目录
PySpark SQL
基础
SparkSession对象
DataFrame入门
DataFrame构建
DataFrame代码风格
DSL
SQL
SparkSQL Shuffle 分区数目
DataFrame数据写出
Spark UDF
Catalyst优化器
Spark SQL的执行流程
PySpark SQL
基础
PySpark SQL与Hive的异同
Hive和Spark 均是:“分布式SQL计算引擎”
均是构建大规模结构化数据计算的绝佳利器,同时SparkSQL拥有更好的性能。
目前,企业中使用Hive仍旧居多,但SparkSQL将会在很近的未来替代Hive成为分布式SQL计算市场的顶级

这里的重点是:Spark SQL能支持SQL和其他代码混合执行,自由度更高,且其是内存计算,更快。但是其没有元数据管理,然而它最终还是会作用到Hive层面,可以调用Hive的Metasotre
SparkSQL的基本对象是DataFrame,其特点及与其他对象的区别为:

SparkSQL 其实有3类数据抽象对象
- SchemaRDD对象 (已废弃)
- DataSet对象: 可用于Java、Scala语言
- DataFrame对象:可用于Java、Scala、Python、R
SparkSession对象
在RDD阶段,程序的执行入口对象是: SparkContext
在Spark 2.0后,推出了SparkSession对象,作为Spark编码的统一入口对象
SparkSession对象可以:
-用于SparkSQL编程作为入口对象
- 用于SparkCore编程,可以通过SparkSession对象中获取到SparkContext
from pyspark.sql import SparkSession
if __name__ == '__main__':spark = SparkSession.builder.appName('lmx').master('local[*]').getOrCreate()sc = spark.sparkContextDataFrame入门
DataFrame的组成如下
在结构层面
StructType对象描述整个DataFrame的表结构StructField对象描述一个列的信息
在数据层面
Row对象记录一行数据
Column对象记录一列数据并包含列的信息
DataFrame构建
1、用RDD进行构建
rdd的结构要求为:[[xx,xx],[xx,xx]]
spark.createDataFrame(rdd,schema=[])
spark = SparkSession.builder.appName('lmx').master('local[*]').getOrCreate()sc = spark.sparkContextrdd = sc.textFile('data/input/sql/people.txt').map(lambda x:x.split(',')).map(lambda x:[x[0],int(x[1])])print(rdd.collect())# [['Michael', 29], ['Andy', 30], ['Justin', 19]]df = spark.createDataFrame(rdd,schema=['name','age'])df.printSchema()#打印表结构df.show()#打印表
# root
# | -- name: string(nullable=true)
# | -- age: long(nullable=true)
#
# +-------+---+
# | name | age |
# +-------+---+
# | Michael | 29 |
# | Andy | 30 |
# | Justin | 19 |
# +-------+---+2、利用StructType进行创建
需要先引入StructType,StringType,IntegerType等构建schema
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType,StringType,IntegerType
if __name__ == '__main__':spark = SparkSession.builder.appName('lmx').master('local[*]').getOrCreate()sc = spark.sparkContextrdd = sc.textFile('data/input/sql/people.txt').map(lambda x:x.split(',')).map(lambda x:[x[0],int(x[1])])
#构建schema
schema =StructType().add("name",StringType(),nullable=False).\add('age',IntegerType(),nullable=True)df = spark.createDataFrame(rdd,schema=schema)df.printSchema()df.show()3、toDF将rdd转换为df
下面展示了两种方式
# 只设定列名,列的数据结构则是内部自己判断df = rdd.toDF(['name','age'])df.printSchema()# root# | -- name: string(nullable=true)# | -- age: long(nullable=true)# 设定列名和数据类型schema =StructType().add("name",StringType(),nullable=False).\add('age',IntegerType(),nullable=True)df = rdd.toDF(schema=schema)df.printSchema()# root# | -- name: string(nullable=false)# | -- age: integer(nullable=true)4、基于pandas构建
dfp = pd.DataFrame({"id":[1,2,3],'score':[99,98,100]})df = spark.createDataFrame(dfp)df.printSchema()df.show()# root# | -- id: long(nullable=true)# | -- score: long(nullable=true)# # +---+-----+# | id | score |# +---+-----+# | 1 | 99 |# | 2 | 98 |# | 3 | 100 |# +---+-----+5、通过文件读取创造

