一、万古霉素
是一种杀菌型 抗生素,抑制细菌细胞壁的合成
万古霉素对以下细菌有效:
-
大多数革兰阳性球菌和杆菌有抗菌活性,包括几乎所有耐青霉素和头孢菌素的 Staphylococcus aureus 和凝固酶阴性葡萄球菌株
-
许多菌株 肠球菌 (大多 Enterococcus faecalis)
但许多肠球菌菌株和一些S. aureus株对其耐药。
万古霉素是由下列细菌引起严重感染和 心内膜炎治疗常用药物(除万古霉素耐药株):
-
耐甲氧西林金黄色葡萄球菌S. aureus
-
耐甲氧西林凝固酶阴性葡萄球菌
-
耐beta-内酰胺类和多药耐药的 肺炎链球菌
-
beta-溶血性链球菌(当beta-内酰胺类药物过敏或耐药而不能使用时)
-
Corynebacterium属包括 C. jeikeium, 和 C. striatum
-
草绿色链球菌(当beta-内酰胺类药物过敏或耐药而不能使用时)
-
肠球菌(当beta-内酰胺类药物过敏或耐药而不能使用时)
万古霉素治疗甲氧西林敏感的S. aureus感染,与beta-内酰胺类抗葡萄球菌青霉素相比效果差。当治疗耐甲氧西林凝固酶阴性葡萄球菌感染引起的瓣膜修补术后心内膜炎或肠球菌心内膜炎时,万古霉素需联合其他抗生素。万古霉素虽然透过脑脊液不稳定(特别和地塞米松同时治疗时),万古霉素也已经用来治疗对青霉素敏感性降低的肺炎球菌引起的 脑膜炎。当单独治疗肺炎球菌性脑膜炎,临床治疗失败的报告表明其并非最佳药物。
万古霉素口服被用来治疗 艰难梭菌(以前称梭菌属)感染导致的腹泻(假膜性肠炎)。对于初始发生的非严重C. difficile感染,推荐万古霉素而不是甲硝唑。治疗严重 C. difficile 感染,万古霉素优于甲硝唑。同时作为i对甲硝唑治疗无效者备选药物。然而,美国传染病学会 (IDSA) 和美国医疗保健流行病学学会 (SHEA)的2021成人艰难梭菌感染管理临床实践指南建议,对于艰难梭菌感染,使用非达霉素(如果有)代替万古霉素。
二、 剂量
治疗脑膜炎剂量必须高于常规剂量。
肾功能不全患者减量
在记录或怀疑有侵袭性甲氧西林耐药的 S. aureus (MRSA) 感染患者中,万古霉素的给药剂量应达到 400 至 600 的浓度-时间曲线下面积 (AUC)。不再推荐将靶向谷作为替代指标,以实现 AUC 与最低抑菌浓度 (AUC/MIC) 之比≥ 400。
剂量优化可以通过获得多个分布后水平(输注结束和低谷后 1 至 2 小时)并使用一阶动力学方程计算 AUC,使用使用 1 或 2 次迭代的基于软件的贝叶斯方法,或通过滴定连续输注至 20 至 25 微克/毫升(13.8 至 17.25 微摩尔/升)的稳态浓度。(参见 the 2020 therapeutic monitoring of vancomycin for serious methicillin-resistant Staphylococcus aureus infections guidelines revised by the American Society of Health-System Pharmacists, the Infectious Diseases Society of America, the Pediatric Infectious Diseases Society, and the Society of Infectious Diseases Pharmacists.)
