文章目录
- 🚡 简介
- ☀️ Spring
- 🐥 体系结构
- 🐠 生命周期
- 🍁 SpringMVC
- 🌰 执行流程
- 🌜 SpringBoot
- 🌍 核心组件
- 🎍 自动装配
- 🎑 3.0升级
- 🔅 spring Cloud Alibaba
- 💊 体系机构
- ⛳️ 服务注册发现&配置【NACOS】
- 🚵 Spring Cloud Gateway
- 🎨 Sentinel
- 🌅 Nginx全配置知多少???
- 🍹 分布式事务Seata
- 🍤可靠消息服务(RabbitMq)
- 🍭 云原生
- ⛺️ 技术选型原则
🚡 简介

海阔凭鱼跃,天高任鸟飞! 学习不要盲目,让大脑舒服的方式吸收知识!!!
本人马上离开济南,回泰安发展,为了积极准备面试,本篇主要梳理的是微服务关联的知识点,同时希望能够帮助到需要的人…
☀️ Spring
🐥 体系结构
Spring体系结构
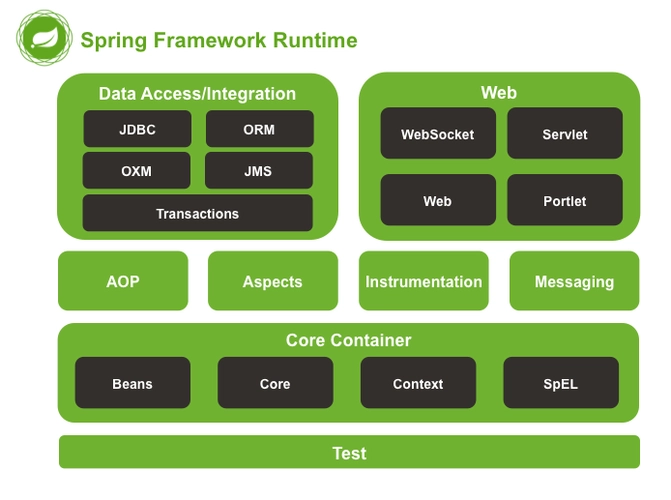
- Spring体系结构spring core:提供了框架的基本组成部分,包括控制反转(Inversion of Control,IOC)和依赖注入(Dependency Injection,DI)功能。
- spring beans:提供了BeanFactory,是工厂模式的一个经典实现,Spring将管理对象称为Bean。
- spring context:构建于 core 封装包基础上的 context 封装包,提供了一种框架式的对象访问方法。
- spring jdbc:提供了一个JDBC的抽象层,消除了烦琐的JDBC编码和数据库厂商特有的错误代码解析, 用于简化JDBC。
- spring aop:提供了面向切面的编程实现,让你可以自定义拦截器、切点等。
- spring Web:提供了针对 Web 开发的集成特性,例如文件上传,利用 servlet listeners 进行 ioc 容器初始化和针对 Web 的 ApplicationContext。
- spring test:主要为测试提供支持的,支持使用JUnit或TestNG对Spring组件进行单元测试和集成测试。
🐠 生命周期
Spring框架Bean的生命周期(⭐⭐⭐⭐⭐)

