昨晚和大家聊到 数据库(DataBase)简单概述 ,今天和大家聊聊 关系型数据库(关系数据库) 也就是DataBase(简称DB)的历史,它是以关系模型(Relational Model)来构建的数据存储系统。
关系数据库有个核心的东西”SQL“,它是关系数据库的编程语言。其实,在关系数据库问世以前,就已经有数据库的概念了,之后出现了层次结构、网状结构等不是由关系模型构建的数据库。
今天,我们把这些不是由关系模型构建的数据库统称为 NoSQL,也就是非关系数据库。“No” 最开始想表达 “不是” 关系数据库,从而跟关系数据库划开界限。如今,这个“No”,表达的意思是 Not Only,其含义是 NoSQL不仅仅是非关系数据库,还是对关系数据库一个非常好的补充(把所有不是关系型数据库的数据库统称为NoSQL)。
谈到 History of DataBase,就必须提起关系数据库的奠基人Edgar F. Codd (埃德加·科德)。Codd 从牛津大学数学系毕业后,参加了第二次世界大战,二战胜利后加入了美国的
IBM公司。1969年,他在公司内部刊物上发表了一篇关系型数据库的论述,但由于是 公司内部的刊物,所以并没有得到广泛传播。1970年,Codd在Communications of the ACM上发表了名为A Relational Model of Datafor Large Shared Data Banks(用于大型共享数据库的关系数据模型)的论文(那时候数据库还不叫DataBase,而是Data Banks也就是银行数据仓库),提出了关系模型的概念,奠定了关系型数据库的理论基础。后来,很多人看到这篇文章并以里面的内容为基础,做出了关系型数据库各种各样的产品,其中就包括拉里·埃里森受到Codd的思想和成果的启发了创立甲骨文公司 (主要从事计算机软件和技术的开发、销售和支持,是全球最大的企业级软件公司之一)。随后,Codd又陆续发表多篇文章,论述了范式理论和衡量关系系统的12条标准,用数学理论奠定了关系数据库的基础。

IBM公司则是全球知名的跨国科技公司之一,成立于1911年,总部位于美国纽约州阿蒙克市。它是电子计算机领域的先驱,曾经推出过多款具有历史意义的计算机产品,如IBM System/360、IBM PC等。目前,IBM公司的业务涉及云计算、人工智能、区块链、物联网、大数据等领域,是全球最大的信息技术和服务提供商之一。
统计学工具SPSS(Statistical Package for the Social Sciences)是一款用于统计分析和数据挖掘的软件工具,最初由美国的一家公司开发,后来于2009年被IBM公司收购。自此以后,SPSS成为IBM的一部分,并与IBM的其他产品和服务进行整合。
