解决视网膜长尾数据:实例级类平衡、层次预训练、混合知识蒸馏
- 问题:视网膜疾病分类,解法:深度学习模型
- 问题:数据复杂性处理,解法:多任务框架(同时处理多种疾病)和少量样本学习(提高对罕见疾病的识别)
- 问题:长尾分布处理,解法:重新采样(平衡类别分布)和重新加权(从不平衡数据中的学习)
- 问题:长尾分类中的转移学习,解法:从多数类别到少数类别的知识转移
- 总结
论文:https://arxiv.org/pdf/2111.08913v1.pdf
如何有效地从长尾多标签的视网膜疾病数据集中学习,特别是在处理罕见疾病时。
长尾分布意味着少数几种疾病的样本数量占据了数据集的大部分,而大多数疾病的样本数量非常少。
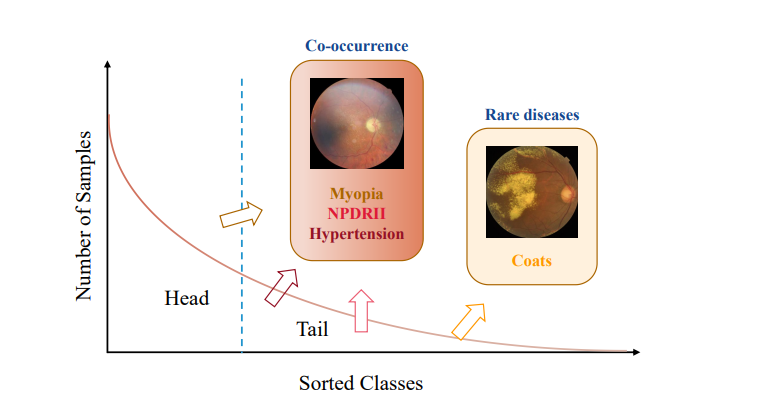
此外,还存在标签共现问题,即一个样本可能包含多个疾病标签。
问题:视网膜疾病分类,解法:深度学习模型
- 子问题:长尾多标签分布下的学习难题。
- 子解法:实例级类平衡采样策略和混合知识蒸馏法。
- 为什么使用这种解法:通过这种方法可以更好地从长尾分布中学习,同时保证对所有类别的公平性和无偏见。
例子:假设数据集中有1000个样本属于常见疾病(如糖尿病视网膜病变),但只有10个样本属于罕见疾病(如视网膜色素变性)。
传统训练方法可能会导致模型对常见疾病过度拟合,而忽略罕见疾病。
通过实例级类平衡采样,模型在训练过程中对每种疾病的样本都给予相同的重视,从而提高对罕见疾病的识别能力。
混合知识蒸馏进一步加强了模型对不同疾病特征的学习,通过整合多个模型的知识来提升整体性能。
- 子问题:选择合适的网络结构和优化策略。
- 子解法:使用预训练的 ResNet-50 作为主干网络,并使用Adam进行优化。
- 为什么使用这种解法:ResNet-50是一种广泛应用的深度学习架构,特别适用于图像识别任务。
- 子解法:使用预训练的 ResNet-50 作为主干网络,并使用Adam进行优化。
预训练权重可以帮助加速训练过程并提高性能。
问题:数据复杂性处理,解法:多任务框架(同时处理多种疾病)和少量样本学习(提高对罕见疾病的识别)