在读取json和parquet文件时不需要设定schema,因为文件已经自带
而读取csv时,还需要使用.option设定 header等参数
这里说一下parquet文件
parquet:是Spark中常用的一种列式存储文件格式
和Hive中的ORC差不多,他俩都是列存储格式
parquet对比普通的文本文件的区别:
- parquet 内置schema(列名列类型 是否为空)
- 存储是以列作为存储格式
- 存储是序列化存储在文件中的(有压缩属性体积小)
DataFrame代码风格
DataFrame支持两种风格进行编程,分别是DSL风格和SQL风格
DSL语法风格
DSL称之为:领域特定语言
其实就是指DataFrame的特有API
DSL风格意思就是以调用API的方式来处理Data比如: df.where0.limit0
SQL语法风格
SQL风格就是使用SQL语句处理DataFrame的数据比如: spark.sql(“SELECT*FROM xxx)
DSL
其实就是用其内置的API处理数据,举例:
df.select('id','subject').show()df.where('subject="语文"').show()df.select('id','subject').where('subject="语文"').show()df.groupBy('subject').count().show()API其实跟SQL类似,这里不详细说明了,个人感觉不如直接写SQL语句
SQL
DataFrame的一个强大之处就是我们可以将它看作是一个关系型数据表,然后可以通过在程序中使用spark.sgl0来执行SQL语句查询,结果返回一个DataFrame。如果想使用SQL风格的语法,需要将DataFrame注册成表采用如下的方式:
df.createTempView('tmp') #创建临时视图df.createGlobalTempView('global_tmp')#创建全局试图# 全局表: 跨SparkSession对象使用在一个程序内的多个SparkSession中均可调用查询前带上前缀:global_tmpdf.createOrReplaceTempView('repalce_tmp')#创建临时表,如果存在则替换然后使用spark.sql的形式书写sql代码
spark.sql('select * from tmp where subject = "语文"').show()spark.sql('select id,score from repalce_tmp where score>90').show()spark.sql('select subject,max(score) from global_temp.global_tmp group by subject').show()SparkSQL Shuffle 分区数目
原因: 在SparkSQL中当Job中产生Shufle时,默认的分区数 spark.sql.shufle,partitions 为200,在实际项目中要合理的设置。
在代码中可以设置:
spark = SparkSession.builder.appName('lmx').\
master('local[*]').config('spark.sql.shufle,partitions',2).\
getOrCreate()spark.sqL.shuffle.partitions 参数指的是,在sql计算中,shuffle算子阶段默认的分区数是200
对于集群模式来说,200个默认也算比较合适
如在Local下运行,200个很多,在调度上会带宋限外的损耗,所以在Local下建议修改比较低, 比如2\4\10均可,这个参数和Spark RDD中设置并行度的参数是相互独立的
DataFrame数据写出
统一API:

下面提供两种方法,分别写出为json和csv
spark.sql('select user_id,avg(score) avg_score from tmp group by user_id order by avg_score desc').write.mode('overwrite').format('json').save('data/output/1t')spark.sql('select user_id,avg(score) avg_score from tmp group by user_id order by avg_score desc').write.mode('overwrite').format('csv')\.option('header',True)\.option('sep',';')\.save('data/output/csv')其他的一些方法:
SparkSQL中读取数据和写出数据 - 知乎
不过这里似乎不能自己命名导出的数据文件
Spark UDF
无论Hive还是SparKSQL分析处理数据时,往往需要使用函数,SparkSQL模块本身自带很多实现公共功能的函数,在pyspark.sql.functions中SparkSQL与Hive一样支持定义函数:UDF和UDAF,尤其是UDF函数在实际项目中使用最为广泛。回顾Hive中自定义函数有三种类型:
第一种:UDF(User-Defined-Function)函数.