SPSS软件提供了广泛的统计分析功能,包括描述统计、回归分析、方差分析、聚类分析、因子分析等。它在社会科学、市场研究、医学研究等领域得到了广泛的应用,为用户提供更强大的数据分析和决策支持能力。
了解部分:并不影响我们后续学习
那么什么样的数据库称为关系型数据库呢?满足以下三个特点:
1、理论基础:关系代数(离散数学有提到)
关系代数用于描述和操作关系数据库中的数据,它提供了一组形式化的操作(集合论和一阶逻辑、关系运算),如选择、投影、联接、差异、并集、笛卡尔积等,这些操作都可以通过集合论和一阶逻辑进行严格定义和证明。
1)集合论(交 ∩ 、并∪、补等)和一阶逻辑(谓词、量词、命题等)
一阶逻辑是数理逻辑中的一个重要分支,也称为一阶谓词逻辑或一阶述词逻辑,它是一种用于描述真实世界中命题和量化关系的逻辑系统。一阶逻辑通过使用量词、变元、谓词等符号来建立命题和推理的形式化表示,能够进行精确的推理和证明工作。所谓的一阶逻辑就是把人们用自然语言描述的命题符号化或公式化,便于推导与演算。 一阶逻辑包含一下内容:
个体:具体的事物或抽象的概念
谓词:表示个体性质或彼此关系
量词:全称量词:用符号∀表示 ; 存在量词:用符号ョ表示
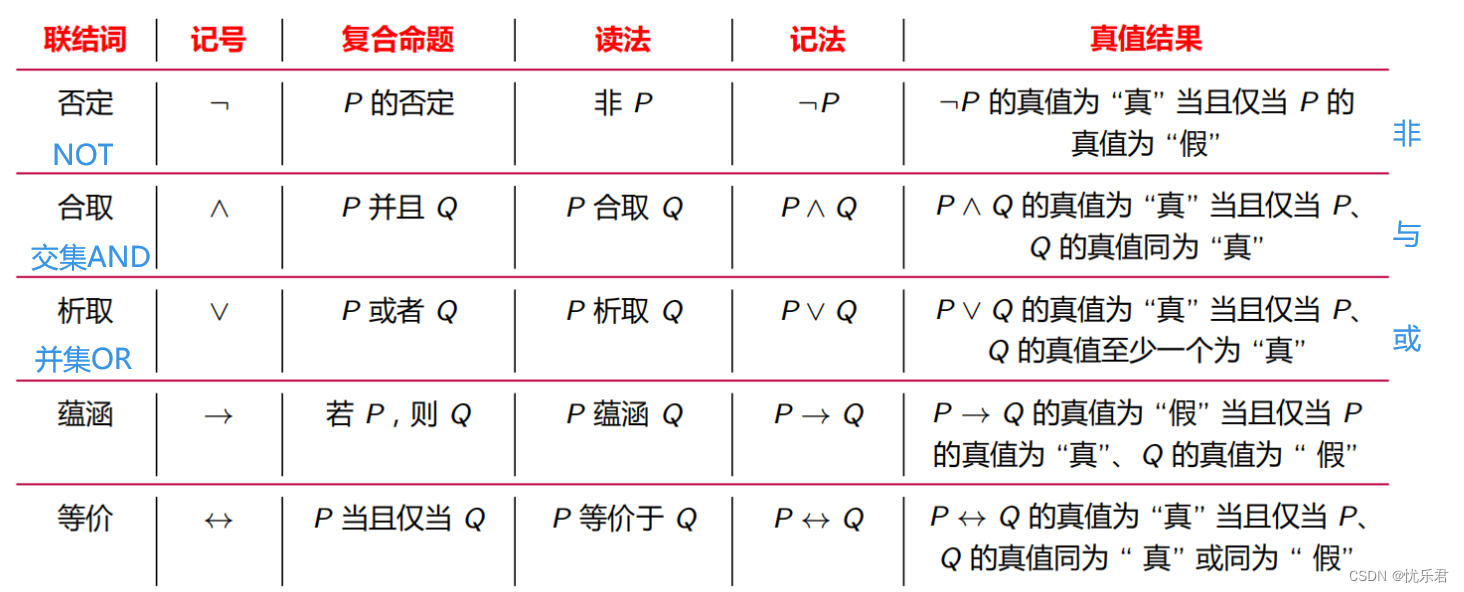
连接符:合取(与)∧、折取(或)∨、否定(非)¬、蕴含→、等价(双向蕴含)↔
虽然叫法不同,但表达的意义是等价的,都有自己专业术语,混合理解更轻松(五个联接词的优先顺序为:否定,合取,析取,蕴涵,等价;)

2)关系运算:选择(σ)、投影(π)、笛卡尔积(x,“叉积”或“交叉连接”)、并集(u)、差集(-)、重命名(ρ)六个原始运算
选择运算符(σ)用于从一个关系中选取满足指定条件的元组;
投影运算符(π)用于从一个关系中选择特定的属性列;
笛卡尔积运算符(x)用于将两个关系中的所有元组进行组合;
并集运算符(u)用于将两个关系中的所有元组合并在一起;
差集运算符(-)用于从一个关系中删除另一个关系中存在的元组;
重命名运算符(ρ)用于对一个关系中的属性列进行重命名。
举例:两个集合 P = {A, B, C} 和 Q = {1, 2, 3} 的笛卡尔积可以表示为:
P × Q = {(A, 1), (A, 2), (A, 3), (B, 1), (B, 2), (B, 3), (C, 1), (C, 2), (C, 3)}
这里,每对括号中的第一个元素来自集合 P,第二个元素来自集合 Q。这些有序对构成了 P 和 Q 的笛卡尔积。
看一眼就好,就好比老师说听不懂没关系听一耳朵就好,毕竟Codd是一个数学大牛,例如他发表的第一篇关于关系型数据库的论文内容他都是用数学知识推导证明成功,可想他有很深的数学功底。如今,我们学习数据库只需了解最基本的这些!!!当然,感兴趣的friend可以找论文钻研琢磨一番,这个过程可能需要求助数学界的大佬。