- 实例化:第 1 步,实例化一个 bean 对象;
- 属性赋值:第 2 步,为 bean 设置相关属性和依赖;
- 初始化:第 3~7 步,步骤较多,其中第 5、6 步为初始化操作,第 3、4 步为在初始化前执行,第 7 步在初始化后执行,该阶段结束,才能被用户使用;
- 销毁:第 8~10步,第8步不是真正意义上的销毁(还没使用呢),而是先在使用前注册了销毁的相关调用接口,为了后面第9、10步真正销毁 bean 时再执行相应的方法。
通过代码看整个流程~【doCreateBean()】
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)throws BeanCreationException {// 1. 实例化BeanWrapper instanceWrapper = null;if (instanceWrapper == null) {instanceWrapper = createBeanInstance(beanName, mbd, args);}Object exposedObject = bean;try {// 2. 属性赋值populateBean(beanName, mbd, instanceWrapper);// 3. 初始化exposedObject = initializeBean(beanName, exposedObject, mbd);}// 4. 销毁-注册回调接口try {registerDisposableBeanIfNecessary(beanName, bean, mbd);}return exposedObject;
}
通过上面的代码很清晰的看出四步走,但是之前在介绍初始化的时候,又包括了一些详细的步骤,故进入初始化函数initializeBean。
// AbstractAutowireCapableBeanFactory.java
protected Object initializeBean(final String beanName, final Object bean, @Nullable RootBeanDefinition mbd) {// 3. 检查 Aware 相关接口并设置相关依赖if (System.getSecurityManager() != null) {AccessController.doPrivileged((PrivilegedAction<Object>) () -> {invokeAwareMethods(beanName, bean);return null;}, getAccessControlContext());}else {invokeAwareMethods(beanName, bean);}// 4. BeanPostProcessor 前置处理Object wrappedBean = bean;if (mbd == null || !mbd.isSynthetic()) {wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);}// 5. 若实现 InitializingBean 接口,调用 afterPropertiesSet() 方法// 6. 若配置自定义的 init-method方法,则执行try {invokeInitMethods(beanName, wrappedBean, mbd);}catch (Throwable ex) {throw new BeanCreationException((mbd != null ? mbd.getResourceDescription() : null),beanName, "Invocation of init method failed", ex);}// 7. BeanPostProceesor 后置处理if (mbd == null || !mbd.isSynthetic()) {wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);}return wrappedBean;
}
销毁~
// DisposableBeanAdapter.java
public void destroy() {// 9. 若实现 DisposableBean 接口,则执行 destory()方法if (this.invokeDisposableBean) {try {if (System.getSecurityManager() != null) {AccessController.doPrivileged((PrivilegedExceptionAction<Object>) () -> {((DisposableBean) this.bean).destroy();return null;}, this.acc);}else {((DisposableBean) this.bean).destroy();}}}// 10. 若配置自定义的 detory-method 方法,则执行if (this.destroyMethod != null) {invokeCustomDestroyMethod(this.destroyMethod);}else if (this.destroyMethodName != null) {Method methodToInvoke = determineDestroyMethod(this.destroyMethodName);if (methodToInvoke != null) {invokeCustomDestroyMethod(ClassUtils.getInterfaceMethodIfPossible(methodToInvoke));}}
}
🍁 SpringMVC
🌰 执行流程

🌜 SpringBoot
🌍 核心组件
核心组件~

🎍 自动装配
自动装配~

🎑 3.0升级
SpringBoot3.0
- spring.factories文件废弃,自动配置包位置变化
3.0之后外部自动配置类通过META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports文件 - 必须使用JDK17
- Spring Native
使用GraalVM将SpringBoot 的应用程序编译成本地可执行的镜像文件,可以显著提升启动速度、峰值性能以及减少内存使用。GraalVM的即时编译器和AOT编译器可以显著提高应用程序的性能。据测试,GraalVM的性能可以比传统的JVM高出20%-100%。GraalVM就是Java的救世主,Java要想不被Go挤掉,整个Java生态都要向GraalVM靠齐。
- log4j2的一个日志框架的支持
- 完善分布式链路追踪(Micrometer)
在实际的开发中,我们一般是结合Prometheus来采集java进程中的一个指标数据。然后用Grafana来实现Dashboard的一个展示,这个呢,就相当于是一套比较完整的分布式链路追踪和流量指标的一个解决方案。
- 内置声明式HTTP客户端
为什么说JDK17是JAVA程序员必须掌握的版本???
🔅 spring Cloud Alibaba
💊 体系机构