一对一的关系,输入一个值经过函数以后输出一个值;
在Hive中继承UDF类,方法名称为evaluate,返回值不能为void,其实就是实现一个方法;第二种:UDAF(User-Defined Aggregation Function)聚合函数
多对一的关系,输入多个值输出一个值,通常与groupBy联合使用;
第三种:UDTF(User-DefinedTable-Generating Functions)函数
一对多的关系,输入一个值输出多个值(一行变为多行),用户自定义生成函数,有点像flatMap;
在SparkSQL中,目前仅仅支持UDF函数和UDAF函数,目前Python仅支持UDF
UDF有两种定义方式
方式1语法
udf对象=sparksession.udfregister(参数1,参数2,参数3)参数1:UDF名称,可用于SQL风格
参数2:被注册成UDF的方法名
参数3:声明UDF的返回值类型udf对象:返回值对象,是一个UDF对象,可用于DSL风格
方式2语法from pyspark.sql import functions as F
udf对象 = F.udf(参数1,参数2)
参数1:被注册成UDF的方法名
参数2:声明UDF的返回值类型
udf对象:返回值对象,是一个UDF对象,可用于DSL风格
举例:
def double_score(num):return 2*numudf1 = spark.udf.register('udf_1',double_score,IntegerType())# dsl风格df.select(udf1(df['score'])).show()# sql风格df.selectExpr('udf_1(score)').show()# sql风格2df.createTempView('tmp')spark.sql("select udf_1(score) from tmp").show()udf2 = F.udf(double_score,IntegerType())df.select(udf2(df['score'])).show()当返回值是数组时,需要定义数组内部数据的数据类型:ArrayType(StringType())
spark = SparkSession.builder.appName('lmx').master('local[*]').config('spark.sql.shufle,partitions',2).getOrCreate()sc = spark.sparkContextrdd=sc.parallelize([['i love you'],['i like you']])df = rdd.toDF(['ifo'])def func(num):return num.split(' ')udf = spark.udf.register('udf_sql',func,ArrayType(StringType()))# dsl风格df.select(udf(df['ifo'])).show()当返回值是字典时,需要使用StructType(),且定义每个列的名字(需要跟函数返回值的列名一样)和数据类型
