本文给大家介绍一下在 Spring Boot 项目中如何集成消息队列 RabbitMQ,包含对 RibbitMQ 的架构介绍、应用场景、坑点解析以及代码实战。
我将使用 waynboot-mall 项目作为代码讲解,项目地址:https://github.com/wayn111/waynboot-mall。本文大纲如下,

RabbitMQ 架构介绍

RibbitMQ 是一个基于 AMQP 协议的开源消息队列系统,具有高性能、高可用、高扩展等特点。通常作为在系统间传递消息的中间件,它可以实现异步处理、应用解耦、流量削峰等功能。
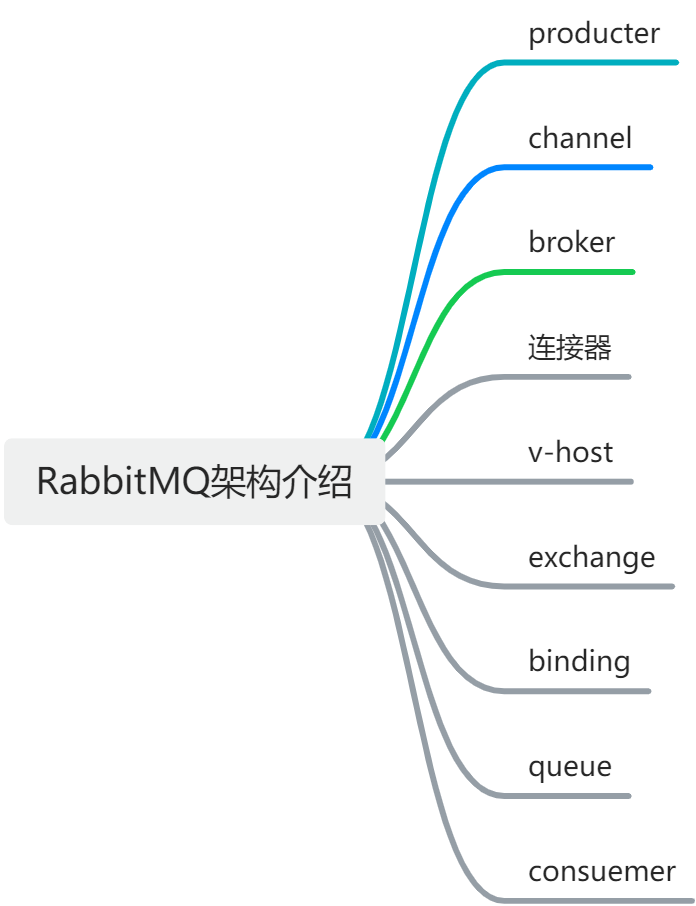
RibbitMQ 的主要组件介绍如下,
-
producter:生产者,创建消息,然后将消息发布(发送)到 RabbitMQ。
-
channel: 信道,多路复用连接中的一条独立的双向数据流通道。信道是建立在真实的 TCP 连接内地虚拟链接,AMQP 命令都是通过信道发出去的,不管是发布消息、订阅队列还是接收消息,这些动作都是通过信道完成。因为对于操作系统来说,建立和销毁 TCP 都是非常昂贵的开销,所以引入了信道的概念,以复用一条 TCP 连接。
-
broker: 标识消息队列服务器实体 rabbitmq-server。
-
连接器:这是负责接收客户端连接请求和建立连接的组件。RabbitMQ 支持多种连接器,如 AMQP 0-9-1, AMQP 1.0, MQTT, STOMP 等。
-
v-host:虚拟主机,这是 RabbitMQ 的逻辑隔离单元,每个虚拟主机相当于一个独立的代理,拥有自己的交换器、队列、绑定、权限等。不同的虚拟主机之间是相互隔离的,不能共享资源。一个 RabbitMQ 实例可以创建多个虚拟主机,以满足不同的业务需求。
-
exchange:交换机,这是负责接收生产者发送的消息,并根据路由规则将消息分发到相应的队列或者其他交换器的组件。RabbitMQ 支持多种类型的交换器,如 fanout, direct, topic, headers 等。
-
binding:绑定,这是负责将交换器和队列之间建立关联关系的组件。绑定可以指定一个路由键或者模式匹配规则,以决定哪些消息可以被路由到哪些队列。
-
queue:队列,这是负责存储消费者需要消费的消息的组件。队列可以有多种属性和特性,如持久化、排他性、自动删除、死信队列、优先级队列等。队列可以绑定到一个或多个交换器上,并指定一个或多个路由键或者模式匹配规则。
-
consuemer:消费者,连接到 RabbitMQ 服务器,并订阅到队列上,接收来自队列的消息。
应用场景

RabbitMQ 是一个非常强大和灵活的消息中间件,它可以应用于多种场景和需求。以下是一些常见的 RabbitMQ 应用场景和实战经验:
-
异步处理:当系统需要执行一些耗时或者不重要的任务时,可以使用 RabbitMQ 将任务封装成消息发送到队列中,然后由专门的消费者来异步地执行这些任务。这样可以提高系统的响应速度和用户体验,同时也可以避免因为任务失败或超时而影响主流程的执行。例如在 waynboot-mall 项目中,用户下单后需要发送邮件通知,这个任务就可以使用 RabbitMQ 异步处理。
-