复杂性是指:多样性、非均衡分布的样本数量,难以识别的疾病特征。
例子:假设一个视网膜疾病的医学图像数据集包含多种疾病,如糖尿病视网膜病变(DR)、青光眼、黄斑变性以及一些非常罕见的遗传性视网膜疾病,如视网膜色素变性。
在这样的数据集中,常见疾病(如DR)的样本数量可能相对较多,而罕见疾病的样本数量则极少。
这种情况导致数据集呈现出明显的长尾分布特征,即大多数样本属于少数几种疾病,而大量其他疾病的样本非常稀少。
对于罕见疾病,如视网膜色素变性,由于样本数量有限,模型在学习过程中可能无法充分学习到识别这些疾病的关键特征。
此外,这些罕见疾病的临床表现可能与常见疾病大不相同,导致识别难度增加。
因此,模型可能在识别常见疾病方面表现出色,但在识别罕见疾病方面表现不佳。
在处理数据前,先看看数据情况:
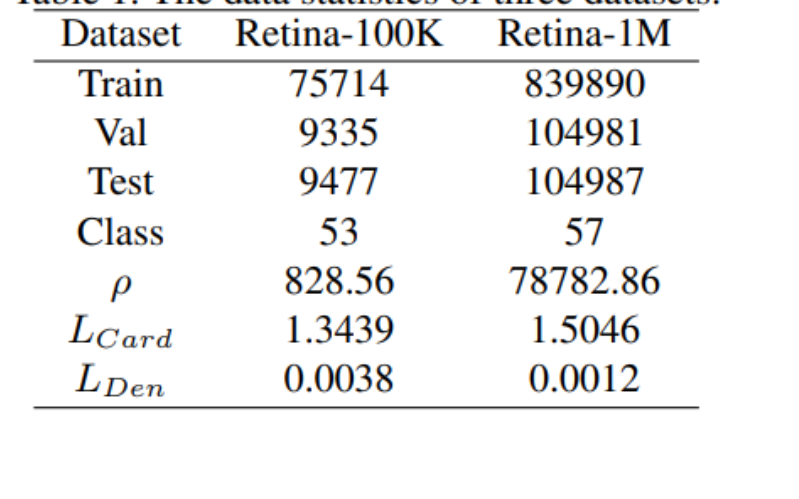
上图是训练集、验证集和测试集的样本数,以及数据集中的类别数、不平衡比例(ρ)、标签基数(L_Card)和标签密度(L_Den)。
例如,Retina-100K数据集有75,714个训练样本,9,335个验证样本,9,477个测试样本,共53个类别,不平衡比例是828.56,标签基数是1.3439,标签密度是0.0038。
- 子问题:处理原始数据分布的不平衡性。
- 子解法:评估不平衡比例(ρ)。
- 为什么使用这种解法:通过量化数据集中最常见类别和最不常见类别之间的数量差异(不平衡比例),可以更好地理解和应对数据不平衡问题。
假设一个视网膜疾病数据集中,最常见的疾病类别有1000个样本,而最不常见的疾病类别只有10个样本。
通过计算不平衡比例(1000/10 = 100),可以明确地了解数据集的不平衡程度,并据此制定合适的策略来处理这种不平衡。
- 子问题:标签共现问题。
- 子解法:使用标签基数和标签密度作为度量指标。
- 为什么使用这种解法:这些度量指标帮助理解每个样本中标签的平均数量和标签在整个数据集中的分布情况,从而解决标签共现问题。
如果一个样本可能同时包含多种视网膜疾病的标签,例如糖尿病视网膜病变和黄斑变性,那么通过计算标签基数和标签密度,可以量化每个样本的标签数量和整个数据集中标签的分布情况。
