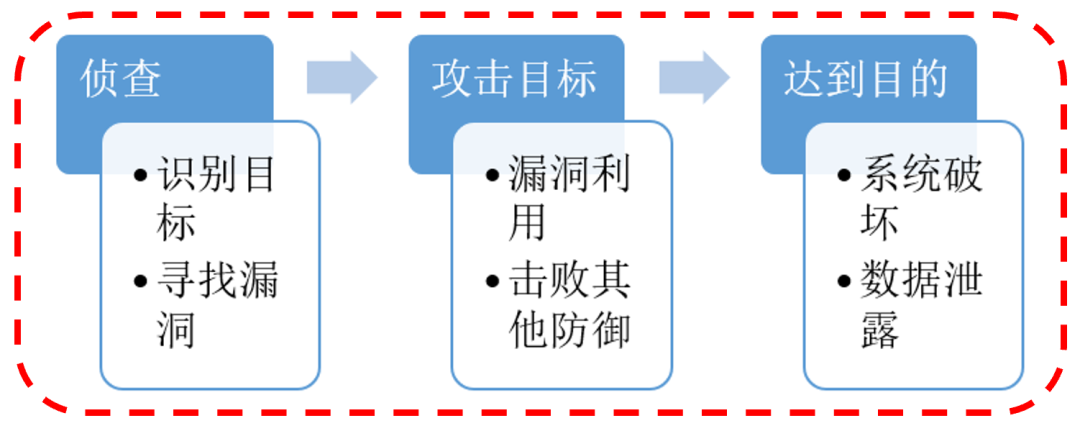
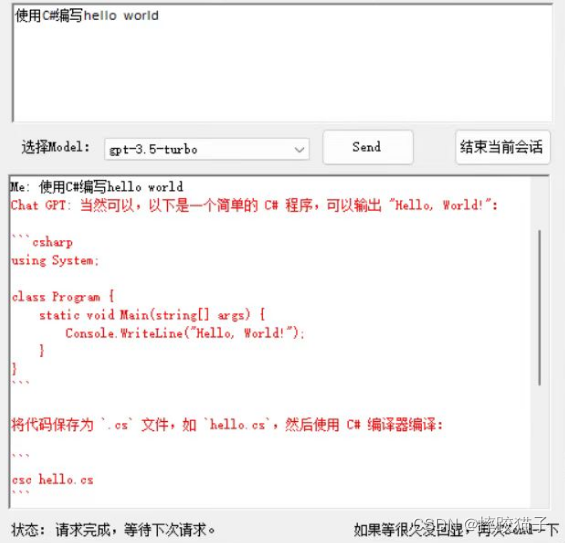
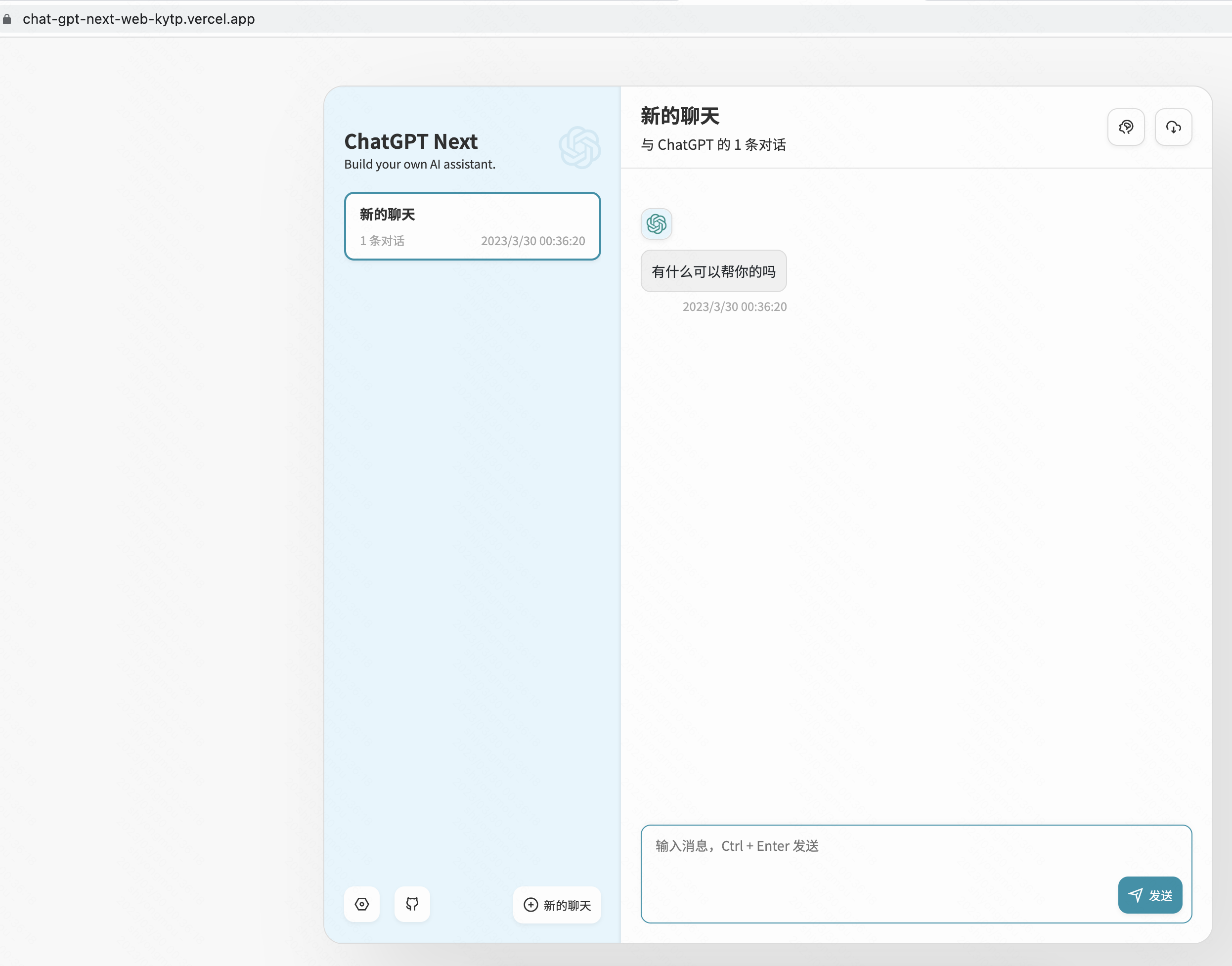
ChatGPT是一个大语言模型(LLM),它根据已有的内容,循环的生成下一个合理的内容,准确的说是一个token。每次循环的时候,都会生成一份带有概率的token列表,从这个概率列表中挑选一个token拼接到文本中。
token挑选规则
挑选文本的规则不是固定的,一般情况下是取概率最高的token,但这会造成生成内容的循环,以及内容看起来很“僵硬”(生成的句子都是包含最常见token的组合,让句子看起来很机械)。所以模型加入了随机挑选因子,会有一定的概率选择不是最大概率的token。
token概率来源
模型会根据网上的资料,统计出每对token出现的概率。例如,生成2个词的概率列表,“我”后面出现“们”的概率是10%,“要”的概率是6%。生成3个词的概率列表,“我们”后面出现“要”的概率是2%,等等。
这里有一个问题,2个token的组合有16亿,3个token的组合有60万亿,要穷举所有长度token组合几乎不可能。这时就要通过LLM来估计出概率。
模型内部结构
ChatGPT内部上一个大的神经网络,包含400多个网络层,网络层之间建立了1750亿个链接,每个链接都有不同的权重。
token筛选流程
一段文本进来的时候,会先拆成token,再将token转出embedding向量,向量进过神经网络层层过滤,最终找到最合适的token。