流量削峰:当系统面临突发的高并发请求时,如果直接让所有请求打到后端服务器上,可能会导致服务器崩溃或者响应缓慢。这时可以使用 RabbitMQ 作为一个缓冲层,将请求先发送到队列中,然后由后端服务器按照自己的处理能力从队列中拉取请求进行处理。这样可以平滑地分摊请求压力,避免系统崩溃或者服务降级。例如,在 waynboot-mall 项目中,每天晚上八点有秒杀活动,这时可以使用 RabbitMQ 来削峰限流,保证系统的稳定运行。
-
消息广播:当系统需要将消息发送到多个接收方时,可以使用 RabbitMQ 的发布/订阅模式,将消息发送到一个 fanout 类型的交换器上,然后由多个队列绑定到这个交换器上,从而实现消息的广播功能。这样可以实现一对多的消息通信,同时也可以根据不同的业务需求,订阅不同的消息内容。例如,在 waynboot-mall 项目中,当商品信息发生变化时,需要通知搜索系统、推荐系统、缓存系统等多个系统,这时可以使用 RabbitMQ 的消息广播功能。
-
消息路由:当系统需要根据不同的条件将消息发送到不同的接收方时,可以使用 RabbitMQ 的路由模式,将消息发送到一个 direct 或者 topic 类型的交换器上,然后由多个队列绑定到这个交换器上,并指定不同的路由键或者模式匹配规则,从而实现消息的路由功能。这样可以实现多对多的消息通信,同时也可以灵活地控制消息的分发和消费。例如,在 waynboot-mall 项目中,当订单状态发生变化时,需要通知不同的系统进行不同的处理,这时可以使用 RabbitMQ 的消息路由功能。
坑点分析

在使用 RabbitMQ 的过程中,有一些常见的问题需要注意:
-
消息确认:消息确认是 RabbitMQ 保证消息可靠传递的机制。消息确认分为生产者确认和消费者确认。生产者确认是指生产者发送消息后,等待 RabbitMQ 返回一个确认消息,表明消息已经被正确接收和存储。消费者确认是指消费者接收消息后,向 RabbitMQ 发送一个确认消息,表明消息已经被正确处理和消费。在 waynboot-mall 项目中,消费者开启了手动消息确认。
-
消息持久化:消息持久化是指将消息存储到磁盘上,以防止 RabbitMQ 重启或者崩溃时丢失消息。消息持久化需要满足以下三个条件:交换器、队列和消息都需要设置为持久化。持久化会影响 RabbitMQ 的性能,因为需要进行磁盘 IO 操作。建议根据业务需求选择是否需要持久化消息,并合理地配置磁盘空间和清理策略。在 waynboot-mall 项目中,交换器、队列设置了持久化,消息没有设置持久化(消息设置持久化会对 RabbitMQ 的性能造成较大影响)。
-
死信队列:死信队列是指存储那些因为某些原因无法被正常消费的消息的队列。死信队列可以用来处理一些异常或者失败的情况,如消息过期、队列达到最大长度、消费者拒绝等。建议使用死信队列来监控和处理这些情况,并根据业务需求选择合适的重试或者补偿策略。在 waynboot-mall 项目中,当订单消费者处理消息失败重试三次后,会将订单消息发送到死信队列。
-
集群和镜像:集群和镜像是 RabbitMQ 实现高可用和高扩展的两种方式。集群是指将多个 RabbitMQ 实例组成一个逻辑单元,共享元数据和负载均衡。镜像是指将同一个队列在多个节点上创建副本,实现数据冗余和容错。建议根据业务需求选择合适的集群模式和镜像类型,并注意集群中的网络分区、脑裂等问题。
代码实战
在 waynboot-mall 项目中,消息层包含两个模块 waynboot-message-core 以及 waynboot-message-consumer,目录结构如下,
|-- waynboot-message-core // 核心消息配置,供其他服务集成使用
