摘要:本文整理自阿里云智能高级开发工程师王日宇,在 Flink Forward Asia 2023 流式湖仓(二)专场的分享。本篇内容主要分为以下四部分:
- StarRocks+Paimon 湖仓分析的发展历程
- 使用 StarRocks+Paimon 进行湖仓分析主要场景和技术原理
- StarRocks+Paimon 湖仓分析能力的性能测试
- StarRocks+Paimon 湖仓分析能力的未来规划
一、StarRocks+Paimon 湖仓分析的发展历程

StarRocks 的发展主要分为三个阶段:
- 1.x 版本主要关注性能,性能也是 StarRocks 迅速出圈的立足点,如今在绝大部分外表分析场景,无论是哪种格式,如 Hive、Hudi、Iceberg 等,都可以获得 3-5 倍以上的提升。
- 2.x 版本主要关注极速统一,StarRocks 真正接入的所有的外表格式都是在 2.x 中进行的。
- 3.x 版本主要关注湖仓融合的特性。
StarRocks 在三个大版本方向上的发展历程主要分为上下两部分,即底层性能持续优化与湖仓重大特性。
StarRocks 最初是通过极速的性能破圈的,主要包括向量化执行引擎、优秀的 CBO 优化器,以及各种 Runtime Filter 等应用。
StarRocks 1.x 在 2021 年开源时,就支持 Hive、ES 以及 MySQL 外表,还有自身的 StarRocks 外表,也可以做外表关联查询。
StarRocks 2.x 在 StarRocks 湖仓分析领域的重大突破,主要包括以下几点:
- 支持Catalog数据目录。在 1.x 时,要查询外表,需要根据对应表创建 External Table,就像普通表一样,指定各种列、类型,但在大数据领域,库和表很多,若要一个个创建外表,运维成本和人工成本很高,不容易维护,因此,在 2.x 中引入 Catalog 目录,只需要指定一个元数据地址,如 Hive Metastore,阿里云上的 DLF 或 AWS Glue,StarRocks 就可以直接根据元数据将所有的库表信息同步过来。
- 去年开始发布的 2.x,已经支持数据湖四种类型中的三种,包括 Iceberg、Hudi、Delta Lake ,当时 Paimon 还在孵化中。