这些给药建议仅适用于 MRSA,不应用于指导其他革兰氏阳性感染的给药。
万古霉素对许多病原菌最小抑菌浓度(MIC)在过去20年一直在升高。根据万古霉素的MIC,对金黄色葡萄球菌 S. aureus 敏感性如下:
-
≤2 mcg/mL (≤ 1.4 micromol/L) :敏感
-
4~8 mcg/mL (2.8-5.5 micromol/L):中度
-
> 8 mcg/mL (> 5.5 micromol/L)::耐药
但是,由S. aureus感染,万古霉素MIC≥2 mcg/mL,可能对标准剂量的治疗效果未达最佳,需增加剂量,即谷浓度维持在15~20mcg/mL,因此,对于临床反应差且MIC≥2的患者,转向替代疗法的门槛应该较低。
三、 MIMIC-IV数据库中,查询万古霉素
关于查找药物的教程建议提前看这篇文章, 这里不赘述
MIMIC数据提取教程 - 提取血管紧张素受体阻滞剂(ARB)药物
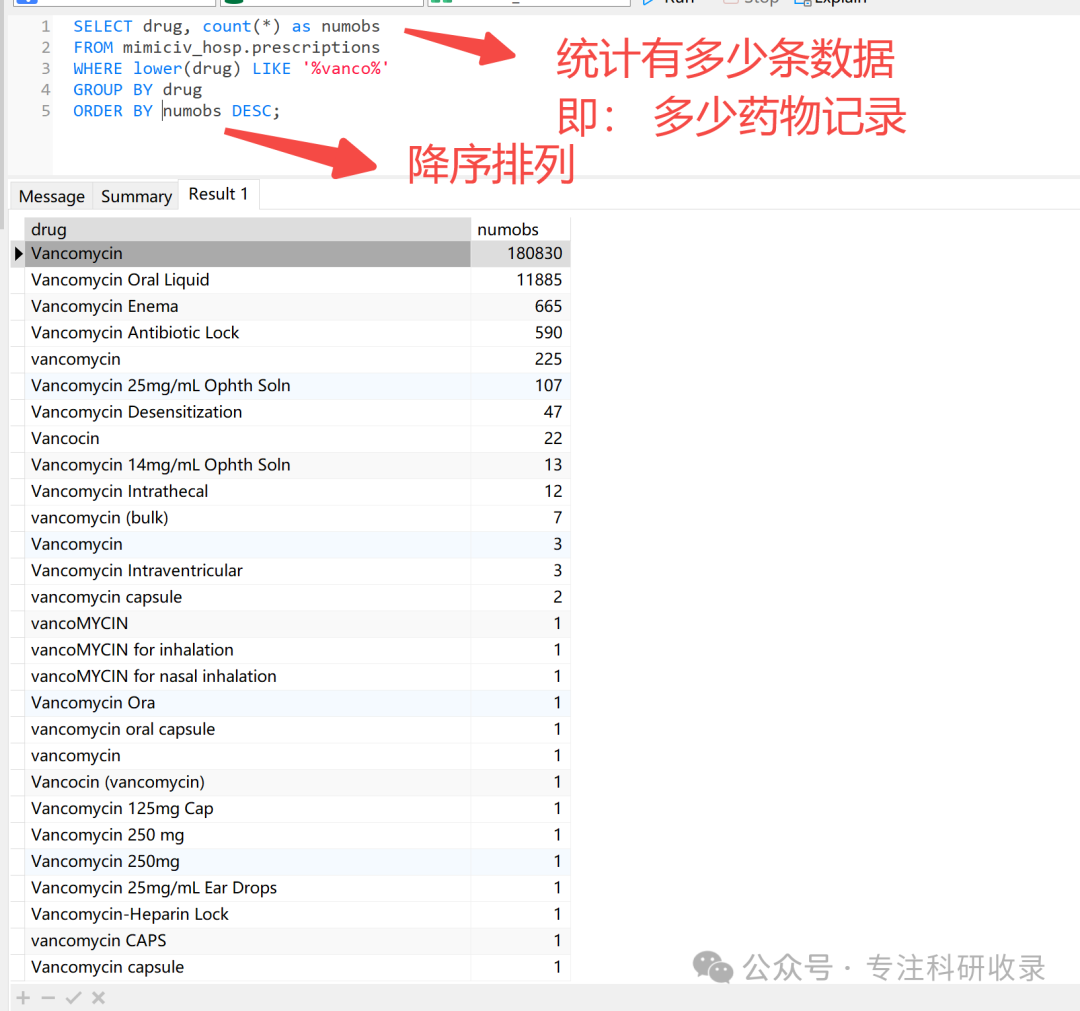
drug:药物的名称
numobs:药物数量
我们用python代码取下数据
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport psycopg2schema_name = 'mimic'# 连接到MIMIC-IV数据库conn = psycopg2.connect(dbname='mimiciv', user='postgres', password='mimic',host='10.241.148.228', port=5432)query_schema = 'SET search_path to ' + schema_name + ';'# # # 设置查询语句# # # 我们选择从mimiciv_hosp.admissions表中提取hadm_id等于10006的行。# # # 在写sql代码时,最好先执行“set search_path to mimiciv" 随后的所有操作均不需要指明表格的位置;否则,任何操作都应该在表格名前面加前缀mimiciv# query1 = query_schema + 'SELECT subject_id, hadm_id, admittime, dischtime, admission_type FROM mimiciv_hosp.admissions'## # 运行查询并将结果分配给变量# admissions_pd = pd.read_sql_query(query1,conn)# admissions_pd.head()# print(admissions_pd.head())query = """SELECT drug, count(*) as numobsFROM mimiciv_hosp.prescriptionsWHERE lower(drug) LIKE '%vanco%'GROUP BY drugORDER BY numobs DESC;"""ie = pd.read_sql_query(query, conn)ie.head(20)print(ie.head(20))
以下内容将被删除,因为我们只关注静脉注射的万古霉素:
-
Vancomycin 25mg/mL Ophth Soln - eye use