| |-- config
| |-- constant
| |-- dto
|-- waynboot-message-consumer // 消息消费服务,订阅队列接收消息,调用其他服务执行一些具体的业务逻辑
| |-- api
| |-- config
| |-- consumer
waynboot-message-core 包目录说明如下,
-
config:核心消息配置目录,包含业务上使用的订单消息、邮件消息、死信消息、延迟消息的交换机、队列、路由绑定配置以及 RabbitTemplate 配置。
-
constants:核心消息配置的相关常量目录,包含 MQ 的常量类,这里面会定义订单、邮件、死信、延迟消息的交换机名称、队列名称、路由键名称等。
-
dto:核心消息配置的数据转换实体目录,包含 OrderDTO 等。
waynboot-message-consumer 包目录说明如下,
-
api:消息消费服务调用其他服务定义的 api 包目录,包含 MobileApi 类用来调用 moibile-api。
-
config:消息消费服务的核心配置目录,包含 RestTemplate 配置类。
-
consumer:消息消费服务的消费者包目录,包含下单、发送邮件、未支付订单超时取消等消费者。
添加 POM 依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId><version>${spring-boot.version}</version>
</dependency>
指定虚拟主机

在 waynboot-mall 项目中,通过 yml 文件的 spring.rabbitmq.virtual-host=“/” 属性来指定虚拟主机名称。
建议大家在使用 RabbitMQ 时都配置好自己项目的虚拟主机名称,来达到各系统资源隔离的目的。当然如果 RabbitMQ 服务只有一个项目在用,那就用默认的 / 作为虚拟主机名称也是可以的。
小知识:出于多租户和安全因素设计的,vhost 把 AMQP 的基本组件划分到一个虚拟的分组中。每个 vhost 本质上就是一个 mini 版的 RabbitMQ 服务器,拥有自己的队列、交换机、绑定和权限机制。当多个不同的用户使用同一个 RabbitMQ 服务器时,可以划分出多个虚拟主机。RabbitMQ 默认的虚拟主机路径是 /。
生产者发送消息
在 waynboot-mall 项目中,用订单消息来举例,生产者发送消息需要经过三个步骤
1. 创建订单消息的交换机、队列以及路由绑定
public class MQConstants {public static final String ORDER_DIRECT_QUEUE = "order_direct_queue";public static final String ORDER_DIRECT_EXCHANGE = "order_direct_exchange";public static final String ORDER_DIRECT_ROUTING = "order_direct_routing";
}@Configuration