- 2.x 引入 JNI Connector,最开始是为了解决读取 Hudi 的 MOR 表问题,因为大数据生态基本由 Java 开发,但 StarRocks 的主要语言是 C++,而 C++ 与 Java 之间的交互需要在内存里做数据转换,因此封装抽象 JNI Connector,全面封装所有的 C++ 与 Java 之间的内存转换和通信工作。
- 支持外表物化视图。很多使用场景都是基于 StarRocks 物化视图做的。
- 支持 Json、Map、Struct、Array 以及其他复杂类型的读取,性能优化也做了很多提升,包括大量 IO 的性能优化,如 Reader 合并、Rowgroup 合并、Data Cache 以及延迟物化。
- 对执行引擎进行了较大的改造,支持 Pipeline 执行引擎,使其执行顺序更加流水线,CPU 和 IO 之间有了非常好的平衡。
- 支持更加复杂的统计类型,包括直方图。
进入 3.x 时代,StarRocks 的主要突破有:
- 引入对 Paimon 数据湖格式的支持,并进一步优化对 JNI Connector 复杂类型的支持。Paimon 也是由 Java 开发的,所以使用了 JNI Connector。
- 支持算子落盘的 Spill,为将来使用 StarRocks 直接做 ETL 打基础。ETL 数据量通常比较大,通过 Spill 可以仅使用少量资源,如几个节点,在内存受限的情况下做大规模的数据处理。
- 提升 Trino 的兼容性。之前, Presto 或 Trino 与 StarRocks MySQL 语上有一定的区别,如要迁移到 StarRocks,则需要修改 SQL 作业,3.x 引入 Trino 兼容性之后,只需要设置 Session 变量就可以直接把原来的 Trino 作业运行在 StarRocks 上。
- 支持物化视图的分区刷新。在这之前都是整表刷新,现在可以自动感知刷新的分区,仅刷新有变化的分区,减少物化视图刷新的资源消耗。
- 除读取外,StarRocks 现在还支持 Hive、Iceberg 数据的写入。
二、使用 StarRocks+Paimon 进行湖仓分析主要场景和技术原理
