大家好,我是微学AI,今天给大家介绍一下深度学习技巧应用35-L1 正则化和L2正则在神经网络模型训练中的应用。L1正则化和L2正则化是机器学习中常用的两种正则化方法,用于防止模型过拟合并提高模型的泛化能力。这两种正则化方法通过在损失函数中添加惩罚项来控制模型的复杂性。在实际应用中,选择L1正则化还是L2正则化取决于具体问题和数据的特征。例如,L1正则化生成稀疏模型,这在需要特征选择时非常有利。另一方面,L2正则化鼓励使用较小但非零的系数,并且在特征之间存在强相关性时更适合。有时,还会使用L1和L2正则化的组合(称为弹性网络正则化),以同时受益于这两种技术的优势。
一、L1正则化和L2正则化的介绍
L1正则化和L2正则化的数学原理
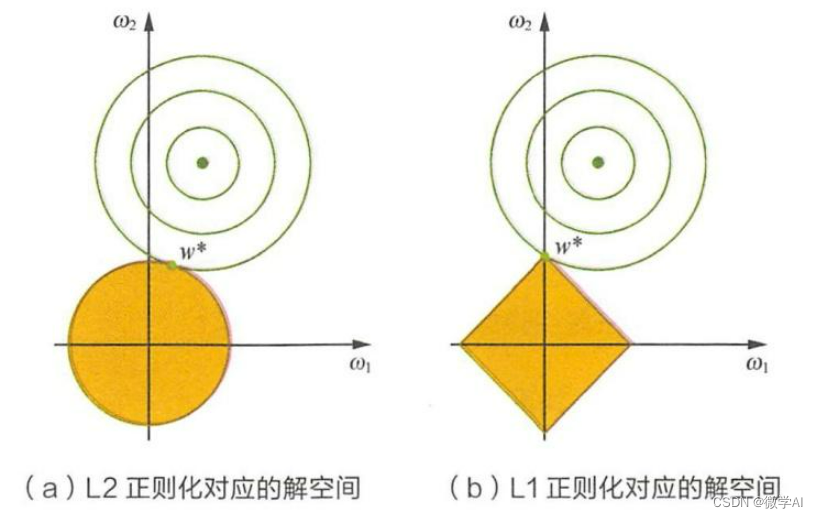
L1正则化和L2正则化是机器学习中常用的两种正则化技术,用于防止模型过拟合。正则化通过对模型的复杂度进行惩罚,从而限制模型的自由度。
L1正则化(Lasso正则化)
L1正则化的公式是在原始的损失函数基础上增加一个L1范数项,即权重向量的绝对值之和。L1正则化的损失函数可以表示为:
J (