⛳️ 服务注册发现&配置【NACOS】

pull (客户端的轮询)和push (服务端主动push)
- 客户端启动时会将当前服务的信息包含ip、端口号、服务名、集群名等信息封装为一个Instance对象,然后创建一个定时任务,每隔一段时间向Nacos服务器发送PUT请求并携带相关信息。
- nacos服务器端在接收到心跳请求后,会去检查当前服务列表中有没有该实例,如果没有的话将当前服务实例重新注册,注册完成后立即开启一个异步任务,更新客户端实例的最后心跳时间,如果当前实例是非健康状态则将其改为健康状态。
- 心跳定时任务创建完成后,通过POST请求将当前服务实例信息注册进nacos服务器。
- nacos服务器端在接收到注册实例请求后,会将请求携带的数据封装为一个Instance对象,然后为这个服务实例创建一个服务- Service,一个Service下可能有多个服务实例,服务在Nacos保存到一个ConcurrentHashMap中Map(namespace,Map(group::serviceName, Service));。
- nacos将实例添加到对应服务列表中会根据AP和CP不同的模式,采用不同协议。
CP模式就是基于Raft协议(通过leader节点将实例数据更新到内存和磁盘文件中,并且通过CountDownLatch实现了一个简单的raft写入数据的逻辑,必须集群半数以上节点写入成功才会给客户端返回成功)
AP模式基于Distro协议(向任务阻塞队列添加一个本地服务实例改变任务,去更新本地服务列表,然后在遍历集群中所有节点,分别创建数据同步任务放进阻塞队列异步进行集群数据同步,不保证集群节点数据同步完成即可返回) - nacos在将服务实例更新到服务注册表中时,为了防止并发读写冲突,采用的是写时复制的思想,将原注册表数据拷贝一份,添加完成之后再替换回真正的注册表。
- nacos在更新完成之后,通过发布服务变化事件,将服务变动通知给客户端,采用的是UDP通信,客户端接收到UDP消息后会返回一个ACK信号,如果一定时间内服务端没有收到ACK信号,还会尝试重发,当超出重发时间后就不在重发。
- 客户端通过定时任务定时从服务端拉取服务数据保存在本地缓存。

客户端 long pull 的方式
1.Nacos 客户端会循环请求服务端变更的数据,并且超时时间设置为30s,当配置发生变化时,请求的响应会立即返回,否则会一直等到 29.5s+ 之后再返回响应
2.客户端的请求到达服务端后,服务端将该请求加入到一个叫 allSubs 的队列中,等待配置发生变更时 DataChangeTask主动去触发,并将变更后的数据写入响应对象。
3.与此同时服务端也将该请求封装成一个调度任务去执行,等待调度的期间就是等DataChangeTask 主动触发的,如果延迟时间到了 DataChangeTask 还未触发的话,则调度任务开始执行数据变更的检查,然后将检查的结果写入响应对象(基于文件的MD5)
🚵 Spring Cloud Gateway
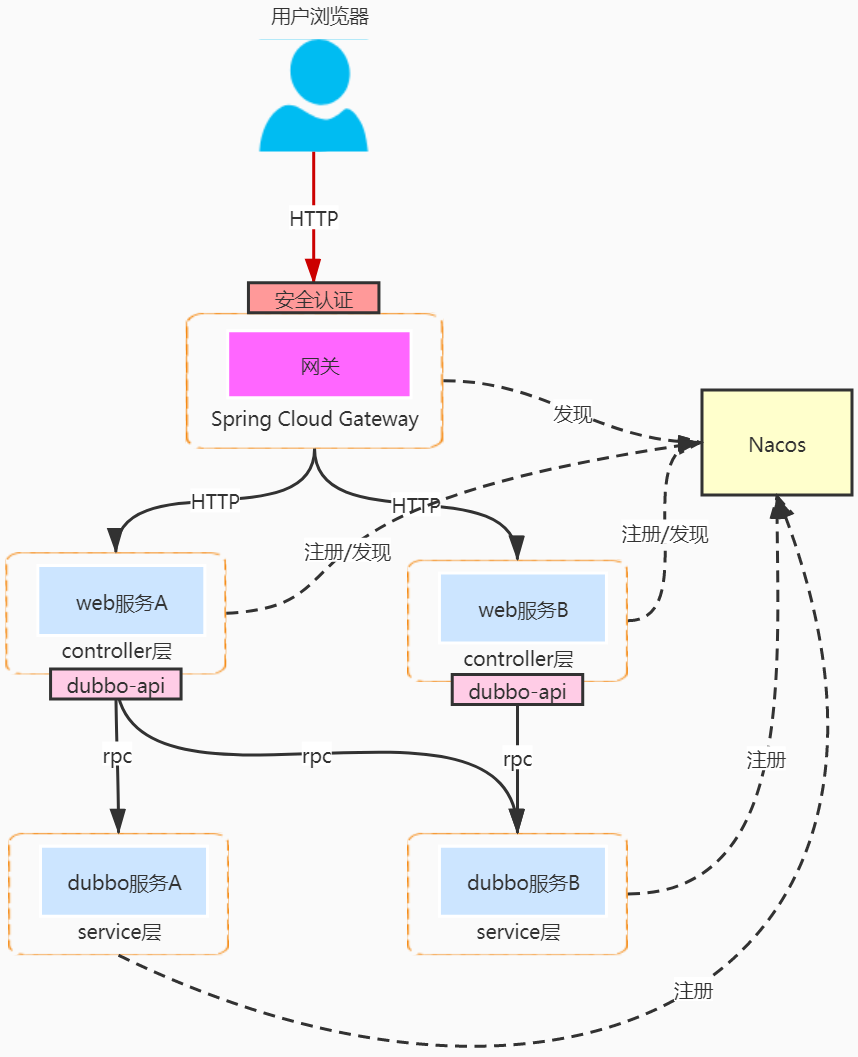
- Route:一个 Route 由路由 ID,转发 URI,多个 Predicates 以及多个 Filters 构成。Gateway 上可以配置多个 Routes。处理请求时会按优先级排序,找到第一个满足所有 Predicates 的 Route;
- Predicate:表示路由的匹配条件,可以用来匹配请求的各种属性,如请求路径、方法、header 等。一个 Route 可以包含多个子 Predicates,多个子 Predicates 最终会合并成一个;
- Filter:过滤器包括了处理请求和响应的逻辑,可以分为 pre 和 post 两个阶段。多个 Filter 在 pre 阶段会按优先级高到低顺序执行,post 阶段则是反向执行。Gateway 包括两类 Filter。
全局 Filter:每种全局 Filter 全局只会有一个实例,会对所有的 Route 都生效。
路由 Filter:路由 Filter 是针对 Route 进行配置的,不同的 Route 可以使用不同的参数,因此会创建不同的实例。
🎨 Sentinel
Sentinel生态圈