public class BusinessRabbitConfig {@Beanpublic Queue orderDirectQueue() {return new Queue(MQConstants.ORDER_DIRECT_QUEUE);}@BeanDirectExchange orderDirectExchange() {return new DirectExchange(MQConstants.ORDER_DIRECT_EXCHANGE);}@BeanBinding bindingOrderDirect() {return BindingBuilder.bind(orderDirectQueue()).to(orderDirectExchange()).with(MQConstants.ORDER_DIRECT_ROUTING);}}
在 BusinessRabbitConfig 中,我们创建了订单交换机、队列以及路由绑定关系。在 Spring 项目中,项目启动时,就会自动在 RabbitMQ 服务器上创建好这些东西。
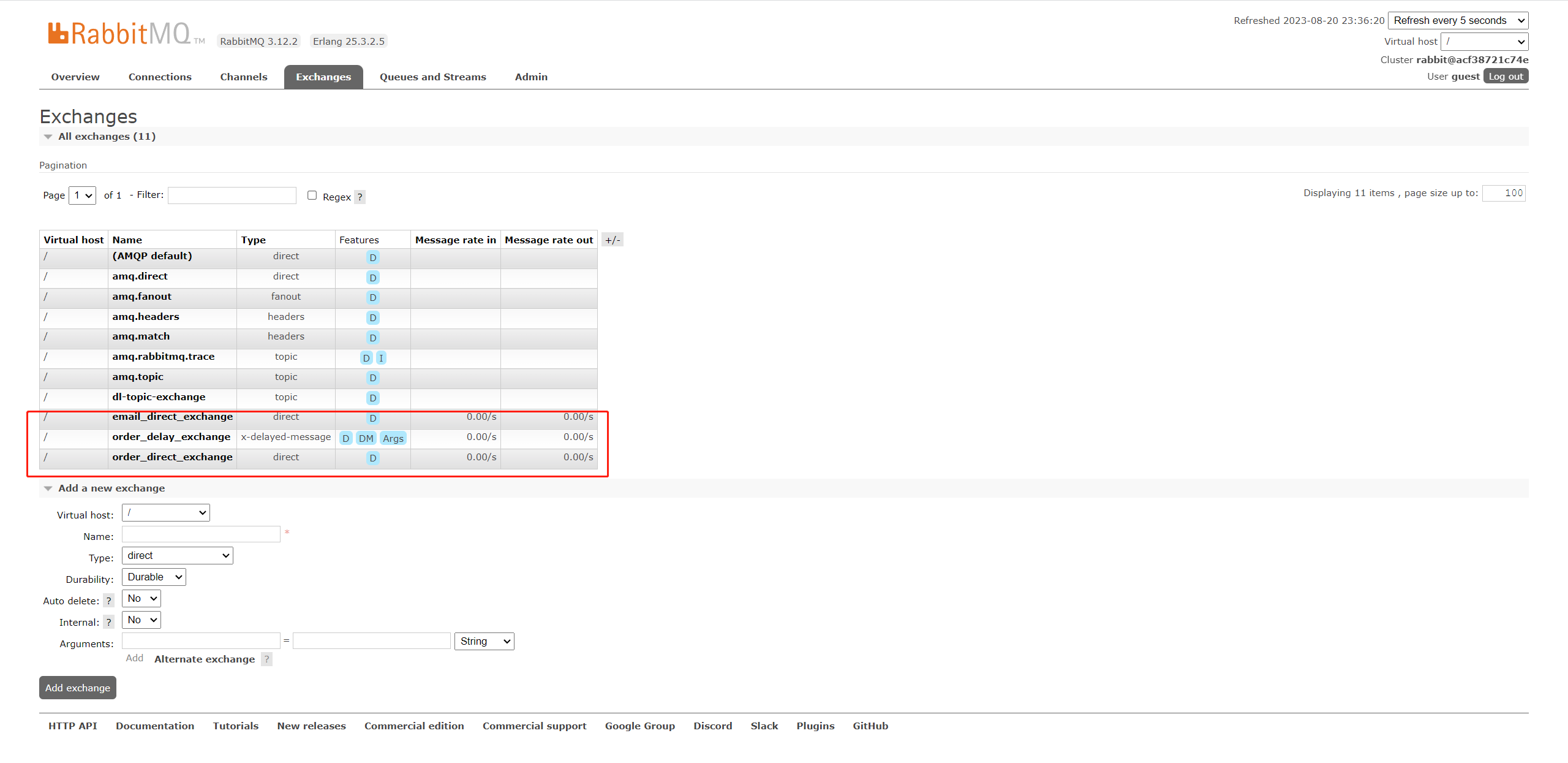
交换机列表

队列列表
2. 生产者配置
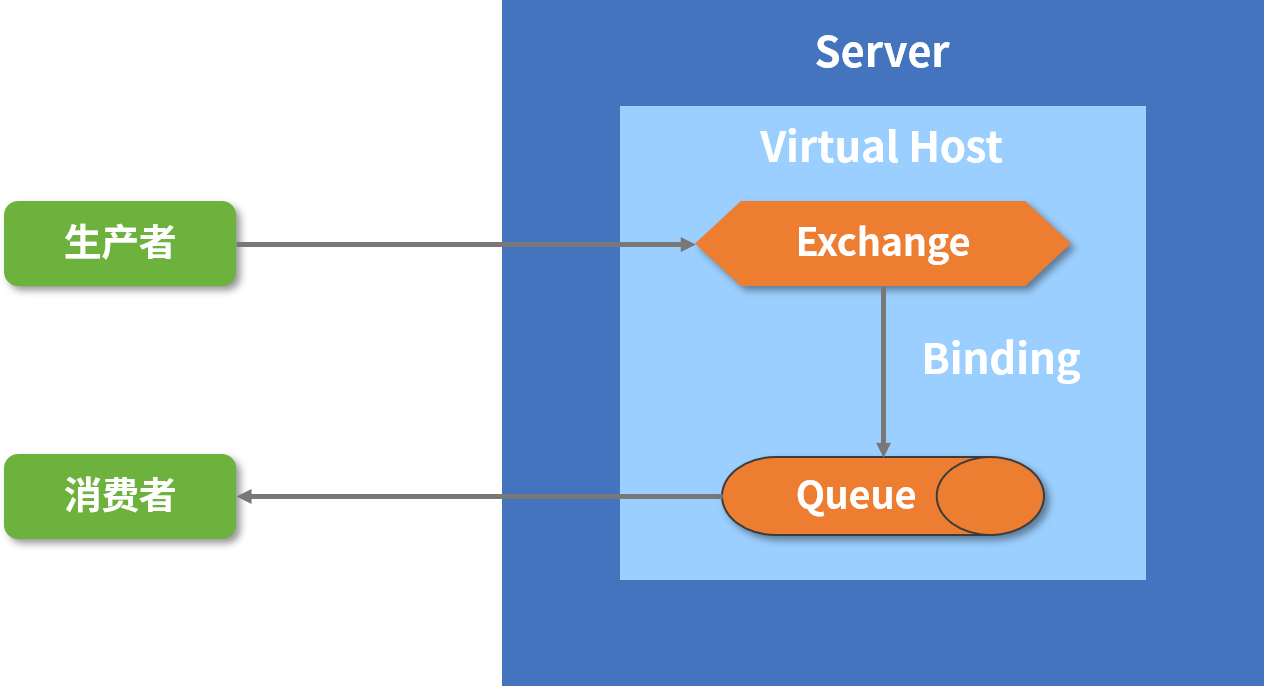
生产者的消息发送确认主要包含两部分,
producter -> rabbitmq broker exchange -> queue
-
消息从 producte( 生产者)发送到 rabbitmq broker(RabbitMQ 服务器)的交换机中,发送后会触发 confirmCallBack 回调
-
消息从 exchange 发送到 queue,投递失败则会调用 returnCallBack 回调
waynboot-mall 项目的 yml 中关于 RabbitMQ 的相关配置如下,
spring:# 配置rabbitMq 服务器rabbitmq:host: 127.0.0.1port: 5672username: guestpassword: guest# 消息确认配置项# 确认消息已发送到交换机(Exchange)publisher-confirm-type: correlated# 确认消息已发送到队列(Queue)publisher-returns: true# 虚拟主机名称virtual-host: /
publisher-confirm-type 属性
可以看到,我们设置了 publisher-confirm-type 属性为 correlated,表示开启发布确认模式,用来确认消息已发送到交换机,publisher-confirm-type 有三个选项:
-
NONE:禁用发布确认模式,是默认值
-
CORRELATED:发布消息成功到交换器后会触发回 confirmCallBack 回调方法
-
SIMPLE:经测试有两种效果,其一效果和 CORRELATED 值一样会触发回调方法,其二在发布消息成功后使用 rabbitTemplate 调用 waitForConfirms 或 waitForConfirmsOrDie 方法等待 broker 节点返回发送结果,根据返回结果来判定下一步的逻辑,要注意的点是 waitForConfirmsOrDie 方法如果返回 false 则会关闭 channel,则接下来无法发送消息到 broker。
publisher-returns 属性
在 RabbitMQ 中,消息发送到交换机中也不代表消费者一定能接收到消息,所以我们还需要设置 publisher-returns 为 true 来表示确认交换机中消息已经发送到队列里。true 表示开启失败回调,开启后当消息无法路由到指定队列时会触发 ReturnCallback 回调。