rdd=sc.parallelize([[1],[2],[3],[4],[5]])df = rdd.toDF(['ifo'])df.show()def func(num):return {'num':num,'num1':num+10}udf = spark.udf.register('udf_sql',func,StructType().\add('num',IntegerType(),nullable=False).\add('num1',IntegerType(),nullable=False))df.select(udf(df['ifo'])).show()Catalyst优化器
RDD的执行流程为:
代码 ->DAG调度器逻辑任务 ->Task调度器任务分配和管理监控 ->Worker干活
SparkSQL会对写完的代码,执行“自动优化”,既Catalyst优化器,以提升代码运行效率,避免开发者水平影响到代码执行效率。 (RDD代码不会,是因为RDD的数据对象太过复杂,无法被针对性的优化)
加入优化的SparkSQL大致架构为:

1.API 层简单的说就是 Spark 会通过一些 API 接受 SQL 语句
2.收到 SQL 语句以后,将其交给 Catalyst,Catalyst 负责解析 SQL,生成执行计划等
3.Catalyst 的输出应该是 RDD 的执行计划
4.最终交由集群运行
Catalyst优化器主要分为四个步骤
1、解析sql,生成AST(抽象语法树)

2、在 AST 中加入元数据信息,做这一步主要是为了一些优化,例如 col=col 这样的条件
以上面的图为例:
- score.id → id#1#L 为 score.id 生成 id 为1,类型是 Long
- score.math_score→math_score#2#L为 score.math_score 生成 id 为 2,类型为 Long
- people.id→id#3#L为 people.id 生成 id 为3,类型为 Long
- people.age→age#4#L为 people.age 生成 id 为 4,类型为 Long
3、对已经加入元数据的 AST,输入优化器,进行优化,主要包含两种常见的优化:
谓词下推(Predicate Pushdown)\ 断言下推:将逻辑判断 提前到前面,以减少shuffle阶段的数据量。
以上面的demo举例,可以先进行people.age>10的判断再进行Join等操作。
列值裁剪(Column Pruning):将加载的列进行裁剪,尽量减少被处理数据的宽度
以上面的demo举例,由于只select了score和id,所以开始的时候,可以只保留这两个列,由于parquet是按列存储的,所以很适合这个操作
4、上面的过程生成的 AST 其实最终还没办法直接运行,这个 AST 叫做 逻辑计划,结束后,需要生成 物理计划,从而生成 RDD 来运行
Spark SQL的执行流程
如此,Spark SQL的执行流程为:
1.提交SparkSQL代码
2.catalyst优化
a.生成原始AST语法数
b.标记AST元数据
c.进行断言下推和列值裁剪 以及其它方面的优化作用在AST上