例如,一个图像可能同时标注了“糖尿病视网膜病变”和“视网膜血管瘤”。
在这种情况下:
- 标签基数(Label Cardinality) 表示每个图像平均有多少个疾病标签。
例如,如果我们有100个图像,总共有200个疾病标签,那么标签基数就是2,这意味着每个图像平均有2个疾病标签。
- 标签密度(Label Density) 是标签基数相对于可能的最大标签数量的比例。
例如,如果我们的数据集中可能的最大标签数量是10(即每个图像最多可以有10个不同的疾病标签),那么标签密度就是2/10 = 0.2。
通过计算这些指标,我们可以更好地理解数据集中疾病标签的分布和复杂性。这有助于我们设计更有效的学习策略,尤其是在需要处理多标签分类问题时。
【多任务】
层次信息预训练与实例重采样策略结合。
这也可以归类于多任务框架,因为层次信息的预训练涉及对多个相关但不同的类别(子类别和父类别)进行学习。
假设我们的数据集包含多种视网膜疾病,这些疾病可以按其性质和影响区域被分成不同的类别和子类别。
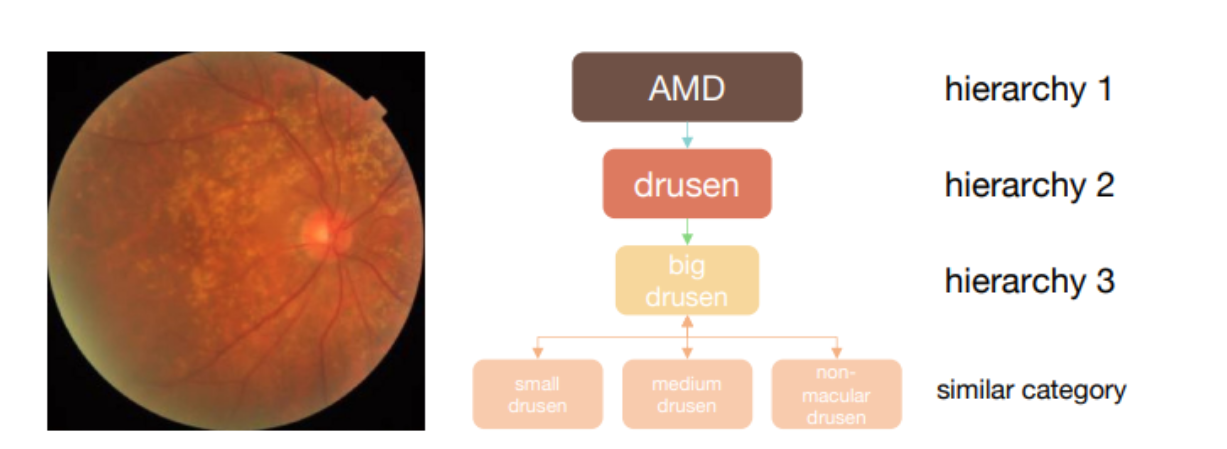
上图是疾病分类的层次结构。
例如,AMD(年龄相关性黄斑变性)分为不同的子类别,如drusen(视网膜色素上皮下沉积物),再进一步分为big drusen。
这种层次结构也展示了类别间的相似性,例如small drusen、medium drusen和non-macular drusen被认为是相似的类别。
例如:
- 大类别: 血管性疾病、神经性疾病、黄斑区疾病。
- 子类别:
- 血管性疾病下的子类别可能包括糖尿病视网膜病变、视网膜静脉阻塞等。
- 神经性疾病下的子类别可能包括青光眼、视神经炎等。
- 黄斑区疾病下的子类别可能包括年龄相关性黄斑变性、黄斑裂孔等。
层次信息预训练意味着模型首先学习区分大类别(如血管性疾病与神经性疾病),然后在每个大类别内部进一步识别具体的子类别。
这种方法帮助模型构建一个更丰富的视网膜疾病知识框架,从而提高对特定疾病的识别准确性。
为什么做一个分类,构建一个更丰富的视网膜疾病知识框架,就能提高对特定疾病的识别准确性?
