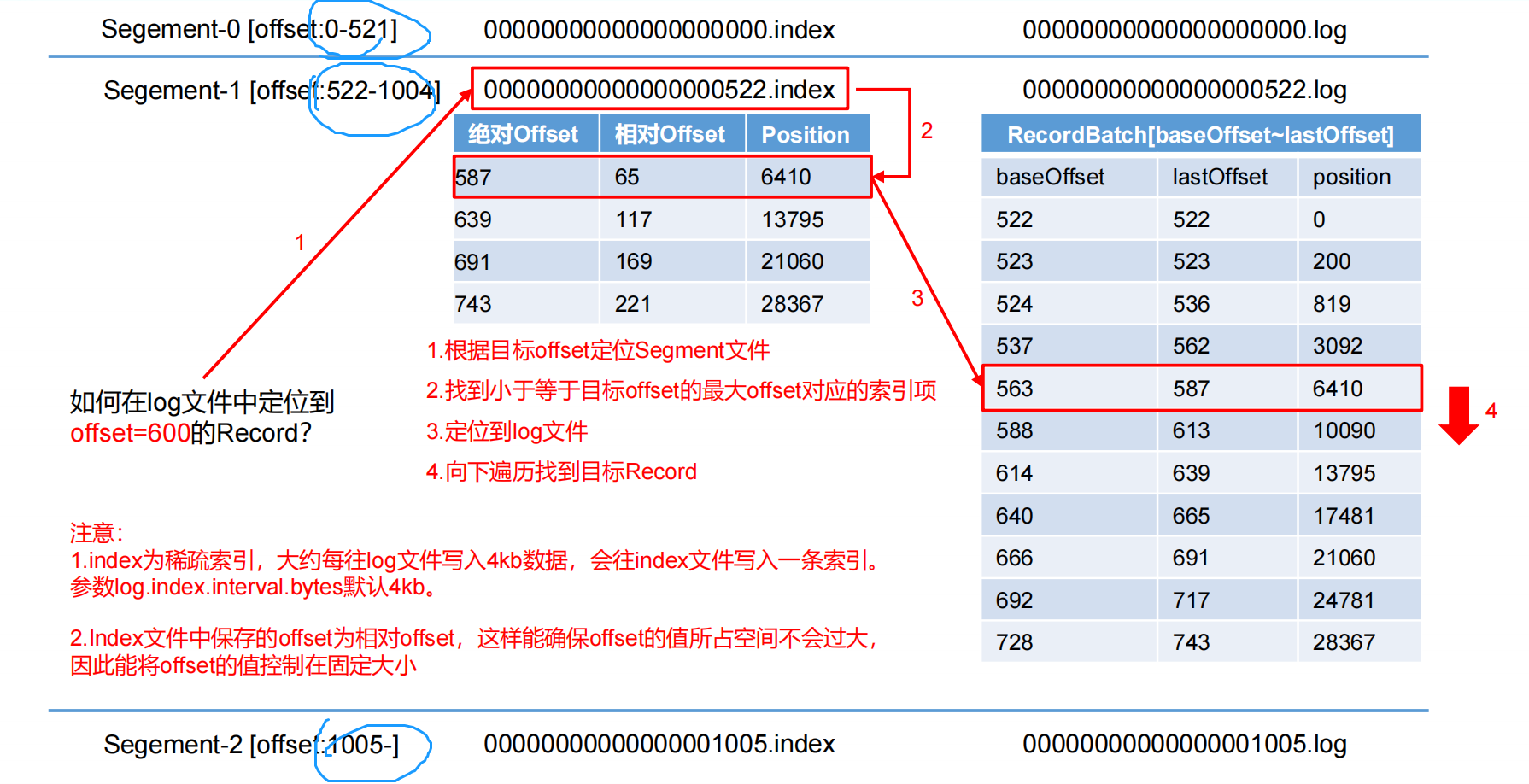
常见基本概念
在正式引入架构演进之前,先了解几个比较重要的概念做前置介绍。
应用(Application)/系统(System)
一个应用,就是一个/一组服务器程序
模块(Module)/组件(Component)
一个应用,里面有很多个功能。每个独立的功能,就可以称为是一个模块/组件
分布式(Distributed)
引入多个主机/服务器,协同配合完成一系列的工作
物理上的多个主机
集群(Cluster)
引入多个主机/服务器,协同配合完成一系列的工作
逻辑上的多个主机
主(Master)/从(Slave)
集群中,通常有一个程序需要承担更多的职责,被称为主;其他承担附属职责的被称为从。
多个服务器节点,其中一个是主,另外的是从,从节点的数据主要从主节点这里同步过来
中间件(Middleware)
和业务无关的服务(功能更通用的服务),比如数据库、缓存和消息队列
评价指标(Metric)
可用性(Availability):系统整体可用的时间/总的时间
响应时长(Response Time RT):用来衡量服务器的性能,和具体服务器要做的业务密切相关,越小越好
吞吐(Throughput)vs并发(Concurrent):衡量系统的处理请求的能力,是衡量性能的一种方式
架构演进