体系结构

sentinel在内部创建了一个责任链,责任链是由一系列ProcessorSlot对象组成的,每个ProcessorSlot对象负责不同的功能,外部请求是否允许访问资源,需要通过责任链的校验,只有校验通过的,才可以访问资源,如果被校验失败,会抛出BlockException异常。
Sentinel提供了8个ProcessorSlot的实现类:
- DegradeSlot:用于服务降级,如果发现服务超时次数或者报错次数超过限制,DegradeSlot将禁止再次访问服务,等待一段时间后,DegradeSlot试探性的放过一个请求,然后根据该请求的处理情况,决定是否再次降级。
- AuthoritySlot:黑白名单校验,按照字符串匹配,如果在黑名单,则禁止访问。
- ClusterBuilderSlot:构建ClusterNode对象,该对象用于统计访问资源的QPS、线程数、异常、响应时间等,每个资源对应一个ClusterNode对象。
- SystemSlot:校验QPS、并发线程数、系统负载、CPU使用率、平均响应时间是否超过限制,使用滑动窗口算法统计上述这些数据。
- StatisticSlot:用于从多个维度(入口流量、调用者、当前被访问资源)统计响应时间、并发线程数、处理失败个数、处理成功个数等。
- FlowSlot:用于流控,可以根据QPS或者每秒并发线程数控制,当QPS或者并发线程数超过设定值,便会抛出FlowException异常。FlowSlot依赖于StatisticSlot的统计数据。
- NodeSelectorSlot:负责收集资源路径,并将这些资源的调用路径,以树状结构存储起来,用于根据调用路径来限流降级、数据统计。
- LogSlot:打印日志。