-
万古霉素 25mg/mL Ophth Soln - 眼睛使用
-
-
Vancomycin Enema - rectal use
-
万古霉素灌肠 - 直肠使用
-
-
Vancomycin Intrathecal - cerebral spinal fluid injection
-
鞘内注射万古霉素 - 脑脊髓液注射
-
-
Vancomycin Intraventricular - cerebral shunt injection
-
脑室内注射万古霉素 - 脑分流注射
-
-
Vancomycin Oral Liquid - oral use
-
万古霉素口服液 - 口服使用
-
-
Vancomycin fortified opthalmic- eye use
-
万古霉素强化眼科 - 眼睛使用
-
-
Vancomycin ophthalmic 50mg/ml - eye use
-
万古霉素眼用 50mg/ml - 眼睛使用
-
-
Vancomycin ophthalmic solution - eye use
-
万古霉素滴眼液 - 眼睛使用
-
-
vancoMYCIN for inhalation - nasal use
-
吸入用万古霉素 - 鼻腔使用
-
-
vancoMYCIN for nasal inhalation - nasal use
-
鼻吸入用万古霉素 - 鼻腔使用
-
添加SQL
drug in('NEO*IV*Vancomycin', 'Vancocin', 'Vancomycin','Vancomycin ', 'Vancomycin Antibiotic Lock','Vancomycin Desensitization', 'Vancomycin HCl')

接下来,我们需要确定保留实验室事件labevents表和d_items表中的 哪些itemid
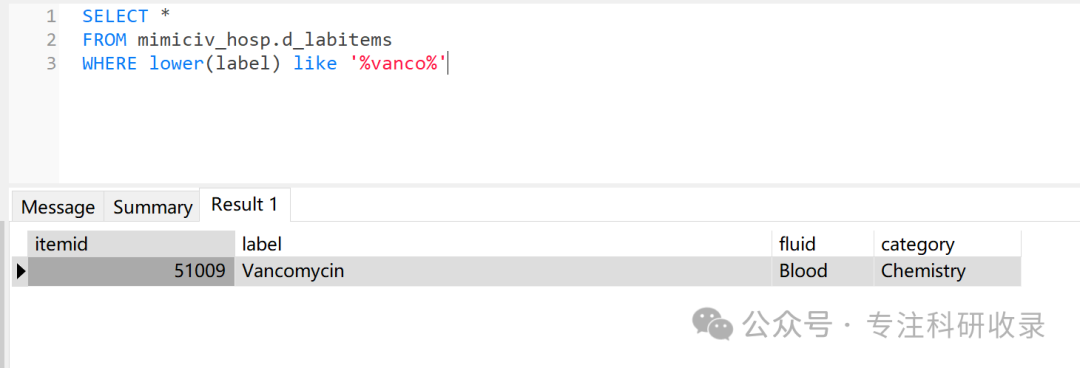
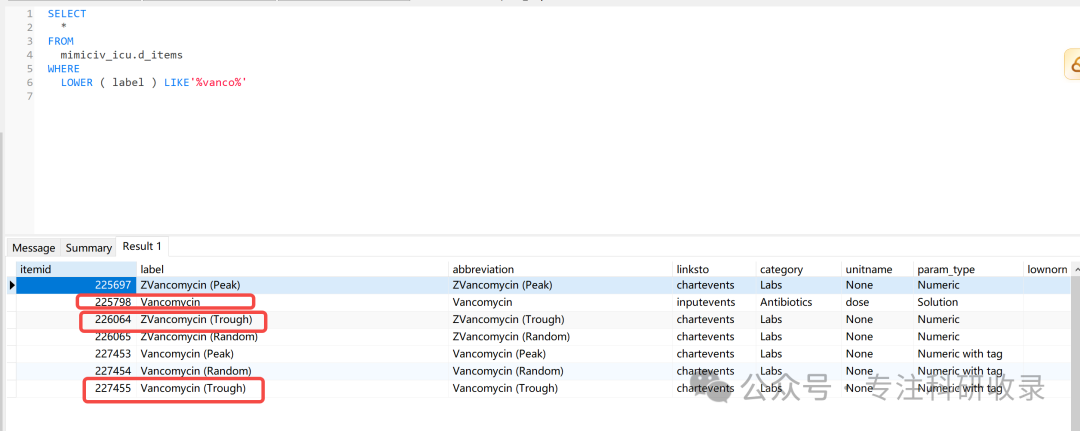
我们只需要Trough值的万古霉素
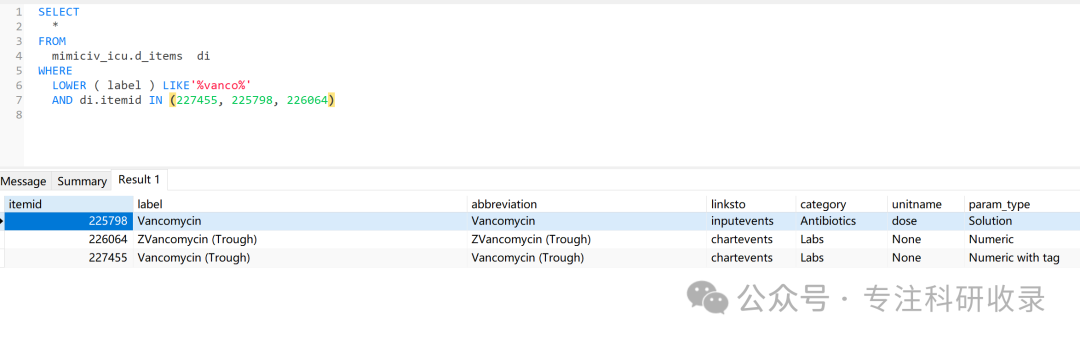
所以我们可以给SQL加上
itemid in(227455, 225798, 226064)
写一个python函数: 从每个表中获取给定“subject_id”的数据。
数据以dataframe格式输出
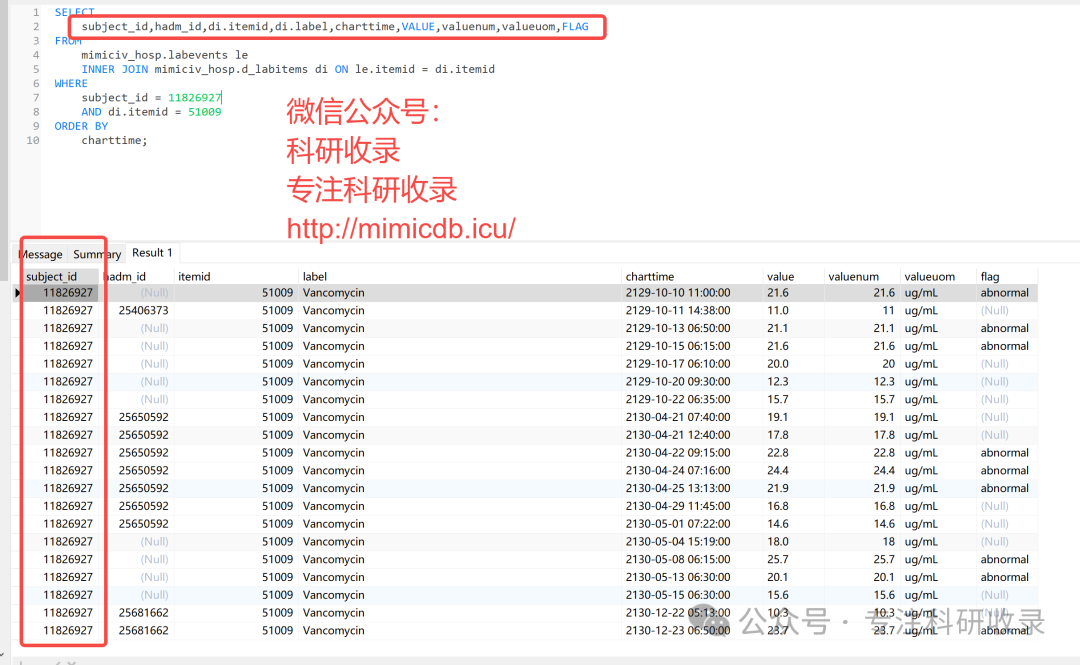
获取实验室检查数据
labevents实验室检测事件数据,记录了与患者实验室检测结果相关的信息,如检测时间、检验指标、结果值等。
实验室事件表存储对单个患者进行的所有实验室测量的结果。其中包括血液学测量、血气、化学检测以及基因检测等不太常见的测试
def get_lab_data_for_subject(subject_id, query_schema, conn):# lab data 实验室数据query = query_schema + """SELECTsubject_id,hadm_id,di.itemid,di.label,charttime,VALUE,valuenum,valueuom,FLAGFROMmimiciv_hosp.labevents leINNER JOIN mimiciv_hosp.d_labitems di ON le.itemid = di.itemidWHEREsubject_id = {}AND di.itemid = 51009ORDER BYcharttime;""".format(subject_id)lab = pd.read_sql_query(query, conn)return lab
