HuggingFace库中BERTForxxx模型代码详细分析 使用BERT进行无监督预训练
- 引言
- HF库封装的各种任务列举
- BertModel的结构分析
- BertForPreTraining的结构分析
- BertForMaskedLM的结构分析
- BertForNextSentencePrediction的结构分析
- BertForSequenceClassification的结构分析
- BERT模型的面试题解答
- BERT如何进行无监督预训练?
引言
随着对BERT的使用越来越频繁,一直以来,有一些疑问埋在心底没有去解决,也请大家在阅读本文之前,尝试回答一下这些面试题:
1、BERT在huggingface库里有那么多BertForxxxModel变种,不同的Model加载预训练向量之后,预训练向量覆盖了哪些层、没有覆盖哪些层?
2、BERT的自动MASK机制,是一直都有,还是在特定的任务中才有?是如何实现的?
3、BERT的NSP,当输入是只有一个句子时,是如何处理的?
4、BERT的CLS位置特殊在哪,和最后一层隐藏层其他位置难道有区别吗?为什么只用CLS位置做文本分类任务呢?
5、BERT的tokenizer,分中文的分字分词现象、分英文时的WordPiece现象
如果大家对上面的疑问还不是完全清楚的话,本文将会从HuggingFace库中BERT-based的各种模型结构上分析,为大家解答上述疑问。
在讲解代码时,可能会说到具体哪一行,所以事先说明我的transformers库的版本为4.36.2。
HF库封装的各种任务列举
访问HF库BERT模型的文档:https://huggingface.co/docs/transformers/model_doc/bert,可以看到这些模型:

· BertModel
· BertForPreTraining
· BertForMaskedLM
· BertForNextSentencePrediction
· BertForSequenceClassification
· BertForQuestionAnswering
如果我们想在其中增加一些模块,比如LSTM、CRF等优化模型,我们可以仿造这些封装好的API的写法,当然也可以直接使用上面的这些模型。
下面来分析各个模型的结构。
BertModel的结构分析
首先,我们来打印一下模型结构,写如下代码:
path = r"D:\PLMs\bert\bert-base-chinese"
model = BertModel.from_pretrained(path)
print(model)
可以在控制台看到BertModel的结构如下:

BertModel由三部分组成,embeddings、encoder与pooler。因为embeddings、encoder都是固定的,所以这里我就用省略号代替了。
Embeddings是嵌入层,包括三个嵌入层的组合:词嵌入,位置嵌入和句子嵌入。
Encoder是BERT模型的核心,由12个Transformer编码器构成。
Pooler用来提取固定的特征表示。在BERT模型中,通常使用第一个token([CLS])的最后一层的隐藏状态作为整个输入序列的表示。
在这三部分中,从理解BertModel结构的角度上看,Pooler是最重要的。 假设一个长为32的文本向量为[1, 32],输入到模型中,并且经过Encoder编码后,它的大小应该为[1, 32, 768],768是隐藏层的维度。此时我们想得到这个句子的编码,应该如何去操作呢?
如果是RNN系列的模型,我们通常会取最后一个token位置上的768维的向量作为句子向量。这是因为RNN是时序模型,普遍认为一个状态一个状态向后传递,最终最后一个位置的向量能够编码全局信息。
但是由于BERT是自编码模型,又用到了注意力机制,结构如下图,虽然每个位置(即 T 1 T_1 T1至 T n T_n Tn)的向量不一样,但是理论上经过一通全局角度的信息提取后,每个位置都能代表整个句子的信息。而我们知道,BERT的做法是取第一个位置的token(即 T 1 T_1 T1,也就是官方所说的CLS位置)作为句子向量的。

实现代码可以去查看BertModel中forward部分的代码(modeling_bert.py的1025行):

会发现在经过编码器编码后,送入pooler的向量是提取了第0个元素的。
最后,查看BertModel模型的输出类为:
BaseModelOutputWithPoolingAndCrossAttentions(last_hidden_state=sequence_output,pooler_output=pooled_output,past_key_values=encoder_outputs.past_key_values,hidden_states=encoder_outputs.hidden_states,attentions=encoder_outputs.attentions,cross_attentions=encoder_outputs.cross_attentions,
)
主要还是把编码过程中的隐藏层last_hidden_state,和提取CLS位置的句子向量pooler_output给输出出来了。
综上所述,BertModel模型在用encoder编码了句子之后,使用了pooler提取第0个位置的token向量作为句子向量返回。所以在我们用BERT接自定义网络层的时候,通常会使用BertModel模型,而不是其他变体。
目前来说,我们只弄清楚了BertModel模型,对NSP、MLM仍然还没涉及。
BertForPreTraining的结构分析
首先,我们来打印一下模型结构,写如下代码:
path = r"D:\PLMs\bert\bert-base-chinese"
model = BertForPreTraining.from_pretrained(path)
print(model)
可以在控制台看到BertForPreTraining的结构如下:

BertForPreTraining是BERT变体的所有模型中,结构最全的模型。可以理解为,其他的变体都是BertForPreTraining模型的子集,只不过各有不同而已。观察它的结构可以发现,BertForPreTraining模型是在BertModel模型的基础上,加了一个预训练头BertPreTrainingHeads。
预训练头BertPreTrainingHeads做了两个工作,一个是predictions做MLM任务预测[MASK]标记的概率分布,另外一个是seq_relationship做NSP任务预测两个句子是否是下一个句子的关系。
其实很好理解,对于predictions:它里面有个decoder,这是线性分类器,形状为768 * 21128,也就是隐藏层*词典大小。流程大概为:一个句子经过编码器编码为[1, 32, 768]的向量,然后再通过predictions变成[1, 32, 21128]的概率向量,这样不就能完成完形填空的预训练任务了吗!
而对于seq_relationship:它也是线性分类器,形状为768 * 2,也就是隐藏层*标签数量。对于NSP任务,标签就是有或无这两个。流程大概为:一个句子经过编码器编码为[1, 32, 768]的向量,然后再通过pooler变成[1, 768]的句子向量,最后通过seq_relationship变成[1, 2]的概率向量,这样不就能完成下一个句子预测的预训练任务了吗!
此时去查看预训练头的代码(modeling_bert.py的721行):
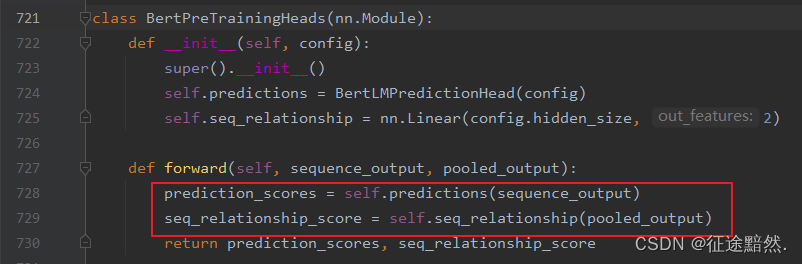
此时我们就会发现,两个预训练任务MLM和NSP的输入是不一样的!一个是编码后的向量,维度为[1, 32, 768],表示对每个token的编码。另一个是经过pooler的向量,维度为[1, 768],表示对整个句子的编码。但是仔细想想,这也非常合理!完形填空任务需要的是每个位置的表征向量,而下一个句子预测任务当然需要的是句子向量。
最后,查看BertForPreTraining模型的输出类为:
BertForPreTrainingOutput(loss=total_loss,prediction_logits=prediction_scores, # (b, s, v) 字典词的logitsseq_relationship_logits=seq_relationship_score, # (b, 2) 句子是否是上下句hidden_states=outputs.hidden_states,attentions=outputs.attentions,
)
BertForPreTrainingOutput也就是把两个预训练任务的概率给返回一下。
BertForMaskedLM的结构分析
首先,我们来打印一下模型结构,写如下代码:
path = r"D:\PLMs\bert\bert-base-chinese"
model = BertForMaskedLM.from_pretrained(path)
print(model)
可以在控制台看到BertForMaskedLM的结构如下:

顾名思义,BertForMaskedLM是专门做MLM任务的模型。我们观察它的结构可以看到,BertForMaskedLM是在BertModel删除pooler的基础上,加了一个MLM预测头BertOnlyMLMHead。
不同过多的在乎这个很容易搞混的类名,我们就简单的把BertForMaskedLM和BertForPreTraining模型的结构对比下你就会惊喜的发现,BertForMaskedLM其实就是BertForPreTraining删除NSP任务的版本!! 不但删除了seq_relationship对句子关系预测的分类器,同时由于MLM任务不需要句子向量,所以把pooler也给删除了。
看到这里,读者一定能猜出来BertForNextSentencePrediction模型的结构了!
BertForNextSentencePrediction的结构分析
首先,我们来打印一下模型结构,写如下代码:
path = r"D:\PLMs\bert\bert-base-chinese"
model = BertForNextSentencePrediction.from_pretrained(path)
print(model)
可以在控制台看到BertForNextSentencePrediction的结构如下:

果然和你预测的一样对不对!BertForNextSentencePrediction模型其实就是BertForPreTraining模型删除MLM任务的版本,把MLM分类头给删除了,同时由于NSP任务是需要句子向量的,所以保留了pooler。
BertForSequenceClassification的结构分析
要是说上述模型都属于BERT本身的范畴的话,那么BertForSequenceClassification模型就是纯纯BERT的下游任务模型了。
首先,我们来打印一下模型结构,写如下代码:
path = r"D:\PLMs\bert\bert-base-chinese"
model = BertForSequenceClassification.from_pretrained(path)
print(model)
可以在控制台看到BertForSequenceClassification的结构如下:

可以看到,BertForSequenceClassification模型是在BertModel的基础上,仅仅加了一个线性分类器而已!而且它需要句子向量来进行分类,所以pooler也保留了下来。
而且在加载BertForSequenceClassification模型的预训练向量的时候,控制台会打印如下信息:
Some weights of BertForSequenceClassification were not initialized from the model checkpoint atD:\PLMs\bert\bert-base-chinese and are newly initialized: ['classifier.bias', 'classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it
for predictions and inference.
这是在说,对于BertForSequenceClassification模型最后的线性分类器classifier,BERT的预训练向量是没有覆盖的,需要我们继续训练这部分参数来微调。
因为下游任务千变万化,而且每个人的语料和领域都不同,所以对于BERT模型之外的网络层,需要手动训练,这是非常合理的。
BERT模型的面试题解答
说到这里,文章开头问题基本上都能解答了。
1、BERT在huggingface库里有那么多BertForxxxModel变种,不同的Model加载预训练向量之后,预训练向量覆盖了哪些层、没有覆盖哪些层?
答:BERT模型的预训练参数只能覆盖BertForPreTraining的结构这么多。如果接了下游任务的网络层的话,这些层的参数是随机初始化的。
3、BERT的NSP,当输入是只有一个句子时,是如何处理的?
答:因为NSP任务的分类器的输入是句子向量,而不管输入的是一个句子还是两个句子,CLS位置都是对输入整体的编码,也就是说都是有句子编码的。所以只有一个句子的时候,NSP任务虽然可以正常运行,但是它的输入是没有意义的。
4、BERT的CLS位置特殊在哪,和最后一层隐藏层其他位置难道有区别吗?为什么只用CLS位置做文本分类任务呢?
答:如果只看MLM任务的训练过程的话,最后一层隐藏层所有位置的向量都能代表句子向量,但是,CLS位置是拿去做NSP任务的啊!所以CLS特殊就特殊在它比其他token位置的向量多做了个NSP任务,所以把它当作句子的表征向量而不是其他位置。
BERT如何进行无监督预训练?
在说BERT如何进行无监督预训练之前,我们需要接着解答文章开头的问题:
2、BERT的自动MASK机制,是一直都有,还是在特定的任务中才有?是如何实现的?
答:相信大家对BERT论文中随机抽取15%的token来MASK印象深刻,我在HF库的源码中找了半天也没找到随机MASK的具体实现。知道最后才发现,随机MASK是在数据准备阶段做的。在做MLM任务(无监督)之前,我们先是有输入input_id,然后从中抽取15%,再按8:1:1的比率进行MASK、不变、随机(就像论文中说的那样),其他位置设置为-100,然后组成一个向量mlm_label,表示MLM任务的标签。在最后计算交叉熵损失的时候,对于标签为-100的数据,是不会进行计算的(pytorch库中确实是这样实现的,可以去看下源码)。综上所述,所谓BERT的自动MASK机制是需要我们在数据准备阶段手动构造标签来实现的。所以,模型到底有没有自动MASK,看你自己怎么构造标签。当然,像BertForSequenceClassification这样的模型,并不涉及MLM任务,是肯定不会有自动MASK机制的。
OK。说完上面的问题,相信大家对怎么进行无监督训练肯定清楚了。假设我们有一堆文本数据:
1、选择模型:模型采用BertForPreTraining模型(因为它同时包含MLM和NSP任务)。
2、构建MLM输入:先对文本进行分词,转化为数值向量。
3、构建NSP输入:把文本切成两个句子,可以利用BERT的分词器构造。但是要不要负采样、以什么规则把把文本切成两个句子的Trick比较多。
4、构建MLM标签:从MLM输入中抽取15%,再按8:1:1的比率进行MASK、不变、随机(就像论文中说的那样),其他位置设置为-100,构成标签向量。
5、构建NSP标签:这个简单,有关系就是0,没关系就是1。




![[设计模式Java实现附plantuml源码~结构型]实现对象的复用——享元模式](https://img-blog.csdnimg.cn/direct/89a51d17748c4bd496e37b23387ed48e.png)