2.1 主要场景
-
trino兼容
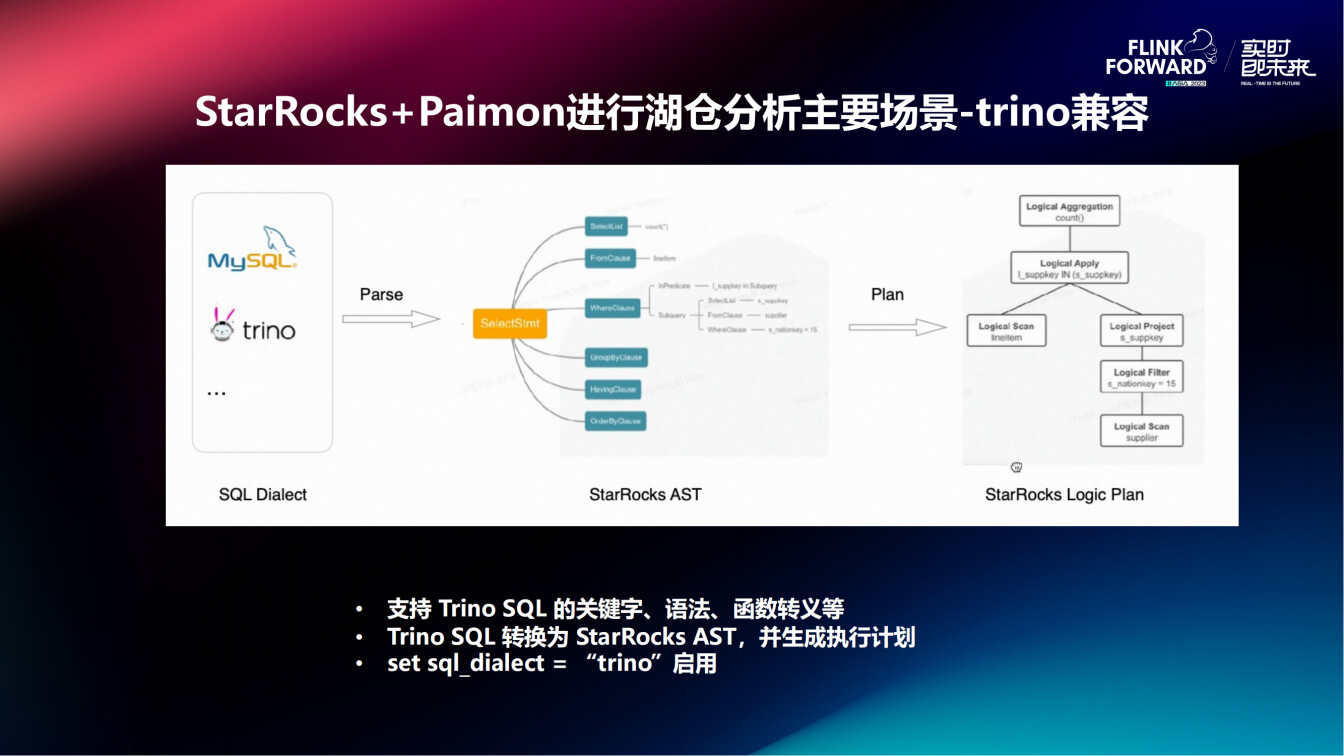
支持 Trino SQL 的关键字、语法和函数转义等。在使用过程中,可以直接 Trino SQL 转换为 StarRocks AST,并生成执行计划,只需要在 StarRocks 中执行语句 set sql_dialect = “trino” 即可启用。这样,所有的作业都可以直接搬到 StarRocks,而无需修改任何一行代码,该特性已在实际生产环境包括合作伙伴、客户案例中正式落地了,目前基本上达到了 90% 以上的兼容性。

-
联邦分析
由于不同的业务线使用不同的湖格式,甚至有自己的数据源,所以对于一些复杂查询,需要把不同数据源 join 起来联合查询。以 Paimon 的使用为例,直接 CREATE EXTERNAL CATALOG paimon_fs_catalog,指定地址,即可直接查询 Paimon 数据源表。其他数据格式的表也类似,需要联邦查询的时候,就直接对不同类型的表做 join 即可,包括 StarRocks 内表也是可以跟外表联合查询的。
-
透明加速
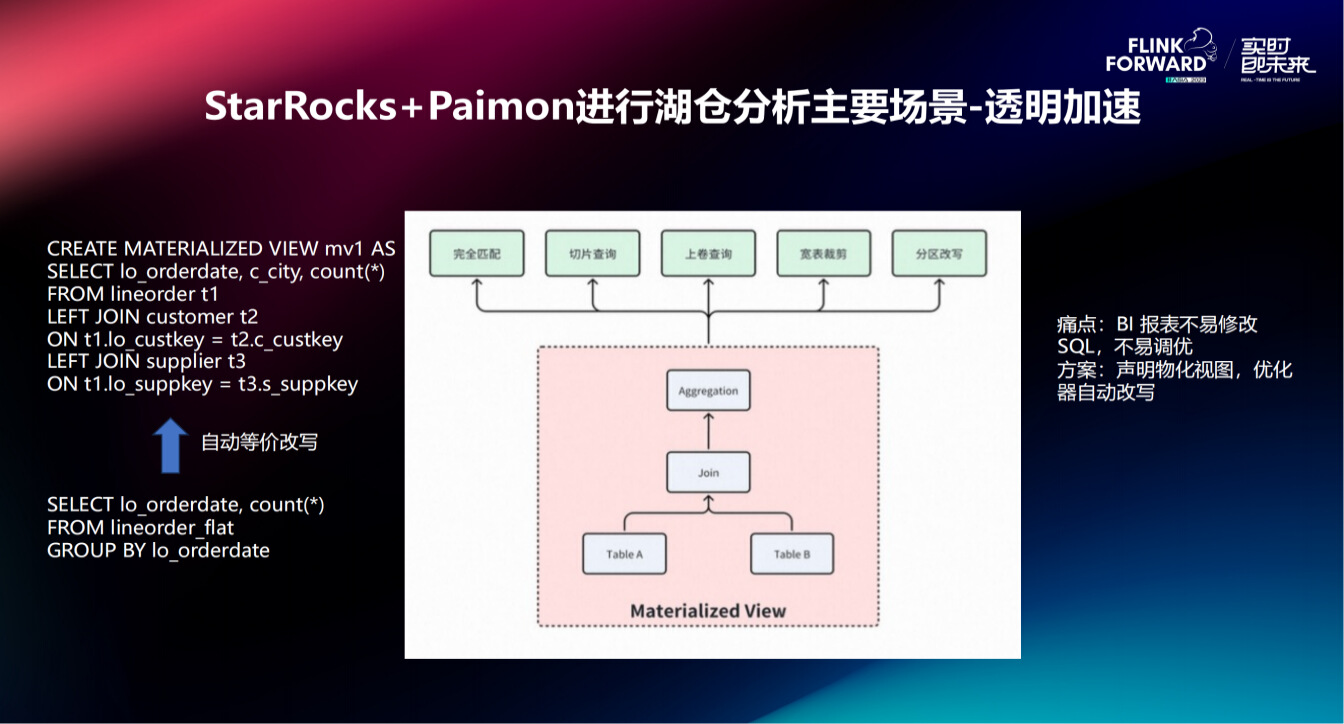
其主要依赖于物化视图功能,而之所以要做物化视图,是因为 StarRocks 有自己的格式,很多特定的优化都是在自有格式的基础上进行的,这些性能优化都是依赖于特定的索引、特定的存储格式等,都需要 StarRocks 自己管理。使用透明加速,可以利用外表的物化视图功能把一些需要加速的表和分区构建成物化视图做成 StarRocks 自有格式,做到加速查询的效果。如图中右侧案例,建立了一个外表物化视图,join 了三个表,但实际业务中并不对三张表都进行查询,而是可能查询其中某一张表或某两张表,StarRocks 可以自动改写 SQL 命中物化视图进行加速查询,解决了 BI 报表不易修改,SQL 不易调优的痛点,该过程对用户是无感知的。
-
数据建模
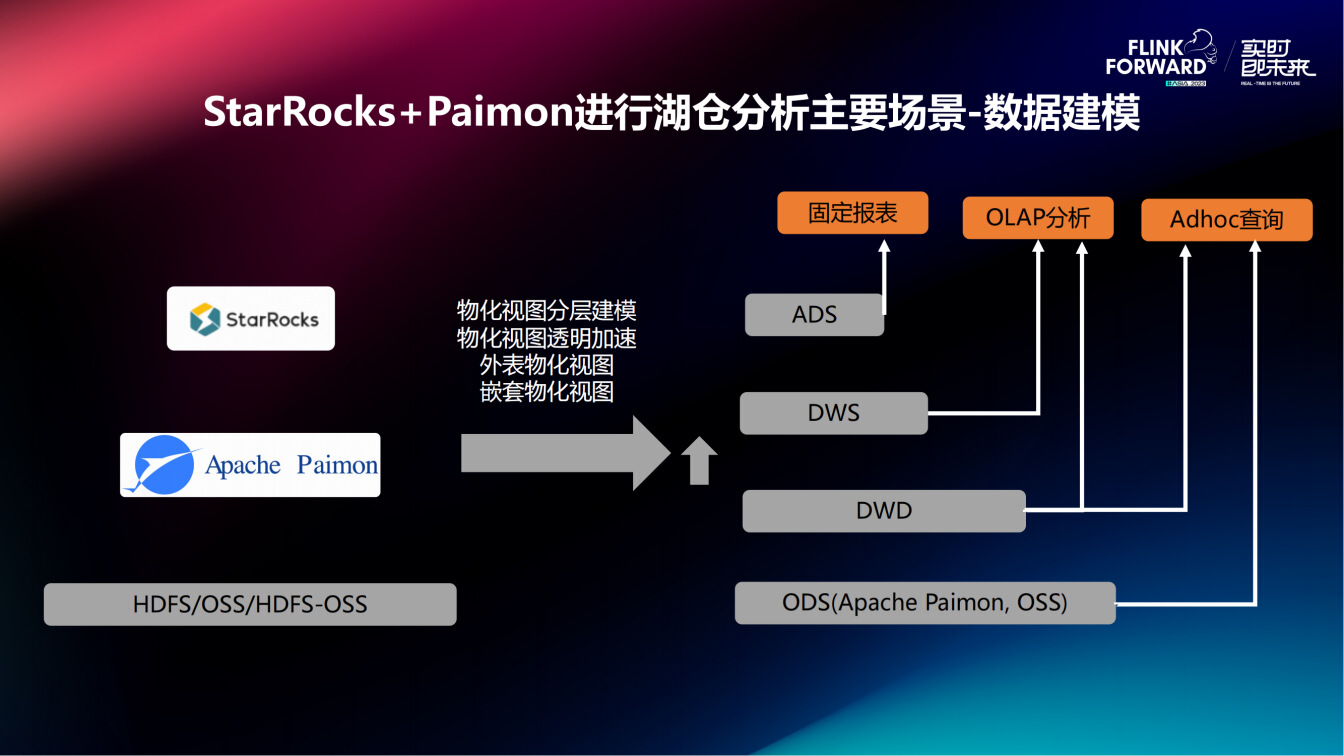