获取Chartevents图表数据
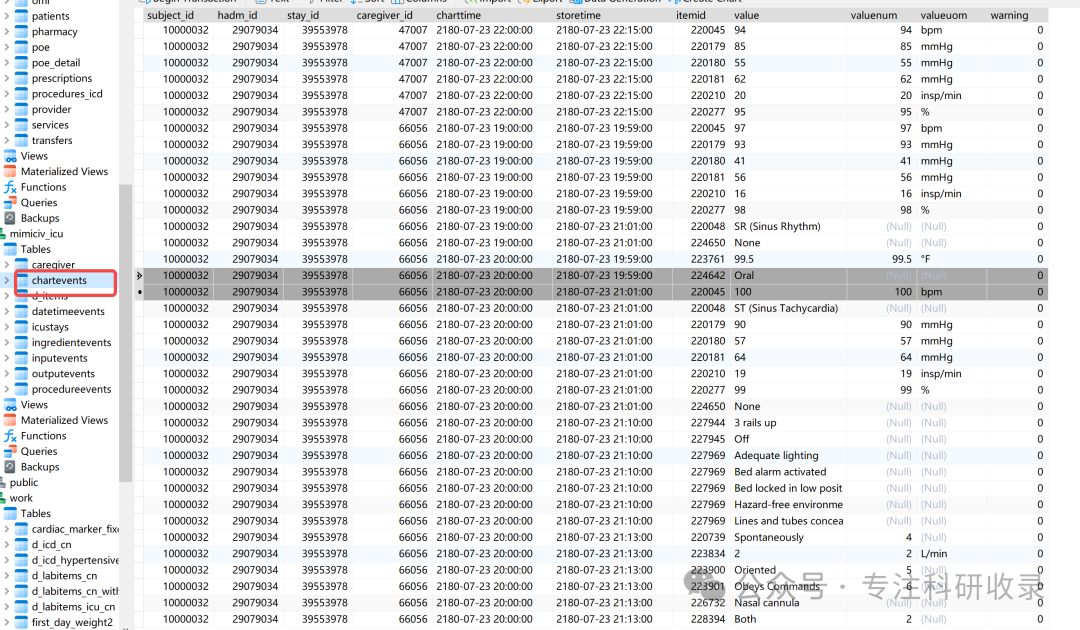
Chartevents 包含患者可用的所有图表数据。在 ICU 住院期间,患者信息的主要存储库是他们的电子病历。电子图表显示患者的常规生命体征以及与其护理相关的任何其他信息:呼吸机设置、实验室值、代码状态、精神状态等。因此,有关患者住院的大部分信息都包含在图表事件中。此外,即使实验室值是在其他地方(实验室事件)捕获的,它们也会在图表事件中频繁重复。发生这种情况是因为需要在患者的电子图表上显示实验室值,因此这些值从存储实验室值的数据库复制到存储图表事件的数据库。
Labevents 和 Chartevents 表之间的某些项目是重复的。如果测量之间存在分歧,则应将实验室事件视为基本事实。
-
subject_id,hadm_id,stay_id
指定患者的标识符:subject_id 是患者唯一的,hadm_id 是患者住院期间唯一的,stay_id 是患者病房期间唯一的。有关这些标识符的更多信息可在此处找到https://mimic.mit.edu/docs/iv/about/concepts/
-
caregiver_id 唯一标识在 ICU 信息系统中记录数据的单个护理人员
-
itemid数据库中单个测量类型的标识符。与一个 itemid(例如 220045)关联的每一行对应于相同测量值(例如心率)的实例 -
value,valuenumvalue 包含为 itemid 标识的概念测量的值。如果该值是数字,则 valuenum 包含数字格式的相同数据。如果此数据不是数字,则 valuenum 为 null。在某些情况下(例如格拉斯哥昏迷量表、里士满镇静激动量表和代码状态等分数),valuenum 包含分数,value 包含分数和描述分数含义的文本。 -
valueuomvalueuom 是值的测量单位(如果适用) -
Warning : 指定护理人员是否手动记录了针对此观察结果的警告。
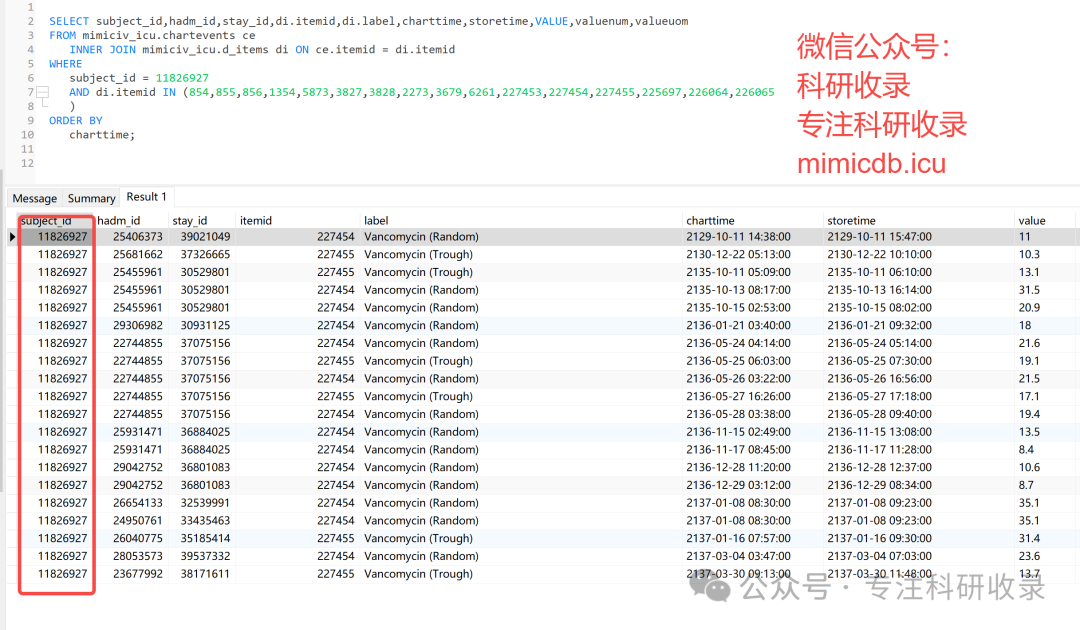
def get_ce_data_for_subject(subject_id, query_schema, conn):# charted dataquery = query_schema + """SELECT subject_id,hadm_id,stay_id,di.itemid,di.label,charttime,storetime,VALUE,valuenum,valueuomFROMmimiciv_icu.chartevents ceINNER JOIN mimiciv_icu.d_items di ON ce.itemid = di.itemidWHEREsubject_id = {}AND di.itemid IN (854,855,856,1354,5873,3827,3828,2273,3679,6261,227453,227454,227455,225697,226064,226065)ORDER BYcharttime;""".format(subject_id)ce = pd.read_sql_query(query, conn)return ce