下文以“电子商务”应用为例,介绍从一百个到千万级并发情况下服务端的架构的演进过程。
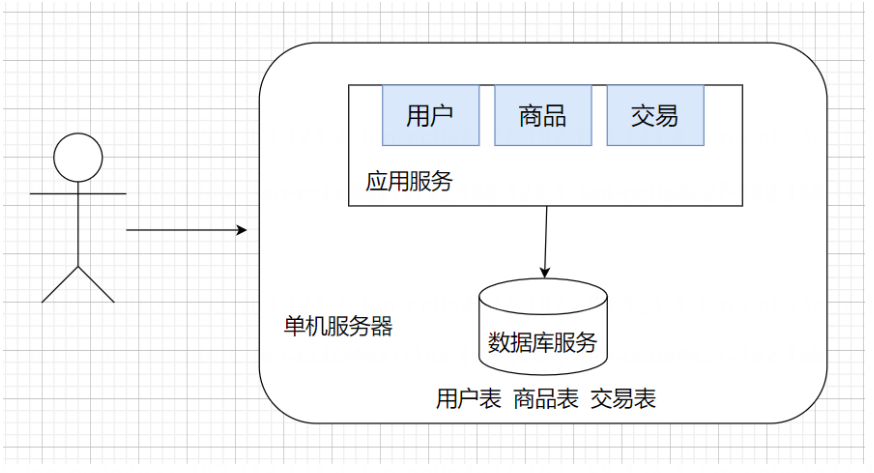
单机架构
在初期,大部分公司的产品都是单机架构,只有一台服务器,这个服务器负责所有的工作
前期用户访问量很少,没有对我们的性能、安全等提出很高的要求,而且系统架构简单,无需专业的运维团队,所以选择单机架构是合适的。
虽然只有一个单机服务器,但是至少包含两部分,应用服务和数据库服务,应用服务就是我们写的服务器程序(HTTP服务器),比如Spring;数据库服务比如MySQL;MySQL是一个客户端服务器结构的程序,本体是MySQL服务器(存储和组织数据的部分),客户端就是应用服务器,来读写数据库服务器;
比如用户现在想查看商品列表,应用服务器就会发送一个select查询请求到MySQL服务器上,MySQL服务器负责查到并返回给应用服务器,应用服务器再通过HTTP协议返回给用户,最终显示在浏览器界面上。
如果业务进一步增长,用户量和数据量都水涨船高,一台主机难以应付的时候,就需要引入更多的主机,引入更多的硬件资源。
一台主机的硬件资源是有上限的,包括但不限于CPU、内存、硬盘、网络等,服务器每次收到一个请求,都是需要消耗上述的一些资源的,如果同一时刻,处理的请求多了,就可能会导致某个硬件资源不够用了。