d.将最终AST得到,生成执行计划
e.将执行计划翻译为RDD代码
3.Driver执行环境入口构建(SparkSession)
4.DAG 调度器规划逻辑任务
5.TASK 调度区分配逻辑任务到具体Executor上工作并监控管理任务
6.Worker干活
Spark新特性
自适应查询(SparkSQL)
即:Adaptive Query Execution
由于缺乏或者不准确的数据统计信息(元数据)和对成本的错误估算(执行计划调度)导致生成的初始执行计划不理想
在Spark3.x版本提供Adaptive Query Execution自适应查询技术 通过在”运行时”对查询执行计划进行优化, 允许Planner在运行时执行可选计划,这些可选计划将会基于运行时数据统 计进行动态优化, 从而提高性能,其开启方式为:
set spark.sql.adaptive.enabled = true;Adaptive Query Execution AQE主要提供了三个自适应优化:
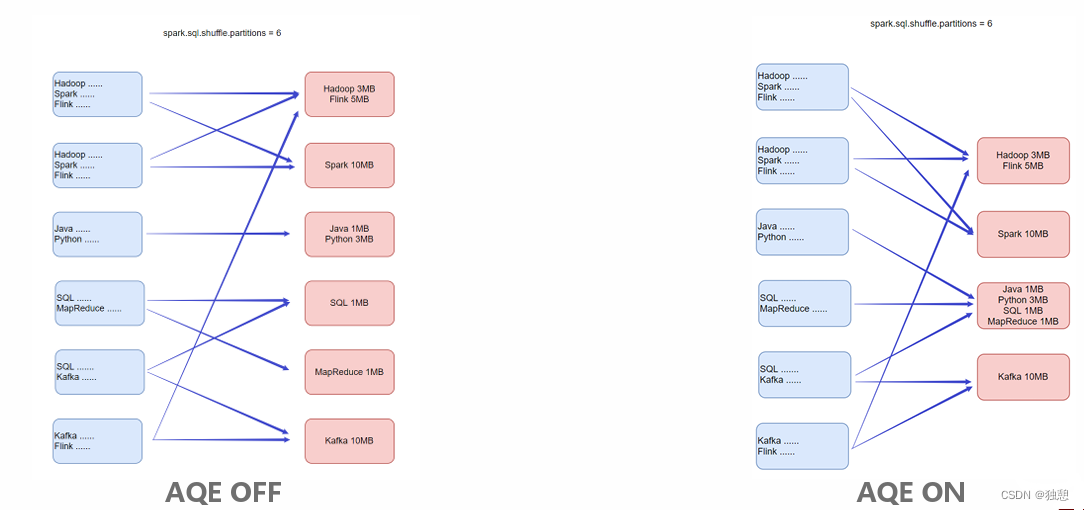
动态合并
即:Dynamically coalescing shuffle partitions
可以动态调整shuffle分区的数量。用户可以在开始时设置相对较多的shuffle分区数,AQE会在运行时将相邻的小分区 合并为较大的分区。
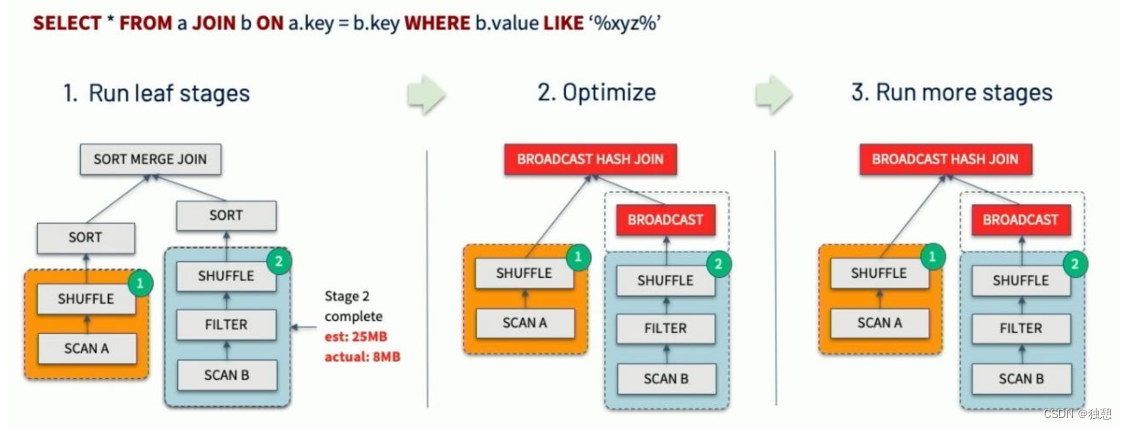
动态调整Join策略
即:Dynamically switching join strategies
此优化可以在一定程度上避免由于缺少统计信息或着错误估计大小(当然也可能两种情况同时存在),而导致执行计 划性能不佳的情况。这种自适应优化可以在运行时sort merge join转换成broadcast hash join,从而进一步提升性能
动态优化倾斜Join
skew joins可能导致负载的极端不平衡,并严重降低性能。在AQE从shuffle文件统计信息中检测到任何倾斜后,它可 以将倾斜的分区分割成更小的分区,并将它们与另一侧的相应分区连接起来。这种优化可以并行化倾斜处理,获得更 好的整体性能。
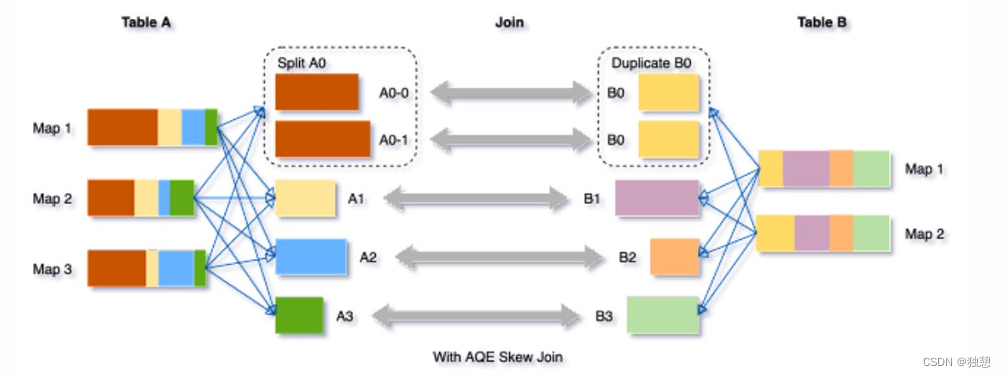
触发条件: 1. 分区大小> spark.sql.adaptive.skewJoin.skewedPartitionFactor (default=10) * "median partition size(中位数分区大小)"
2. 分区大小> spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes (default = 256MB )
动态分区裁剪(SparkSQL)
即:Dynamic Partition Pruning
当优化器在编译时无法识别可跳过的分区时,可以使用"动态分区裁剪",即基于运行时推断的信息来进一步进行分区 裁剪。这在星型模型中很常见,星型模型是由一个或多个并且引用了任意数量的维度表的事实表组成。在这种连接操 作中,我们可以通过识别维度表过滤之后的分区来裁剪从事实表中读取的分区。