从输出表获取检查数据mimiciv_icu.inputevents表
inputevents表
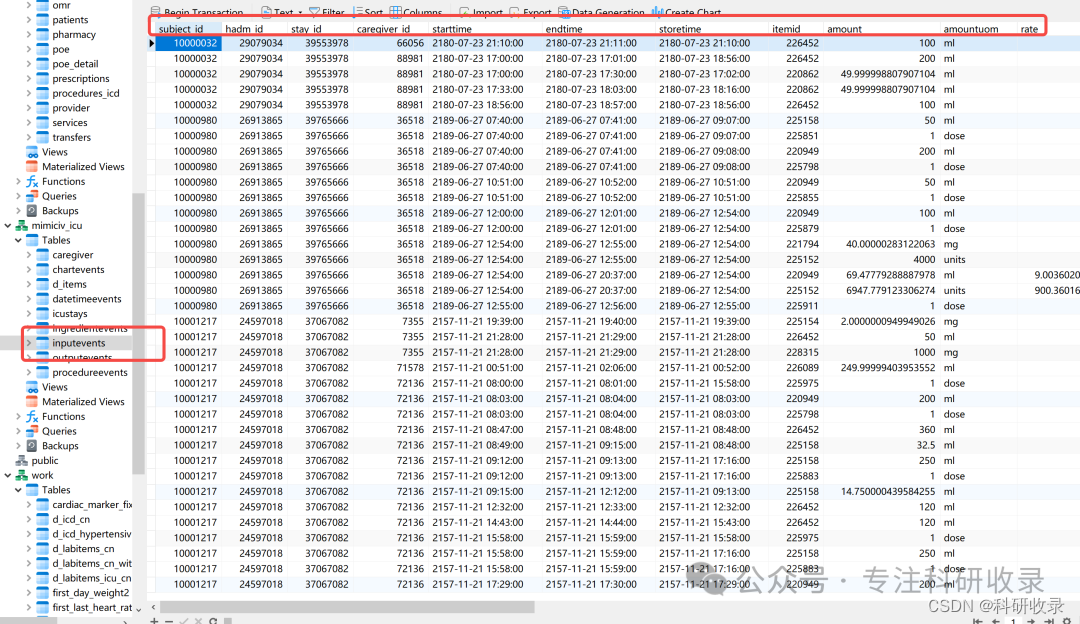
此表记录了病患的所有输入事件, 包括药物给药, 液体输入等
-
subject_id: 患者的唯一标识符。
-
hadm_id: 入院号,表示患者的住院标识符。
-
stay_id: 留观号,指患者在医院中的留观期间的唯一标识符。
-
caregiver_id: 护理人员标识符,表示执行该记录的护理人员。
-
starttime: 开始时间,指记录事件或处理开始的时间。
-
endtime: 结束时间,表示记录事件或处理结束的时间。
-
storetime: 存储时间,表示记录被存储的时间。
-
itemid: 项目ID,指记录的特定项目或测量。
-
amount: 数量,表示与该项目相关的数值量。
-
amountuom: 数量单位,表示数值的单位。
-
rate: 速率,指与该项目相关的速率值。
-
rateuom: 速率单位,表示速率的单位。
-
orderid: 医嘱ID,表示与记录相关联的医嘱标识符。
-
linkorderid: 链接医嘱ID,指连接到当前记录的其他医嘱的标识符。
-
ordercategoryname: 医嘱类别名称,表示医嘱的类别名称。
-
secondaryordercategoryname: 辅助医嘱类别名称,指医嘱的辅助类别名称。
-
ordercomponenttypedescription: 医嘱组件类型描述,表示医嘱组件的类型描述。
-
ordercategorydescription: 医嘱类别描述,表示医嘱的类别描述。
-
patientweight: 患者体重,表示患者的体重值。
-
totalamount: 总数量,表示与该项目相关的总数量。
-
totalamountuom: 总数量单位,表示总数量的单位。
-
isopenbag: 是否为开袋状态,指示医嘱是否处于开袋状态。
-
continueinnextdept: 是否延续至下一科室,指示医嘱是否需要延续至下一个科室。
-
statusdescription: 状态描述,表示记录的状态描述。
-
originalamount: 原始数量,表示原始数值量。
-
originalrate: 原始速率,指原始速率值。
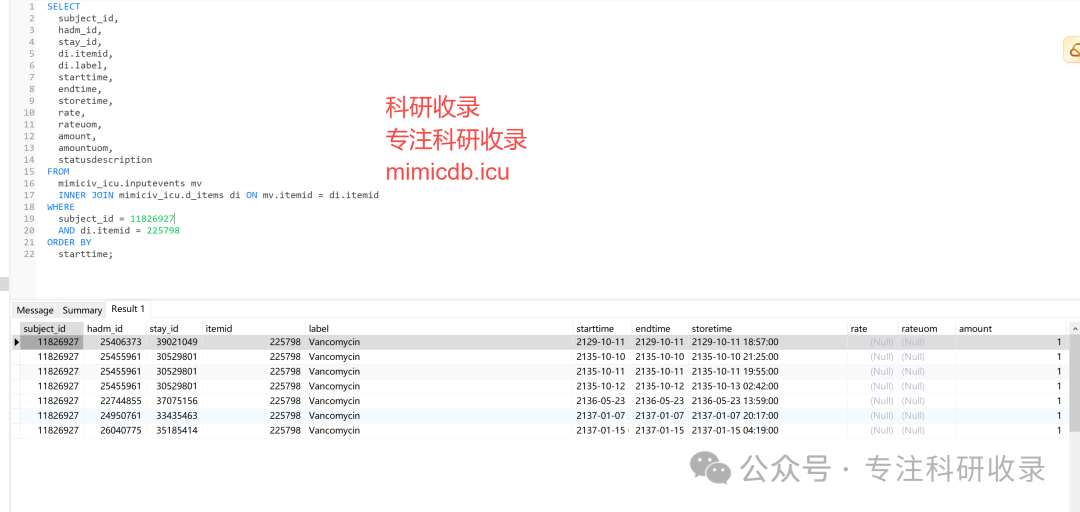
def get_imv_data_for_subject(subject_id, query_schema, conn):# input dataquery = query_schema + """selectsubject_id, hadm_id, stay_id, di.itemid, di.label, starttime, endtime, storetime, rate, rateuom, amount, amountuom, statusdescriptionfrom mimiciv_icu.inputevents mvinner join mimiciv_icu.d_items dion mv.itemid = di.itemidwhere subject_id = {}and di.itemid = 225798order by starttime;""".format(subject_id)imv = pd.read_sql_query(query, conn)return imv