无论是哪方面不够用了,都可能会导致服务器处理请求的时间变长,甚至于处理出错;
如果真的遇到了这样的服务器不够用的场景,就需要通过开源节流两种方式来解决,开源就是简单粗暴的通过增加更多的硬件资源来实现,节流是指在软件上优化,需要通过性能测试,找到对应瓶颈,再去对症下药,对我们的要求就比较高了。
应用服务和数据库分离
随着请求量和数据量的增加,一台主机很有可能就扛不住了,就需要引入多台主机来解决,最典型的方案就是把应用服务和数据库来分别部署到两台主机上
应用服务器里面可能会包含很多的业务逻辑,可能会吃CPU和内存
数据库服务器需要更大的磁盘空间,更快的数据访问速度
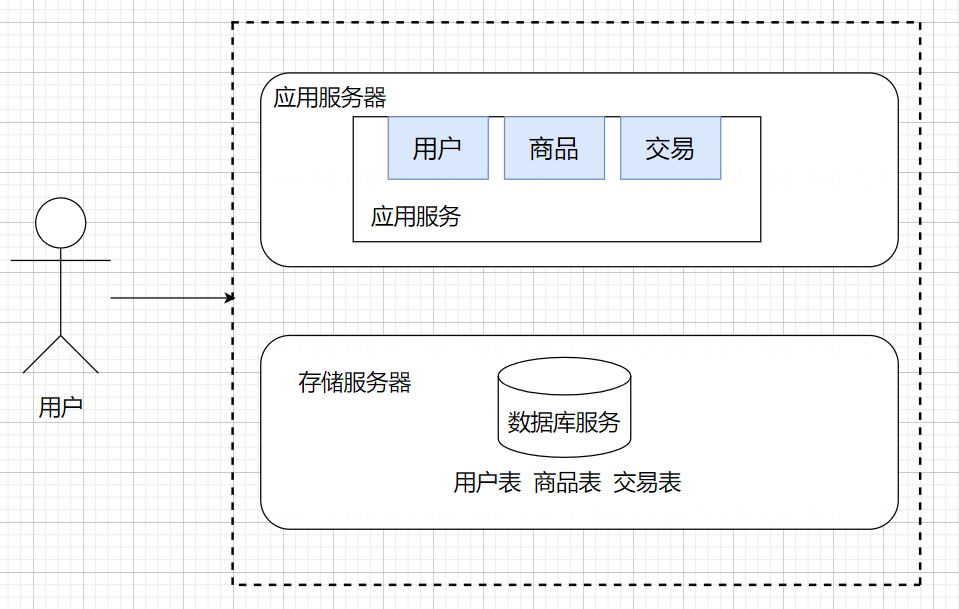
应用服务集群——负载均衡
应用服务器可能会比较吃CPU和内存,如果把CPU或者内存吃没了,此时应用服务器就顶不住了,需要引入更多的应用服务器来解决上述问题
用户的请求,会先到达负载均衡器/网关服务器(单独的服务器),然后会根据一些算法再分配给多个应用服务器。
负载均衡器看起来承担了所有的请求,但是其对于请求量的承担能力,要远超过应用服务器。
这是因为负载均衡器就类似于领导,只负责分配工作,而应用服务器是组员,需要执行任务,分配工作所耗费的成本要远少于执行任务所耗费的成本。
如果出现请求量大到负载均衡器也扛不住了,就需要引入更多的负载均衡器(引入多个机房)
