----------------2024-2-6-更新--------------
doris的routineload,就是从kafka中加载数据到表,特点是定时、周期性的从kafka取数据。
要想在本地开发测试routine load相关功能,需要配置kafka环境,尤其是需要增加routine load回归测试用例时,还需要kafka有回归测试需要的数据。
doris源码里自带了一个脚本 docker/thirdparties/run-thirdparties-docker.sh ,它可以在本地的docker中创建container(里面包含了kafka、zookeeper,总之就是kafka测试环境),并且加载回归测试所需要的数据。
下面就是使用这个脚本,搭建本地kafka环境的步骤:
1、首先本地机器要安装和启动docker服务器,podman也行:
systemctl start docker
或者
systemctl start podman
docker ps
脚本中要用docker-compose,这是个python脚本,要用pip下载:pip install docker-compose
2、安装Java环境:
export JAVA_HOME=/home/postgres/jdk-1.8.0_201
export PATH=$JAVA_HOME/bin:$PATH
3、安装kafka(客户端)
在docker之外,我们需要kafka客户端,这样可以查看docker中的kafka的topic,由于只需要客户端,只要下载安装包解压就行,不需要任何配置:
[root@qinhvm postgres]# ls kafka_2.13-2.7.2*
kafka_2.13-2.7.2.tgzkafka_2.13-2.7.2:
bin config libs LICENSE licenses NOTICE site-docs
4、然后就是doris源码里的脚本 docker/thirdparties/run-thirdparties-docker.sh,在我的环境,它有点问题,需要改一下。
其实我们只用到 run-thirdparties-docker.sh 的
if [[ "${RUN_KAFKA}" -eq 1 ]]; then
。。。
fi
这部分代码块,修改后的这部分脚本如下:
if [[ "${RUN_KAFKA}" -eq 1 ]]; then# kafkaKAFKA_CONTAINER_ID="${CONTAINER_UID}kafka"eth0_num=$(ifconfig -a|grep flags=|grep -n ^ens3|awk -F ':' '{print $1}')IP_HOST=$(ifconfig -a|grep inet|grep -v 127.0.0.1|grep -v inet6|awk '{print $2}'|tr -d "addr:"|tail -n +${eth0_num}|head -n 1)cp "${ROOT}"/docker-compose/kafka/kafka.yaml.tpl "${ROOT}"/docker-compose/kafka/kafka.yamlsed -i "s/doris--/${CONTAINER_UID}/g" "${ROOT}"/docker-compose/kafka/kafka.yamlsed -i "s/localhost/${IP_HOST}/g" "${ROOT}"/docker-compose/kafka/kafka.yamlsudo docker-compose -f "${ROOT}"/docker-compose/kafka/kafka.yaml downif [[ "${STOP}" -ne 1 ]]; thensudo docker-compose -f "${ROOT}"/docker-compose/kafka/kafka.yaml up --build --remove-orphans -dsleep 10s# start_kafka_producers "${KAFKA_CONTAINER_ID}" "${IP_HOST}"fi
fi
下面的红色粗体部分根据自己机器上网卡名替换一下:
eth0_num=$(ifconfig -a|grep flags=|grep -n ^ens3|awk -F ':' '{print $1}')
start_kafka_producers() 这个函数把测试数据写到kafka的topic里,测试数据在doris/docker/thirdparties/docker-compose/kafka/scripts/目录下,这个函数在最新的代码里被注掉了,因为routine load测试用例里,有一段代码替代了它的工作。
还要修改 doris/docker/thirdparties/custom_settings.env:
CONTAINER_UID="doris-mytest-" # 这个要改一下,随便取个名
还需要修改 doris/docker/thirdparties/docker-compose/kafka/kafka.yaml.tpl :
version: "3"
networks:
doris--kafka--network:
ipam:
driver: default
config:
- subnet: 168.45.0.0/24services:
doris--zookeeper:
image: wurstmeister/zookeeper
restart: always
container_name: doris--zookeeper
ports:
- 12181:2181
networks:
- doris--kafka--network
doris--kafka:
image: wurstmeister/kafka
restart: always
container_name: doris--kafka
depends_on:
- doris--zookeeper
ports:
- 19193:19193
environment:
KAFKA_ZOOKEEPER_CONNECT: doris--zookeeper:2181/kafka
KAFKA_LISTENERS: PLAINTEXT://:19193
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:19193
KAFKA_BROKER_ID: 1
volumes:
- /var/run/docker.sock:/var/run/docker.sock
networks:
- doris--kafka--network
上面这些都弄好后,执行 ./run-thirdparties-docker.sh -c kafka,就会下载镜像,创建kafka和zookeeper的容器,配置好网络。
每次执行完本地的routine load测试用例,下次执行前要重复执行一下./run-thirdparties-docker.sh -c kafka 这样可以删除之前测试用例创建的topic,否则会重复插入数据导致测试失败。
但是在执行routine load测试用例时,又遇到了一个问题,就是报找不到类:
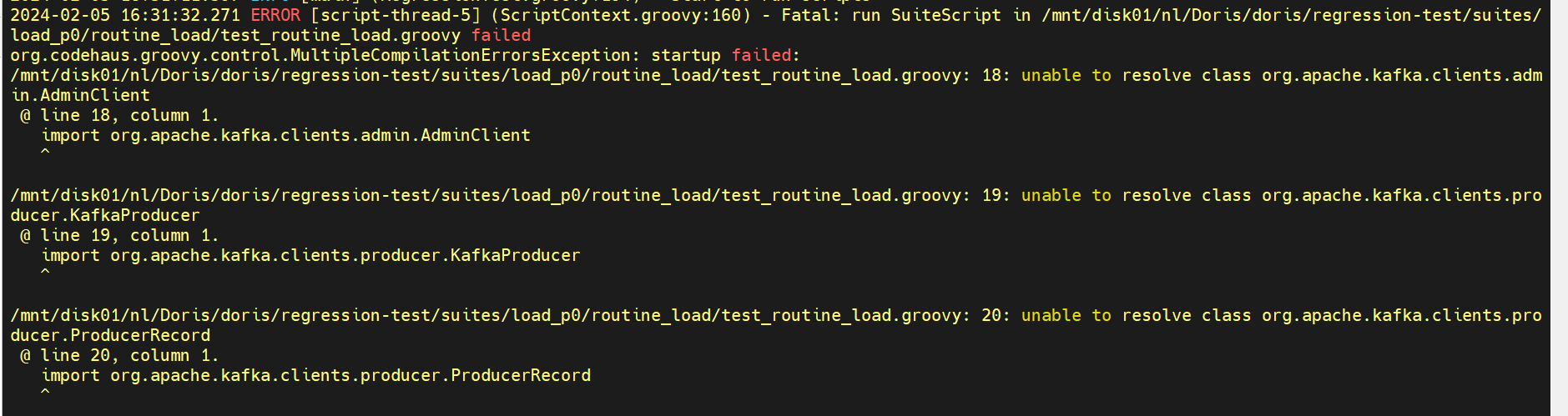
这应该是没有把kafka-client的jar加到classpath中,打开run-thirdparties-docker.sh,在文件的最后做如下修改:(kafka-client的jar报在fe中有)

然后就OK了。