其依赖于 StarRocks 物化视图的嵌套功能,因为 StarRocks 的物化视图并不是只能针对源表进行加速,它可以在物化视图的基础上再建立物化视图,也就是所谓的嵌套的形式。这与平时数据建模相同,最底层是对象存储,包括 HDFS/OSS/HDFS-OSS,ODS 层在数据湖场景使用的多为湖格式,如 Paimon,之后上面的所有层 DWD、DWS、ADS 都可以继续使用物化视图构建。DWD 是直接的外表物化视图,DWS、ADS 是嵌套物化视图,这样就可以把所有层建立联系起来,使用一套系统完成整个数据建模工作。而且,无论查询哪一层,都可以直接使用物化视图的透明加速功能。

-
冷热融合
由于业务每时每刻都在积累数据,但实际上经常需要的仅是查询最近几天或最近几个月的数据,称之为热数据,而更早的、不经常查询的数据称为冷数据。在做数仓时,很多都是按时间进行分区,如天、月、年等。在建立 StarRocks 物化视图时,可以指定一个 TTL,即物化视图的有效时间,如 TTL = 3 months 表示对最近三个月的分区做物化,其余分区不做物化,所有的过程都是自动的,这样,冷数据就可以在廉价的 OSS 存储中存较长的时间,热数据在 StarRocks 里加速查询。当然,并不是所有的作业都只查询热数据,还要查询冷数据。业务编写 SQL 时也无需关心是冷数据,还是热数据,如指定查询五个月的数据,以 TTL = 3 months 为例,StarRocks 会自动将三个月的数据直接从物化视图里读取,剩余两个月的数据再到外表中查,用户无需感知物化视图的存在,就像正常查询一样写外表查询语句就可以。
2.2 技术原理
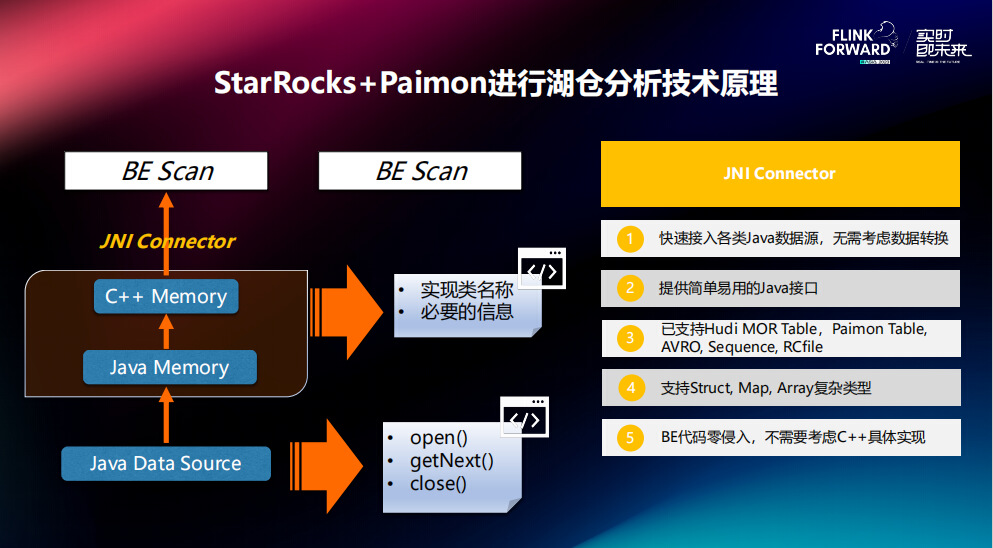
JNI Connector是阿里云团队 2022 年为社区贡献的重大的 Feature 之一。现在不但支持 Paimon,还有 Hudi,AVRO,RCFile 等多种格式。因为 StarRocks 的 BE 端是用 C++ 编写的,而所有的湖格式都是用 Java 编写的,JNI Connector 可以将 C++ Memory 和 Java Memory 转换过程封装起来。在此之前,需要对每个新格式都写一层 JNI 程序,JNI 比较难调试,工作量也会很大。