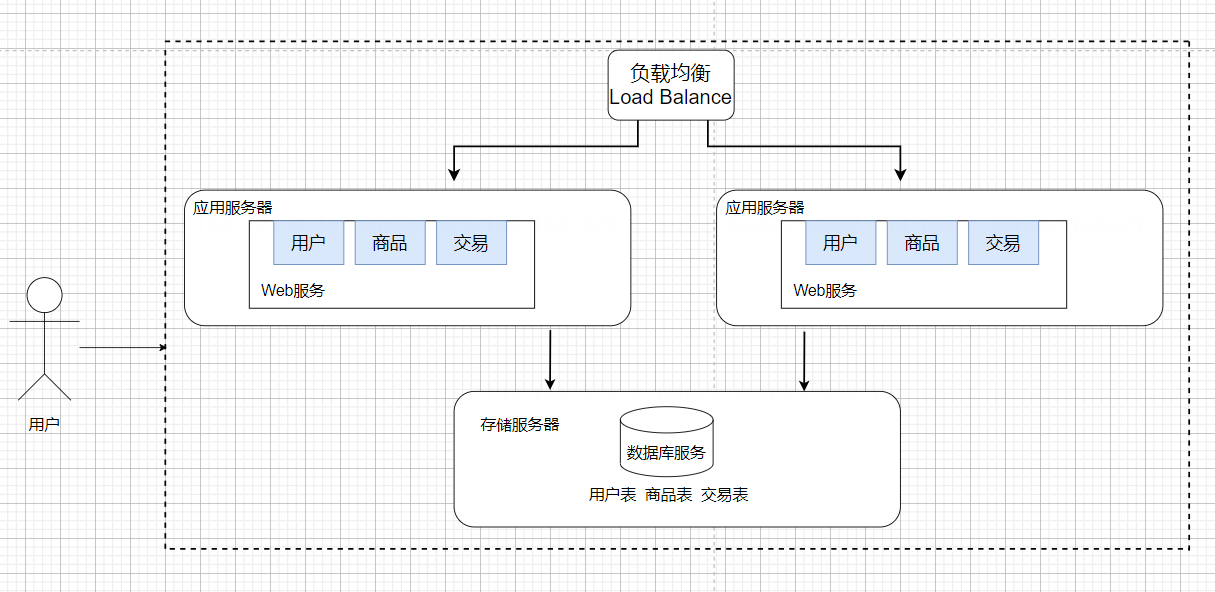
读写分离——主(master)从(slave)架构
如上所讨论,增加应用服务器,确实能够处理更高的请求量,但是随之存储服务器要承担的请求量也就更多了,我们就需要引入更多的存储服务器来处理请求。
在实际的应用场景中,读的频率要比写的频率是高的,所以我们保留一个主要的数据库作为写入数据库(主库),其他的数据库作为从属数据库(从库),从库的所有数据全部来自主库的数据,经过同步后,从库可以维护着和主库一致的数据。然后为了分担数据库的压力,我们可以将写数据请求全部交给主库处理,但读请求分散到各个从库中。
主服务器一般是一个,从服务器可以有多个(一主多从);同时从数据库通过负载均衡的方式,让应用服务器进行访问。
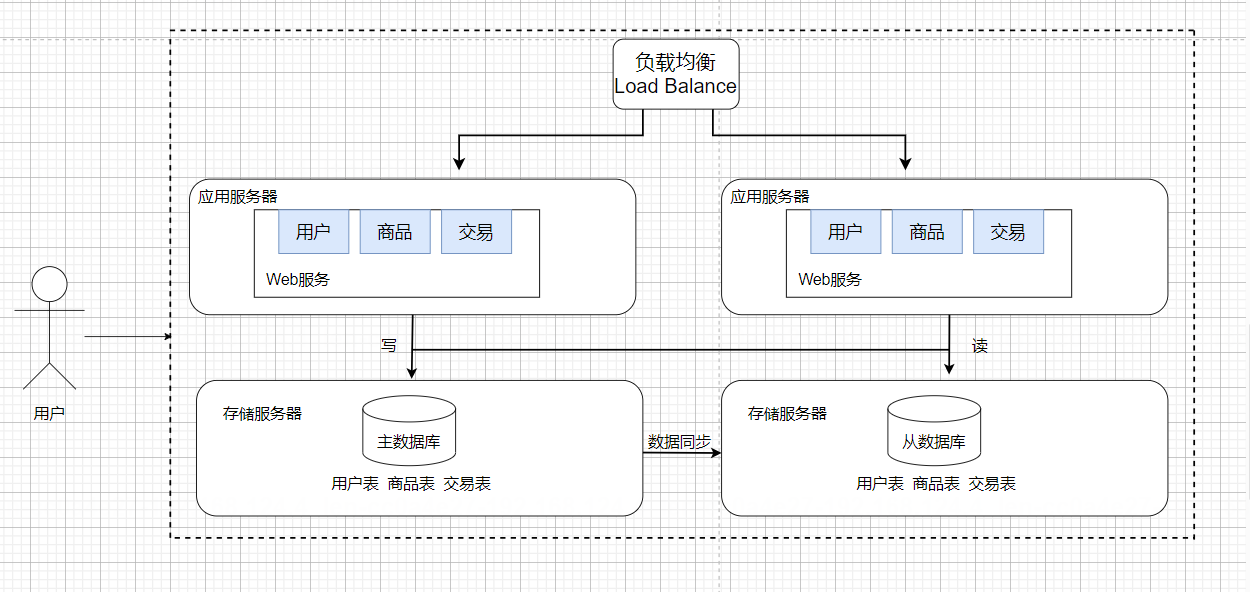
缓存——冷热分离
数据库天然有个问题,响应速度是更慢的,但随着访问量的增加,我们可以发现一部分热点数据,可以被频繁的访问到,也就是20%的数据,能够支持80%的访问量;
所以我们把数据区分**“冷热”**,把热点数据放到缓存中,缓存的访问速度要比数据库快很多,以这种方式来解决响应速度慢的问题。
分库分表
引入分布式系统,不光要能够去应对更高的请求量,同时也要能应对更大的数据量,在实际场景中,可能会出现一台服务器已经存不下数据了,这时候就需要多台主机来存储。