接着是 RabbitTemplateConfig 的代码,这里面会定义前面提到的 confirmCallBack、returnCallBack 相关代码,
@Slf4j
@Component
public class RabbitTemplateConfig {@Beanpublic RabbitTemplate rabbitTemplate(CachingConnectionFactory connectionFactory) {RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory);// 设置开启Mandatory,才能触发回调函数,无论消息推送结果怎么样都强制调用回调函数rabbitTemplate.setMandatory(true);// 交换机收到消息回调rabbitTemplate.setConfirmCallback((correlationData, ack, cause) -> log.info("消息发送成功:correlationData({}),ack({}),cause({})", correlationData, ack, cause));// 队列收到消息回调,如果失败的话会进行 returnCallback 的回调处理,反之成功就不会回调。rabbitTemplate.setReturnsCallback(returned -> {log.info("returnCallback: " + "消息:" + returned.getMessage());log.info("returnCallback: " + "回应码:" + returned.getReplyCode());log.info("returnCallback: " + "回应信息:" + returned.getReplyText());log.info("returnCallback: " + "交换机:" + returned.getExchange());log.info("returnCallback: " + "路由键:" + returned.getRoutingKey());});return rabbitTemplate;}
}
在 RabbitTemplateConfig 类代码里,我们可以设置 confirmCallBack、returnCallBack 回调函数后,监控生产者发送消息是否被交换机接收、以及交换机是否把消息发送到队列中。
3. 使用 RabbitTemplate 发送消息
在 Spring Boot 项目中,集成了 spring-boot-starter-amqp 依赖后,就可以直接注入 RabbitTemplate 来发送消息。
这里用 waynboot-mall 项目中的异步下单流程举例,代码如下,
@Slf4j
@Service
@AllArgsConstructor
public class OrderServiceImpl extends ServiceImpl<OrderMapper, Order> implements IOrderService {private RabbitTemplate rabbitTemplate;@Overridepublic R asyncSubmit(OrderVO orderVO) {OrderDTO orderDTO = new OrderDTO();...