假设我们有一个视网膜疾病识别系统,初步只按单一层次进行分类(即没有细分成多个子类别)。
在这种设置下,模型可能在区分某些相似疾病(如不同类型的血管性疾病)时表现不佳,因为它没有学习到足够区分这些疾病的特定特征。
假设这种单一层次分类的准确率是70%。
现在,假设我们将这个系统升级为一个层次化分类模型,其中包括大类别(如血管性疾病)和子类别(如糖尿病视网膜病变、视网膜静脉阻塞)。
在这种设置下,模型首先学习识别大类别的通用特征,然后进一步学习区分每个大类别下的具体疾病。
这种层次化学习方法使模型能够更准确地识别具体的视网膜疾病,因为它现在可以利用更详细的特征集来区分类似但不同的条件。
在这种层次化分类下,准确率可能提高到85%。
- 子问题:长尾多标签分类中的采样策略。
- 子解法:实例级类平衡采样(ICS)技术。
- 为什么使用这种解法:在长尾分布的数据集中,一些疾病类别的样本数量远多于其他类别。
传统的实例平衡采样和类平衡采样方法在多标签情境下效果不佳,因为它们无法有效处理这种类别不平衡和标签共现的问题。
ICS技术通过对每个类别进行更精细的采样,从而更平衡地表示数据集中的所有类别。
假设有一个数据集,其中大部分样本都标注为常见的疾病A,而罕见的疾病B的样本非常少。
使用ICS技术,模型在训练时会更频繁地看到疾病B的样本,从而减少对疾病A的过度拟合,提高对疾病B的识别能力。
ICS技术旨在解决长尾分布数据集中的类别不平衡问题,尤其是在多标签分类情境下。
这种技术的核心在于调整训练过程中各个类别的样本出现频率,以确保罕见类别获得足够的注意力。
流程拆解:
-
识别长尾分布:
- 分析数据集中各类别样本的分布情况,识别哪些类别是常见的(大量样本),哪些是罕见的(少量样本)。
-
采样策略调整:
- 传统的实例平衡采样方法按照样本出现的频率来随机选择样本,这导致高频类别过度表示,低频类别则被忽略。
- 类平衡采样尝试为每个类别分配相等的表示,但在多标签场景中可能导致一些样本被过度采样,尤其是那些包含多个标签的样本。
- ICS技术综合考虑了样本的类别分布和标签共现情况,调整每个样本被选中的概率,以确保所有类别都得到适当的表示。
-
实现细节:
- 计算每个样本对每个类别的贡献度,这通常是通过考虑样本中包含的每个标签的罕见程度来确定的。
- 在训练过程中,根据这些贡献度来调整样本的选择概率,以便罕见类别的样本更有可能被选中。
-
训练调整:
- 在模型训练期间,根据ICS策略来选择样本,这样可以保证即使是样本量较少的类别也能在模型训练中得到足够的表示。
假设我们有一个视网膜疾病数据集,其中包含常见疾病A(例如糖尿病视网膜病变)的1000个样本,和罕见疾病B(例如黄斑裂孔)的只有10个样本。
- 不使用ICS:模型大多数时间只会看到疾病A的样本,导致在识别疾病B时性能不佳。
- 使用ICS:模型在训练时会更平衡地看到两种疾病的样本。即使疾病B的样本数量少,也会通过调整它们被选中的概率来保证它们在训练中得到足够的表示。结果是,模型在识别疾病B时的准确性显著提高,同时对疾病A的识别能力仍然保持高效。
同时,实例重采样策略则关注于如何平衡各种疾病类别的样本分布。