从药物处方表获取药物数据mimiciv_hosp.prescriptions表
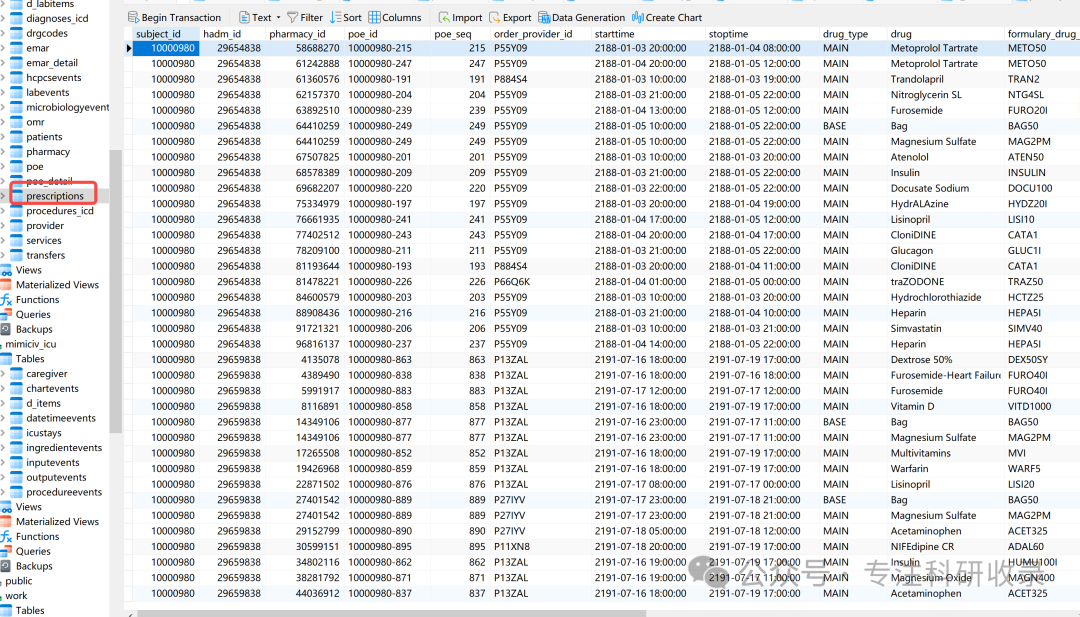
此表包含了病患的药物处方资讯,记录药物名称、用量和给药时间
-
subject_id:患者的唯一标识符。
-
hadm_id:入院号,指患者的住院标识符。
-
pharmacy_id:药房的唯一标识符。
-
poe_id:医嘱输入/录入(Prescription Order Entry)的唯一标识符。
-
poe_seq:医嘱输入/录入的顺序号。
-
order_provider_id:开单医生的唯一标识符。
-
starttime:药物使用的开始时间。
-
stoptime:药物使用的停止时间。
-
drug_type:药物类型,如处方药、非处方药等。
-
drug:药物的名称。
-
formulary_drug_cd:药物在药物目录中的代码。
-
gsn:用于标识药物。
-
ndc:国家药物编码(National Drug Code),用于唯一标识药物。
-
prod_strength:药物的剂量强度。
-
form_rx:处方剂型,表示药物的制剂形式。
-
dose_val_rx:处方剂量的数值。
-
dose_unit_rx:处方剂量的单位。
-
form_val_disp:实际发放的剂量的数值。
-
form_unit_disp:实际发放的剂量的单位。
-
doses_per_24_hrs:每24小时给药的次数。
-
route:给药途径/路径。
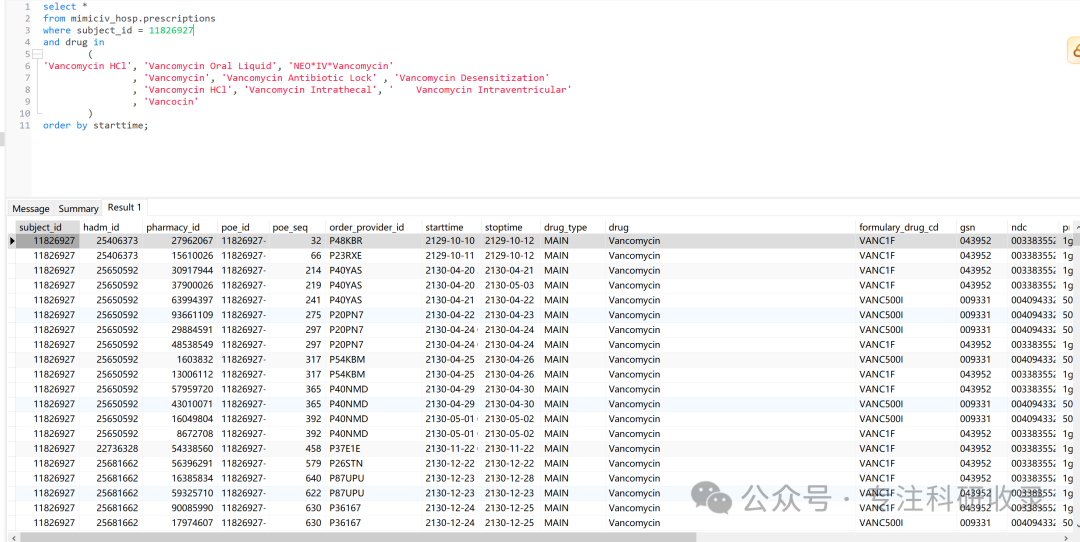
def get_pr_data_for_subject(subject_id, query_schema, conn):# prescriptionsquery = query_schema + """select *from mimiciv_hosp.prescriptionswhere subject_id = {}and drug in('Vancomycin HCl', 'Vancomycin Oral Liquid', 'NEO*IV*Vancomycin', 'Vancomycin', 'Vancomycin Antibiotic Lock' , 'Vancomycin Desensitization', 'Vancomycin HCl', 'Vancomycin Intrathecal', ' Vancomycin Intraventricular', 'Vancocin')order by starttime;""".format(subject_id)pr = pd.read_sql_query(query, conn)return pr
获取患者转院记录数据
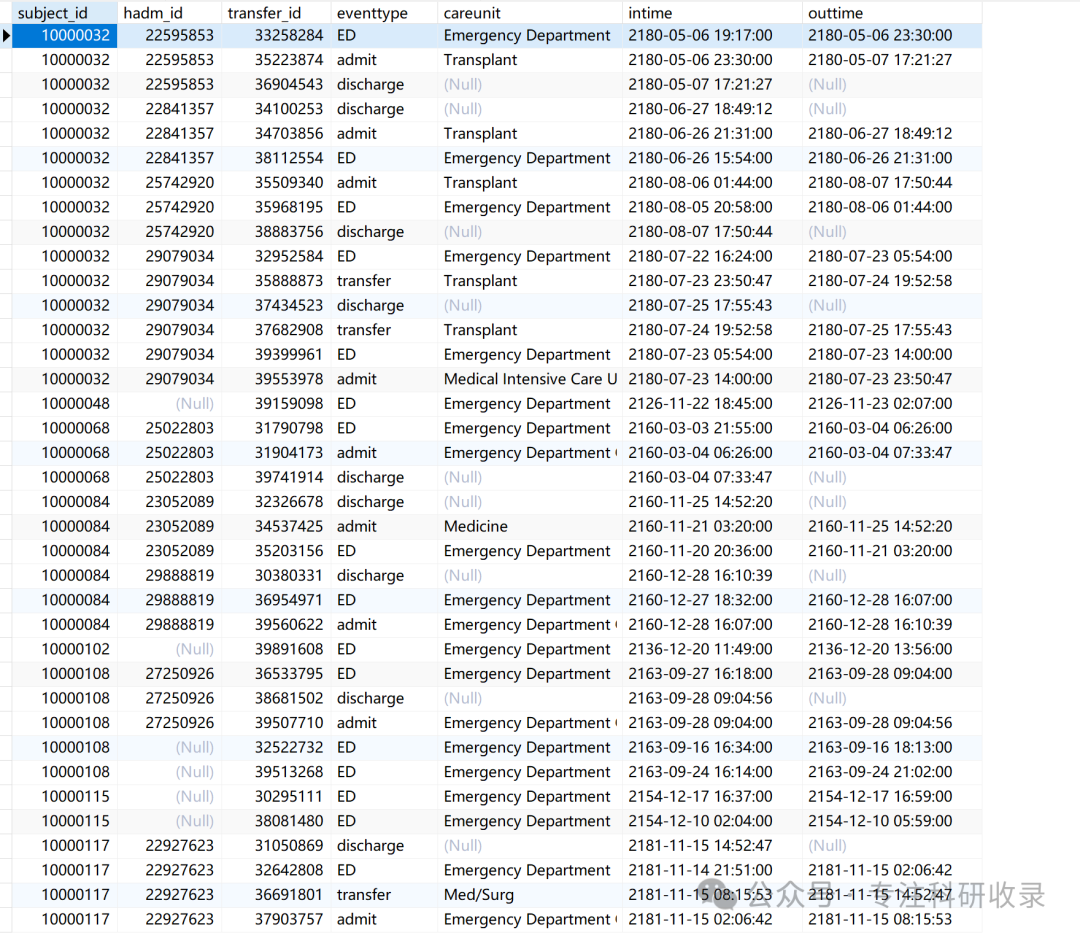