// 开始异步下单String uid = IdUtil.getUid();// 1. 创建消息ID,确认机制发送消息时,需要给每个消息设置一个全局唯一 id,以区分不同消息,避免 ack 冲突CorrelationData correlationData = new CorrelationData(uid);// 2. 创建消息载体 Message ,AMQP 规范中定义的消息承载类,用来在生产者和消费者之前传递消息Map<String, Object> map = new HashMap<>();map.put("order", orderDTO);map.put("notifyUrl", WaynConfig.getMobileUrl() + "/callback/order/submit");try {Message message = MessageBuilder.withBody(JSON.toJSONString(map).getBytes(Constants.UTF_ENCODING)).setContentType(MessageProperties.CONTENT_TYPE_TEXT_PLAIN).setDeliveryMode(MessageDeliveryMode.PERSISTENT).build();// 3. 发送消息到 RabbitMQ 服务器,需要指定交换机、路由键、消息载体以及消息IDrabbitTemplate.convertAndSend(MQConstants.ORDER_DIRECT_EXCHANGE, MQConstants.ORDER_DIRECT_ROUTING, message, correlationData);} catch (UnsupportedEncodingException e) {log.error(e.getMessage(), e);}return R.success().add("actualPrice", actualPrice).add("orderSn", orderSn);}
}
waynboot-mall 项目中在使用 rabbitTemplate 发送消息时,按照如下步骤,大家可以参考
-
创建消息 ID,确认机制发送消息时,需要给每个消息设置一个全局唯一 id,以区分不同消息,消费者消费时出现 ack 冲突。
-
创建消息载体 Message ,AMQP 规范中定义的消息承载类,用来在生产者和消费者之前传递消息。
-
发送消息到 RabbitMQ 服务器,需要指定交换机、路由键、消息载体以及消息 ID。
以上就是生产者发送消息时所有相关代码了,接着我们看下消费者处理消息的相关代码。
消费者处理消息
在 waynboot-mall 项目中,还是用订单消息来举例,消费者 yml 配置如下,
1. 消费者配置
在 RabbitMQ 的消息消费环节,需要注意的一点就是,如果需要确保消费者不出现漏消费,则需要开启消费者的手动 ack 模式。
spring:rabbitmq:host: 127.0.0.1port: 5672username: guestpassword: guest...listener:simple:# 消息确认方式,其有三种配置方式,分别是none、manual(手动ack) 和auto(自动ack) 默认autoacknowledge-mode: manual# 一个消费者最多可处理的nack(未确认)消息数量,默认是250prefetch: 250# 设置消费者数量concurrency: 1