假设我们的数据集中血管性疾病的样本非常多,但黄斑区疾病的样本相对较少。
在这种情况下,实例重采样策略会确保在训练过程中较少见的疾病(如黄斑区疾病)获得足够的关注,即使它们在数据集中的出现频率较低。
这样,模型不会仅仅偏向于识别最常见的疾病类型,而是能够均衡地识别所有类型的疾病。
综合这两种策略,我们的模型不仅能够理解视网膜疾病的复杂层次结构,还能够有效地处理由于样本数量不平衡带来的挑战。
【少样本】
利用视网膜疾病的层级信息,提高对少数类别的泛化能力。
解法:利用视网膜疾病的层级信息:
- 为什么使用这种解法:层级信息可以帮助模型利用在层级相关类别之间共享的特征,特别是对于少数类别,从而提高对这些类别的识别能力。
如果数据集包含各种类型的黄斑病变,这些病变可能具有共同的视网膜特征。
通过建立一个包含不同黄斑病变子类别的层级结构,模型可以学习到这些子类别之间共享的特征,从而即使对于样本量较少的特定黄斑病变,也能实现更准确的识别。
解法二:混合知识蒸馏方法,提高罕见疾病识别的准确性。
这种方法通过从其他模型中蒸馏知识来强化对罕见疾病的识别能力,因此可以看作是一种针对少量样本(罕见疾病样本)的学习技术。
- 为什么使用这种解法:通过从两个教师模型中提取知识并融合到一个统一的学生模型中,可以同时学习更好的表示和更公平的分类器,从而提高罕见疾病的识别准确性。
假设有两个教师模型,一个在识别常见视网膜疾病方面表现良好,另一个则更擅长识别罕见疾病。
通过混合知识蒸馏,可以将这两个模型的优点结合起来,训练出一个学生模型,该模型不仅能准确识别常见疾病,也能有效识别罕见疾病。
- 子问题:桥接两阶段训练中的特征和分类器偏差。
- 子解法:混合多重知识蒸馏。
- 为什么使用这种解法:在两阶段训练过程中,第一阶段的模型可能会学习到有效的特征表示,但第二阶段的分类器可能存在偏差。通过混合多重知识蒸馏,可以将第一阶段模型的特征表示和第二阶段模型的分类能力结合起来,从而提高整体模型的性能。
假设在第一阶段,一个模型学习到了对于识别多种视网膜疾病非常有效的特征,而在第二阶段,另一个模型在分类这些疾病方面表现更好。
通过混合知识蒸馏,可以创建一个新的模型,该模型结合了第一阶段模型的特征学习能力和第二阶段模型的分类准确性。
假设我们正在开发一个视网膜疾病识别系统,需要同时处理多种视网膜疾病,包括一些非常罕见的病例。
第一阶段:特征学习
- 模型A:这个模型专注于从大量数据中学习丰富的特征。它能够识别视网膜图像中的各种细微特征,例如微小的血管变化、色素沉着、或黄斑区的微小变化。这个模型虽然在特征提取上表现出色,但在实际的疾病分类方面可能不够精确。
第二阶段:分类精度
- 模型B:这个模型在分类视网膜疾病方面表现更好。它可能不如模型A那样擅长于提取复杂特征,但它能够更准确地将这些特征与特定的疾病类型联系起来。
混合多重知识蒸馏过程:
-
特征蒸馏:从模型A中提取关键的特征识别知识,这些知识对于理解视网膜图像至关重要。
-
分类蒸馏:从模型B中提取高效的疾病分类策略,特别是它对于识别不同疾病类型的能力。
-
综合应用:将这两个阶段的知识结合到一个新的“学生”模型中,这个模型既包含了强大的特征提取能力,又具有高精度的疾病分类能力。