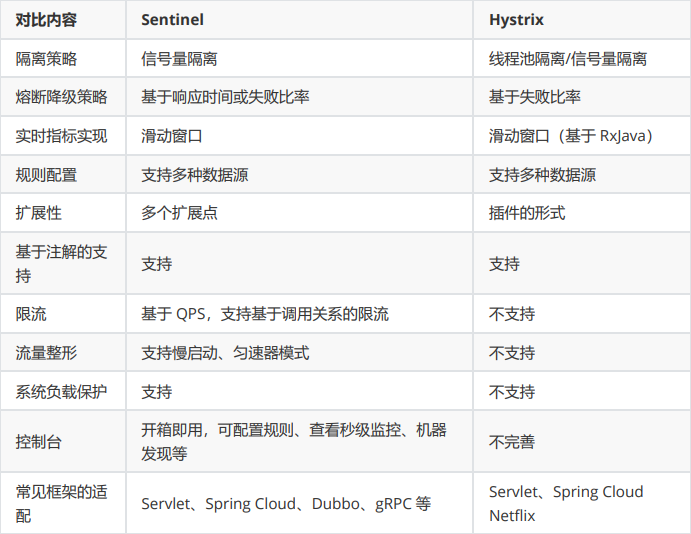
Sentinel VS Hystrix
🌅 Nginx全配置知多少???
NGINX搞懂这篇就够了!!!
🍹 分布式事务Seata
seataGit源码地址
架构体系⭐⭐⭐⭐⭐⭐

- TC (Transaction Coordinator) - 事务协调者:维护全局和分支事务的状态,协调全局事务提交或回滚。
- TM (Transaction Manager) - 事务管理器:定义全局事务的范围、开始全局事务、提交或回滚全局事务。
- RM (Resource Manager) - 资源管理器:管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
分布式事务解决方案

- XA模式
强一致性分阶段事务模式,牺牲了一定的可用性,无业务侵入

【XA流程】
- RM一阶段的工作:
注册分支事务到TC
执行分支业务sql但不提交
报告执行状态到TC- TC二阶段的工作:
TC检测各分支事务执行状态
如果都成功,通知所有RM提交事务
如果有失败,通知所有RM回滚事务- RM二阶段的工作:
接收TC指令,提交或回滚事务
- AT模式(分阶段提交)

- 阶段一RM的工作:
注册分支事务
记录undo-log(数据快照)
执行业务sql并提交
报告事务状态- 阶段二提交时RM的工作:
删除undo-log即可- 阶段二回滚时RM的工作:
根据undo-log恢复数据到更新前
TCC(柔性事务)

- Try:资源的检测和预留;
- Confirm:完成资源操作业务,要求 Try 成功 Confirm 一定要能成功。
- Cancel:预留资源释放,可以理解为try的反向操作。
SAGA(长事务解决方案)

一阶段:直接提交本地事务
二阶段:成功则什么都不做;失败则通过编写补偿业务来回滚
🍤可靠消息服务(RabbitMq)


- 生产者确认机制:确保消息从生产者到达MQ不会有问题:
消息生产者发送消息到RabbitMQ时,可以设置一个异步的监听器,监听来自MQ的ACK
MQ接收到消息后,会返回一个回执给生产者:消息到达交换机后路由失败,会返回失败ACK;消息路由成功,持久化失败,会返回失败ACK;消息路由成功,持久化成功,会返回成功ACK
生产者提前编写好不同回执的处理方式:失败回执:等待一定时间后重新发送;成功回执:记录日志等行为
- 消费者确认机制:确保消息能够被消费者正确消费:
消费者需要在监听队列的时候指定手动ACK模式
RabbitMQ把消息投递给消费者后,会等待消费者ACK,接收到ACK后才删除消息,如果没有接收到ACK消息会一直保留在服务端,如果消费者断开连接或异常后,消息会投递给其它消费者。
消费者处理完消息,提交事务后,手动ACK。如果执行过程中抛出异常,则不会ACK,业务处理失败,等待下一条消息
容器化Docker部署
🍭 云原生

⛺️ 技术选型原则
- 技术栈选型要匹配产品发展阶段。不需要一上来就用最先进的技术方案,而是需要和产品阶段一起考虑和权衡
- 技术栈选型要结合团队成员的技术背景。
- 不论选择什么技术栈,安全、稳定、可维护(扩展)都是要考虑清楚的。用什么语言、用什么服务会变化,但是这些基础的安全意识、稳定性意识,如何编写可维护的代码,都是决定项目能否长期发展下去的重要因素。