acknowledge-mode 属性
在 yml 文件的消费者配置中,acknowledge-mode 属性用于指定消息确认模式,有三种模式:
-
手动确认 manual,在该模式下,消费者消费消息后需要根据消费情况给 Broker 返回一个回执,是确认 ack 使 Broker 删除该条已消费的消息,还是失败确认返回 nack,还是拒绝该消息。开启手动确认后,如果消费者接收到消息后还没有返回 ack 就宕机了,这种情况下消息也不会丢失,只有 RabbitMQ 接收到返回 ack 后,消息才会从队列中被删除。
-
自动确认 none,rabbitmq 默认消费者正确处理所有请求(不设置时的默认方式)。
- 根据请况确认 auto,主要分成以下几种情况:
-
如果消费者在消费的过程中没有抛出异常,则自动确认。
-
当消费者消费的过程中抛出 AmqpRejectAndDontRequeueException 异常的时候,则消息会被拒绝,且该消息不会重回队列。
-
当抛出 ImmediateAcknowledgeAmqpException 异常,消息会被确认。
-
如果抛出其他的异常,则消息会被拒绝,但是与前两个不同的是,该消息会重回队列,如果此时只有一个消费者监听该队列,那么该消息重回队列后又会推送给该消费者,会造成死循环的情况。
-
prefetch 属性
消费者配置中,prefetch 属性用于指定消费者每次从队列获取的消息数量。
每个 customer 会在 MQ 预取一些消息放入内存的 LinkedBlockingQueue 中进行消费,这个值越高,消息传递的越快,但非顺序处理消息的风险更高。如果 ack 模式为 none,则忽略。
prefetch 默认值以前是 1,这可能会导致高效使用者的利用率不足。从 spring-amqp 2.0 版开始,默认的 prefetch 值是 250,这将使消费者在大多数常见场景中保持忙碌,从而提高吞吐量。
不过在有些情况下,尤其是处理速度比较慢的大消息,消息可能在内存中大量堆积,消耗大量内存;以及对于一些严格要求顺序的消息,prefetch 的值应当设置为 1。
对于低容量消息和多个消费者的情况(也包括单 listener 容器的 concurrency 配置)希望在多个使用者之间实现更均匀的消息分布,建议在手动 ack 下并设置 prefetch=1。
如果要保证消息的可靠不丢失,当 prefetch 大于 1 时,可能会出现因为服务宕机引起的数据丢失,故建议将 prefetch=1。
concurrency 属性
消费者配置中,concurrency 属性设置的是对每个 listener 在初始化的时候设置的并发消费者的个数。在上面的 yml 配置中,concurrency=1,即每个 Listener 容器将开启一个线程去处理消息。在 2.0 以后的版本中,可以在注解中配置该参数,实例代码如下,
@RabbitListener(queues = MQConstants.ORDER_DIRECT_QUEUE, concurrency = "2")
public void process(Channel channel, Message message) throws IOException {String body = new String(message.getBody());log.info("OrderPayConsumer 消费者收到消息: {}", body);...