熟悉部分:方便我们后续学习
2、具体表象:用二维表保存数据
将来我们的数据库系统肯定不只是一张表,而是有很多张表连接在一起。二维表(下面简称表)有行有列,excel就是一个典型的二维表。
需要记忆:
表的每一行是一条记录(record),也称为元组 (tuple)
表的每一列是一个字段 (field),更专业称为属性 (attribute)
行和列交叉单元格就是数据
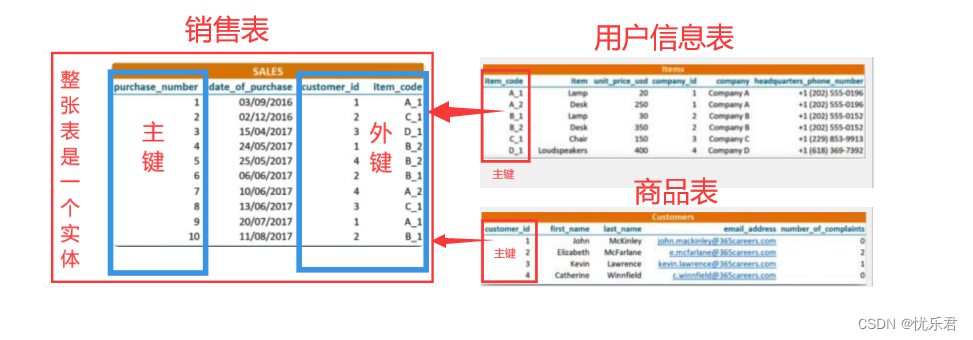
表的主键(primary key):唯一的标识和确定一条记录(独一无二的)
表的外键(foreign key):外来的主键(用于建立表与表之间的关联关系,通过外键可以引用其他表中的主键作为关联条件)
实体(entity):整张表称为实体
简单解析:
销售表中,purchase_number(购买编号或交易流水号)是独一无二的列,我们称为主键,主键在一张表中能够唯一确定一条记录。该表有两个外键:customer_id(用户ID)和 item_code(商品代码),这两个外键分别是用户信息表、商品表的主键,它们在各自表内是独一无二的,能够唯一确定一条记录。
3、编程语言:SQL - 结构化查询语言 Structured query language
读作C扣
这是一个领域特定语言(DSL),与Python这样的通用语言不同,DSL更专注于解决某个具体领域中的问题,具有更高的表达能力和可读性,而Python这样的通用语言很多场景都能用到。
这是一个声明式编程语言,不关注过程,只关注结果。在Python中,需要给一个列表排序,如果这时候并没有排序函数,就需要写排序算法,需要自行实现。在SQL中,只需要申明一下,我要排序即可,数据库底层会自行实现。
结构化查询语言分为四个部分 (加粗部分重点记忆):
数据定义语言(DDL - 建库建表):create - 创建 / drop - 删除 / alter - 修改 / rename / truncate
数据操作语言(DML):insert - 新增 / delete - 删除 / update - 修改 / select - 查询(读写数据、提数)
数据控制语言(DCL):grant / revoke
事务控制语言(TCL):start transaction / commit / rollback
番外:二维表有行有列,让我想到统计学上的二维列联表,它们之间有什么联系吗?
原来,二维列联表是一种特殊形式的二维表,用于统计和分析两个或多个分类变量之间的关系,在二维列联表中,单元格值用于统计和描述行变量与列变量之间的关联程度。

慢慢来,今天先熟悉上述需要记忆的地方,后面会逐一介绍!!!