JNI Connector 将所有通用的功能抽取出来,并暴露了三个 Java Reader 接口,即 open、getNext 和 close。在对接新格式时,只需要编写一段 Java 代码,实现这三个接口,再告知 JNI Connector 一些基础和必要信息即可,剩余的各种字段类型的转换,或 String、int 等各种内存之间转换,都会自动完成。JNI Connector 的主要目的就是快速接入各类 Java 数据源,方便开发者编程。如今,JNI Connector 已经支持了很多格式,从最初支持的 Hudi MOR Table 扩展到现在的 Paimon Table、AVR0、Sequence、RCfile,也支持所有的复杂类型,包括 Struct、Map、Array 等。接入新数据源可以实现 BE 代码的零侵入,不需要考虑 C++ 的具体实现。
具体的内存转化原理及过程:

核心原理是,在 Java 堆外内存,针对不同字段类型,参考 StarRocks 在 BE 存储的布局,将数据在 Java 中构造起来。比如,对于 int 字段这类的定长字段(4个字节),其在 BE 中就是按顺序排开存储的,还有 Null indicator 用来指定对应行是否是 null,如果是 null,则无需读取,如果不是 null,再进行读取4个字节,每个 indicator 是一个 byte。这样在 Java 的堆外内存里,按照这样的布局构造之后,在 BE 端直接调用 memory copy 就可以把块内存直接给 C++ 用。
比较特殊的是有变长字段,变长字段比定长字段多了 offset indicator,因为变长字段无法提前知道每一行字段的长度,需要使用 offset indicator 存储每个字段的起始地址,如第一个字段起始地址是 offset 0,第二个字段的起始地址 offset 1,则第一个数据的总长度为 offset 1 - offset 0 +1。下面给出了两个链接,包括最新 Paimon 读取、Hudi MOR 读取支持的实现。
三、StarRocks+Paimon 湖仓分析能力的性能测试
-
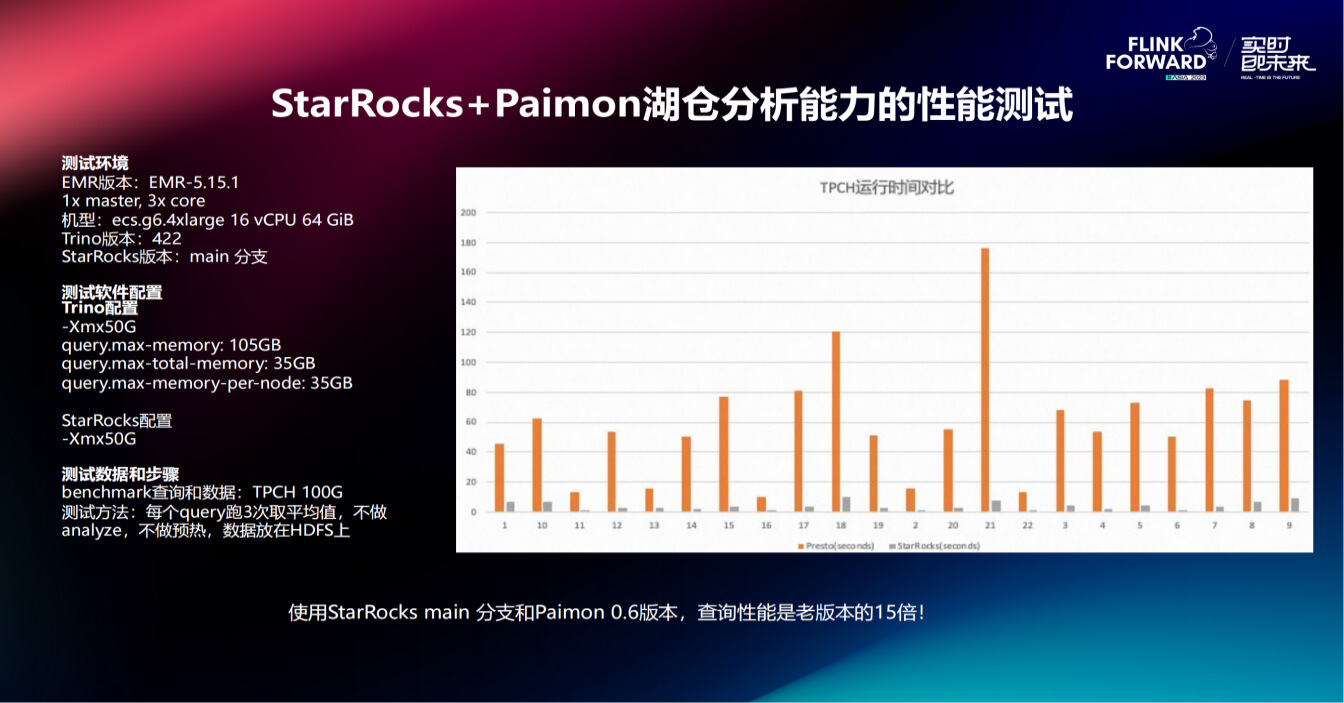
测试环境:
测试环境 EMR 版本是 EMR-5.15.1,1 个 master 节点,3 个 core 节点,配置都相同,都是 16 vCPU 64 GiB,Trino 版本是两个月前新出的 422 版本,StarRocks 版本是 main 分支。 -
测试软件配置:
测试软件的配置仅修改了内存,因为内存机器是 64 GiB,把 Trino 改为 -Xmx50G, StarRocks 也使用 -Xmx50G。 -
测试步骤:
测试 TPCH 100G,每个 query 都测试 3 次,取平均值,不做任何提前 analyze, 不做预热,数据放在 HDFS 上。 -
测试结果:
观察图表,可以发现对比特别明显,在 StarRocks 内核优化以及 Paimon 两个团队的共同努力下,其查询性能是上一版本的 15 倍。
四、StarRocks+Paimon 湖仓分析能力的未来规划

-
支持系统表的查询:
Paimon 中有一些系统表,其本身也有很多元数据,如 snapshot、files、tugs 等都是通过系统表提供的,接下来会支持基础的系统表查询。 -
支持 time travel 和 snapshot 查询:
数据回溯能力。 -
支持 Paimon 外表的 sink 能力:
通过 StarRocks 写 Paimon 外表。 -
优化 date/datetime 类型的处理效率:
这属于 JNI Connector 的范畴,因为现在读取 Paimon 是通过 JNI Connector 进行的,JNI Connector 如今要处理 date/datetime 中间要经过一层 string 转化,其仍旧占用了一部分不必要的开销。 -
接入 unified catalog:
如果查 Hive,则要建 Hive catalog;如果要查 Paimon,则要建 Paimon catalog;需要建两个 catalog,虽然可以联邦查询进行撞义,但用户体验感不佳,接入 unified catalog 后,即使很多用户库中不仅有一种类型的表,都可以只建一个 catalog 即可。 -
使用元数据缓存加速查询:
现在所有 FE 处理 Paimon 时都没有进行元数据缓存,元数据缓存可以减少很多 IO 请求,实现加速。