原来的一个数据库服务器,可以通过引入多个数据库服务器来演变为一个数据库集群,每个数据库服务器存储一个或者一部分数据库(create database)。
如果某个表特别大,大到一台主机存不下,也可以针对表进行拆分,具体分库分表如何实践,还需要结合实际的业务场景来展开。
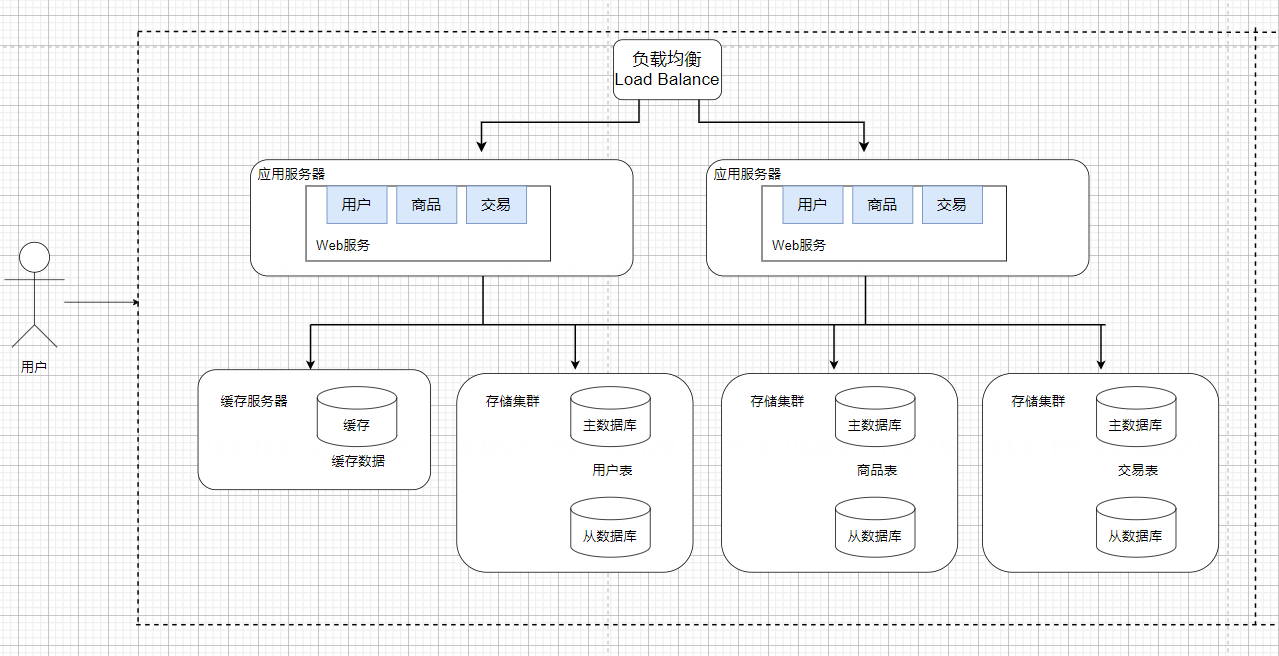
微服务
之前的应用服务器,一个服务器程序里可能做了很多的业务,这就可能会导致这一个服务器的代码变的越来越复杂,为了更方便于代码的维护,就可以把这样的一个复杂的服务器,拆分成更多的,功能更单一,但是更小的服务器,这样服务器的种类和数量就增加了。
当应用服务器复杂了,势必就需要更多的人来维护了;当人多了,就需要划分组织结构,分成多个组,每个组分别配备领导进行管理。
按照功能,拆分成多组微服务,就可以有利于上述人员的组织结构的分配了。
所以微服务,本质上是在解决“人”的问题
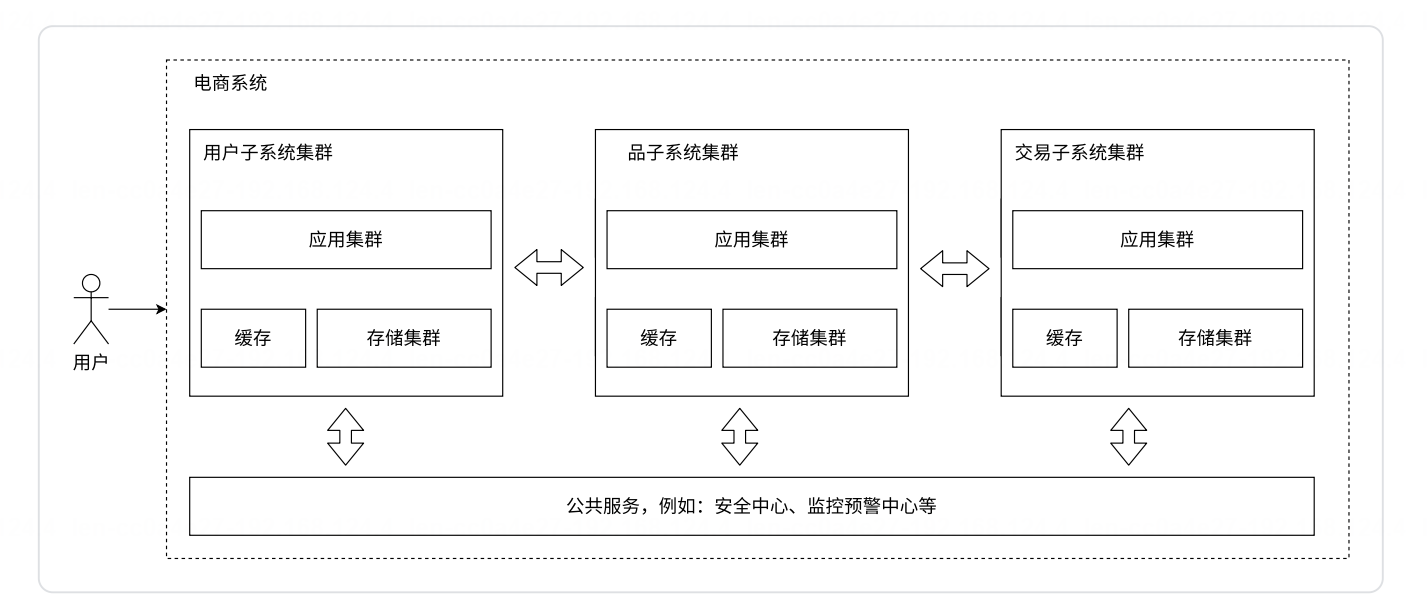
微服务的代价:
1、系统的性能下降
因为拆出来更多的服务,多个功能之间要更依赖网络通信,网络通信的速度很可能是比硬盘还慢的;要想保证性能不下降太多,只能引入更多的机器,更多的硬件资源
2、系统复杂程度提高,可用性受到影响
微服务引入的服务器更多了,出现问题的概率也就更大了