}
2. 使用 RabbitListener 注解消费消息
在 waynboot-mall 项目中,消费者监听队列代码如下,
@Slf4j
@Component
public class OrderPayConsumer {@Resourceprivate RedisCache redisCache;@Resourceprivate MobileApi mobileApi;@RabbitListener(queues = MQConstants.ORDER_DIRECT_QUEUE)public void process(Channel channel, Message message) throws IOException {// 1. 转换订单消息String body = new String(message.getBody());log.info("OrderPayConsumer 消费者收到消息: {}", body);// 2. 获取消息IDString msgId = message.getMessageProperties().getHeader("spring_returned_message_correlation");// 3. 获取发送taglong deliveryTag = message.getMessageProperties().getDeliveryTag();// 4. 消费消息幂等性处理if (redisCache.getCacheObject(ORDER_CONSUMER_MAP.getKey()) != null) {// redis中包含该 key,说明该消息已经被消费过log.error("msgId: {},消息已经被消费", msgId);channel.basicAck(deliveryTag, false);// 确认消息已消费return;}try {// 5. 下单处理mobileApi.submitOrder(body);// 6. 手动ack,消息成功确认channel.basicAck(deliveryTag, false);// 7. 设置消息已被消费标识redisCache.setCacheObject(ORDER_CONSUMER_MAP.getKey(), msgId, ORDER_CONSUMER_MAP.getExpireSecond());} catch (Exception e) {channel.basicNack(deliveryTag, false, false);log.error(e.getMessage(), e);}}
}
waynboot-mall 项目中在使用 RabbitListener 注解消费消息时,按照如下步骤,大家可以参考
-
将 message 参数转换成订单消息。
-
从 message 参数中获取消息唯一 msgId。
-
从 message 参数中获取消息发送 tag。
-
幂等性处理,根据第二步获取的 msgId ,消费消息时需要先判断 msgId 是否已经被处理。
-
调用 mobile-api 服务,进行下单逻辑处理,在 mobileApi.submitOrder(body) 方法中使用 Spring-Retry 的 @Retryable 注解,进行自动重试。
-
手动 ack,basicAck(long deliveryTag, boolean multiple)。basicAck 方法表示成功确认,使用此方法后,消息就会被 rabbitmq 服务器删除。
其中参数 long deliveryTag 为消息的唯一序号也就是第三步获取的发送 tag,第二个 boolean multiple 参数表示是否一次消费多条消息,false 表示只确认该序列号对应的消息,true 则表示确认该序列号对应的消息以及比该序列号小的所有消息,比如我先发送 2 条消息,他们的序列号分别为 2,3,并且他们都没有被确认,还留在队列中,那么如果当前消息序列号为 4,那么当 multiple 为 true,则序列号为 2、3 的消息也会被一同确认。
-
幂等性处理,消息已经被成功消费后,根据第二步获取的 msgId 设置幂等标识。
总结一下
这篇文章给大家讲解了在 Spring Boot 项目中如何集成消息队列 RabbitMQ 用于业务逻辑解耦,有架构介绍、应用场景、坑点解析、代码实战 4 个部分,能带领大家比较全面的了解一波 RabbitMQ。大家在自己的项目中如果需要引入 RabbitMQ 时,都可以参考本文的代码实战配置,帮助大家快速集成、避免踩坑。




![【C++入门到精通】C++的IO流(输入输出流) [ C++入门 ]](https://img-blog.csdnimg.cn/direct/686178f7f6ea4d23a2e3953d816d3215.png)