transfer表 患者转院记录数据,包含有关患者转院的信息,如转出科室、转入科室等。
-
subject_id:患者的唯一标识符。
-
hadm_id:入院号,指患者的住院标识符。
-
transfer_id:转归ID,指该转归记录在该患者所有转归中的序号。
-
eventtype:事件类型,指该转归是入住、转科、出院还是其他事件。
-
careunit:病房名称,指患者所在病房的名称。
-
intime:入住时间,指患者入住病房的时间。
-
outtime:出院时间,指患者出院的时间
def get_tr_data_for_subject(subject_id, query_schema, conn):# transfers infoquery = query_schema + """select * from mimiciv_hosp.transferswhere subject_id = {};""".format(subject_id)tr = pd.read_sql_query(query, conn)return tr
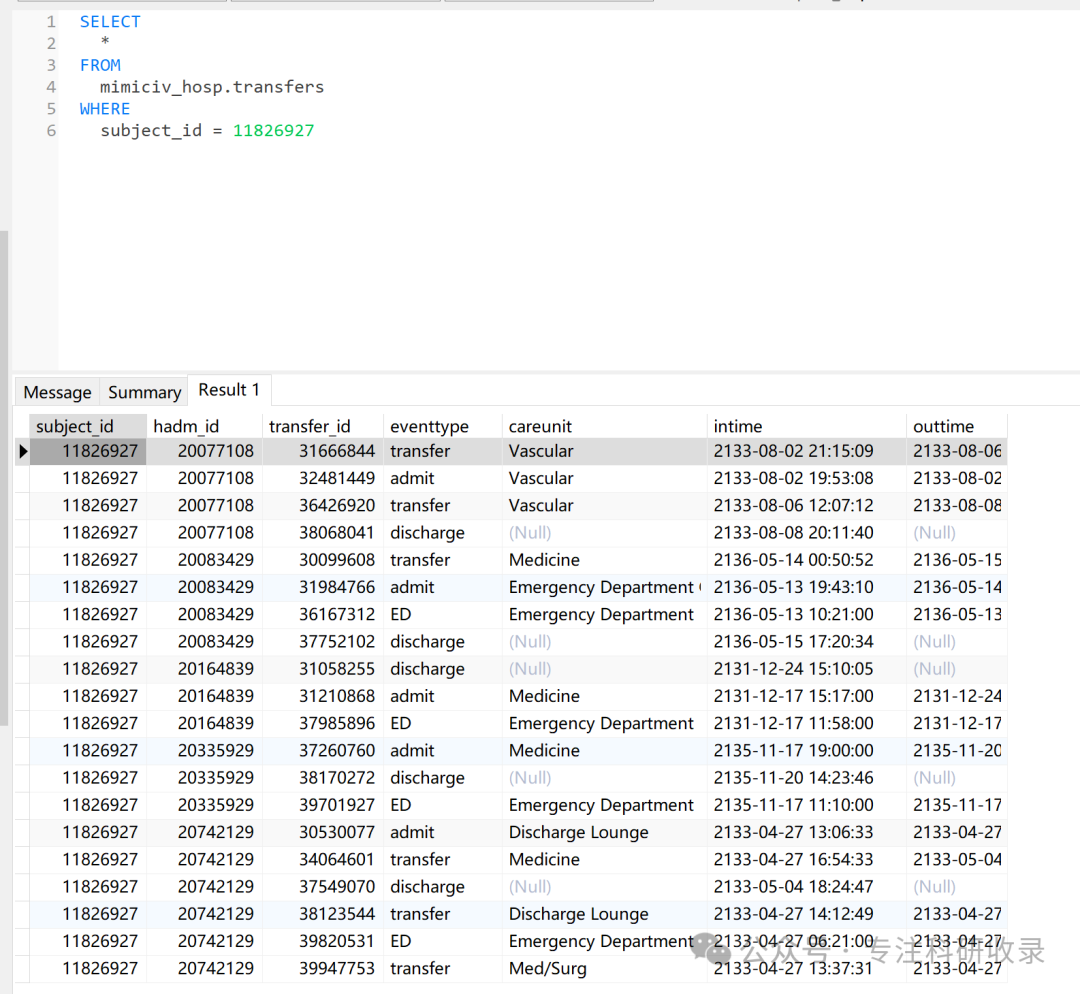
把以上python代码函数合并成一个取数据函数
def get_data_for_subject(subject_id, query_schema, conn):# lab data 实验室数据query = query_schema + """SELECTsubject_id,hadm_id,di.itemid,di.label,charttime,VALUE,valuenum,valueuom,FLAGFROMmimiciv_hosp.labevents leINNER JOIN mimiciv_hosp.d_labitems di ON le.itemid = di.itemidWHEREsubject_id = {}AND di.itemid = 51009ORDER BYcharttime;""".format(subject_id)lab = pd.read_sql_query(query, conn)# charted dataquery = query_schema + """SELECT subject_id,hadm_id,stay_id,di.itemid,di.label,charttime,storetime,VALUE,valuenum,valueuomFROMmimiciv_icu.chartevents ceINNER JOIN mimiciv_icu.d_items di ON ce.itemid = di.itemidWHEREsubject_id = {}AND di.itemid IN (854,855,856,1354,5873,3827,3828,2273,3679,6261,227453,227454,227455,225697,226064,226065)ORDER BYcharttime;""".format(subject_id)ce = pd.read_sql_query(query, conn)# input dataquery = query_schema + """selectsubject_id, hadm_id, stay_id, di.itemid, di.label, starttime, endtime, storetime, rate, rateuom, amount, amountuom, statusdescriptionfrom mimiciv_icu.inputevents mvinner join mimiciv_icu.d_items dion mv.itemid = di.itemidwhere subject_id = {}and di.itemid = 225798order by starttime;""".format(subject_id)imv = pd.read_sql_query(query, conn)# no vanco data in CV# prescriptionsquery = query_schema + """select *from mimiciv_hosp.prescriptionswhere subject_id = {}and drug in('Vancomycin HCl', 'Vancomycin Oral Liquid', 'NEO*IV*Vancomycin', 'Vancomycin', 'Vancomycin Antibiotic Lock' , 'Vancomycin Desensitization', 'Vancomycin HCl', 'Vancomycin Intrathecal', ' Vancomycin Intraventricular', 'Vancocin')order by starttime;""".format(subject_id)pr = pd.read_sql_query(query, conn)# transfers infoquery = query_schema + """select * from mimiciv_hosp.transferswhere subject_id = {};""".format(subject_id)tr = pd.read_sql_query(query, conn)return lab, ce, imv, pr, tr
传入subject_id, 连接数据库, 运行代码
# pick the subject# 可修改subject_id = 11826927# get data for this subjectlab_df= get_data_for_subject(subject_id, query_schema, conn)print(lab_df)
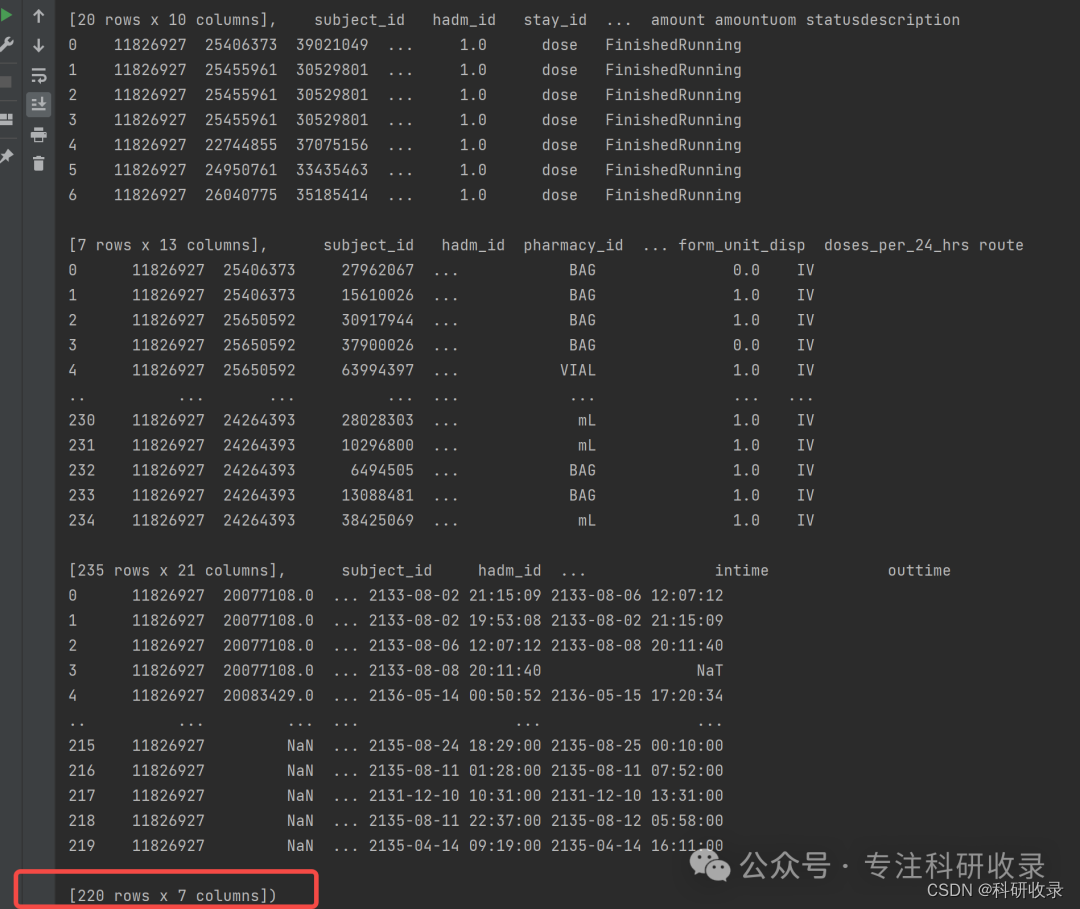
以上我们完成了取数据, 下面我们需要对数据进行处理
将多个dataframe数据框组合成单个dataframe。它通过将列组合在一起来实现这一点
因此,虽然单个列中的数据不再一致地表示相同的概念,但它更易于阅读。
由于文章已经过长,这部分内容下一章讲解, 敬请期待








![[python] 过年燃放烟花](https://img-blog.csdnimg.cn/direct/0e9bbf7314694c23b32806bd57a6c284.png)

![【蓝桥杯冲冲冲】 [SCOI2005] 骑士精神](https://img-blog.csdnimg.cn/img_convert/85c9a7afe11ad6e04d138db642e902e3.png)