在这种设置下,混合知识蒸馏后的学生模型可以提高对各种视网膜疾病的整体识别能力。
例如,模型A可能对于检测黄斑区的微小变化非常敏感,而模型B可能更擅长于将这些变化与特定的黄斑病变类型相关联。
结合后的模型不仅能够检测出这些微小变化,而且还能准确地诊断它们是由于年龄相关性黄斑变性还是其他类型的黄斑病变。
这种结合方法显著提高了整体识别准确率,对于罕见疾病和常见疾病都有所改善。
问题:长尾分布处理,解法:重新采样(平衡类别分布)和重新加权(从不平衡数据中的学习)
- 子问题:长尾多标签分布下的学习难题。
- 子解法:实例级类平衡采样策略和混合知识蒸馏法。
- 为什么使用这种解法:通过这种方法可以更好地从长尾分布中学习,同时保证对所有类别的公平性和无偏见。
假设数据集中有1000个样本属于常见疾病(如糖尿病视网膜病变),但只有10个样本属于罕见疾病(如视网膜色素变性)。
传统训练方法可能会导致模型对常见疾病过度拟合,而忽略罕见疾病。
通过实例级类平衡采样,模型在训练过程中对每种疾病的样本都给予相同的重视,从而提高对罕见疾病的识别能力。
混合知识蒸馏进一步加强了模型对不同疾病特征的学习,通过整合多个模型的知识来提升整体性能。
重新采样可以平衡类别分布,而重新加权方法则可以通过设计损失函数来强化从不平衡数据中的学习。
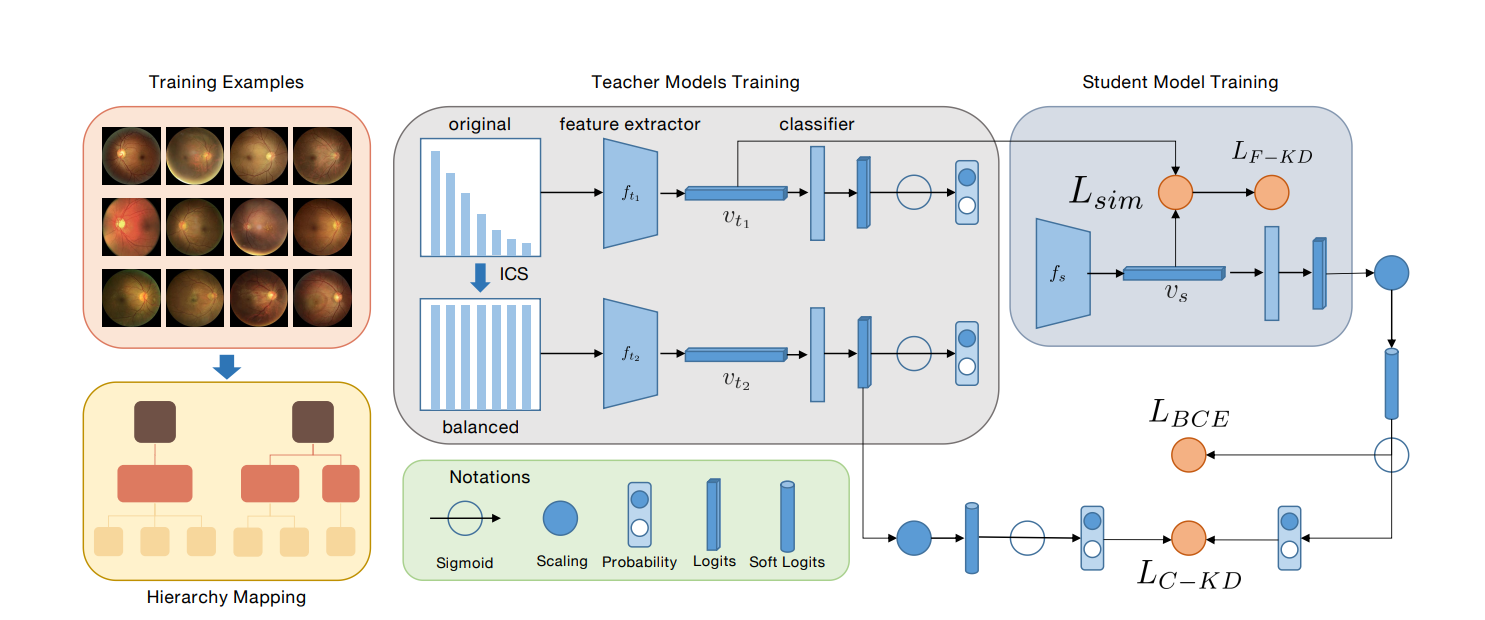
上图是一个用于识别视网膜疾病的深度学习训练框架,包括三个关键部分:层次映射、教师模型训练和学生模型训练。
-
层次映射(Hierarchy Mapping):这是数据准备的阶段,其中视网膜疾病被映射到一个层次结构中,这有助于模型理解和学习不同疾病间的关系。
-
教师模型训练(Teacher Models Training):这个阶段有两个并行的训练路径。
第一个路径是对原始数据分布进行训练,第二个路径使用实例级类平衡采样(Instance-wise Class-balanced Sampling, ICS)技术对数据进行重采样以解决数据的长尾分布问题。
每个路径都包括一个特征提取器(feature extractor)和一个分类器(classifier),它们分别输出特征表示(vt1, vt2)。
-
学生模型训练(Student Model Training):在这个阶段,学生模型(fs)通过混合知识蒸馏的方式学习教师模型的特征表示和分类决策。这包括两种类型的知识蒸馏损失:
- 特征级知识蒸馏损失(LF-KD),用于使学生模型的特征表示更接近最佳的教师模型特征表示。
- 类别级知识蒸馏损失(LC-KD),用于传递分类器的决策能力。
此外,使用二元交叉熵损失(LBCE)来直接训练学生模型对疾病进行分类。
图中的符号包括Sigmoid激活函数、缩放操作、概率、逻辑值和软逻辑值。
整个训练过程的目标是构建一个性能更好、对罕见疾病也有公平识别权重的模型。
通过将丰富的层次信息和平衡的重采样策略结合到深度学习框架中,这种方法能够提高识别罕见视网膜疾病的准确性。
问题:长尾分类中的转移学习,解法:从多数类别到少数类别的知识转移
- 子问题:转移学习在处理长尾分类问题中的作用。
- 子解法:从多数类别中学习通用知识并将其转移到少数类别。