这就需要一系列的手段,来保证系统的可用性,比如更丰富的监控报警,以及配套的运维人员
微服务的优势
1、解决了人的问题
2、使用微服务,可以更方便于功能的复用
3、可以给不同的服务进行不同的部署
小结
所谓的分布式系统,就是想办法引入更多的硬件资源,上文所谈及的分布式架构的演化步骤,只是一个粗略的过程,实际上一个商业项目,真实的演化过程,都是和他的业务发展密切相关的。
分布式系统演化过程的小结如下:
1、单机架构(应用程序+数据库服务器)
2、数据库和应用分离
应用程序和数据库服务器 分别放到不同主机上部署了
3、引入负载均衡 应用服务器=>集群
通过负载均衡器,把请求比较均匀的分发给集群中的每个应用服务器
4、引入读写分离 数据库主从结构
一个数据库节点作为主节点,其他N个数据库节点作为从节点
主节点负责写数据,从节点负责读数据;主节点需要把修改过的数据同步给从节点
5、引入缓存,冷热数据分离
根据二八原则,将热点数据存储在缓存中,加快访问速度,进一步的提升了服务器针对请求的处理能力,但是同时也引入了数据库和缓存数据不一致的问题;
Redis在一个分布式系统中,通常就扮演着缓存这样的角色;
6、引入分库分表,数据库能够进一步扩展存储空间
7、引入微服务,从业务上进一步拆分应用服务器
从业务功能的角度,把应用服务器,拆分成更多的功能更单一,更简单,更小的服务器