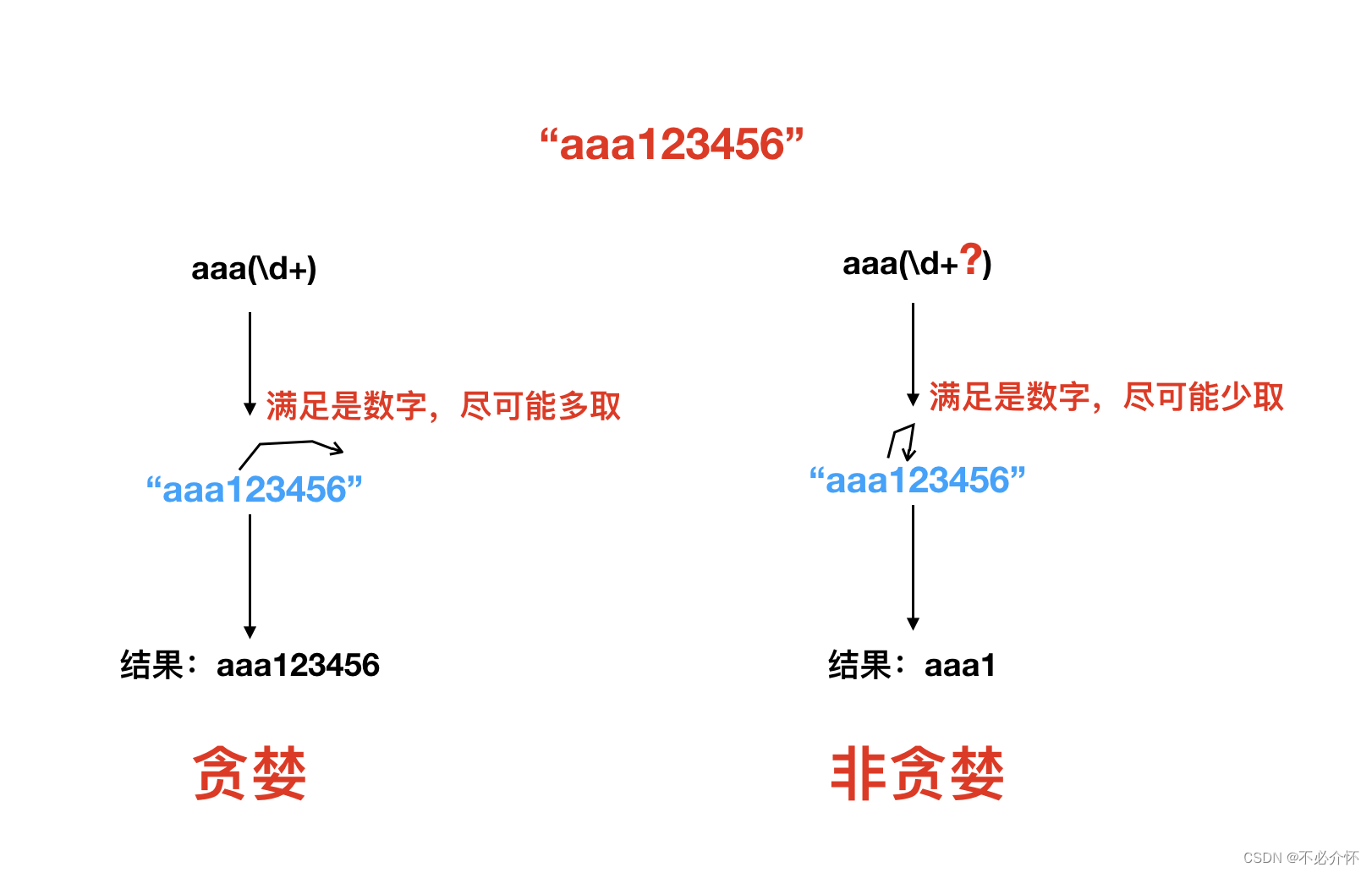
贪婪和非贪婪
Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪则相反,总是尝试匹配尽可能少的字符。
在"*","?","+","{m,n}"后面加上?,使贪婪变成非贪婪。
解决方式:非贪婪操作符“?”,这个操作符可以用在"*","+","?"的后面,要求正则匹配的越少越好。
r的作用
Python中在正则字符串前面加上 ‘r‘ 表示,
让正则中的 '\' 不再具有转义功能(默认为转义),就是表示原生字含义一个斜杠 \
re.match(r"<([a-zA-Z0-9]*)>.*</\1>", "<html>helloworld</html>")简单爬虫
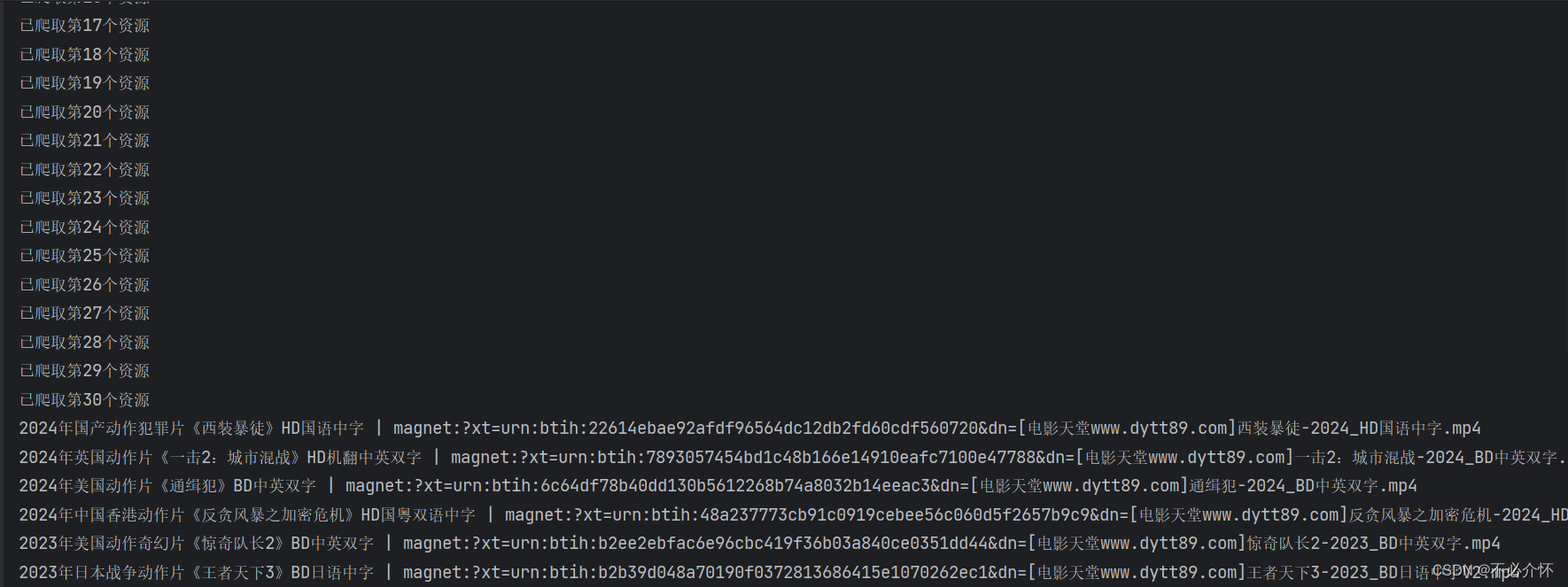
爬取电影天堂的下载地址
import urllib.request
import redef down_page():# 打开网页respon_data = urllib.request.urlopen("https://www.dy2018.com/2/")# 解码respon_decode = respon_data.read().decode("gbk")# 正则表达式获取下载页面网址films_data = re.findall(r"<a href=\"(.*)\" class=\"ulink\" title=\"(.*)\">", respon_decode)# 创建字典存储当前页的电影名和下载页面网址films_dict = {}count = 1# 将电影名和下载页网址从列表中拆包for films_url, films_name in films_data:# 拼接下载页面网站films_url = "https://www.dy2018.com/" + films_url# 打开下载页面respon_films_data = urllib.request.urlopen(films_url)# 解码respon_deown = respon_films_data.read().decode("gbk")# 使用正则提取下载地址down_url = re.search(r">(magnet:.*\.mp4)</a>", respon_deown)# 将电影名和下载地址存入字典films_dict[films_name] = down_url.group(1)print("已爬取第%s个资源" % count)count += 1return films_dictdef main():down_dict = down_page()for name in down_dict:print(name, "|", down_dict[name])if __name__ == '__main__':main()
运行结果