- 为什么使用这种解法:转移学习可以利用多数类别中的丰富信息,帮助提升对少数类别的识别性能。
- 子解法:从多数类别中学习通用知识并将其转移到少数类别。
假设我们有一个大型的视网膜疾病数据集,其中某些疾病(如糖尿病视网膜病变)的样本数量非常多,而其他疾病(如遗传性视网膜病变)的样本数量非常少。
-
学习阶段:
- 从多数类别学习:首先,模型在包含大量样本的多数类别(如糖尿病视网膜病变)上进行训练,学习这些疾病的通用特征和模式。
- 知识提取:在这个阶段,模型会形成对常见疾病的深入理解,包括疾病的特征、发展阶段和常见表现形式。
-
转移阶段:
- 转移到少数类别:接下来,这些已学习的知识被用来指导对少数类别(如遗传性视网膜病变)的学习。
- 微调:模型在这些少数类别的样本上进行微调,以适应它们的特定特征,同时保留从多数类别中学到的一般知识。
-
效果:
- 提高识别性能:通过这种方法,即使是在样本数量较少的少数类别上,模型也能表现出更好的识别性能。这是因为从多数类别中学到的知识为模型提供了一个强大的起点,帮助它更快地学习和适应罕见疾病的特征。
通过转移学习,我们有效地利用了数据集中的丰富信息,增强了模型对所有类别,特别是那些样本较少的类别的识别能力。
当然,转移学习的成功在很大程度上取决于源类别和目标类别之间的这种相似性和相关性,以及模型能够从一个类别学习到的知识能多大程度上应用于另一个类别。
总结
基于视网膜长尾数据的论文中,研究者们面临的是如何从一个分布极不均匀的数据集中有效地学习,其中大量的样本属于少数类别,而少量的样本分布在多数类别中。
-
子问题:长尾数据分布下的类别不平衡。
- 子解法:实例级类平衡采样(Instance-wise Class-balanced Sampling, ICS)。
- 为什么使用这种解法:ICS通过为每个类别分配均等的采样概率来缓解类别不平衡问题,这样模型就不会过度偏向于高频类别。
- 在整体解法中的目的:确保所有类别都能公平地影响模型训练,提高罕见类别的识别准确性。
- 子解法:实例级类平衡采样(Instance-wise Class-balanced Sampling, ICS)。
-
子问题:罕见类别识别能力不足。
- 子解法:层次信息预训练(Hierarchical Pre-training)。
- 为什么使用这种解法:通过预训练模型来理解类别之间的层次关系,模型可以更好地泛化到看到的少数类别。
- 在整体解法中的目的:利用类别之间的内在联系来增强模型对罕见类别的识别能力。
- 子解法:层次信息预训练(Hierarchical Pre-training)。
-
子问题:知识从头部类别到尾部类别的转移不足。
- 子解法:混合知识蒸馏(Hybrid Knowledge Distillation)。
- 为什么使用这种解法:通过蒸馏头部类别(常见类别)模型和尾部类别(罕见类别)模型的知识到一个学生模型,可以结合两者的优点。
- 在整体解法中的目的:创建一个综合的模型,它具有广泛的泛化能力,并对所有类别都有公平的识别能力。
- 子解法:混合知识蒸馏(Hybrid Knowledge Distillation)。